PyTorch生成3D模型
Posted 新缸中之脑
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了PyTorch生成3D模型相关的知识,希望对你有一定的参考价值。
本文将介绍如何利用深度学习技术生成3D模型,使用了PyTorch和PolyGen。

1、概述
有一个新兴的深度学习研究领域专注于将 DL 技术应用于 3D 几何和计算机图形应用程序,这一长期研究的集合证明了这一点。对于希望自己尝试一些 3D 深度学习的 PyTorch 用户,Kaolin 库值得研究。对于 TensorFlow 用户,还有TensorFlow Graphics。一个特别热门的子领域是 3D 模型的生成。创造性地组合 3D 模型、从图像快速生成 3D 模型以及为其他机器学习应用程序和模拟创建合成数据只是 3D 模型生成的无数用例中的一小部分。
然而,在 3D 深度学习研究领域,为你的数据选择合适的表示是成功的一半。在计算机视觉中,数据的结构非常简单:图像由密集的像素组成,这些像素整齐均匀地排列成精确的网格。3D 数据的世界没有这种一致性。3D 模型可以表示为体素、点云、网格、多视图图像集等。这些输入表示也都有自己的一组缺点。例如,体素尽管计算成本很高,但输出分辨率很低。点云不编码表面或其法线的概念,因此不能仅从点云唯一地推断出拓扑。网格也不对拓扑进行唯一编码,因为任何网格都可以细分以产生相似的表面。PolyGen,一种用于网格的神经生成模型,它联合估计模型的面和顶点以直接生成网格。DeepMind GitHub 上提供了官方实现。
2、研究
现在经典的PointNet论文为点云数据建模提供了蓝图,例如 3D 模型的顶点。它是一种通用算法,不对 3D 模型的面或占用进行建模,因此无法单独使用 PointNet 生成独特的防水网格。3D-R2N2采用的体素方法将我们都熟悉的 2D 卷积扩展到 3D,并自然地从 RGB 图像生成防水网格。然而,在更高的空间分辨率下,体素表示的计算成本很高,有效地限制了它可以产生的网格的大小。
Pixel2Mesh可以通过变形模板网格(通常是椭圆体)从单个图像预测 3D 模型的顶点和面。目标模型必须与模板网格同胚,因此使用凸模板网格(例如椭圆体)会在椅子和灯等高度非凸的物体上引入许多假面。拓扑修改网络(TMN) 通过引入两个新阶段在 Pixel2Mesh 上进行迭代:拓扑修改阶段用于修剪会增加模型重建误差的错误面,以及边界细化阶段以平滑由面修剪引入的锯齿状边界。如果你有兴趣,我强烈建议同时查看AtlasNet和Hierarchical Surface Prediction。

虽然变形和细化模板网格的常用方法表现良好,但它始于对模型拓扑的主要假设。就其核心而言,3D 模型只是 3D 空间中的一组顶点,通过各个面进行分组和连接在一起。是否可以避开中间表示并直接预测这些顶点和面?
3、PolyGen
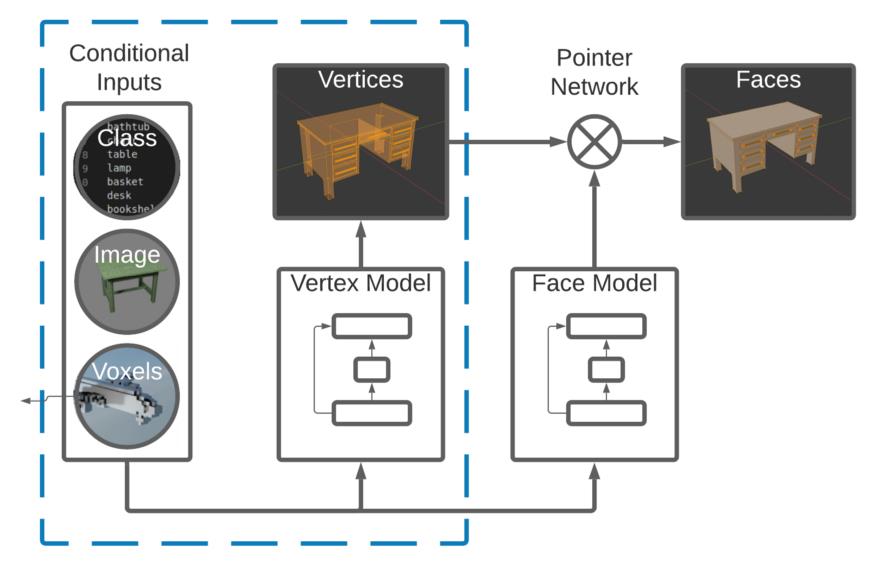
PolyGen 通过将 3D 模型表示为顶点和面的严格排序序列,而不是图像、体素或点云,对模型生成任务采取了一种相当独特的方法。这种严格的排序使他们能够应用基于注意力的序列建模方法来生成 3D 网格,就像 BERT 或 GPT 模型对文本所做的那样。
PolyGen 的总体目标有两个:首先为 3D 模型生成一组合理的顶点(可能以图像、体素或类标签为条件),然后生成一系列面,一个接一个,连接顶点在一起,并为此模型提供一个合理的表面。组合模型将网格上的分布p(M)表示为两个模型之间的联合分布:顶点模型p(V)表示顶点,面模型p(F|V)表示以顶点为条件的面。
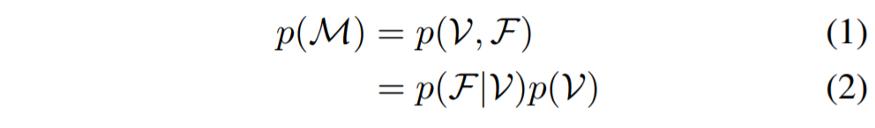
顶点模型是一个解码器,它试图预测以先前标记为条件的序列中的下一个标记(并且可选地以图像、体素字段或类标签为条件)。人脸模型由一个编码器和一个解码器指针网络组成,该网络表示顶点序列上的分布。该指针网络一次有效地“选择”一个顶点,以添加到当前面序列并构建模型的面。该模型以先前的人脸序列和整个顶点序列为条件。由于 PolyGen 架构相当复杂并且依赖于各种概念,因此本文将仅限于顶点模型。
4、预处理顶点
流行的ShapeNetCore数据集中的每个模型都可以表示为顶点和面的集合。每个顶点由一个 (x, y, z) 坐标组成,该坐标描述了 3D 网格中的一个点。每个面都是一个索引列表,指向构成该面角的顶点。对于三角形面,此列表长 3 个索引。对于 n 边形面,此列表是可变长度的。原始数据集非常大,因此为了节省时间,我在此处提供了一个更轻量级的预处理数据集子集供你进行实验。该子集仅包含来自 5 个形状类别的模型,并且在转换为 n 边形后少于 800 个顶点(如下所述)。
为了使序列建模方法发挥作用,数据必须以一种受约束的、确定性的方式表示,以尽可能多地消除可变性。出于这个原因,作者对数据集进行了一些简化。首先,他们将所有输入模型从三角形(连接 3 个顶点的面)转换为 n 边形(连接 n 个顶点的面),使用Blender 的平面抽取修改器合并面。这为相同的拓扑提供了更紧凑的表示,并减少了三角剖分中的歧义,因为大型网格并不总是具有唯一的三角剖分。为了篇幅的缘故,我不会在这篇文章中讨论 Blender 脚本,但有很多资源,包括官方文档和GitHub 上的这套优秀示例,很好地涵盖了这个主题。我提供的数据集已经预先抽取。

要继续进行,请下载此示例 cube.obj 文件。这个模型是一个基本的立方体,有 8 个顶点和 6 个面。以下简单代码片段从单个 .obj 文件中读取所有顶点。
def load_obj(filename):
"""Load vertices from .obj wavefront format file."""
vertices = []
with open(filename, 'r') as mesh:
for line in mesh:
data = line.split()
if len(data) > 0 and data[0] == 'v':
vertices.append(data[1:])
return np.array(vertices, dtype=np.float32)
verts = load_obj(cube_path)
print('Cube Vertices')
print(verts)
其次,顶点首先从它们的 z 轴(在这种情况下为垂直轴)按升序排序,然后是 y 轴,最后是 x 轴。这样,模型顶点是自下而上表示的。在 vanilla PolyGen 模型中,然后将顶点连接成一维序列向量,对于较大的模型,该向量最终会得到一个非常长的序列向量。作者在论文的附录 E 中描述了一些减轻这种负担的修改。
要对一系列顶点进行排序,我们可以使用字典排序。这与对字典中的单词进行排序时采用的方法相同。要对两个单词进行排序,您将查看第一个字母,然后如果有平局,则查看第二个字母,依此类推。对于“aardvark”和“apple”这两个词,第一个字母是“a”和“a”,所以我们移动到第二个字母“a”和“p”来告诉我“aardvark”在“apple”之前。在这种情况下,我们的“字母”是按顺序排列的 z、y 和 x 坐标。
verts_keys = [verts[..., i] for i in range(verts.shape[-1])]
sort_idxs = np.lexsort(verts_keys)
verts_sorted = verts[sort_idxs]
最后,顶点坐标被归一化,然后被量化以将它们转换为离散的 8 位值。这种方法已在像素递归神经网络和WaveNet中用于对音频信号进行建模,使它们能够对顶点值施加分类分布。在最初的WaveNet论文中,作者评论说“分类分布更灵活,并且可以更容易地对任意分布进行建模,因为它不对它们的形状做任何假设。” 这种质量对于建模复杂的依赖关系很重要,例如 3D 模型中顶点之间的对称性。
# normalize vertices to range [0.0, 1.0]
lims = [-1.0, 1.0]
norm_verts = (verts - lims[0]) / (lims[1] - lims[0])
# quantize vertices to integers in range [0, 255]
n_vals = 2 ** 8
delta = 1. / n_vals
quant_verts = np.maximum(np.minimum((norm_verts // delta), n_vals - 1), 0).astype(np.int32)
5、顶点模型
顶点模型由一个解码器网络组成,它具有变压器模型的所有标准特征:输入嵌入、18 个变压器解码器层的堆栈、层归一化,最后是在所有可能的序列标记上表示的 softmax 分布。给定一个长度为N的扁平顶点序列Vseq,其目标是在给定模型参数的情况下最大化数据序列的对数似然:
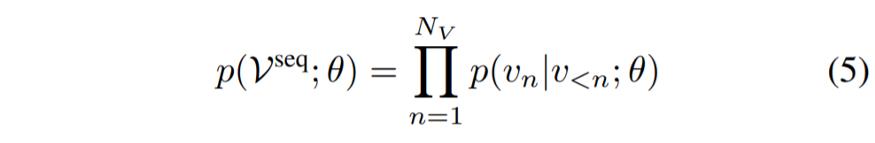
与 LSTM 不同的是,transformer 模型能够以并行方式处理顺序输入,同时仍使来自序列一部分的信息能够为另一部分提供上下文。这一切都归功于他们的注意力模块。3D 模型的顶点包含各种对称性和远点之间的复杂依赖关系。例如,考虑一个典型的桌子,其中模型对角的腿是彼此的镜像版本。注意力模块允许对这些类型的模式进行建模。
6、输入嵌入
嵌入层是序列建模中用于将有限数量的标记转换为特征集的常用技术。在语言模型中,“国家”和“民族”这两个词的含义可能非常相似,但与“苹果”这个词却相距甚远。当单词用唯一的标记表示时,就没有相似性或差异性的固有概念。嵌入层将这些标记转换为矢量表示,可以对有意义的距离感进行建模。
PolyGen 将同样的原理应用于顶点。该模型使用三种类型的嵌入层:坐标表示输入标记是 x、y 还是 z 坐标,值表示标记的值,以及位置编码顶点的顺序。每个都向模型传达有关令牌的一条信息。由于我们的顶点一次在一个轴上输入,坐标嵌入为模型提供了基本的坐标信息,让它知道给定值对应的坐标类型。
coord_tokens = np.concatenate(([0], np.arange(len(quant_verts)) % 3 + 1, (n_padding + 1) * [0]))
值嵌入对我们之前创建的量化顶点值进行编码。我们还需要一些序列控制点:额外的开始和停止标记分别标记序列的开始和结束,并将标记填充到最大序列长度。
TOKENS =
'<pad>': 0,
'<sos>': 1,
'<eos>': 2
max_verts = 12 # set low for prototyping
max_seq_len = 3 * max_verts + 2 # num coords + start & stop tokens
n_tokens = len(TOKENS)
seq_len = len(quant_verts) + 2
n_padding = max_seq_len - seq_len
val_tokens = np.concatenate((
[TOKENS['<sos>']],
quant_verts + n_tokens,
[TOKENS['<eos>']],
n_padding * [TOKENS['<pad>']]
))
由于并行化而丢失的给定序列位置n的位置信息通过位置嵌入来恢复。也可以使用位置编码,一种不需要学习的封闭形式的表达。在经典的 Transformer 论文“ Attention Is All You Need ”中,作者定义了一种由不同频率的正弦和余弦函数组成的位置编码。他们通过实验确定位置嵌入的性能与位置编码一样好,但编码的优势在于比训练中遇到的序列更长。有关位置编码的出色视觉解释,请查看此博客文章。
pos_tokens = np.arange(len(quant_tokens), dtype=np.int32)
生成所有这些标记序列后,最后要做的是创建一些嵌入层并将它们组合起来。每个嵌入层都需要知道期望的输入字典的大小和输出的嵌入维度。每层的嵌入维数为 256,这意味着我们可以将它们与加法相结合。字典大小取决于输入可以具有的唯一值的数量。对于值嵌入,它是量化值的数量加上控制标记的数量。对于坐标嵌入,对于每个坐标 x、y 和 z,它是一个,对于上述任何一个(控制标记)都不是一个。最后,位置嵌入对于每个可能的位置或最大序列长度都需要一个。
n_embedding_channels = 256
# initialize value embedding layer
n_embeddings_value = 2 ** n_bits + n_tokens
value_embedding = torch.nn.Embedding(n_embeddings_value,
n_embedding_channels, padding_idx=TOKENS['<pad>'])
# initialize coordinate embedding layer
n_embeddings_coord = 4
coord_embedding = torch.nn.Embedding(n_embeddings_coord,
n_embedding_channels)
# initialize position embedding layer
n_embeddings_pos = max_seq_len
pos_embedding = torch.nn.Embedding(n_embeddings_pos,
n_embedding_channels)
# pass through layers
value_embed = self.value_embedding(val_tokens)
coord_embed = self.coord_embedding(coord_tokens)
pos_embed = self.pos_embedding(pos_tokens)
# merge
x = value_embed + coord_embed + pos_embed
7、序列掩蔽
Transformer模型如此并行化的另一个后果是什么?对于时间n的给定输入标记,模型实际上可以“看到”序列后面的目标值,当你尝试仅根据先前的序列值调整模型时,这会成为一个问题。为了防止模型关注无效的未来目标值,可以-Inf在 self-attention 层中的 softmax 步骤之前屏蔽未来位置。
n_seq = len(val_tokens)
mask_dims = (n_seq, n_seq)
target_mask = torch.from_numpy(
(val_tokens != TOKENS['<pad>'])[..., np.newaxis] \\
& (np.triu(np.个(mask_dims),k=1).astype('uint8')== 0))
PolyGen 还广泛使用无效预测掩码来确保其生成的顶点和面部序列编码有效的 3D 模型。例如,必须强制执行诸如“z 坐标不递减”和“停止标记只能出现在完整顶点(z、y 和 x 标记的三元组)之后”之类的规则,以防止模型产生无效的网格. 作者在论文的附录 F 中提供了他们使用的掩蔽的广泛列表。这些约束仅在预测时强制执行,因为它们实际上会损害训练性能。
8、核取样
与许多序列预测模型一样,该模型是自回归的,这意味着给定时间步的输出是下一个时间步的可能值的分布。整个序列一次预测一个标记,模型在每一步都会查看先前时间步骤中的所有标记以选择其下一个标记。解码策略决定了它如何从这个分布中选择下一个Token。
如果使用次优解码策略,生成模型有时会陷入重复循环或产生质量较差的序列。我们都看到生成的文本看起来像是胡说八道。PolyGen 采用称为核采样的解码策略来生成高质量序列。原始论文在文本生成上下文中应用了这种方法,但它也可以应用于顶点。前提很简单:仅从 softmax 分布中共享 top-p 概率质量的标记中随机抽取下一个标记。这在推理时应用以生成网格,同时避免序列退化。有关核采样的 PyTorch 实现,请参阅此要点。
9、条件输入
除了无条件生成模型外,PolyGen 还支持使用类标签、图像和体素进行输入调节。这些可以指导生成具有特定类型、外观或形状的网格。类标签通过嵌入投影,然后添加到每个注意力块中的自注意力层之后。对于图像和体素,编码器创建一组嵌入,然后用于与转换器解码器的交叉注意。
10、结论
PolyGen 模型描述了一个强大、高效和灵活的框架,用于有条件地生成 3D 网格。序列生成可以在各种条件和输入类型下完成,从图像到体素到简单的类标签,甚至只是一个起始标记。表示网格顶点分布的顶点模型只是联合分布难题的一部分。我打算在以后的文章中介绍面部模型。同时,我鼓励你查看DeepMind 的 TensorFlow 实现,并尝试生成条件模型!
原文链接:深度学习生成3D模型 — BimAnt
以上是关于PyTorch生成3D模型的主要内容,如果未能解决你的问题,请参考以下文章