图灵奖得主Yoshua Bengio的一生!
Posted Datawhale
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了图灵奖得主Yoshua Bengio的一生!相关的知识,希望对你有一定的参考价值。

文 | 智商掉了一地
2018 年图灵奖获得者、AI 先驱、深度学习三巨头之一、对抗生成网络 GAN、标志性的银灰卷发和浓眉,如果还没猜到的话,当你看到这个封面,一定就会意识到自己在学习的路上,已经或间接或直接地拜读过大佬的著作了。

看到花书的封面,和前面的关键词,也许你会意识到,他就是——Yoshua Bengio。

从下面这个记录可以看出,他的著作在谷歌学术上的引用量也是一骑绝尘。

就在这两天的 NeurIPS 2022 New in ML Workshop 上,Yoshua Bengio 做了一个 Live Talk,介绍了自己从本科毕业开始,一直到现在的人生之路。
链接:
https://nehzux.github.io/NewInML2022NeurIPS/assets/YoshuaBengio-NewInML-NeurIPS-28nov2022.pdf
接下来,就是Bengio在大会上亲口讲述“自己一生”的故事。
从最初本科毕业时的“广度优先搜索”,了解到 Hinton 的连接主义, 到探索人脑、初代语言模型、注意力机制等等,以及度过人工智能寒冬,再到现在探索抽象、生成流网络、Ai4Science、HLAI(人类级别智能)、意识先验、System-2、因果推断、元学习、模块化等重要且新颖的领域。Yoshua Bengio 回顾了自己的科研生涯,他说“Staying Humble”。
爱上一个研究方向
一开始,Yoshua 讲述了“他是如何爱上一个研究方向”。
1985 - 1986 年,他刚读完本科,思索自己下一步要做什么,阅读了大量不同领域的论文,将视线聚焦于神经网络研究,尤其是 Geoff Hinton 和 David Rumelhart 等其他早期连接主义者的论文。
1986 - 1988 年,Yoshua 进一步阅读玻尔兹曼机,实现音素分类,完成了关于语音识别的玻尔兹曼机的硕士论文,而后当了解到反向传播时,对它感到兴奋,并开始使用它,在之后参加了 1988 年连接主义的暑期学校,遇到了许多其他充满热情的研究生和研究人员们。
1988-1991 年,Yoshua 完成了关于神经网络(RNNs 和 ConvNets)和 HMM 混合的博士论文。
 神经网络与人工智能
神经网络与人工智能
随后,Yoshua 阐述了自己的工作中对于神经网络与 AI 的理解。从一个令人兴奋的先验知识出发,他指出,通过学习,智能(机器、人类或动物)的产生是有一些原则的,这些原则非常简单,可以被简洁地描述出来,类似于物理定律,也就是说,我们的智能不只是一堆技巧和知识的结果,而是获取知识的一般机制。

他还辨析了传统 AI 和机器学习的要点,提到了人工智能的机器学习方法:
经典的 AI 一般是基于规则、基于符号的:其知识由人类提供,但直觉知识是不可传播的,机器只做推理工作,没有很强的学习和适应能力,对不确定性的处理能力不足。
而机器学习则试图解决这些问题:在很大程度上取得了成功,但更高层次的(有意识的)认知尚未实现。
而后 Yoshua 从维度诅咒和分布式表示(指数级优势)这两个细节出发,强调了促使 ML 向 AI 转变的五个关键因素:
海量&海量的数据;
非常灵活的模型;
足够的算力;
计算效率推断;
强大的先验知识,可以打破“维度诅咒”,实现对新情况的强泛化。
他还提到了脑启发(Brain-inspired),以及如下特性:
大量简单自适应计算单元的协同作用;
关注分布式表示(如单词表示);
视智能为结合的产物(近似优化器、初始架构/参数化);
端到端学习
长期依赖和梯度下降
紧接着,Yoshua 回顾了机器学习 101 课程的要点:
函数族;
可调参数;
从未知数据中抽样的例子产生分布;
对经过训练的函数所产生的误差的度量;
近似最小化算法搜索最佳参数选择,迭代减少平均训练误差
又引出了他们自己 1994 年的工作 "Learning Long-Term Dependencies with Gradient Descent is Difficult" ,并强调了他的经验:负面结果可能非常重要,它教会了我们一些东西,推动了许多下游研究,比如 2014 年关于自注意力机制的工作。
接下来他展开介绍了这项工作:
如何存储 1 bit?在某些维度上有多个引力盆地的动力学
如果动力系统在某些维度上有多个吸引域,则状态的某些子空间可以存储 1 bit 或多个 bit 信息。
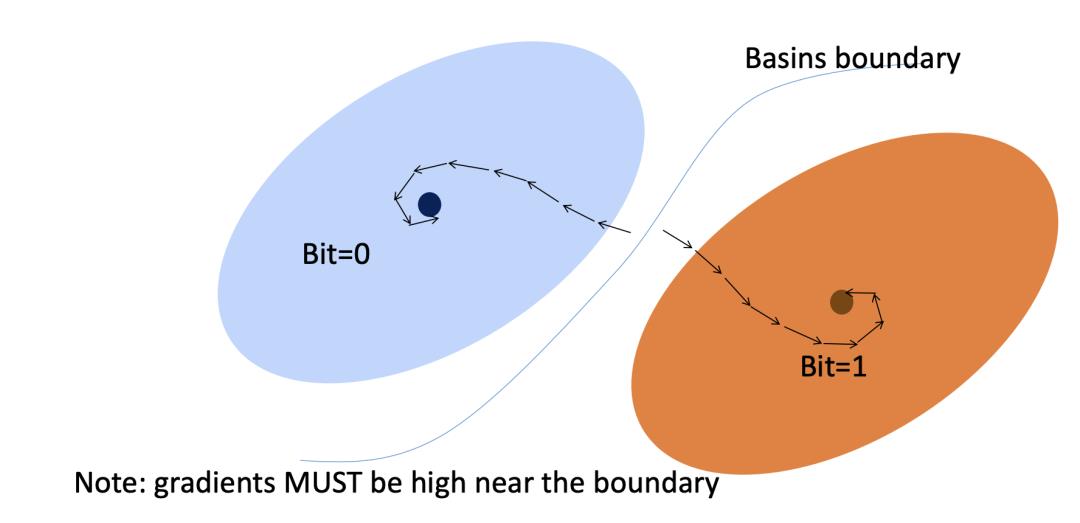
在有界噪声存在的情况下稳健地存储 1 bit:
光谱半径 > 1,噪声可以踢出吸引子的状态(不稳定);
而当半径 < 1时就不是这样了(收缩→稳定)。

可靠地存储→消失的梯度
可靠地存储比特信息需要谱半径 < 1
谱半径 < 1的 T 个矩阵的乘积是一个矩阵,其谱半径在 T 上以指数速度收敛于 0。

如果 Jacobian 矩阵的谱半径 < 1 →传播梯度消失
为什么它会损害基于梯度的学习?
与短期依赖关系相比,长期依赖关系得到的权重是指数级小的(以 T 为单位)。

当谱半径 < 1时,时间差越长,谱半径越小。
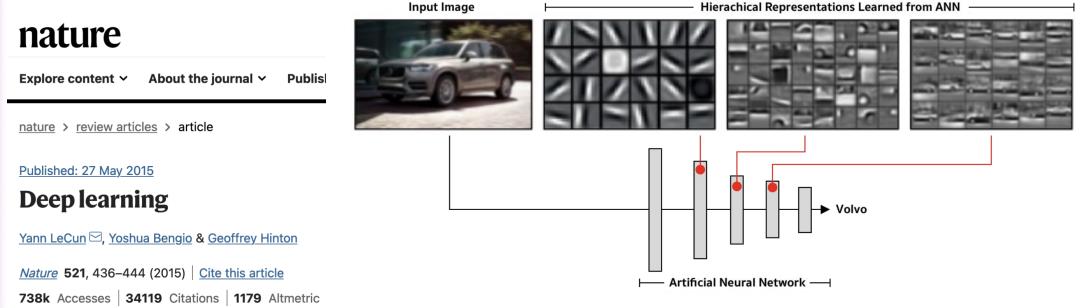
 深度学习:学习内部表征
深度学习:学习内部表征
深度学习并不像其他机器学习方法:
没有中间表示(线性)
或固定的(通常是非常高维的)中间表示(支持向量机、内核机)
那么什么是好的表征形式呢?——使其他或下游任务更容易。
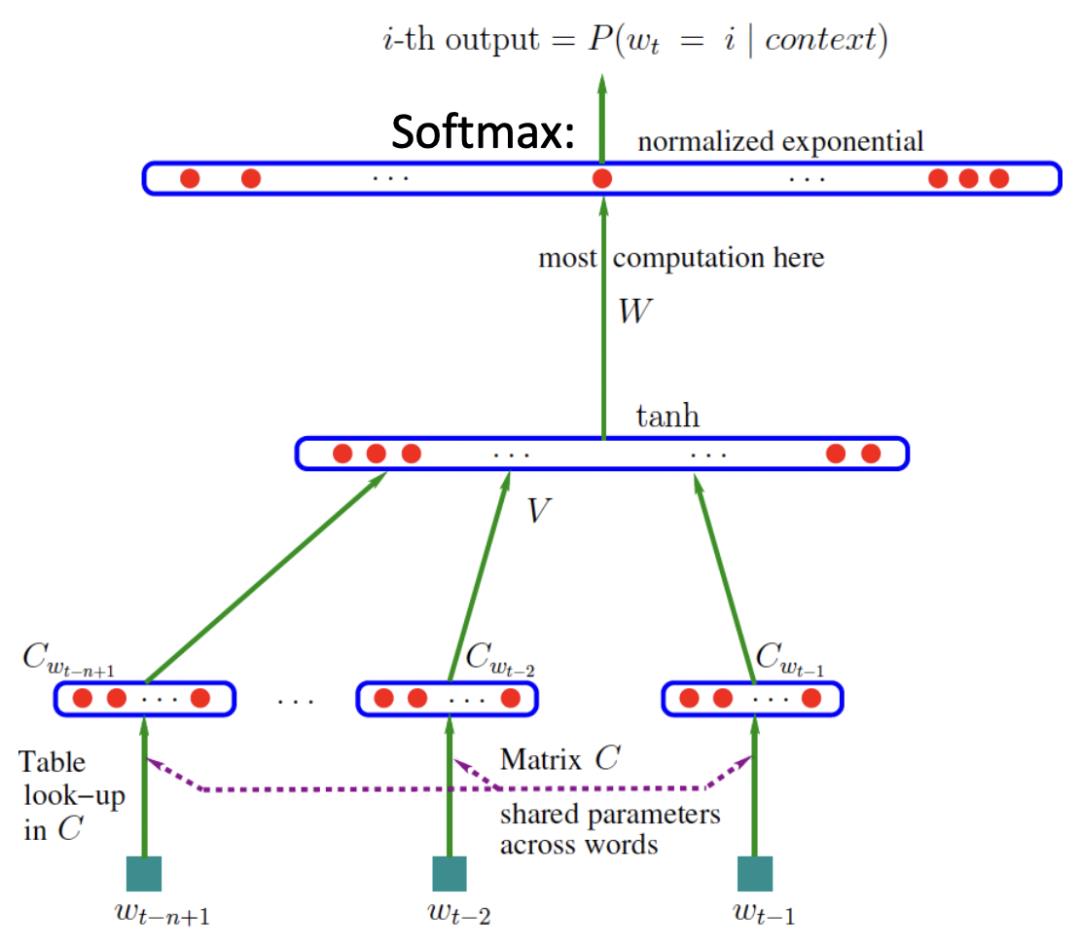
语言模型 LM
于是 Yoshua 又回顾了他们 2003 年的经典工作《A Neural Probabilistic Language Model》,这是首次用神经网络来解决语言模型的问题,也为后来深度学习在解决语言模型问题甚至很多别的 NLP 问题时,奠定了坚实的基础(比如之后 word2vec 的提出)。
每个词由一个分布式连续值代码向量表示=嵌入;
跨n-gram(单词元组)共享;
泛化到语义上与训练序列相似的单词序列
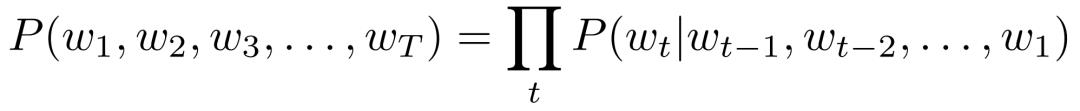
为什么要设置多层(multiple layer)?——世界是可构成的
具有不断增加的抽象级别的表示层次;
每个阶段都是一种可训练的特征变换。
图像识别:像素→边缘→文本→主题→零件→物体;
文本:文字→单词→词组→从句→句子→故事;
语音:样本→谱带→声音→……→电话→音素→单。词

随着深度学习的不断发展,不止 NLP 领域,语音和图像也迈出了重要一步:
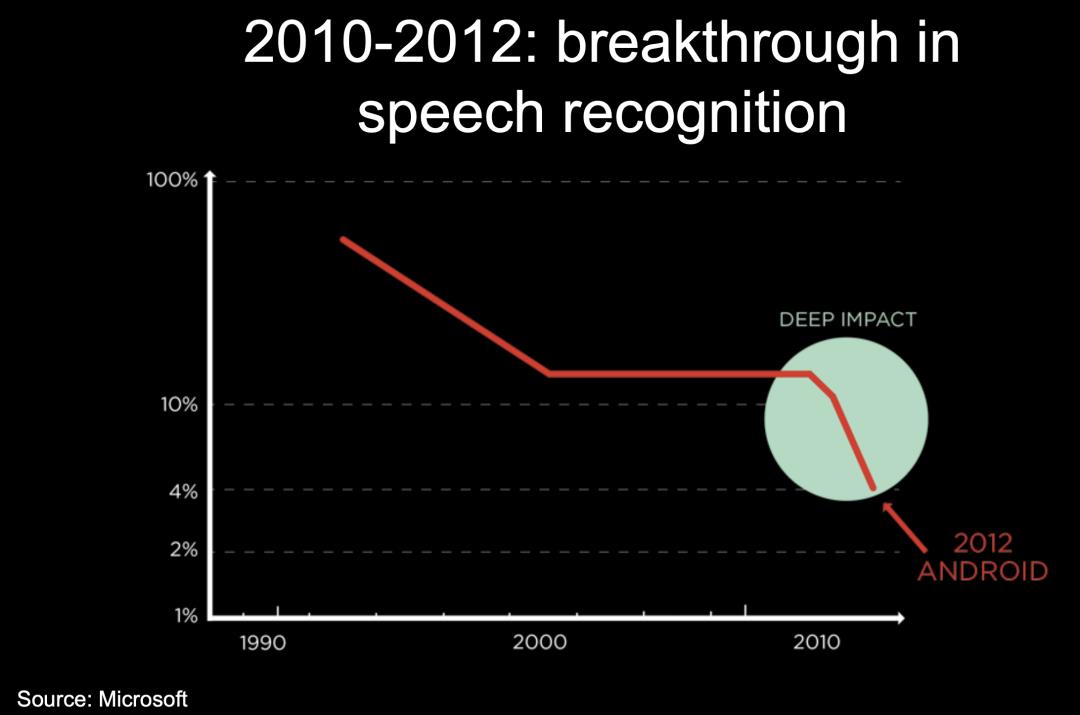
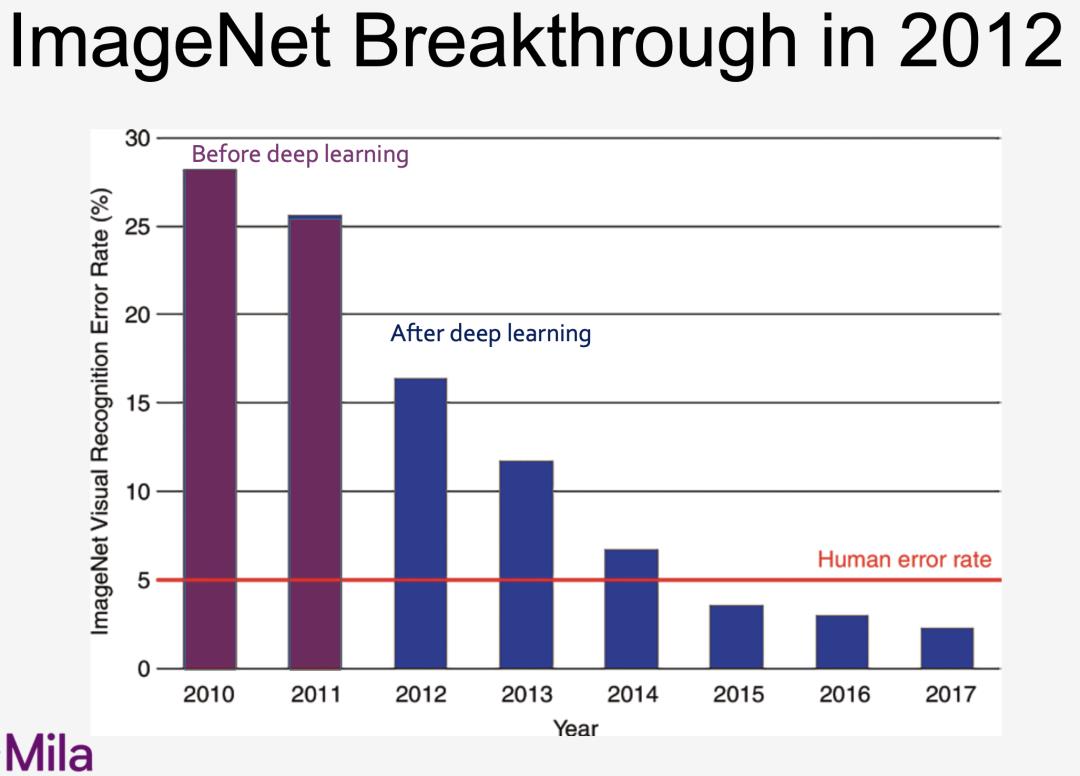
但其实 1996-2012 年也是神经网络的寒冬:
AI 研究失去了达到人类智能水平的雄心
关注“更简单”(更容易分析)的机器学习
很难说服研究生进行神经网络的研究
这需要坚持下去,但也要处理一些棘手的问题:
遵循直觉
但尝试通过实验或数学方法验证
理清思路以澄清问题,提出“为什么”问题,试着去理解
支持小组的重要性(CIFAR计划)
生成对抗网络 GAN
自 2010 年以来,Yoshua 关于生成式深度学习的论文,尤其是和 Ian Goodfellow 共同研究的生成性对抗网络(GAN),这篇经典之作更是引发了计算机视觉和图形学领域的深刻革命。

GAN 以其优越的性能,在短短两年时间里,迅速成为人工智能的一大研究热点,也将多个数据集的结果刷至新高。
Attention 机制的“革命”
对一个输入序列或图像,通过设置权重或每个输入位置的概率,正如 MLP 中所产生的那样,运用到每一个位置。Attention 在在翻译、语音、图像、视频和存储中的应用非常广泛,也具有以下的特点/优点:
一次只关注一个或几个元素;
根据具体情况,了解该让哪参与进来;
能对无序set操作;
是 NLP 中的 SOTA,为 Transformer 的提出奠定基础;
在 RNN 中绕过学习长期依赖的问题!!

强化学习
深度强化学习在 2016 年初露头角,取得巨大突破:
AlphaGo 以 4-1 击败世界冠军李世石;
人工智能和围棋专家没有预料到;
将深度学习与强化学习相结合。

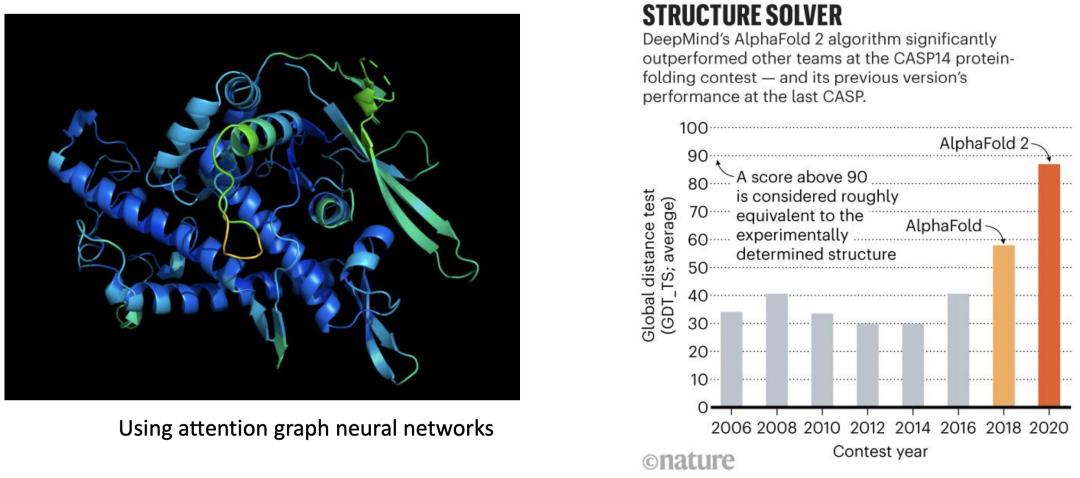
深度学习的生物学突破
除了在计算机领域的成就以外,深度学习也在生物学领域取得重要突破,英国《Nature》杂志在 2021 年发表了一项结构生物学最新研究,人工智能公司 DeepMind 的神经网络 Alphafold 2 ,利用注意力图神经网络,预测的蛋白质结构能达到原子水平的准确度,这也为生命科学领域带来革命性影响。
 心得分享
心得分享
保持谦逊
最好别想奖项、奖品和认可:这些都是危险的干扰!
自负会使我们盲目,使我们过度自信,是科学发现的敌人
损害我们灵活思考的能力,质疑我们认为理所当然的东西,倾听别人不同意我们的观点的能力
我多次改变主意:2005 年有监督 vs 无监督,2022 年频率论 vs 贝叶斯。

学习更高层次的抽象
(Bengio & LeCun 2007)
深度学习的最大回报是允许学习更高层次的抽象。
更高层次的抽象:将解释变量和它们的因果机制分离开,这将使得更容易的泛化和转移到新的任务上去。
如何发现好的解耦表征
如何发现抽象?
什么是好的表现形式?(Bengio et al 2013)
需要线索(=归纳偏差)来帮助理清潜在因素及其依赖性,例如:
空间和时间尺度
要素之间的依赖关系简单稀疏(意识优先)
因果/机制独立性(可控变量=干预)
多个时空尺度(粗略的高层因素解释了较低层的细节)
绕过维度的诅咒
我们需要在机器学习模型中构建组合性,就像人类语言利用组合性为复杂的思想赋予表征和意义一样。
利用组合性:在指代能力上获得指数级的增长;
分布式表示/嵌入:特征学习;
当前的深度架构:多层次的特征学习;
系统 2 深度学习:一次编写几个概念;
先验假设(Priori):组合性有助于有效地描述我们周围的世界。
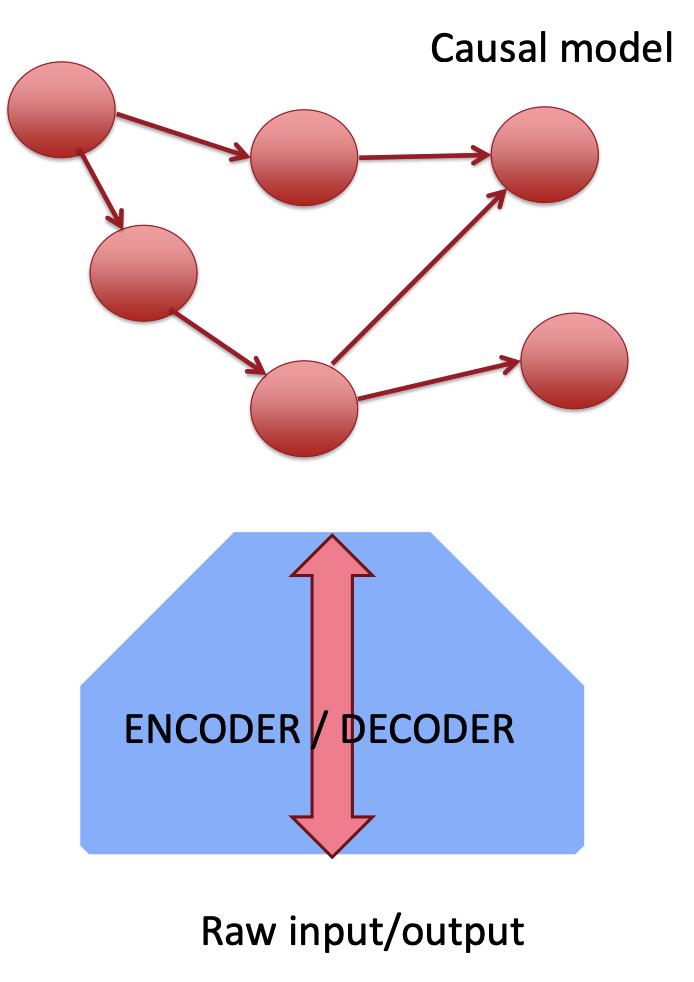
 深度学习目标:发现因果表征
深度学习目标:发现因果表征
Yoshua 之前也研究过一段时间的因果,这里他也发表了与此相关的一些看法。
我们需要了解这些问题:
正确的表述是什么?解释数据的因果变量
如何发现它们(作为观测数据的函数)?
如何发现他们的因果关系、因果图?
行动如何与因果干预相对应?
原始感官数据如何与高层因果变量相关?高层因果变量如何转化为低层行为和局部观察?
需要额外的偏见:因果关系是关于分布的变化
当前机器学习的缺失
超越训练分布的理解与泛化;
学习理论只处理同一分布内的泛化;
模型学习但不能很好地泛化(或在适应时具有高样本复杂性)修改后的分布、非平稳性等。
知识重用性差、模块化差
要超越训练分布的泛化
由于性能不佳的 OOD,目前工业强度的机器学习存在鲁棒性问题;
如果没有独立同分布(iid),需要替代假设,否则没有理由期望泛化;
分布如何变化?
人类做得更好!
来自大脑的归纳偏见?
人类如何重用知识?
系统泛化
根据之前的一些工作,将这种能力总结如下:
学过语言学;
动态重组现有概念;
即使新组合在训练分布下的概率为 0:
例如:科幻小说场景
例:在一个陌生的城市开车
目前的深度学习不太成功,它可能会“过拟合”训练分布。

SOTA AI 和人类水平智力之间的差距
其主要的差距有:
样本复杂度:学习一项任务所需的样本数量;
非分布泛化;
适应的非分布速度(迁移学习);
因果发现和推理;
复合知识表示和推理
造成差距的唯一原因:有意识的处理?
假设:这种差距源于一种与人类意识处理相关的计算、知识表示和推理,但在人工智能中尚未掌握。
有意识的处理帮助人类处理 OOD 设置
面对新奇或罕见的情况,人类总是有意识的注意力,迅速结合适当的知识片段,对它们推理,并设想解决方案。
我们不遵循我们的惯例,在新奇的环境中使用有意识的思维。
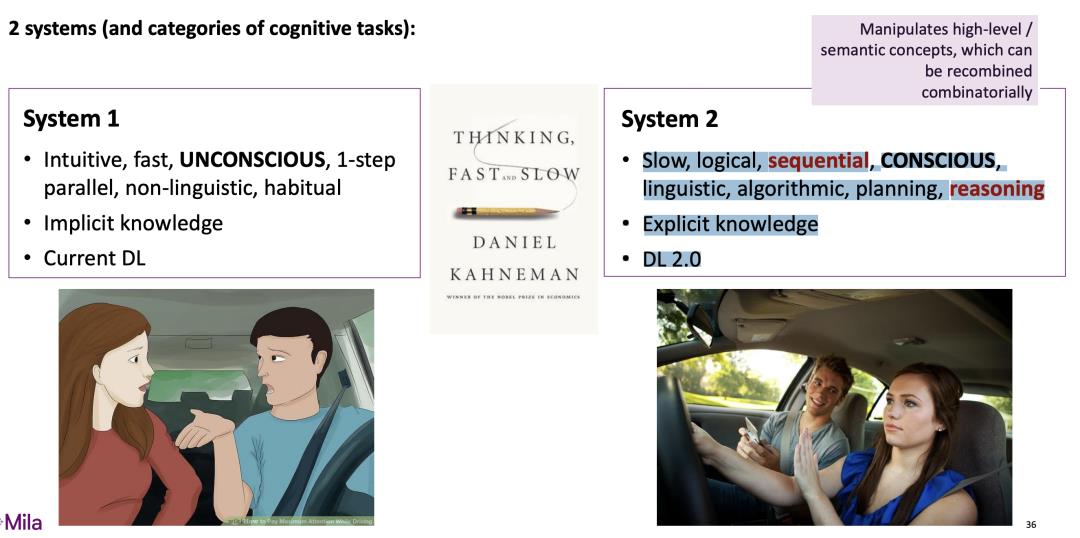
系统 1 和系统 2 的认知——2个系统(以及认知任务的类别):
系统 1
直觉、快速、无意识、一步并行、非语言、习惯性;
隐性知识;
当前 DL
系统 2
缓慢的、有逻辑的、顺序的、有意识的;
语言,算法,计划,推理;
明确的知识;
DL 2.0
从推理到 OOD 泛化
目前工业级别的机器学习(包括 NLP)由于糟糕的 OOD 性能而遭受鲁棒性问题;
人类使用更高层次的认知(系统 2)进行非分布泛化;
为什么有帮助,如何有帮助?
这与代理、因果关系有什么关系?
我们如何在深度学习中结合这些原则来获得系统 1 和系统 2 的深度学习?
将知识分解成可组合的片段进行推理
目前的深度学习:同质架构、知识没有本地化、完全分布式;
迁移学习:重用相关的知识片段,最大限度地减少干扰,最大化重用;
系统 2 推理选择和组合可命名的知识片段,形成思想(想象的未来、反事实的过去、问题的解决方案、输入的解释等)。
如何将知识分解成正确的可重组片段?
迁移到修正分布:超越 iid 假设
iid 假设太强→分布外泛化能力差;
宽松的假设:相同的因果动力学,不同的状态/干预

因果关系作为 OOD 泛化、迁移学习、持续学习等的框架:
非平稳知识(变量值)的因子平稳知识(因果机制);
干预=变量的改变,不仅仅是由于默认的因果链接,而是由于代理;
因果模型=分布族(包括任务);
这些分布的指标是干预措施的选择(或初始状态);
固定知识被分解成可重组的因果机制
为什么需要因果?
因果模型=通过干预/环境/初始状态等与共享参数(机制)索引的分布族
学习者必须预测干预措施的效果,需要解决 Out-Of-Distribution(OOD)=新的干预措施;
干预=完美实现代理的抽象动作;
更现实:实现抽象变量变化的意图=目标;
与多任务和元学习不同,不是学习特定于任务或环境的参数,而是对干预进行推断
Yoshua 团队今年在因果领域研究也有着一个研究成果——作为概率推理机的大型深度网络:

 总结
总结
最后,Yoshua 也表达了自己的愿景:让机器学习走出实验室,走入社会。
机器学习不再只是一个研究问题
基于机器学习的产品正在设计和部署中
而这也是人工智能科学家、工程师、企业家和政府的共同的新责任。
而 AI 也是一个强大的工具,要重点关注它的:
双重用途;
智慧竞赛:技术进步 vs 智慧进步;
如何最大化其有益的使用,以及减少其误用?
同时,一切事物都像双刃剑,AI 也不例,我们也应当避免一些对于社会的负面影响:
控制人们思想的 Big Brother 和杀手机器人;
失业人士的痛苦来源,至少在过渡转型时期是这样;
来自广告和社交媒体的操纵;
强化社会偏见和歧视;
使得不平等加剧,权力集中在少数人、公司和国家。

以上是关于图灵奖得主Yoshua Bengio的一生!的主要内容,如果未能解决你的问题,请参考以下文章