图灵奖得主Yoshua Bengio一作:「生成流网络」拓展深度学习领域
Posted 人工智能博士
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了图灵奖得主Yoshua Bengio一作:「生成流网络」拓展深度学习领域相关的知识,希望对你有一定的参考价值。
点上方人工智能算法与Python大数据获取更多干货
在右上方 ··· 设为星标 ★,第一时间获取资源
仅做学术分享,如有侵权,联系删除
转载于 :机器之心
近日,一篇名为《GFlowNet Foundations》的论文引发了人们的关注,这是一篇图灵奖得主 Yoshua Bengio 一作的新研究,论文长达 70 页。
在 Geoffrey Hinton 的「胶囊网络」之后,深度学习的另一个巨头 Bengio 也对 AI 领域未来的方向提出了自己的想法。在该研究中,作者提出了名为「生成流网络」(Generative Flow Networks,GFlowNets)的重要概念。

GFlowNets 灵感来源于信息在时序差分 RL 方法中的传播方式(Sutton 和 Barto,2018 年)。两者都依赖于 credit assignment 一致性原则,它们只有在训练收敛时才能实现渐近。由于状态空间中的路径数量呈指数级增长,因此实现梯度的精确计算比较困难,因此,这两种方法都依赖于不同组件之间的局部一致性和一个训练目标,即如果所有学习的组件相互之间都是局部一致性的,那么我们就得到了一个系统,该系统可以进行全局估计。
至于 GFlowNets 作用,论文作者之一 Emmanuel Bengio 也给出了一些回答:「我们可以用 GFlowNets 做很多事情:对集合和图进行一般概率运算,例如可以处理较难的边缘化问题,估计配分函数和自由能,计算给定子集的超集条件概率,估计熵、互信息等。」
本文为主动学习场景提供了形式化理论基础和理论结果集的扩展,同时也为主动学习场景提供了更广泛的方式。GFlowNets 的特性使其非常适合从集合和图的分布中建模和采样,估计自由能和边缘分布,并用于从数据中学习能量函数作为马尔可夫链蒙特卡洛(Monte-Carlo Markov chains,MCMC)一个可学习的、可分摊(amortized)的替代方案。
GFlowNets 的关键特性是其学习了一个策略,该策略通过几个步骤对复合对象 s 进行采样,这样使得对对象 s 进行采样的概率 P_T (s) 与应用于该对象的给定奖励函数的值 R(s) 近似成正比。一个典型的例子是从正例数据集训练一个生成模型,GFlowNets 通过训练来匹配给定的能量函数,并将其转换为一个采样器,我们将其视为生成策略,因为复合对象 s 是通过一系列步骤构造的。这类似于 MCMC 方法的实现,不同的是,GFlowNets 不需要在此类对象空间中进行冗长的随机搜索,从而避免了 MCMC 方法难以处理模式混合的难题。GFlowNets 将这一难题转化为生成策略的分摊训练(amortized training)来处理。
本文的一个重要贡献是条件 GFlowNet 的概念,可用于计算不同类型(例如集合和图)联合分布上的自由能。这种边缘化还可以估计熵、条件熵和互信息。GFlowNets 还可以泛化,用来估计与丰富结果 (而不是一个纯量奖励函数) 相对应的多个流,这类似于分布式强化学习。
本文对原始 GFlowNet (Bengio 等人,2021 年)的理论进行了扩展,包括计算变量子集边缘概率的公式(或自由能公式),该公式现在可以用于更大集合的子集或子图 ;GFlowNet 在估计熵和互信息方面的应用;以及引入无监督形式的 GFlowNet(训练时不需要奖励函数,只需要观察结果)可以从帕累托边界进行采样。
尽管基本的 GFlowNets 更类似于 bandits 算法(因为奖励仅在一系列动作的末尾提供),但 GFlowNets 可以通过扩展来考虑中间奖励,并根据回报进行采样。GFlowNet 的原始公式也仅限于离散和确定性环境,而本文建议如何解除这两种限制。最后,虽然 GFlowNets 的基本公式假设了给定的奖励或能量函数,但本文考虑了 GFlowNet 如何与能量函数进行联合学习,为新颖的基于能量的建模方法、能量函数和 GFlowNet 的模块化结构打开了大门。

论文地址:https://arxiv.org/pdf/2111.09266.pdf
机器之心对这篇论文的主要章节做了简单介绍,更多细节内容请参考原论文。
GFlowNets:学习流(flow)
研究者充分考虑了 Bengio et al. (2021)中引入的一般性问题,在这些问题中给出了一些关于流的约束或偏好。研究者的目标是使用估计量 Fˆ(s)和 Pˆ(s→s'|s)找到最能匹配需求的函数,如状态流函数 F(s)或转移概率函数 P(s→s' |s),这些可能不符合 proper flow。因此,他们将这类学习机器称为 Generative Flow Networks(简称为 GFlowNets)。
GFlowNets 的定义如下:

需要注意的是,GFlowNet 的状态空间(state-space)可以轻松修改以适应底层状态空间,其中转换(transition)不会形成有向无环图(directed acyclic graph, DAG)。
对于从终端流(Terminal Flow)估计转换概率,在 Bengio et al. (2021)的设置中, 研究者得到了与「作为状态确定性函数的终端奖励函数 R 」相对应的终端流:

这样一来就可以扩展框架并以各种方式处理随机奖励。
GFlowNets 可以作为 MCMC Sampling 的替代方案。GFlowNet 方法分摊前期计算以训练生成器,为每个新样本产生非常有效的计算(构建单个配置,不需要链)。
流匹配和详细的平衡损失。为了训练 GFlowNet,研究者需要构建一个训练流程,该流程可以隐式地强制执行约束和偏好。他们将流匹配(flow-matching)或细致平衡条件(detailed balance condition)转换为可用的损失函数。
对于奖励函数,研究者考虑了「奖励是随机而不是状态确定性函数」的设置。如果有一个像公式 44 中的奖励匹配损失,则终端流 F(s→s_f)的有效目标是预期奖励 E_R[R(s),因为这是给定 s 时最小化 R(s)上预期损失的值。
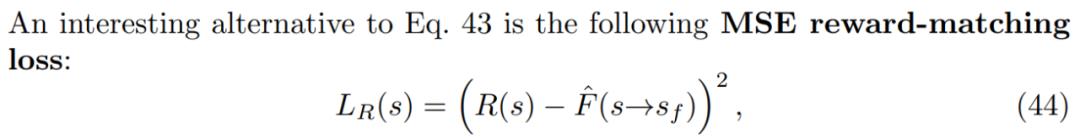
如果有一个像公式 43 中的奖励匹配损失,终端流 log F(s→s_f)的 log 有效目标是 log-reward E_R[log R(s)]的预期值。这表明了使用奖励匹配损失时,GFlowNets 可以泛化至匹配随机奖励。
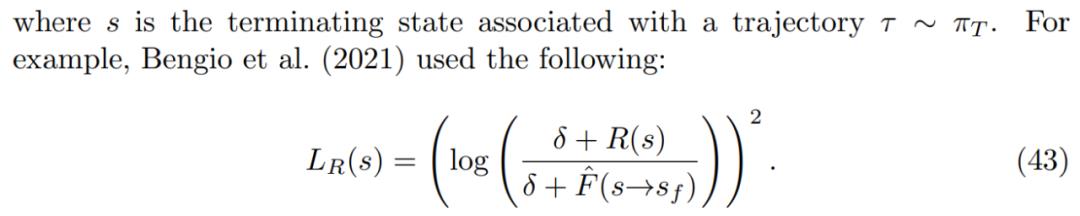
此外,GFlowNets 可以像离线强化学习一样离线训练。对于 GFlowNets 中的直接信用分配(Direct Credit Assignment),研究者认为可以将使用 GFlowNet 采样轨迹的过程等同于在随机循环神经网络中采样状态序列。让事情变得更复杂的原因有两个,其一这类神经网络不直接输出与某个目标匹配的预测,其二状态可能是离散(或者离散和连续共存)的。
条件流和自由能
本章主要介绍了条件流(Conditional flows)和自由能(Free energies)。
流的一个显著特性是:如果满足细致平衡或流匹配条件,则可以从初始状态流 F(s_0) 恢复归一化常数 Z(推论 3)。Z 还提供了与指定了终端转换流的给定终端奖励函数 R 相关联的配分函数(partition function)。下图展示了如何条件化 GFlowNet,给定状态 s,考虑通过原始流(左)和转移流来创建一组新的流(右)。

自由能是与能量函数相关的边缘化操作(即对大量项求和)的通用公式。研究者发现对自由能的估计为有趣的应用打开了大门,以往成本高昂的马尔可夫链蒙特卡洛(Markov chain Monte Carlo, MCMC)通常是主要方法。
自由能 F(s)的状态定义如下:
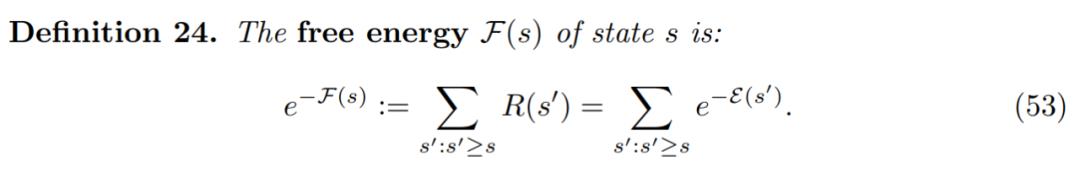
如何估计自由能呢?让我们考虑条件式 GFlowNet 的一种特殊情况,它允许网络估计自由能 F(s)。为此,研究者提议训练一个条件式 GFlowNet,其中条件输入 x 是轨迹中较早的状态 s。
状态条件式 GFlowNet 的定义如下,并且将 F(s|s)定义为 conditional state self-flow。

研究者表示,使用 GFlowNet 可以训练基于能量的模型。具体地,GFlowNet 被训练用于将能量函数转换为逼近对应的采样器。因此,GFlowNet 可以用作 MCMC 采样的替代方法。
此外,GFlowNet 还可用于主动学习。Bengio et al. (2021)使用的主动学习方案中,GFlowNet 被用于对候选 x 进行采样,其中研究者预计奖励 R(x)通常很大,这是因为 GFlowNet 与 R(x)成比例地采样。
多流、分布式 GFlowNets、无监督 GFlowNets 和帕累托 GFlowNets
与分布式强化学习类似,非常有趣的一点是,泛化 GFlowNets 不仅可以捕获可实现的最终奖励的预期值,还能得到其他分布式统计数据。更一般地讲,GFlowNets 可以被想象成一个族(family),其中每一个都可以在自身流中对感兴趣的特定的未来环境结果进行建模。
下图为以结果为条件的(outcome-conditioned)GFlowNet 的定义:

在实践中,GFlowNet 永远无法完美地训练完成,因此应当将这种以结果为条件的 GFlowNet 与强化学习中以目标为条件的策略或者奖励条件颠倒的强化学习(upside-down RL)同等看待。未来更是可以将这些以结果为条件的 GFlowNets 扩展到随机奖励或随机环境中。
此外,训练一个以结果为条件的 GFlowNet 只能离线完成,因为条件输入(如最终返回)可能只有在轨迹被采样后才能知道。

论文的完整目录如下:


---------♥---------
声明:本内容来源网络,版权属于原作者
图片来源网络,不代表本公众号立场。如有侵权,联系删除
AI博士私人微信,还有少量空位


点个在看支持一下吧

以上是关于图灵奖得主Yoshua Bengio一作:「生成流网络」拓展深度学习领域的主要内容,如果未能解决你的问题,请参考以下文章
价值连城 图灵奖得主Yoshua Bengio约书亚·本吉奥的采访 给AI从业者的建议
价值连城 图灵奖得主Yoshua Bengio约书亚·本吉奥的采访 给AI从业者的建议
人工智能中的深度结构学习 Learning deep architectures for AI - Yoshua Bengio