TiDB 6.0 实战分享丨冷热存储分离解决方案
Posted TiDB_PingCAP
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了TiDB 6.0 实战分享丨冷热存储分离解决方案相关的知识,希望对你有一定的参考价值。
结论先行
TiDB 6.0 正式提供了数据放置框架(Placement Rules in SQL )功能,用户通过 SQL 配置数据在 TiKV 集群中的放置位置,可以对数据进行直接的管理,满足不同的业务场景需要。如:
1.冷热分离存储,降低存储成本
- TiDB 6.0 正式支持数据冷热存储分离,可以降低 SSD 使用成本。使用 TiDB 6.0 的数据放置功能,可以在同一个集群实现海量数据的冷热存储,将新的热数据存入 SSD,历史冷数据存入 HDD,降低历史归档数据存储成本。
- 将热数据从 ssd 迁移到 hdd,每小时可归档约 3000 万行,总体来看效率还是比较高的
- 将冷数据从 hdd 迁移到 ssd,每小时可迁移约 6300 万行,大约是从 ssd 迁移到 hdd 速度的 2 倍
- 分离存储过程,ssd 和 hdd 用于归档的 IO 消耗都在 10%以内,集群访问 QPS 表现平稳,对业务访问的影响较小
- 在补写冷数据场景,每小时写入约 1500 万行到 hdd,数据可正确地直接写入 hdd,不会经过 ssd
2.业务底层物理隔离,实现同一集群不同存储
- 通过放置规则管理将不同数据库下的数据调度到不同的硬件节点上,实现业务间数据的物理资源隔离,避免因资源争抢,硬件故障等问题造成的相互干扰
- 通过账号权限管理避免跨业务数据访问,提升数据质量和数据安全。
3.合并mysql业务,降低运维压力,提升管理效率
- 使用少数 TiDB 集群替换大量的 MySQL 实例,根据不同业务底层设置不同的物理存储隔离需求,让数据库数量大大减少,原本的升级、备份、参数设置等日常运维工作将大幅缩减,在资源隔离和性价比上达到平衡,大幅减少 DBA 日常的运维管理成本。
我们的 HTAP 集群目前有一个数据归档需求,整个集群共约 330TB,考虑到成本和访问频率、性能等各方面需求,要求至少存储 3 个月共约 80TB 到 ssd,250TB 存到 hdd,现在基于我们的大数据冷热分离归档业务场景,本文重点探讨冷热数据归档存储的功能和特性,以方便下一步我们正式应用到生产环境。
概述
TiDB 集群通过 PD 节点(Placement Driver 组件)在系统内基于热点、存储容量等策略自动完成 region 的调度,从而实现集群数据均衡、分散存储在各个节点的目标,这些调度操作是集群的自身管理行为,对用户而已几乎是透明的,在之前的版本用户无法精确控制数据的存储方式和位置。
TiDB 6.0 正式提供了数据放置框架(Placement Rules in SQL )功能,用户通过 SQL 配置数据在 TiKV 集群中的放置位置,可以对数据进行直接的管理,以满足不同的业务场景需要。用户可以将库、表和分区指定部署至不同的地域、机房、机柜、主机。还支持针对任意数据提供副本数、角色类型等维度的灵活调度管理能力,这使得在多业务共享集群、跨中心部署、冷热数据归档存储等场景下,TiDB 得以提供更灵活更强大的数据管理能力。
该功能可以实现以下业务场景:
- 动态指定重要数据的副本数,提高业务可用性和数据可靠性
- 将最新数据存入 SSD,历史数据存入 HDD,降低归档数据存储成本
- 把热点数据的 leader 放到高性能的 TiKV 实例上,提供高效访问
- 不同业务共用一个集群,而底层按业务实现存储物理隔离,互不干扰,极大提升业务稳定性
- 合并大量不同业务的 MySQL 实例到统一集群,底层实现存储隔离,减少管理大量数据库的成本
原理简介
早期版本的 Placement rule 使用时需要通过 pd-ctl 工具设置和查看,操作繁琐且晦涩难懂。经过几个版本的迭代和优化,推出的 PlacementRules in SQL 对用户更加友好,到了 v6.0.0 总体来说还是很方便理解和使用的,避免了使用 pd-ctl 工具配置的复杂性,大大降低使用门槛。
放置策略的实现依赖于 TiKV 集群 label 标签配置,需提前做好规划(设置 TiKV 的 labels)。可通过show placement labels查看当前集群所有可用的标签。
mysql> show placement labels ;
+------+-----------------------------------------------------------------+
| Key | Values |
+------+-----------------------------------------------------------------+
| disk | ["ssd"] |
| host | ["tikv1", "tikv2", "tikv3"] |
| rack | ["r1"] |
| zone | ["guangzhou"] |
+------+-----------------------------------------------------------------+
4 rows in set (0.00 sec)
使用时有基础用法和高级用法两种方式。
(1) 基础放置策略
基础放置策略主要是控制 Raft leader 和 followers 的调度。
#创建放置策略
CREATE PLACEMENT POLICY myplacementpolicy PRIMARY_REGION="guangzhou" REGIONS="guangzhou,shenzhen";
#将规则绑定至表或分区表,这样指定了放置规则
CREATE TABLE t1 (a INT) PLACEMENT POLICY=myplacementpolicy;
CREATE TABLE t2 (a INT);
ALTER TABLE t2 PLACEMENT POLICY=myplacementpolicy;
#查看放置规则的调度进度,所有绑定规则的对象都是异步调度的。
SHOW PLACEMENT;
#查看放置策略
SHOW CREATE PLACEMENT POLICY myplacementpolicy\\G
select * from information_schema.placement_policies\\G
#修改放置策略,修改后会传播到所有绑定此放置策略的对象
ALTER PLACEMENT POLICY myplacementpolicy FOLLOWERS=5;
#删除没有绑定任何对象的放置策略
DROP PLACEMENT POLICY myplacementpolicy;
(2) 高级放置策略
基础放置策略主要是针对 Raft leader 、Raft followers 的调度策略,如果需要更加灵活的方式,如不区分 region 角色将数据指定存储在 hdd,需要使用高级放置策略。使用高级放置策略主要有两个步骤,首先创建策略,然后在库、表或分区上应用策略。
# 创建策略,指定数据只存储在ssd
CREATE PLACEMENT POLICY storeonfastssd CONSTRAINTS="[+disk=ssd]";
# 创建策略,指定数据只存储在hdd
CREATE PLACEMENT POLICY storeonhdd CONSTRAINTS="[+disk=hdd]";
# 在分区表应用高级放置策略,指定分区存储在hdd或者ssd上,未指定的分区由系统自动调度
CREATE TABLE t1 (id INT, name VARCHAR(50), purchased DATE)
PARTITION BY RANGE( YEAR(purchased) ) (
PARTITION p0 VALUES LESS THAN (2000) PLACEMENT POLICY=storeonhdd,
PARTITION p1 VALUES LESS THAN (2005),
PARTITION p2 VALUES LESS THAN (2010),
PARTITION p3 VALUES LESS THAN (2015),
PARTITION p4 VALUES LESS THAN MAXVALUE PLACEMENT POLICY=storeonfastssd
);
高级放置策略具体内容,请看官网介绍https://docs.pingcap.com/zh/tidb/stable/placement-rules-in-sql#%E9%AB%98%E7%BA%A7%E6%94%BE%E7%BD%AE。
环境
| 角色 | 机器数 | 内存 | 数据盘 | CPU | OS |
|---|---|---|---|---|---|
| TiDB&TiPD | 3 | 256G | 1TB hdd | 40 cpu (20 core*2 thread) | Debian 4.19.208-1 (2021-09-29) x86_64 GNU/Linux |
| TiKV | 3 | 256G | 800GB ssd,1TB hdd | 40 cpu (20 core*2 thread) | Debian 4.19.208-1 (2021-09-29) x86_64 GNU/Linux |
冷热归档存储
- 目标:对给定的表按日期分区,将最新分区的数据存入 SSD,历史数据存入 HDD
功能验证
1.部署集群并建立放置策略
-
部署 TiDB v6.0.0 集群,具体参考部署集群操作
-
创建数据落盘策略,以备使用
# 应用该策略的库、表、分区,数据会存储在ssd上 CREATE PLACEMENT POLICY storeonssd CONSTRAINTS="[+disk=ssd]" ; # 应用该策略的库、表、分区,数据会存储在hdd上 CREATE PLACEMENT POLICY storeonhdd CONSTRAINTS="[+disk=hdd]"; #查看集群已有策略 mysql> show placement \\G *************************** 1. row *************************** Target: POLICY storeonhdd Placement: CONSTRAINTS="[+disk=hdd]" Scheduling_State: NULL *************************** 2. row *************************** Target: POLICY storeonssd Placement: CONSTRAINTS="[+disk=ssd]" Scheduling_State: NULL 2 rows in set (0.02 sec)
2.创建库表并应有放置策略
建立目标表为TiDB分区表并且按 Range 分区。
# 创建数据库tidb_ssd_hdd_test,并设置该库默认落盘策略,设置后新建的表都会默认继承该策略
create database tidb_ssd_hdd_test PLACEMENT POLICY=storeonssd;
# 查看策略已经应用到指定库上
mysql> show placement \\G
*************************** 1. row ***************************
Target: POLICY storeonhdd
Placement: CONSTRAINTS="[+disk=hdd]"
Scheduling_State: NULL
*************************** 2. row ***************************
Target: POLICY storeonssd
Placement: CONSTRAINTS="[+disk=ssd]"
Scheduling_State: NULL
*************************** 3. row ***************************
Target: DATABASE tidb_ssd_hdd_test
Placement: CONSTRAINTS="[+disk=ssd]"
Scheduling_State: SCHEDULED
3 rows in set (0.02 sec)
# 建立分区表,可以看到表建立后默认继承和库一样的落盘策略,关键标识为“/*T![placement] PLACEMENT POLICY=`storeonssd` */”
CREATE TABLE `logoutrole_log ` (
`doc_id` varchar(255) NOT NULL,
`gameid` varchar(255) DEFAULT NULL ,
-- some fields
`logdt` timestamp DEFAULT '1970-01-01 08:00:00' ,
`updatetime` varchar(255) DEFAULT NULL ,
UNIQUE KEY `doc_id` (`doc_id`,`logdt`),
-- some index
KEY `logdt_gameid` (`logdt`,`gameid`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_bin /*T![placement] PLACEMENT POLICY=`storeonssd` */
PARTITION BY RANGE ( UNIX_TIMESTAMP(`logdt`) ) (
PARTITION `p20220416` VALUES LESS THAN (UNIX_TIMESTAMP('2022-04-17 00:00:00')),
PARTITION `p20220417` VALUES LESS THAN (UNIX_TIMESTAMP('2022-04-18 00:00:00')),
PARTITION `p20220418` VALUES LESS THAN (UNIX_TIMESTAMP('2022-04-19 00:00:00')),
PARTITION `p20220419` VALUES LESS THAN (UNIX_TIMESTAMP('2022-04-20 00:00:00')),
PARTITION `p20220420` VALUES LESS THAN (UNIX_TIMESTAMP('2022-04-21 00:00:00')),
PARTITION `p20220421` VALUES LESS THAN (UNIX_TIMESTAMP('2022-04-22 00:00:00')),
PARTITION `p20220422` VALUES LESS THAN (UNIX_TIMESTAMP('2022-04-23 00:00:00'))
);
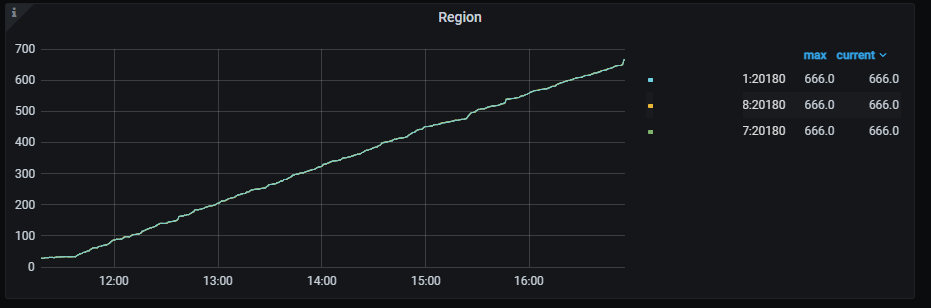
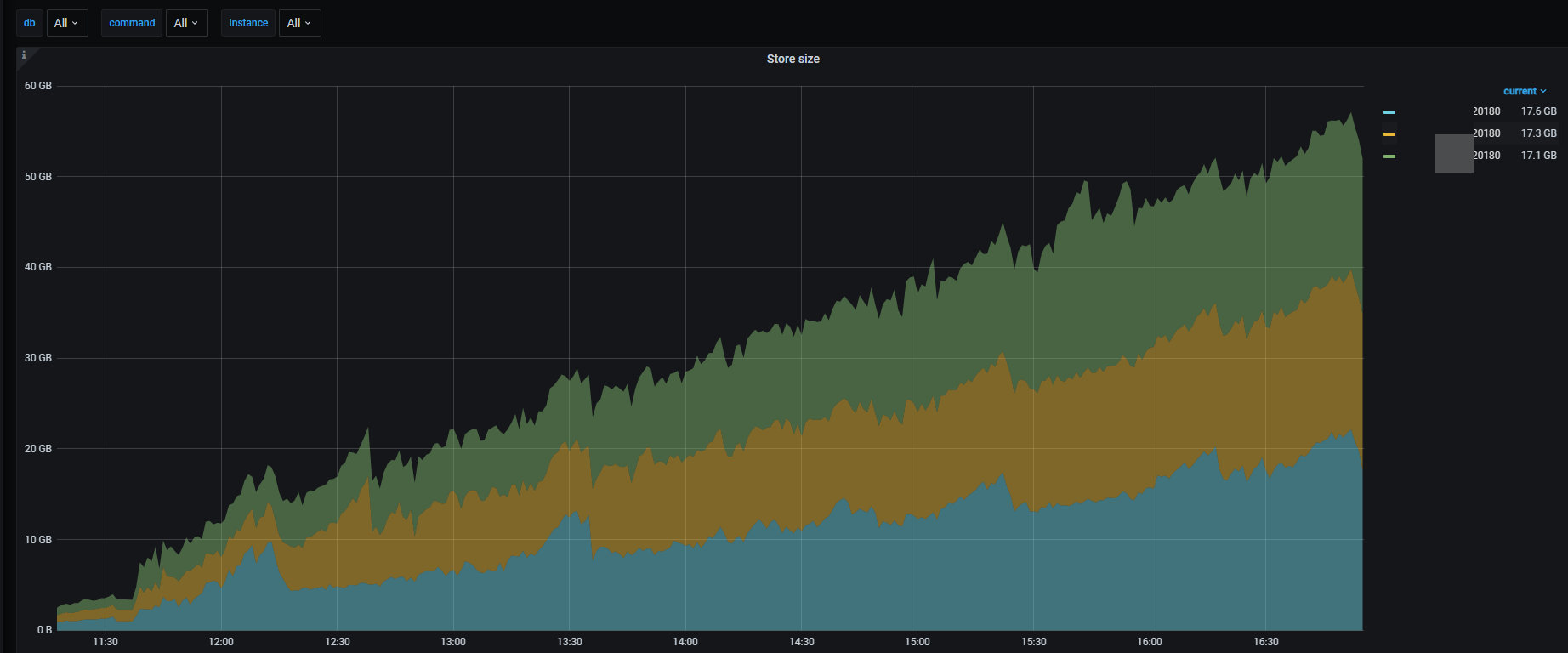
3.写入热数据到 ssd 盘并扩容 hdd 存储节点
- 集群只有 3 个 ssd 的 tikv 节点,启动 flink 流往目标表导入数据,可以看到这 3 个 ssd 节点的 region 数和空间使用在不断增长
- 在原有基础上再扩容 3 个 hdd tikv 实例

4.冷热分离
为了方便模拟数据的迁移,flink 导入的数据是全部落在 2022-04-16 这一天:
mysql> select date(logdt) as day,count(0) from logoutrole_log group by day order by day ;
+------------+----------+
| day | count(0) |
+------------+----------+
| 2022-04-16 | 1109819 |
+------------+----------+
1 row in set (1.09 sec)
停止 Flink 写入后,设置数据分离放置策略,将存储在 ssd 上的 2022-04-16 这一天的数据,转存到 hdd 上,模拟冷数据归档操作:
mysql> alter table tidb_ssd_hdd_test.logoutrole_log partition p20220416 placement policy storeonhdd;
Query OK, 0 rows affected (0.52 sec)
在应用 hdd 转存策略后,如下图可以看到调度规则里 2022-04-16 这一天的分区 Placement 由 ssd 变为了 hdd,即集群已经知晓最新的调度策略是将这一天的分区数据调度到 hdd 去,Scheduling_State 处于 PENDING 状态,表示 Follower 的 raft log 与 Leader 有较大差距,在这里可以理解为是正在处于调度的过程。
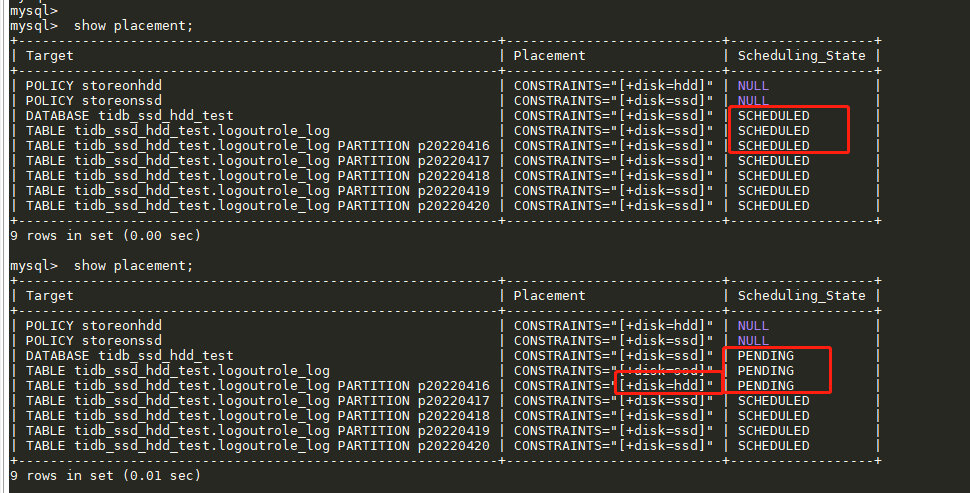
随着时间的推移,数据在不断从 ssd 迁移到 hdd 上。从集群 grafana 监控面板可以看到 ssd 节点上的 region 数据在不断下降,直到降到接近于 0;相反,hdd 上的 region 数不断上升,直到数据全部迁出 ssd 节点。110 万行数据从 ssd 迁移到 hdd,大约耗时 3min 。

在数据全部迁如 hdd 节点后,查看调度进度,此时 Scheduling_State 处于 SCHEDULED 完成调度状态:
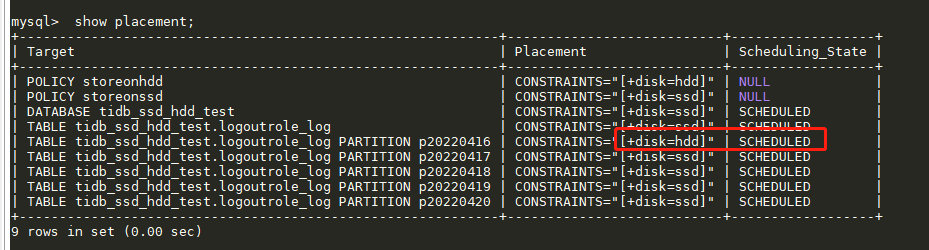
结论:
- 证明冷热数据隔离存储策略已经生效,ssd 上的数据完成迁移到 hdd 上,且 ssd 的空间得以释放,符合数据归档的目标。
静态集群冷热存储分离(无外部访问)
ssd->hdd
继续通过 flink 写入数据到 2022-04-17 分区,然后停流使集群没有外部访问流量,将此分区上 ssd 数据迁移到 hdd。
alter table tidb_ssd_hdd_test.logoutrole_log partition p20220417 placement policy storeonhdd;
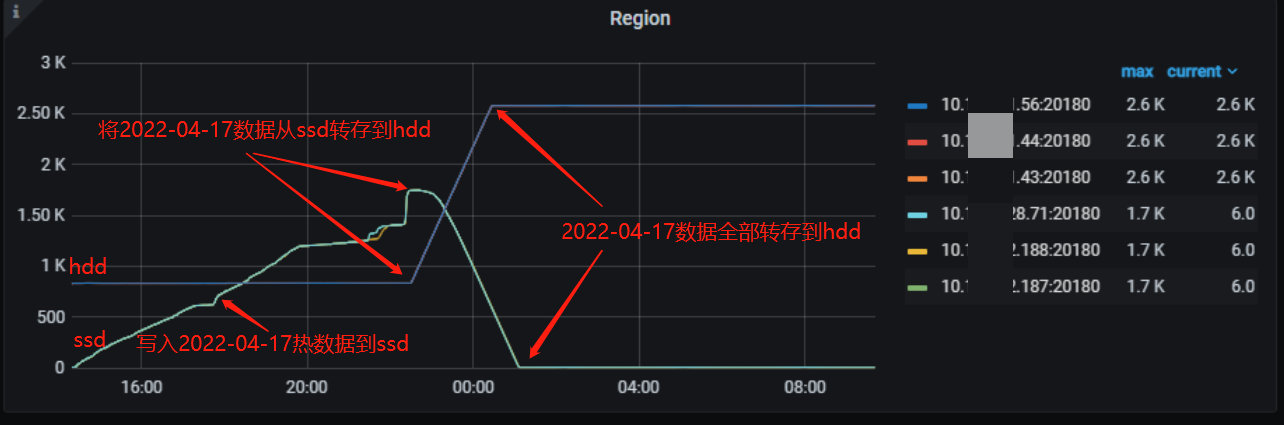
ssd 上的 region 全部迁移到 hdd 上,ssd 空间被释放,hdd 空间使用逐渐增加,迁移过程中 ssd 和 hdd 的 IO 消耗都在 5%左右,内存和网络带宽使用不变、保持平稳。 约 6 千万行 130GB 数据从 ssd 数据迁移到 hdd 大概需要 2 个小时
结论:
- 在将大规模数据从 ssd 数据迁移到 hdd 过程,集群资源消耗比较低,可以有效避免过多占用集群资源。
- 在集群没有外部访问压力时,在默认配置下,集群以每小时约 3000 万行的速度从 ssd 迁移到 hdd 节点。
hdd->ssd
在没有外部流量访问时,将数据从 hdd 迁移回 ssd,从监控图可以看到,hdd 节点的 tikv 的 leader 数、region 数在此期间都在下降,分别从 850、2500 逐渐下降直到为 0,磁盘空间也从 62GB 下降为 0,表示数据在持续迁移出 hdd 节点;

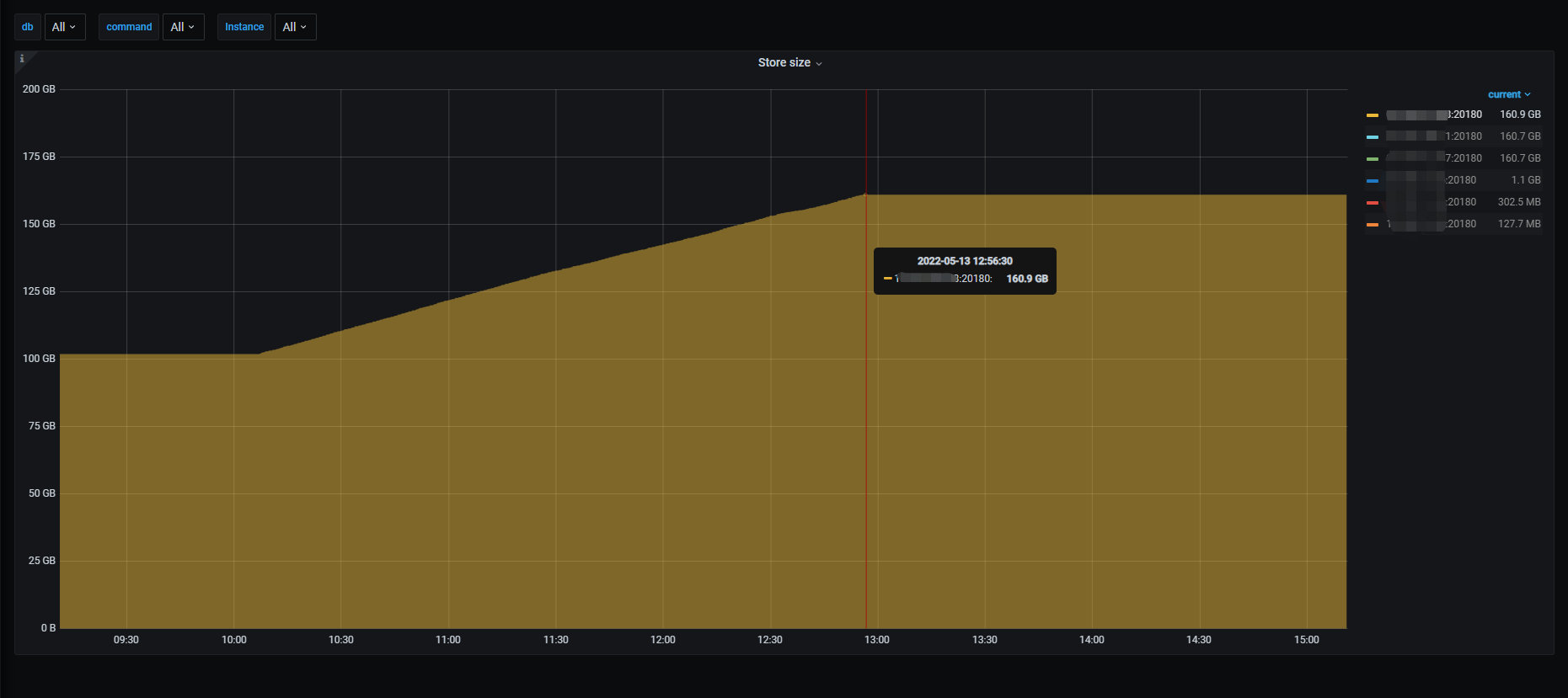
相反地,由于数据不断迁入到 ssd 中,ssd 节点的 tikv 的 leader 数、region 数在此期间都在上升,分别从 1500、4200 逐渐上升到 2200、6700,直到数据迁入完成,然后保持数量不变,ssd 的磁盘空间消耗也从 100GB 上升到 161GB。
迁移的过程中,ssd 和 hdd 节点的 IO 使用率都比较低,如下图:

结论:
- 将冷数据从 hdd 迁移至 ssd,迁移 1.7 亿行共约 200GB 数据,大约耗时 2 小时 40 分钟,平均每小时迁移 6300 万行,速度约为将热数据从 ssd 迁到 hdd 的 2 倍(每小时约 3000 万行)
- 将数据从 hdd 迁移至 ssd 的过程,不管是对 ssd 还是 hdd,其平均 IO 使用率都不高,不会占用过多集群的资源,可以认为数据迁移过程对集群正在运行的业务影响不大
热集群冷热存储分离(外部持续访问)
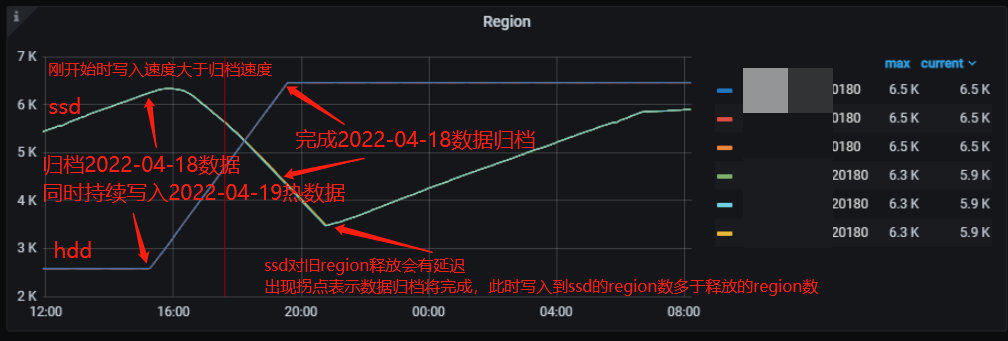
继续持续写入数据到 2022-04-18 和 2022-04-19 的 ssd 分区,然后不停流保持持续的写入压力,迁移 2022-04-18 数据从 ssd 到 hdd,观察集群表现。
#应用放置策略将2022-04-18数据从ssd归档到hdd
alter table tidb_ssd_hdd_test.logoutrole_log partition p20220418 placement policy storeonhdd;
在归档过程,flink 同时持续以 2100 的 QPS 写入热数据,期间 ssd IO 接近 100%,hdd 的 IO 消耗在 10%以下,各节点 CPU 在 500%以下,网络带宽在 200MB/s 以下,内存使用保持平稳。
从 region 数变化的角度来看:
- 在归档数据时,ssd 的 tikv region 数从 6300 下降到 3500 左右,当迁移完成后是净写入数据,此时 ssd 节点的 region 数量又持续上升;
- hdd 节点的 region 数从开始的 2600 上升到 6500 左右,随着数据迁移完成,hdd 的 region 数不再增加,一直保持 6500 不变。
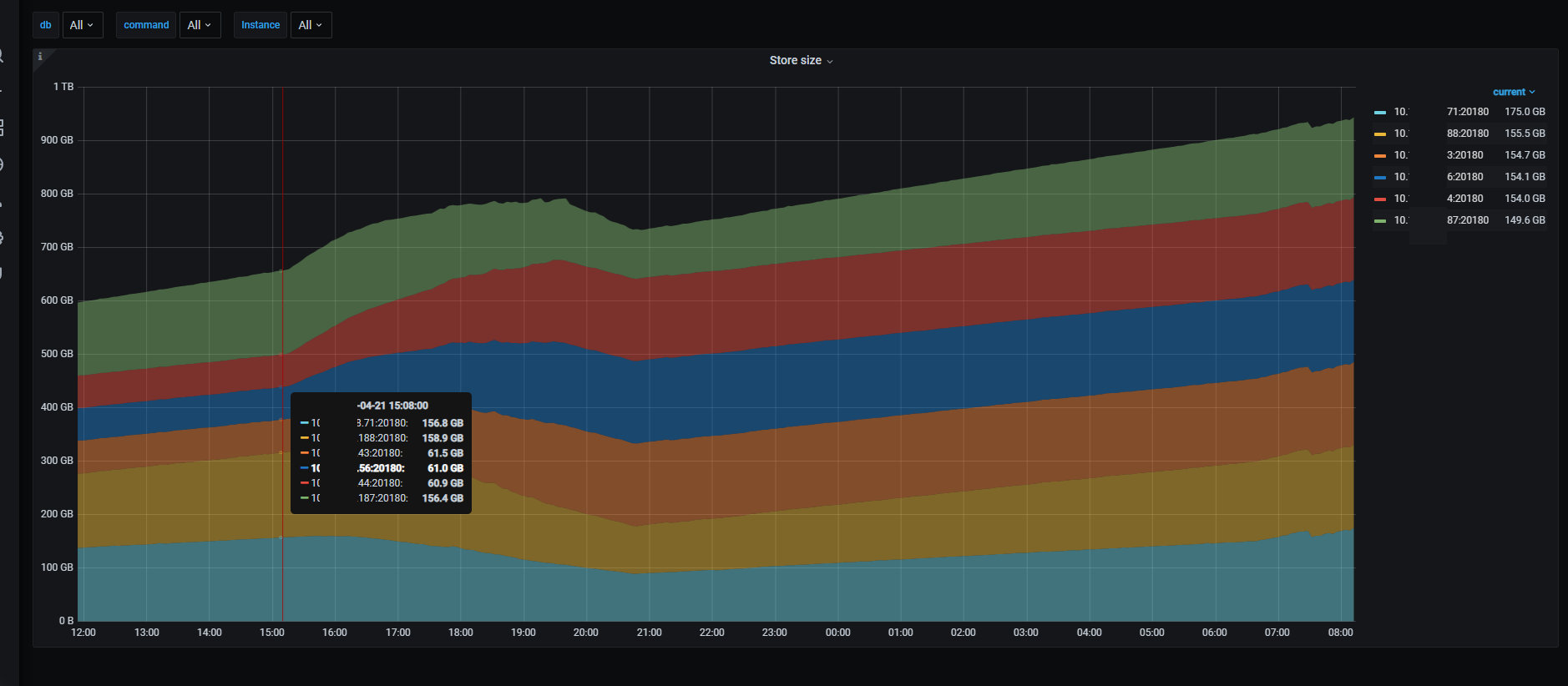
从磁盘使用空间变化的角度来看:
- 归档数据时,ssd 节点的磁盘使用空间从 152GB 下降到 88GB,当迁移完成后,此时是净写入数据,ssd 空间开始上升;
- 数据在不断写入到 hdd 节点,所以其使用空间从 61GB 上升到 154GB,随着数据迁移完成,一直保持不变
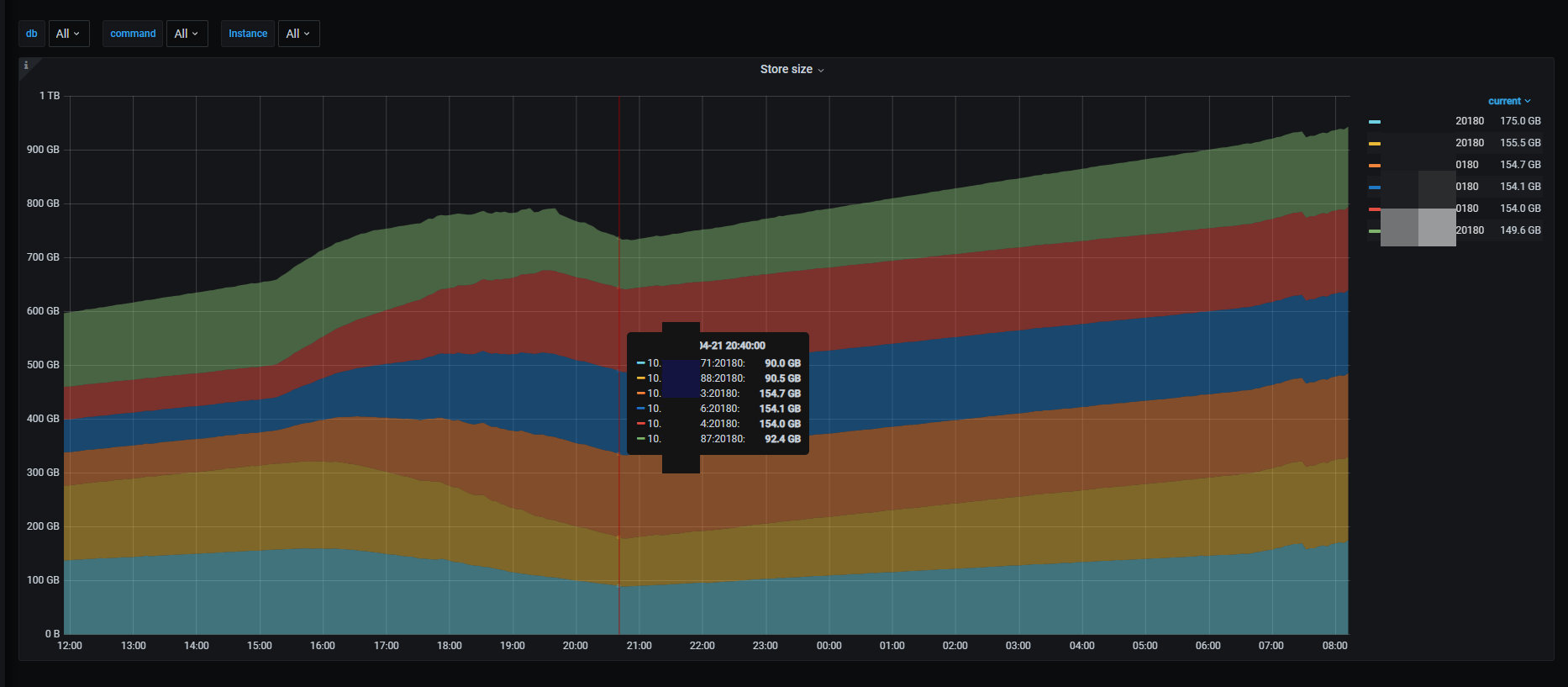
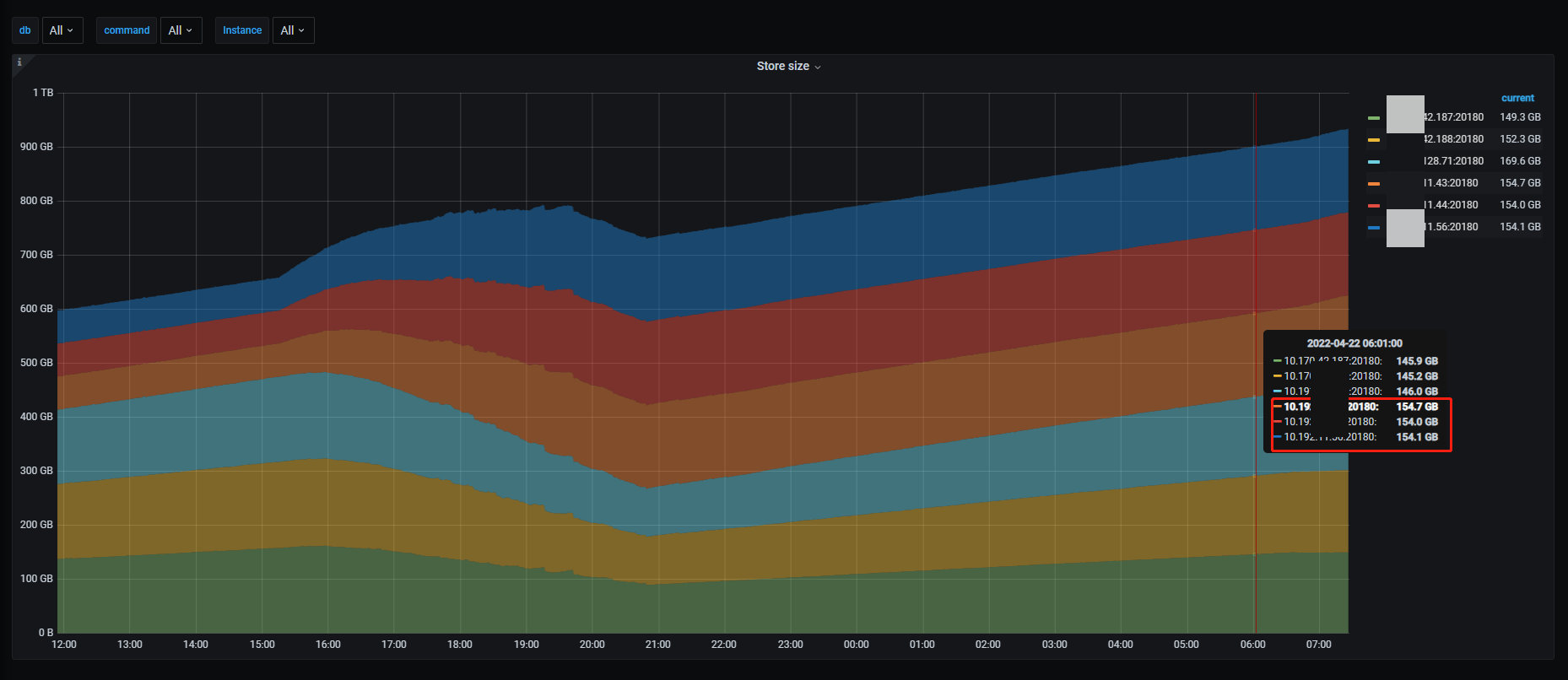
结论:
- 在有外部几乎是满 IO 的写入压力时,归档约 2 亿行、400GB 数据从 ssd 到 hdd 节点,大概需要 6 个小时,即约 3300 万行/小时,可以说冷数据的归档效率还是比较高的
- 集群后台在进行数据归档时,flink 的 sink QPS 变化不大,可以认为归档的过程对集群正常写入影响不大
归档数据补写
业务上有补全历史数据的场景,比如数据重算等,这里模拟补全历史冷数据,写入到 hdd。
- 2022-04-16 这一天的数据已经全部转存到 hdd 冷盘中。启动 flink 流,继续对 2022-04-16 分区写入数据,这些只会写 hdd,不会写入 ssd。flink 流以 2000 左右的 sink QPS 补全冷数据,hdd tikv 节点 IO 打满,SSD 的 IO 使用率比较低。
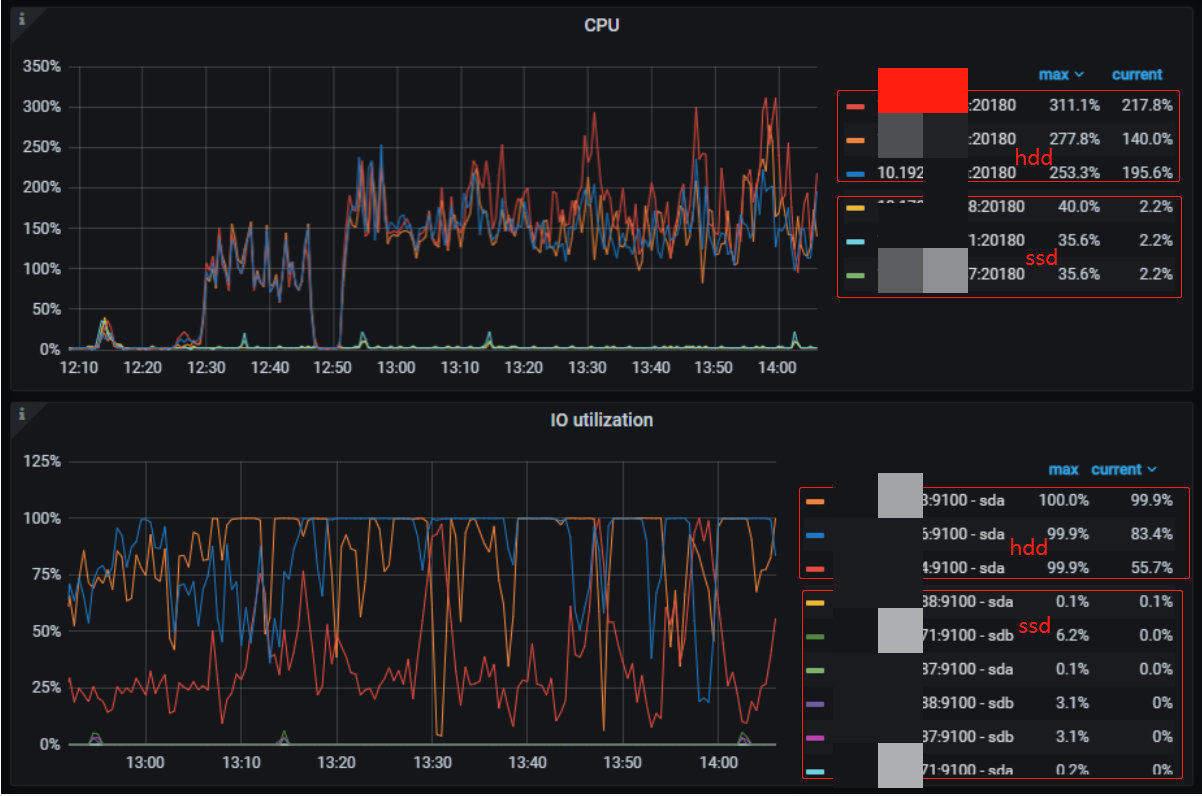
从下图可以看到,在补全冷数据的时候, hdd 节点的 region 数在不断上升,hdd tikv 的空间消耗也在不断增加,而 ssd 的空间使用和 region 数均保持不变,说明数据并不会写入 ssd 中,符合预期。
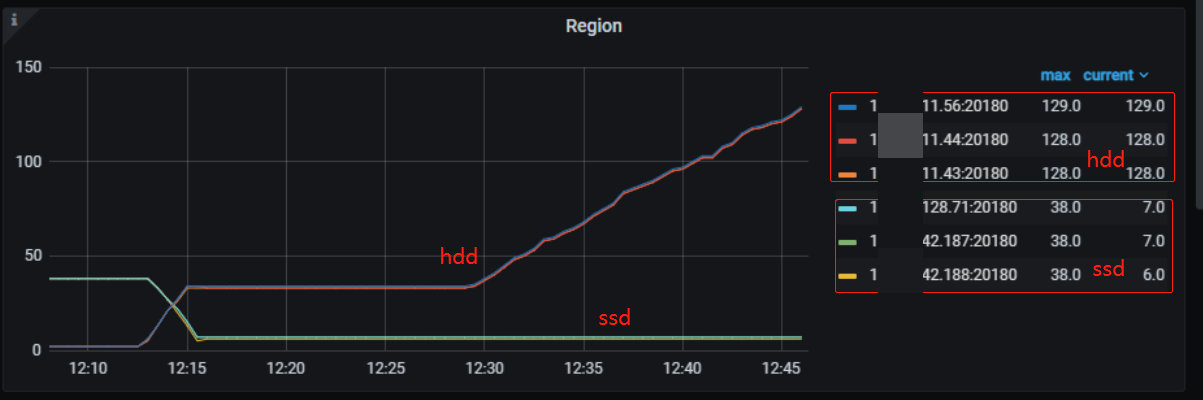
结论:
- 说明 TiDB 冷热数据分离存储功能,在补全历史冷数据的场景,即归档数据补写,数据可以正确地直接写入到 hdd,期间数据不会经过 ssd
- 补全冷数据,hdd tikv 节点 IO 打满,ssd 的 IO 使用率比较低,也说明数据不会经过 ssd
同一集群业务隔离
除了冷热数据归档外,我们线上不同的业务线通常采用一套或多套 MySQL 来管理,但因为业务多导致 MySQL 有数百个,日常的监控、诊断、版本升级、安全防护等工作对运维团队造成了巨大的压力,且随着业务规模越来越大,管理的成本不断上升。
使用 Placement rule 功能可以很容易灵活的集群共享规则。可以将不同 MySQL 上的业务迁移到同一个 TiDB 集群,实现多个不同业务的共用一个集群而底层提供物理存储隔离,有效减少大量 MySQL 的管理成本。这个也是我们接下来会继续推进优化的地方。
举例说明,业务 A和B 共享资源,降低存储和管理成本,而业务 C 和 D 独占资源,提供最高的隔离性。由于多个业务共享一套 TiDB 集群,升级、打补丁、备份计划、扩缩容等日常运维管理频率可以大幅缩减,降低管理负担提升效率。
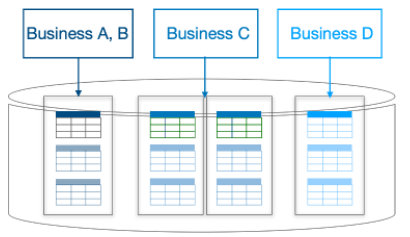
CREATE PLACEMENT POLICY 'shared_nodes' CONSTRAINTS = "[+region=shared_nodes]";
CREATE PLACEMENT POLICY 'business_c' CONSTRAINTS = "[+region=business_c]";
CREATE PLACEMENT POLICY 'business_d' CONSTRAINTS = "[+region=business_d]";
ALTER DATABASE a POLICY=shared_nodes;
ALTER DATABASE b POLICY=shared_nodes;
ALTER DATABASE c POLICY=business_c;
ALTER DATABASE d POLICY=business_d;
基于 SQL 接口的数据放置规则,你仅仅使用少数 TiDB 集群管理大量的 MySQL 实例,不同业务的数据放置到不同的 DB,并通过放置规则管理将不同 DB 下的数据调度到不同的硬件节点上,**实现业务间数据的物理资源隔离,避免因资源争抢,硬件故障等问题造成的相互干扰。**通过账号权限管理避免跨业务数据访问,提升数据质量和数据安全。在这种部署方式下,集群数量大大减小,原本的升级,监控告警设置等日常运维工作将大幅缩减,在资源隔离和性价比上达到平衡,大幅减少日常的 DBA 运维管理成本。
总结
1.冷热分离存储,降低存储成本
- TiDB 6.0 正式支持数据冷热存储分离,可以降低 SSD 使用成本。使用 TiDB 6.0 的数据放置功能,可以在同一个集群实现海量数据的冷热存储,将新的热数据存入 SSD,历史冷数据存入 HDD,降低历史归档数据存储成本。
- 将热数据从 ssd 迁移到 hdd,每小时可归档约 3000 万行,总体来看效率还是比较高的
- 分离存储过程,ssd 和 hdd 用于归档的 IO 消耗都在 10%以内,集群访问 QPS 表现平稳,对业务访问的影响较小
- 在补写冷数据到 hdd 场景,数据可正确地直接写入 hdd,不会经过 ssd。flink 补写冷数据时满 IO 每秒写入约 4000 行,每小时写入约 1500 万行。
2.业务底层物理隔离,实现同一集群不同存储
- 通过放置规则管理将不同数据库下的数据调度到不同的硬件节点上,实现业务间数据的物理资源隔离,避免因资源争抢,硬件故障等问题造成的相互干扰
- 通过账号权限管理避免跨业务数据访问,提升数据质量和数据安全。
3.合并MySQL业务,降低运维压力,提升管理效率
- 使用少数 TiDB 集群替换大量的 MySQL 实例,根据不同业务底层设置不同的物理存储隔离需求,让数据库数量大大减少,原本的升级、备份、参数设置等日常运维工作将大幅缩减,在资源隔离和性价比上达到平衡,大幅减少 DBA 日常的运维管理成本。
4.放置策略应用操作步骤
-
对已有集群应用 Placement Rules
- 将集群升级到 6.0.0 版本
- 创建默认 SSD 策略
- 打开放置策略默认开关,使得集群已有库表都默认存储在 ssd 上 (该功能依赖官方发布新版本支持)
- 目前只能用脚本 alter 全部库设置这个默认策略,如果有新增的库也需要提前进行设置
- 申请新机器并扩容新的 hdd tikv
- 创建 hdd 放置策略
- 在目标表的目标分区上指定 ssd 或 hdd 策略
- 定期将过期分区声明 hhd 放置策略
-
对新建的集群应用 Placement Rules
- 部署 6.0.0 集群版本
- 创建默认 SSD 策略
- 创建的全部库都先设置这个默认策略
- 申请新机器并扩容新的 hdd tikv
- 创建 hdd 放置策略
- 在目标表或目标分区上指定 ssd 或 hdd 策略
- 定期将过期分区声明 hhd 放置策略
以上是关于TiDB 6.0 实战分享丨冷热存储分离解决方案的主要内容,如果未能解决你的问题,请参考以下文章
HBase原理|还不知道HBase冷热分离的技术原理?看这一篇就够了!