PgRouting求解大数据量最短路径
Posted 言成言成啊
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了PgRouting求解大数据量最短路径相关的知识,希望对你有一定的参考价值。

实际工作中的一个场景,类似于要做一个像地图那样,指定起终点,给出所有可行路线,本来是自己实现的,使用图的深度优先算法,结果由于数据量太大了,直接把内存算崩了。我也知道可以大而化小、分而治之、小则建立关系,可惜这样一个好的数据结构,我搞不出来。最终不得已,选用pgrouting作为替代品,但也跟原需求不太符合,这个是个求最优的方式。
唉,不过是一个离了开源啥也干不了的废物罢了。
也许,这才是许许多多CRUD码农,亟待突破的瓶颈!
所以,努力学习吧!
首先要有一个postgresql数据库,并开启postgis与pgrouting扩展,这里不多赘述!查看具体的安装过程。
pgRouting通过osm2pgrouting加载osm地图数据
pgr_dijkstra — pgRouting Manual (3.3)
pgrouting - 如何修复 pgr_dijkstra 错误,查询必须返回列 ‘id’、‘source’、‘target’ 和 ‘cost’? - 地理信息系统堆栈交换
postgresql - 如何编写一个不返回任何内容的 postgres 存储过程? - 堆栈溢出
common table expression - PostgreSQL: Query has no destination for result data - Stack Overflow
返回NULL的行级触发器导致错误:查询没有结果数据的目的地 - Thinbug
一、导入OSM数据
开源地图导出 | OpenStreetMap,通过地图导出自定义的位置信息。
进入Linux,下载地图信息,并导入信息。
# 忽略证书下载后重命名为map.osm
wget https://www.openstreetmap.org/api/0.6/map?bbox=116.3849,39.9093,116.3969,39.9226 -O map.osm --no-check-certificate
# 导入数据
osm2pgrouting -f 地图数据 -h 数据库host -U 数据库用户名 -d 数据库名称 -p 数据库端口 -W 数据库密码 --conf=/usr/share/osm2pgrouting/mapconfig_for_cars.xml rm 地图数据
导入后的输出信息如下
[root@rollback ~]# osm2pgrouting -f map.osm -h 192.168.10.10 -U pgrouting -d pgrouting_test -p 5432 -W meethigher --conf=/usr/share/osm2pgrouting/mapconfig_for_cars.xml rm map.osm
Execution starts at: Wed Apr 27 16:11:47 2022
***************************************************
COMMAND LINE CONFIGURATION *
***************************************************
Filename = map.osm
Configuration file = /usr/share/osm2pgrouting/mapconfig_for_cars.xml
host = 192.168.10.10
port = 5432
dbname = pgrouting_test
username = pgrouting
schema=
prefix =
suffix =
Don't drop tables
Don't create indexes
Don't add OSM nodes
***************************************************
Testing database connection: pgrouting_test
database connection successful: pgrouting_test
Connecting to the database
connection success
Creating tables...
TABLE: ways_vertices_pgr created ... OK.
TABLE: ways created ... OK.
TABLE: pointsofinterest created ... OK.
TABLE: configuration created ... OK.
Opening configuration file: /usr/share/osm2pgrouting/mapconfig_for_cars.xml
Parsing configuration
Exporting configuration ...
- Done
Counting lines ...
- Done
Opening data file: map.osm total lines: 78998
Parsing data
End Of file
Finish Parsing data
Adding auxiliary tables to database...
Export Ways ...
Processing 4493 ways:
[**************************************************|] (100%) Total processed: 4493 Vertices inserted: 174 Split ways inserted 172
Creating indexes ...
Processing Points of Interest ...
#########################
size of streets: 4493
Execution started at: Wed Apr 27 16:11:47 2022
Execution ended at: Wed Apr 27 16:11:47 2022
Elapsed time: 0.459 Seconds.
User CPU time: -> 0.16 seconds
#########################
推荐使用dbeaver打开,可以直接查看地图数据,也是基于OpenStreetMap的。
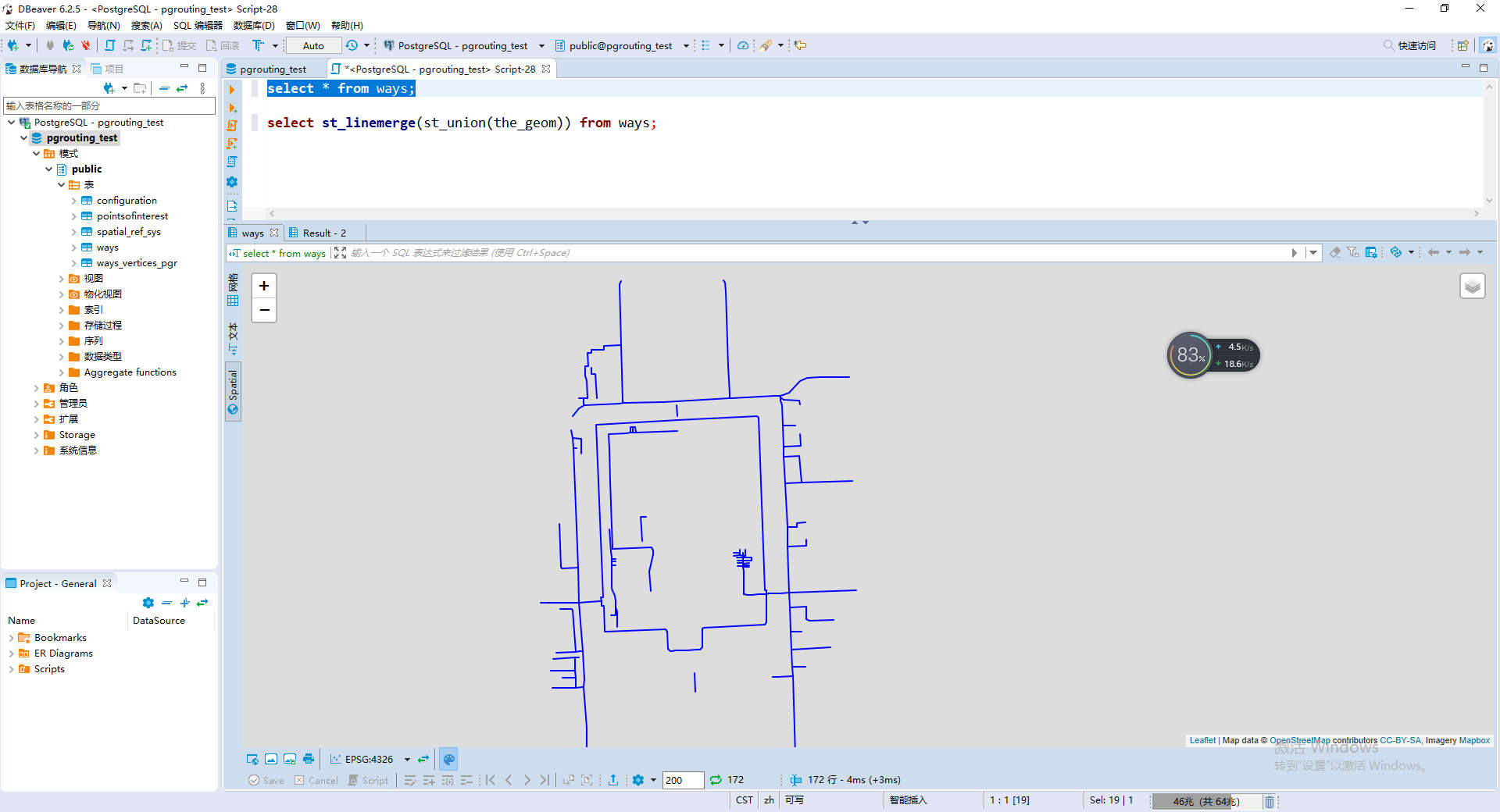
因为OpenStreetMap下载的数据,本身已经经过拓扑处理了,所以就可以直接进行查询。
-- 函数使用说明
pgr_dijkstra(Edges SQL, 起点编号, 终点编号 [, directed])
-- 使用dijkstra查询最短路径
SELECT * FROM pgr_dijkstra(
'SELECT gid as id, source, target, cost FROM ways',
30,56
);
起点编号source和终点编号source是pgrouting维护的。通过dbeaver可以直观的看出起终点号。

二、Dijkstra最短路径
使用自己创建的数据库,来体验下整个流程。
-- 删表
drop table if exists xiangwan;
-- 建表,source、target、cost是pgrouting必需的字段
-- 拉跨帕瓦,顶碗人在哪里?
create table xiangwan ( id int, roadName varchar, region geometry, source int, target int, cost float )
-- 创建索引,不然巨慢
create index if not exists pgr_source_idx on xiangwan("source");
create index if not exists pgr_target_idx on xiangwan("target");
-- 导入数据
insert into xiangwan ("id", "roadname", "region") values ('1', '我爱向晚1', 'LINESTRING(116.403245 39.927884,116.403317 39.926542)');
insert into xiangwan ("id", "roadname", "region") values ('2', '我爱向晚2', 'LINESTRING(116.403317 39.926542,116.400352 39.924245)');
insert into xiangwan ("id", "roadname", "region") values ('3', '我爱向晚3', 'LINESTRING(116.403317 39.926542,116.406676 39.925186)');
insert into xiangwan ("id", "roadname", "region") values ('4', '我爱向晚4', 'LINESTRING(116.400352 39.924245,116.403658 39.920856)');
insert into xiangwan ("id", "roadname", "region") values ('5', '我爱向晚5', 'LINESTRING(116.406676 39.925186,116.403658 39.920856)');
insert into xiangwan ("id", "roadname", "region") values ('6', '我爱向晚6', 'LINESTRING(116.403658 39.920856,116.403586 39.919113)');
-- 计算更新权值,权值的计算方法有很多种,这里就取线的距离
update xiangwan set cost = st_length(region) where cost is null;
-- 更新拓扑图,执行完毕后,再去看表里的source、target已经根据误差自动进行编号了。
select pgr_createTopology('xiangwan',0.000001,'region','id','source','target');
-- 具体字段说明
-- 参数1:表名
-- 参数2:误差缓冲值,两个点的距离在这个距离内,就算重合为一点。这个距离使用st_length计算
-- 参数3:该表的空间坐标字段
-- 参数4:该表的主键
-- 参数5:空间起点编号
-- 参数6:空间终点编号
-- 参数7:看官方描述,默认true
-- 参数8:每次执行都重建拓扑图,默认false
select pgr_createTopology('xiangwan',0.000001,'region','id','source','target',rows_where := 'true', clean := 'true');
-- 求最短路径
-- 参数1:sql
-- 参数2:起点source
-- 参数3:重点target
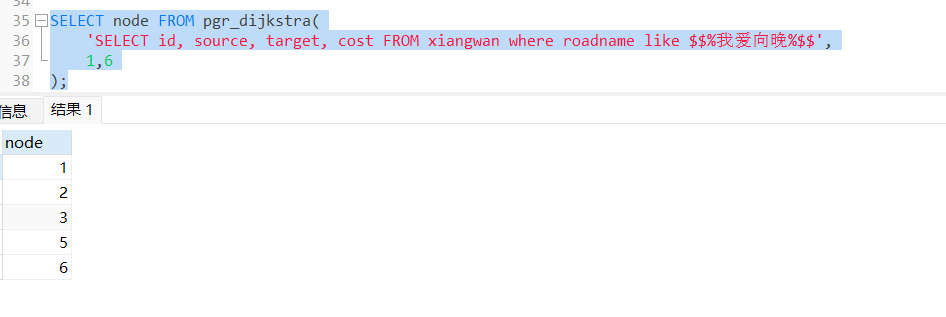
select * from pgr_dijkstra(
'select id, source, target, cost from xiangwan where roadname like $$%我爱向晚%$$',
1,6
);
postgresql 单引号的转义符是$$
上面的写法就是select id, source, target, cost from xiangwan where roadname like ‘%我爱向晚%’
根据查询结果可知,经过的点号依次是1->2->3->5->6。
三、实际做法
因为每有数据来了之后,就要对拓扑图进行一次维护(对cost、source、target的维护)。
由于数据不常变化,这边就想直接使用postgresql的触发器实现。更主要的还是我懒得写代码维护了!
postgresql的触发器比较反人类,必须要基于一个触发器函数才行。这点跟mysql相比,从人性化的角度考虑,简直被吊打。
-- 删除函数
drop function updateTopology();
-- 创建维护拓扑图函数,不想输出内容时,将select换成perform
create or replace function updateTopology()
returns trigger as
$body$
begin
update xiangwan set cost = st_length(region) where cost is null;
perform pgr_createtopology('xiangwan',0.000001,'region','id','source','target');
return null;
end;
$body$ language plpgsql;
-- 创建触发器
create trigger maintainTopology after insert or update of region on xiangwan
for each statement
execute procedure updateTopology();
-- 删除触发器
drop trigger if exists maintainTopology on xiangwan;
上面的那个update xiangwan where cost is null,这么写其实有问题。
但是我的目的是只要有路径能查出来就行,所以这边特别精准是哪条路径对我作用不大。
而且,如果不加where cost is null,就会出现无限套娃的情况!
每次update之后,都要重新执行触发器。
以上是关于PgRouting求解大数据量最短路径的主要内容,如果未能解决你的问题,请参考以下文章