基于飞桨实现高光谱影像和全色影像融合
Posted 百度大脑
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了基于飞桨实现高光谱影像和全色影像融合相关的知识,希望对你有一定的参考价值。
项目背景
高光谱影像因其高光谱分辨率(具有几百个光谱波段)所提供的丰富光谱信息在许多实际应用中都大放光彩,如图像分类、异常检测、变化检测和定量农业等领域。然而由于信噪比和卫星重访周期等原因,高光谱影像的空间分辨率很低,如Modis卫星影像的空间分辨率为500m,使得影像的空间细节严重丢失,极大地限制了其在应用中的范围和精度。
高光谱全色融合是指融合具有高光谱、低空间分辨率的高光谱影像、以及高空间分辨率的单波段全色影像,来得到具有高光谱、高空间分辨率的影像,这是提升高光谱空间分辨率的一种有效的方式。
然而现有的融合方法主要关注于小比例融合任务(即高光谱和全色影像的空间分辨率比值),缺乏实际应用性。如资源一号02D卫星获取的高光谱影像具有166个波段,空间分辨率为30m,而全色影像空间分辨率为2.5m,二者分辨率之比达到12。针对这类大比例分辨率,目前还没有很好的研究成果。
因此本文基于飞桨框架首次聚焦于大比例融合任务(比例为16),并针对融合问题的病态性(即从单波段全色影像预测多波段高光谱影像的反射率),本文提出了一种基于高光谱投影丰度空间的融合网络。此外,根据全色强度和丰度特征之间的线性和非线性的关系,还设计了细节注入的子网络来将全色细节注入到低维的丰度空间而非原始高维空间,有效地缓解了该融合问题的病态性,提升了融合影像的质量。
技术方案
基于全色特征和丰度特征之间的线性和非线性关系,本文构建了PDIN子网络来注入全色细节。
1.线性关系

全色和丰度特征之间的线性关系的推导如上所示,由第四个公式可知,全色强度为丰度的线性组合,而全色强度本身为高光谱的线性组合,因此将全色特征注入到丰度空间和注入到高光谱空间具有等价性。
2.非线性关系

图1:丰度特征和全色强度之间的模拟散点分布图
该非线性关系通过模拟实验得到。首先从USGS光谱库中选择光谱曲线来模拟纯净端元,然后随机生成丰度像元数据,该丰度计算得到的标准差即为图1横轴。随机得到的丰度乘以端元即为构建的高光谱数据,然后乘以worldview2的光谱响应函数生成全色数据。图1即计算得到的丰度标准差和全色强度的散点分布图。由于该分布形状和鱼很相似,故本文称该分布为‘鱼分布’。
运行下方代码即可生成图1分布图。
1import numpy as np
2import matplotlib.pyplot as plt
3srf_pan = np.load('/home/aistudio/data/data124050/srf_pan.npy') # 光谱响应函数
4
5filename = '/home/aistudio/work/file/envi_plot3.txt' # 选择的各种地物纯净光谱
6curve_data =np.loadtxt(filename, skiprows=13)[:, 1:]
7
8pixel_num = 5000
9abun = np.random.rand(pixel_num, curve_data.shape[1])
10abun_sum = np.sum(abun, axis=1)
11abun = abun / np.expand_dims(abun_sum, axis=1)
12
13intensity = np.dot(srf_pan, np.dot(curve_data[:, :], np.transpose(abun))[:srf_pan.shape[0], :]) / np.sum(srf_pan)
14x_var = np.std(abun, axis=1) # 每个像元端元丰度的标准差
15
16plt.scatter(x_var, intensity, color='b', s=10)
17plt.xlabel('Abundance STD')
18plt.ylabel('PAN Intensity')
19plt.show()
3.细节注入子网络(PDIN)图1所示的分布为正确的分布,但实际在网络前向传播过程中,一些模块如上采样模块生成的数据分布并不正确,我们的想法是通过调整数据的分布来变相的注入全色细节。该调整过程设想如下图:

图2:假设的数据分布变换的过程
如图2所示,我们假设绿点是不正确的点(其像元丰度存在误差),而蓝点为符合‘鱼分布’的正确的点。我们希望将绿点移动到蓝点区域以符合‘鱼分布’。由于纵轴是对应的全色强度,是已有的数据,故其能起到监督或约束的作用。即在绿点移动过程中,对应丰度像元所解码得到的‘全色强度’应不偏离真实全色强度。
绿点的移动通过改变丰度像元标准差可以完成,将像元乘以一个权重即可。权重的意思是从图2可以看到,不同的绿点和红线(绿蓝边界)的距离不同,即需要移动的距离也不同,因此丰度像元乘以的权重应自适应每个绿点。由于篇幅有限,具体的推导过程请查看源论文。
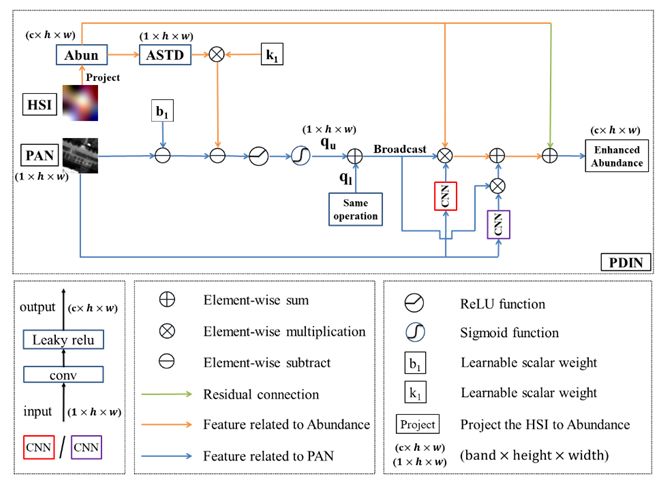
图3:细节注入子网络(PDIN)
下面是基于飞桨构建的PDIN类函数:
1# 利用线性关系和非线性关系构建的融合网络
2class pan_abunstd(nn.Layer):
3 def __init__(self, endmember_num=30):
4 super(pan_abunstd, self).__init__()
5 self.multiply_weight = simple_net_res(1, endmember_num, kernelsize=3) # 乘性权重,改变方差
6 self.plus_weight = simple_net_res(1, endmember_num, kernelsize=3) # 加性权重,改变均值
7
8 def forward(self, w1, w2, b1, b2, pan, abun, dim_band=1):
9 update_weight = F.sigmoid(F.relu(pan - w1 * paddle.std(abun, axis=1, keepdim=True) - b1)) # 应该更新的位置权重
10 update_weight2 = F.sigmoid(F.relu(w2 * paddle.std(abun, axis=1, keepdim=True) + b2 - pan))
11 update_weight = update_weight + update_weight2
12 result0 = self.multiply_weight(pan) * update_weight * abun + self.plus_weight(pan) * update_weight
13 return result0 + abun
其中forward函数里的w1, w2, b1, b2在主类函数里通过paddle.create_parameter()函数定义。
4.总体网络框架
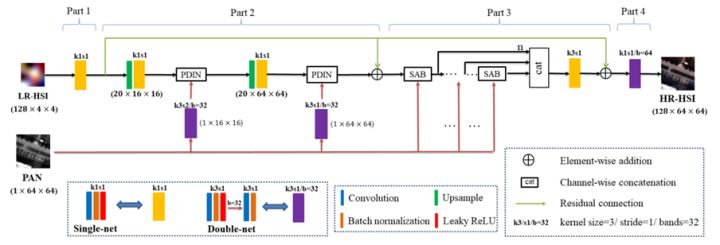
图4:融合网络框架Pgnet
本文提出的融合网络分为四部分,如图4所示。
Part 1为编码部分,即将输入高光谱影像投影到低维丰度空间中,采用了Conv+BN+LReLU的网络结构进行投影。
Part 2为上采样部分,由于本文关注于大比例融合任务,故采用了两步上采样来逐渐提升影像分辨率,绿色方块为上采样block,包含bicubic内插和单卷积操作。紫色方块Double-net为双卷积操作,用于匹配丰度的分辨率和提取特征。

图5:SAB block
Part 3为注意力增强部分,采用了联级的像素级注意力机制来进一步增强特征,如图5所示。并且SAB block中加入了PDIN来进一步注入全色空间细节。
Part 4为解码部分,即将丰度特征还原为高光谱影像。值得注意的是,这部分的卷积参数可以看成线性混合模型中的端元。
实验结果
本文在JiaXing,Chikusei,XiongAn 和Real dataset四个数据集上验证了所提出的Pgnet的融合性能。此外,为了验证网络在小比例融合任务上的泛化性能,我们进行了ratio 4 和 8的实验。消融实验也被设计来验证各个网络模块的必要性和分布变化规律的正确性,即在PDIN中,通过改变数据分布来注入空间细节并不只是设想,实验结果证实了模拟实验所提出的假设。
数据生成代码, 第一步:生成低分辨率高光谱和全色数据;第二步:切割成训练patch:
1def generate_data(path, path_srf): # 第一步
2 ratio_hs = 16
3 # spectral response function of worldview2
4 srf_pan = np.expand_dims(np.expand_dims(np.load(path_srf), axis=-1), axis=-1)
5
6 noise_mean = 0.0
7 noise_var = 0.0001
8 dowmsample16 = Downsampler(ratio_hs) # 高斯核降采样
9 original_msi = np.float32(np.load(path))
10 band, row, col = original_msi.shape
11original_msi = original_msi[:, :(row - row%(ratio_hs*4)), :(col - col%(ratio_hs*4))]
12
13 # ratio 16
14 temp_blur = dowmsample16(paddle.to_tensor(np.expand_dims(original_msi, axis=0), dtype='float32'))
15 print(temp_blur.shape)
16 temp_blur = np.squeeze(temp_blur.numpy())
17 _, rows, cols = temp_blur.shape
18 blur_data = []
19 for i3 in range(temp_blur.shape[0]): # 加入噪声
20 blur_data.append(np.expand_dims(temp_blur[i3, :, :] +
21 np.random.normal(noise_mean, noise_var ** 0.5, [rows, cols]), axis=0))
22 blur_data = np.concatenate(blur_data, axis=0)
23 print('blur_data.shape:' + str(blur_data.shape))
24
25 # simulated pan image
26 temp_pan = np.expand_dims(np.sum(original_msi * srf_pan, axis=0) / np.sum(srf_pan), axis=0)
27 print('temp_pan.shape:' + str(temp_pan.shape))
28
29 return original_msi, temp_blur, temp_pan
30
31def crop_data(hrhs, lrhs, pan, ratio=16, train_ratio=0.8): # 第二步
32 training_size = 64 # training patch size
33 testing_size = 256 # testing patch size
34 idx = int(lrhs.shape[2] * train_ratio) # 切割的坐标索引值
35
36 '''产生训练和测试数据'''
37 train_hs_image, train_hrpan_image, train_label = \\
38 Crop_traindata(lrhs[:, :, :idx],
39 pan[:, :, :idx*ratio],
40 hrhs[:, :, :idx*ratio],
41 ratio=ratio, size=training_size,
42 test=False)
43 test_hs_image, test_hrpan_image, test_label = \\
44 Crop_traindata(lrhs[:, :, idx:],
45 pan[:, :, idx*ratio:],
46 hrhs[:, :, idx*ratio:],
47 ratio=ratio, size=testing_size,
48 test=True)
49 return train_hs_image, train_hrpan_image, train_label, test_hs_image, test_hrpan_image, test_label
训练代码:
1# 定义数据和模型
2dataset0 = Mydata(train_hs_image, train_hrpan_image, train_label) # 训练数据
3train_loader = paddle.io.DataLoader(dataset0, num_workers=0, batch_size=opt.batch_size,
4 shuffle=True, drop_last=True)
5
6dataset1 = Mydata(test_hs_image, test_hrpan_image, test_label) # 测试数据
7test_loader = paddle.io.DataLoader(dataset1, num_workers=0, batch_size=opt.test_batch_size,
8 shuffle=False, drop_last=False)
9
10model = Pg_net(band=opt.in_nc, endmember_num=opt.endmember, ratio=ratio)
11
12L2_loss = nn.loss.MSELoss() # loss 函数
13samloss = SAMLoss()
14
15scheduler = optim.lr.StepDecay(opt.lr, opt.step, gamma=opt.momentum, verbose=False) # 学习率调整
16optimizer = optim.Adam(learning_rate=scheduler, parameters=model.parameters())
17for epoch in range(opt.num_epochs):
18 time0 = time.time()
19 loss_total = 0.0
20
21 scheduler.step(epoch)
22 model.train()
23 for i, (images_hs, images_pan, labels) in enumerate(train_loader()):
24 result = model(images_hs, images_pan)
25
26 loss_l2 = L2_loss(result, labels)
27 loss_sam = samloss(result, labels)
28 loss = loss_l2 + 0.01*loss_sam
29
30 loss.backward()
31 optimizer.step()
32 optimizer.clear_gradients()
33 loss_total += loss.numpy()
34
35 if ((epoch+1) % 10) == 0:
36 print('epoch %d of %d, using time: %.2f , loss of train: %.4f' %
37 (epoch + 1, opt.num_epochs, time.time() - time0, loss_total))
38
39# 测试结果输出:
40model.eval()
41image_all = []
42with paddle.no_grad():
43 for (images_hs, images_pan, _) in test_loader:
44 outputs_temp = model(images_hs, images_pan)
45 image_all.append(outputs_temp)
46 a = paddle.concat(image_all, axis=0)
47return a
JiaXing 实验结果:
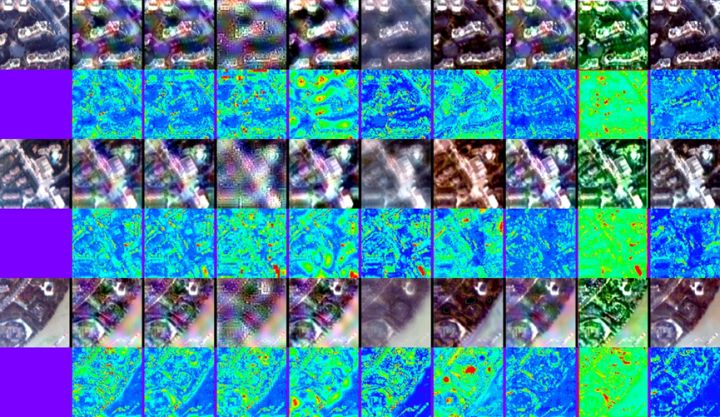
图6:各个方法的融合结果在JiaXing数据集上。其中第一列为真实影像,后续每列分别为GSA, SFIM, Wavelet, MTF_GLP_HPM, CNMF, Hyperpnn2, HSpeSet2, HyperKite方法的结果,本文方法在最后一列 (详细方法请看论文)。其中奇数行为融合高光谱影像,偶数行是和真值的差值。

表1:定量实验结果在JiaXing数据集上。
从上述实验结果可以看出,相比于其他方法,本文方法展现出了更好的光谱和空间保真度。包括多个指标的定量结果也表明我们的方法取得了最好的性能。由于空间关系,其他三个数据集的结果并未展现,但我们的方法均取得了最好的结果。
数据分布变换假设的验证
为了验证提出的PDIN对于数据分布变换的效果,我们对测试影像的中间结果进行了分析,结果如下:
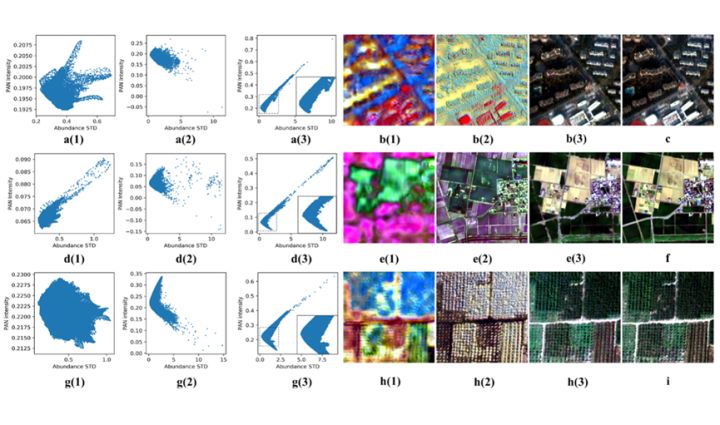
图 7:中间结果变化过程。其中每行代表不同的数据集,以第一行JiaXing数据为例,前三个中间结果散点图(横轴为丰度标准差,纵轴为全色强度)分别代表第二个上采样block后、第二个PDIN后和Part 3的末端。第四到六幅影像为对应解码得到的高光谱影像,最后一个为真实影像。
如图7所示,从第一列到第二列,即经过了一次PDIN的细节注入后,数据分布变得些许像模拟数据的分布了(鱼分布),对应的高光谱影像质量也有所提升(第五列)。在经过了带有PDIN的注意力机制后,即第三列,数据分布变成了和模拟数据几乎相等的分布,对应的高光谱质量也和真实影像非常接近(第六列)。该图所展示的中间结果的变换验证了提出的PDIN能够通过纠正数据分布来注入细节和提升影像质量,并且也验证了‘鱼分布’的正确性。
结论
本文关注于大比例的高光谱和全色融合任务,使用飞桨框架构建了基于投影丰度子空间的逐级上采样融合网络。利用丰度和全色特征之间的线性和非线性关系构建了全色细节注入子网络PDIN,有效地将全色细节注入到了丰度特征中,缓解了融合问题的病态性。定性和定量的实验结果验证了所提出的融合网络的有效性和高效性。对于中间结果的可视化也验证了PDIN能够通过纠正数据分布来注入全色细节和提升影像质量。该轻量型的网络设计(只有49100个参数)和所取得的实验结果使得高光谱和全色融合的实际应用迈出了一步。
以上是关于基于飞桨实现高光谱影像和全色影像融合的主要内容,如果未能解决你的问题,请参考以下文章
GDAL与OpenCV2.X数据转换(适合多光谱和高光谱等多通道的遥感影像)