ElasticSearch——冷热分离
Posted caoweixiong
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了ElasticSearch——冷热分离相关的知识,希望对你有一定的参考价值。
背景
最近在做订单数据存储到ElasticSearch,考虑到数据量比较大,采用冷热架构来存储,每月建立一个新索引,数据先写入到热索引,通过工具将3个月后的索引自动迁移到冷节点上。
冷热架构
官方叫法:热暖架构——“Hot-Warm” Architecture。
通俗解读:热节点存放用户最关心的热数据;温节点或者冷节点存放用户不太关心或者关心优先级低的冷数据或者暖数据。
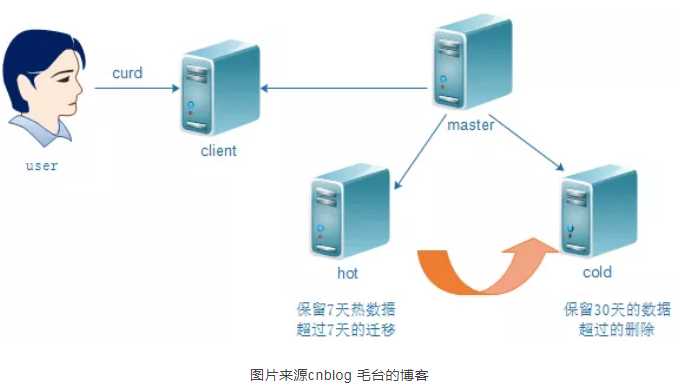
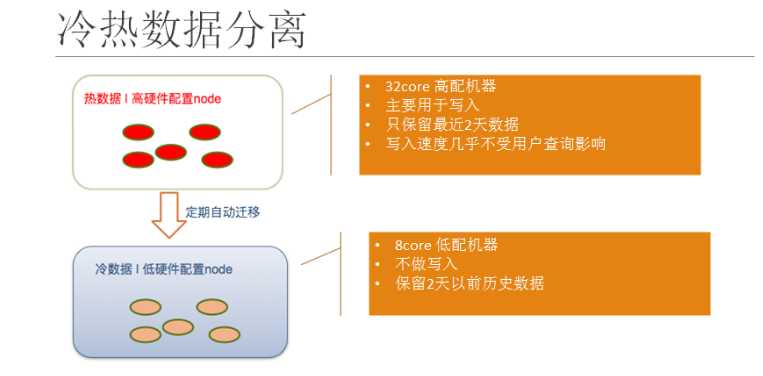
1.1 官方解读冷热架构
为了保证Elasticsearch的读写性能,官方建议磁盘使用SSD固态硬盘。然而Elasticsearch要解决的是海量数据的存储和检索问题,海量的数据就意味需要大量的存储空间,如果都使用SSD固态硬盘成本将成为一个很大的问题,这也是制约许多企业和个人使用Elasticsearch的因素之一。为了解决这个问题,Elasticsearch冷热分离架构应运而生。
冷热架构是一项十分强大的功能,能够让您将 Elasticsearch 部署划分为“热”数据节点和“冷”数据节点。
- 热数据节点处理所有新输入的数据,并且存储速度也较快,以便确保快速地采集和检索数据。
- 冷节点的存储密度则较大,如需在较长保留期限内保留日志数据,不失为一种具有成本效益的方法。
将这两种类型的数据节点结合到一起后,您便能够有效地处理输入数据,并将其用于查询,同时还能在节省成本的前提下在较长时间内保留数据。此架构对日志用例来说尤其大有帮助,因为在日志用例中,人们的大部分精力都会专注于近期的日志(例如最近两周),而较早的日志(由于合规性或者其他原因仍需要保留)则可以接受较慢的查询时间。
1.2 典型应用场景
一句话:在成本有限的前提下,让客户关注的实时数据和历史数据硬件隔离,最大化解决客户反应的响应时间慢的问题。业务场景描述:
每日增量6TB日志数据,高峰时段写入及查询频率都较高,集群压力较大,查询ES时,常出现查询缓慢问题。
- ES集群的索引写入及查询速度主要依赖于磁盘的IO速度,冷热数据分离的关键为使用SSD磁盘存储热数据,提升查询效率。
- 若全部使用SSD,成本过高,且存放冷数据较为浪费,因而使用普通SATA磁盘与SSD磁盘混搭,可做到资源充分利用,性能大幅提升的目标。
实现原理
借助 Elasticsearch的分片分配策略,确切的说是:
- 第一:集群节点层面支持规划节点类型,这是划分热暖节点的前提。
具体方式是在elasticsearch.yml文件中增加以下配置:
node.attr.{attribute}: {value}
其中attribute为用户自定义的任意标签名,value为该节点对应的该标签的值,例如对于冷热分离,可以使用如下设置
node.attr.temperature: hot //热节点 node.attr.temperature: cold //冷节点
- 第二:索引层面支持将数据路由到给定节点,这为数据写入冷、热节点做了保障。
具体方式是在创建模板或索引时指定属性:
index.routing.allocation.include.{attribute} //表示索引可以分配在包含多个值中其中一个的节点上。
index.routing.allocation.require.{attribute} //表示索引要分配在包含索引指定值的节点上(通常一般设置一个值)。
index.routing.allocation.exclude.{attribute} //表示索引只能分配在不包含所有指定值的节点上。
实现方案
1.1 集群设计:
| 节点名称 | 服务器类型 | 存储数据 |
| es-master1 | 4C 16G 1T SATA | 元数据 |
| es-master2 | ||
| es-master3 | ||
| es-hot1 | 16C 64G 1T SSD | Hot |
| es-hot2 | ||
| es-hot3 | ||
| es-cold1 | 8C 32G 5T SATA | Cold |
| es-cold2 |
2.1 配置Master节点
-
Master1节点配置(其他节点配置类似)
[root@es-master1 ~]# cd /etc/elasticsearch/ [root@es-master1 elasticsearch]# vim elasticsearch.yml cluster.name: linuxplus node.name: es-master1.linuxplus.com node.attr.rack: r6 node.master: true node.data: false path.data: /var/lib/elasticsearch path.logs: /var/log/elasticsearch network.host: 0.0.0.0 discovery.zen.ping.unicast.hosts: ["es-master1.linuxplus.com:9300","es-master2.linuxplus.com:9300","es-master3.linuxplus.com:9300","es-hot1.linuxplus.com:9300","es-hot2.linuxplus.com:9300","es-hot3.linuxplus.com:9300","es-stale1.linuxplus.com:9300","es-stale2.linuxplus.com:9300"] discovery.zen.minimum_master_nodes: 1 bootstrap.system_call_filter: false
2.2 配置Hot节点
-
Hot1节点配置(其他节点配置类似)
[root@es-hot1 elasticsearch]# vim elasticsearch.yml cluster.name: linuxplus node.name: es-hot1.linuxplus.com # 提示:自行修改其他节点的名称 node.attr.rack: r1 node.master: false node.data: true path.data: /var/lib/elasticsearch path.logs: /var/log/elasticsearch network.host: 10.10.10.24 # 提示:自行修改其他节点的IP discovery.zen.ping.unicast.hosts: ["es-master1.linuxplus.com:9300","es-master2.linuxplus.com:9300","es-master3.linuxplus.com:9300"] discovery.zen.minimum_master_nodes: 1 bootstrap.system_call_filter: false node.attr.hotwarm_type: hot # 标识为热数据节点 [root@es-hot1 elasticsearch]# /etc/init.d/elasticsearch start
2.3 配置Cold节点
-
Cold1节点配置(其他节点配置类似)
[root@es-stale1 elasticsearch]# vim elasticsearch.yml cluster.name: linuxplus node.name: es-stale1.linuxplus.com # 提示:自行修改其他节点的名称 node.attr.rack: r1 node.master: false node.data: true path.data: /var/lib/elasticsearch path.logs: /var/log/elasticsearch network.host: 10.10.10.27 # 提示:自行修改其他节点的IP discovery.zen.ping.unicast.hosts: ["es-master1.linuxplus.com:9300","es-master2.linuxplus.com:9300","es-master3.linuxplus.com:9300"] discovery.zen.minimum_master_nodes: 1 bootstrap.system_call_filter: false node.attr.hotwarm_type: cold # 标识为冷数据节点 [root@es-stale1 elasticsearch]# /etc/init.d/elasticsearch start
3.1 数据写入
- 方案一:通过模板指定冷热数据节点
PUT _template/order_template
{ "index_patterns": "order_*", "settings": {
"index.routing.allocation.require.hotwarm_type": "hot", # 指定默认为热数据节点
"index.number_of_replicas": "0"
} }
注:以【order_】开头索引命名的,都将其数据放到hot节点上
- 方案二:通过索引指定冷热数据节点
PUT /order_2019-12 { "settings": { "index.routing.allocation.require.hotwarm_type": "hot", # 指定为热数据节点 "number_of_replicas": 0 } }
4.1 数据迁移至冷节点
- 方案一:修改索引路由为:cold
ES看到有新的标记就会将这个索引自动迁移到冷数据节点中
#在kibana里操作: PUT /order_2019-12/_settings { "settings": { "index.routing.allocation.require.hotwarm_type": "cold" # 指定数据存放到冷数据节点 } }
#通过shell脚本将Hot数据(保留7天)迁移到cold
#!/bin/bash
Time=$(date -d "1 week ago" +"%Y.%m.%d") Hostname=$(hostname) arr=("tomcat" "nginx-access" "nginxtcp" "nginxerror" "order") for var in ${arr[@]} do curl -H "Content-Type: application/json" -XPUT http://$Hostname:9200/$var-$Time/_settings?pretty -d‘ { "settings": { "index.routing.allocation.require.hotwarm_type": "cold" # 指定数据存放到冷数据节点 } }‘ done
- 方案二:借助curator定期迁移数据
随着时间发展,当前数据会成为历史数据。历史数据要自动切换到普通磁盘的节点存储,可以借助curator实现。
步骤1:定义cuator.yml,填写Elasticsearch集群配置信息。
步骤2:定义action.yml。
actions: 1: action: allocation description: >- Apply shard allocation routing to ‘require‘ ‘tag=cold‘ for hot/cold node setup for logstash- indices older than 3 days, based on index_creation date options: key: hotwarm_type value: warm allocation_type: require disable_action: false filters: - filtertype: pattern kind: prefix value: logs_ - filtertype: age source: name direction: older timestring: "%Y-%m-%d" unit: days unit_count: 3
应用
因为按时间分了多个索引,查询的时候可以跨多个索引进行查询,打分、排序、分页和搜单个索引没什么区别。
参考:
铭毅天下:干货 | Elasticsearch 冷热集群架构实战
https://blog.51cto.com/stuart/2335120
https://cloud.tencent.com/developer/article/1544261
https://elasticsearch.cn/article/6127#tip3
以上是关于ElasticSearch——冷热分离的主要内容,如果未能解决你的问题,请参考以下文章