Python 自动化办公-玩转浏览器
Posted 朝阳区靓仔_James
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Python 自动化办公-玩转浏览器相关的知识,希望对你有一定的参考价值。
日常工作中,我们不可能避免得使用浏览器来完成一些工作,Python 也有不少浏览器自动化的工具,我用过 selenium、splinter、playwright,最终还是选择了微软的 playwright,之所以选择它,是因为它可以自动安装浏览器,不需要手动下载浏览器的驱动程序,比如 chromedriver,这样写出来的自动化工具很容易移植到其他系统中运行。
Playwright 可通过单个 API 自动执行 Chromium,Firefox 和 WebKit浏览器,支持无头浏览器(headless),Linux、macOS、Windows 下均可以使用,Playwright提供的自动化技术是绿色的,功能强大,稳定且速度快。你可以充分发挥空间,想象它可以实现什么样的功能。
安装: 官方文档 playwright.dev/python/docs…
pip install playwright
playwright install
playwright install 将会安装 Chromium,Firefox 和 WebKit 浏览器的二进制文件,非常方便,需要 Python 3.7 及以上版本才行。
先来一段示例代码:
from playwright.sync_api import sync_playwright
with sync_playwright() as p:
browser = p.chromium.launch()
page = browser.new_page()
page.goto("http://playwright.dev")
print(page.title())
browser.close()
运行程序后,程序会自动打开浏览器,访问 playwright.dev,并打印网站的标题。
自动生成代码
Playwright 最吸引我的地方在于它可以自己记录你对浏览器的操作,并将这些操作生成可以执行的代码,这简直就是神器,大大提升了浏览器自动化的效率。生成代码只需要执行
python -m playwright codegen baidu.com
可以生成如下代码:
from playwright.sync_api import Playwright, sync_playwright
def run(playwright: Playwright) -> None:
browser = playwright.chromium.launch(headless=False)
context = browser.new_context()
# Open new page
page = context.new_page()
# Go to https://www.baidu.com/
page.goto("https://www.baidu.com/")
# Click input[name="wd"]
page.click("input[name=\\"wd\\"]")
# Fill input[name="wd"]
page.fill("input[name=\\"wd\\"]", "playwright ")
# Press CapsLock
page.press("input[name=\\"wd\\"]", "CapsLock")
# Fill input[name="wd"]
page.fill("input[name=\\"wd\\"]", "playwright 教程")
# Press Enter
# with page.expect_navigation(url="https://www.baidu.com/s?ie=utf-8&f=8&rsv_bp=1&rsv_idx=1&tn=baidu&wd=playwright%20%E6%95%99%E7%A8%8B&fenlei=256&rsv_pq=880cdb05002fe1ed&rsv_t=19abqiURFrqQT3i6%2F84nvsfVrJlI%2B1T6XbVpQkOap78JGssznOJ4%2FVasRzE&rqlang=cn&rsv_dl=tb&rsv_enter=1&rsv_sug3=23&rsv_sug1=20&rsv_sug7=100&rsv_sug2=0&rsv_btype=i&inputT=6608&rsv_sug4=11435&rsv_jmp=fail"):
with page.expect_navigation():
page.press("input[name=\\"wd\\"]", "Enter")
# Click text=Playwright-python 教程_天下任我行-CSDN博客
# with page.expect_navigation(url="https://blog.csdn.net/lb245557472/article/details/111572119"):
with page.expect_navigation():
with page.expect_popup() as popup_info:
page.click("text=Playwright-python 教程_天下任我行-CSDN博客")
page1 = popup_info.value
# Click text=×
page1.click("text=×")
# ---------------------
context.close()
browser.close()
with sync_playwright() as playwright:
run(playwright)
如何与浏览器的元素进行交互
先熟悉一些概念
浏览器
浏览器就是指浏览器的一个实例,可以是 Chromium, Firefox 或 WebKit,Playwright 脚本通常从打开一个浏览器开始,以关闭浏览器作为结束,可以使用无头浏览器模式,也就是说虽然打开了浏览器,但是看不到浏览器启动和操作的过程,这是隐藏的。
from playwright.sync_api import sync_playwright
with sync_playwright() as p:
browser = p.chromium.launch(headless=False)
browser.close()
浏览器上下文
浏览器上下文是浏览器实例中孤立的匿名会话。浏览器上下文创建速度快且价格低廉。我们建议在自己的新浏览器上下文中运行每个测试场景,以便在测试之间隔离浏览器状态。浏览器上下文还可用于模拟涉及移动设备、权限、区域设置和配色方案的多页场景。
browser = playwright.chromium.launch()
context = browser.new_context()
页面和框架
浏览器上下文可以有多个页面。页面是指浏览器上下文中的单个选项卡或弹出窗口。它应该用于导航到 URL 并与页面内容交互。
page = context.new_page()
# 显式导航,类似于在浏览器中输入URL。
page.goto('http://example.com')
# 填写输入。
page.fill('#search', 'query')
# 点击链接隐式导航。
page.click('#submit')
# 期待一个新的网址。
print(page.url)
# 页面可以从脚本导航 - 剧作家将接取。
# window.location.href = 'https://example.com'
一个页面可以附加一个或多个 Frame 对象。每个页面都有一个主框架,假设页面级交互(如点击)在主框架中运行。
一个页面可以有附加的附加框架和 iframe html 标签。可以访问这些 iframe:
# Get frame using the frame's name attribute
frame = page.frame('frame-login')
# Get frame using frame's URL
frame = page.frame(url=r'.*domain.*')
# Get frame using any other selector
frame_element_handle = page.query_selector('.frame-class')
frame = frame_element_handle.content_frame()
# Interact with the frame
frame.fill('#username-input', 'John')
选择器
选择器就是选取 html 页面内元素的工具。
Playwright 可以使用 CSS 选择器、XPath 选择器、id 等 HTML 属性、data-test-id 甚至文本内容搜索元素。
您可以显式指定您正在使用的选择器引擎,或让 Playwright 检测到它。
Playwright 的选择器是非常直观好用的,在这里了解更多关于选择器和选择器引擎的信息。
实现视频网站的自动播放
以下是简单的打开视频网站,并通过刷新浏览器达到感知视频播放完毕的代码实现。
from playwright.sync_api import sync_playwright
import re, sys
import progressbar
from log import logger
from urllib.parse import urlparse
import time
from config import chromium, browser_path
current_milli_time = lambda: int(round(time.time() * 1000))
class AutoLearning(object):
@staticmethod
def get_total_seconds(time_str):
hour, minute, seconds = 0, 0, 0
time = [int(i) for i in time_str.split(":")]
if len(time) == 2:
minute, seconds = time
elif len(time) == 1:
seconds = time[0]
elif len(time) == 3:
hour, minute, seconds = time
else:
pass
return hour * 60 * 60 + minute * 60 + seconds
def __init__(self, username, passwd, base_url, key=None):
self.username = username
self.passwd = passwd
urlparseObj = urlparse(base_url)
self.base_url = f"urlparseObj.scheme://urlparseObj.hostname"
self.hostname = urlparseObj.hostname
self.sync_playwright = sync_playwright()
self.playwright = self.sync_playwright.start()
if chromium:
self.browser = self.playwright.chromium.launch(executable_path=browser_path, headless=False)
else:
self.browser = self.playwright.firefox.launch(executable_path=browser_path,headless=False)
self.context = self.browser.new_context()
self.current_page = self.context.new_page()
self.cookies =
self.corp_code = "default"
self.map_url = f"self.base_url/els/html/index.parser.do?id=0007"
self.headers =
"Host": self.hostname,
"User-Agent": "Mozilla/5.0 (Macintosh; Intel Mac OS X 11_2_2) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/89.0.4389.114 Safari/537.36",
"Origin": self.base_url,
self.eln_session_id = ""
def __del__(self):
self.context.close()
self.browser.close()
self.sync_playwright.__exit__()
def login(self):
logger.info(self.base_url)
self.current_page.goto(url=self.base_url)
page = self.current_page
# self.context.set_default_timeout(6000)
try:
# Click [placeholder="请输入用户名"]
page.click('[name="loginName"]')
# Fill [placeholder="请输入用户名"]
page.fill('[name="loginName"]', self.username)
# Click [placeholder="请输入密码"]
page.click('[name="password"]')
# Fill [placeholder="请输入密码"]
page.fill('[name="password"]', self.passwd)
# Click text=登录
page.click("input.login_Btn")
print("如有验证码,请在浏览器上手动登陆")
# Click text=继续登录
# if page.is_visible("text=继续登录", timeout=15000):
page.click("text=继续登录")
except Exception:
print("请在浏览器上手动登陆")
time.sleep(3)
while True:
try:
if (
page.is_visible("text='课程中心'", timeout=3000)
or page.is_visible("text='个人中心'", timeout=3000)
or page.is_visible("text='学习中心'", timeout=3000)
):
logger.info("登陆成功")
self.current_page = page
break
except Exception:
print("请在浏览器上手动登陆")
time.sleep(5)
def learn_course_from_learn_map(self, which_one_to_learn=1, skip_num=0):
logger.info("learn_course_from_learn_map begin.")
self.current_page.goto(self.map_url)
self.current_page.wait_for_selector(
f":nth-match(div.track-list-tit,which_one_to_learn)"
)
item = self.current_page.query_selector(
f":nth-match(div.track-list-tit,which_one_to_learn)"
)
link = self.current_page.query_selector(
f":nth-match(a.track-list-linktoName,which_one_to_learn)"
)
item_title = item.inner_text()
link_title = link.inner_text()
if "学习进度:100%" in item_title:
logger.info(f"link_title 已经学习完成,退出")
return
logger.info(f"开始学习 item_title")
link.click()
self.current_page.wait_for_selector("a.innercan.goCourseByStudy")
courses = self.current_page.query_selector_all("a.innercan.goCourseByStudy")
for course in courses[skip_num:]:
time.sleep(2)
with self.current_page.expect_popup() as popup_info:
course.click()
new_page = popup_info.value
new_page.wait_for_load_state(timeout=60000)
time.sleep(1)
h3 = new_page.query_selector("h3.cs-test-title")
if h3:
logger.info("本课程视频已播放完毕,无需播放")
if h3.inner_text() == "课程评估":
self.evaluation(new_page)
new_page.close()
continue
course_item =
"courseId": course.get_attribute("id"),
"courseName": course.get_attribute("title"),
logger.info(
f"正在播放 course_item['courseName'],courseId = course_item['courseId']"
)
if new_page.is_visible("iframe.url-course-content"):
self.play_single_course2(new_page)
if new_page.is_visible("text='确定'",timeout = 3000):
new_page.click("text='确定'")
if new_page.is_visible("a:has-text('下一步')"):
new_page.click("a:has-text('下一步')")
self.evaluation(new_page)
new_page.close()
logger.info("学习地图任务已完成")
def play_single_course2(self, page):
"""
一分屏、二分屏播放
"""
page.wait_for_selector("time.cl-time")
page.wait_for_selector("id=studiedTime")
time.sleep(5)
total_time_ele = page.query_selector("time.cl-time")
total_minutes = int(0 if total_time_ele.inner_text() == '' else total_time_ele.inner_text())
alread_time_ele = page.query_selector("id=studiedTime")
alread_minutes = int(0 if alread_time_ele.inner_text() == '' else alread_time_ele.inner_text())
chapters = page.query_selector_all("a.scormItem-no.cl-catalog-link.cl-catalog-link-sub.item-no")
if len(chapters) > 0:
logger.info(f"本次需要播放 len(chapters) 节")
chapters[0].click()
logger.info(f"正在播放 chapters[0].get_attribute('title') 总共需要时间 total_minutes 分钟")
bar = None
if sys.platform == "win32":
bar = progressbar.bar.ProgressBar(max_value=total_minutes)
else:
bar = progressbar.ProgressBar(max_value=total_minutes)
bar.update(alread_minutes)
wait_count = 0
while True:
time.sleep(60)
wait_count += 1
if wait_count >= 7:
page.reload()
wait_count = 0
if wait_count % 3 == 0:
chapters = page.query_selector_all("a.scormItem-no.cl-catalog-link.cl-catalog-link-sub.item-no")
if len(chapters) > 0:
logger.info(f"本次需要播放 len(chapters) 节")
chapters[0].click()
logger.info(f"正在播放 chapters[0].get_attribute('title') 总共需要时间 total_minutes 分钟")
page.wait_for_selector("id=studiedTime")
alread_time_ele = page.query_selector("id=studiedTime")
alread_minutes = int(0 if alread_time_ele.inner_text() == '' else alread_time_ele.inner_text())
if page.is_visible("a:has-text('下一步')"):
break
bar.update(alread_minutes)
time.sleep(1)
bar.update(total_minutes)
logger.info(f"本页视频已播放完成")
if __name__ == "__main__":
auto = AutoLearning(username='****', passwd='*', base_url='http://*****.net')
auto.login()
auto.learn_course_from_learn_map(which_one_to_learn=1, skip_num=0)
time.sleep(100)
关于Python技术储备
学好 Python 不论是就业还是做副业赚钱都不错,但要学会 Python 还是要有一个学习规划。最后大家分享一份全套的 Python 学习资料,给那些想学习 Python 的小伙伴们一点帮助!
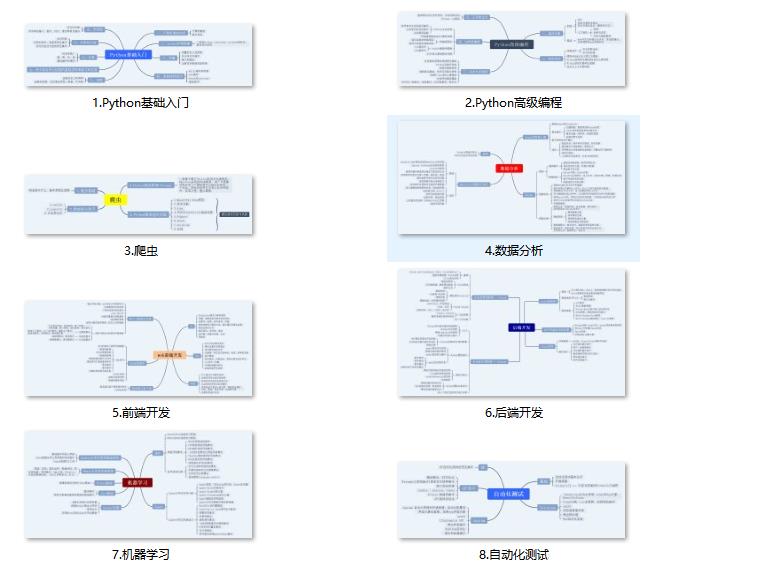
一、Python所有方向的学习路线
Python所有方向路线就是把Python常用的技术点做整理,形成各个领域的知识点汇总,它的用处就在于,你可以按照上面的知识点去找对应的学习资源,保证自己学得较为全面。
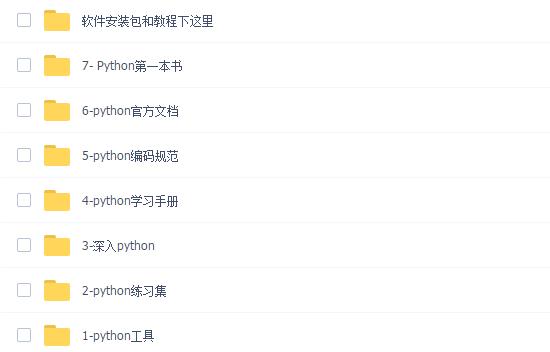
二、学习软件
工欲善其事必先利其器。学习Python常用的开发软件都在这里了,给大家节省了很多时间。
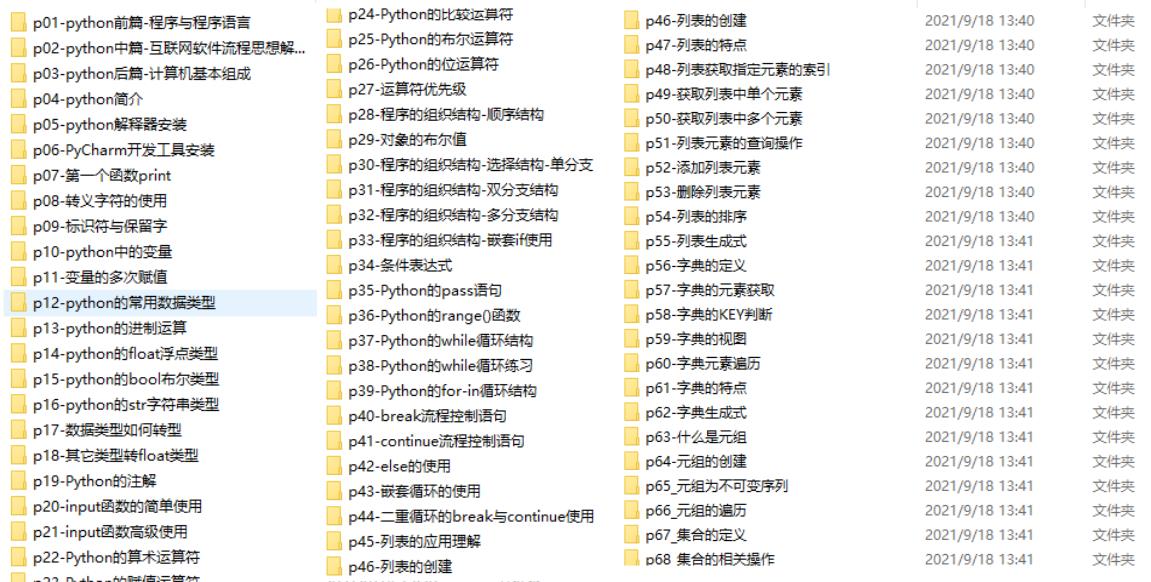
三、入门学习视频
我们在看视频学习的时候,不能光动眼动脑不动手,比较科学的学习方法是在理解之后运用它们,这时候练手项目就很适合了。
四、实战案例
光学理论是没用的,要学会跟着一起敲,要动手实操,才能将自己的所学运用到实际当中去,这时候可
以上是关于Python 自动化办公-玩转浏览器的主要内容,如果未能解决你的问题,请参考以下文章
Python自动化办公--Pandas玩转Excel数据分析
python自动化高效办公第二期,带你项目实战{excel数据处理批量化生成word模板pdf和ppt等自动化操作}
python自动化高效办公第二期,带你项目实战{数据可视化发送邮件(定时任务监控)python聊天机器人(基于微信钉钉)}
python自动化高效办公第二期,带你项目实战{数据可视化发送邮件(定时任务监控)python聊天机器人(基于微信钉钉)}