如何保证缓存和数据库的一致性?
Posted _江南一点雨
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了如何保证缓存和数据库的一致性?相关的知识,希望对你有一定的参考价值。
文章目录
很多小伙伴在面试的时候,应该都遇到过类似的问题,如何确保缓存和数据库的一致性?
如果你对这个问题有过研究,应该可以发现这个问题其实很好回答,如果第一次听到或者第一次遇到这个问题,估计会有点懵,今天我们来聊聊这个话题。
1. 问题分析
首先我们来看看为什么会有这个问题!
我们在日常开发中,为了提高数据响应速度,可能会将一些热点数据保存在缓存中,这样就不用每次都去数据库中查询了,可以有效提高服务端的响应速度,那么目前我们最常使用的缓存就是 Redis 了。
用 Redis 做缓存,并不是一说缓存就是 Redis,还是要结合业务的具体情况,我们可以根据不同业务对数据要求的实时性不同,将数据分为三级,以电商项目为例:
- 第 1 级:订单数据和支付流水数据:这两块数据对实时性和精确性要求很高,所以一般是不需要添加缓存的,直接操作数据库即可。
- 第 2 级:用户相关数据:这些数据和用户相关,具有读多写少的特征,所以我们使用 redis 进行缓存。
- 第 3 级:支付配置信息:这些数据和用户无关,具有数据量小,频繁读,几乎不修改的特征,所以我们使用本地内存进行缓存。
选中合适的数据存入 Redis 之后,接下来,每当要读取数据的时候,就先去 Redis 中看看有没有,如果有就直接返回;如果没有,则去数据库中读取,并且将从数据库中读取到的数据缓存到 Redis 中,大致上就是这样一个流程,读取数据的这个流程实际上是比较清晰也比较简单的,没啥好说的。
然而,当数据存入缓存之后,如果需要更新的话,往往会来带另外的问题:
- 当有数据需要更新的时候,先更新缓存还是先更新数据库?如何确保更新缓存和更新数据库这两个操作的原子性?
- 更新缓存的时候该怎么更新?修改还是删除?
怎么办?正常来说,我们有四种方案:
- 先更新缓存,再更新数据库。
- 先更新数据库,再更新缓存。
- 先淘汰缓存,再更新数据库。
- 先更新数据库,再淘汰缓存。
到底使用哪种?
在回答这个问题之前,我们不妨先来看看三个经典的缓存模式:
- Cache-Aside
- Read-Through/Write through
- Write Behind
2. Cache-Aside
Cache-Aside,中文也叫旁路缓存模式,如果我们能够在项目中采用 Cache-Aside,那么就能够尽可能的解决缓存与数据库数据不一致的问题,注意是尽可能的解决,并无法做到绝对解决。
Cache-Aside 又分为读缓存和写缓存两种情况,我们分别来看。
2.1 读缓存
先来看一张流程图:
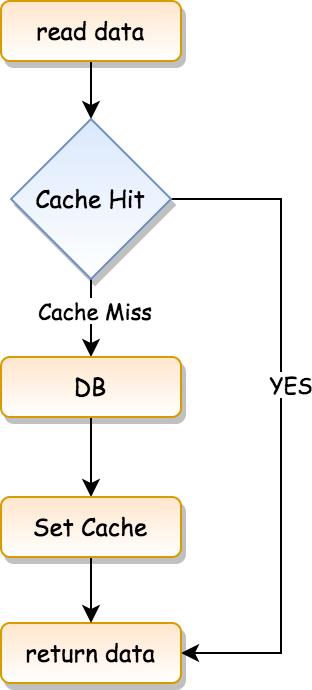
它的流程是这样:
- 读取数据。
- 检查缓存中是否有需要的数据,如果命中缓存(Cache Hit),则直接返回数据。
- 如果没有命中缓存,即 Cache Miss,那么就先去访问数据库。
- 将从数据库中读取到的数据设置到缓存中。
- 返回数据。
这是 Cache-Aside 的读缓存流程。
其实对于读缓存的流程而言,大家一般都没什么异议,有异议的主要是写流程,我们继续来看。
2.2 写缓存
先来看一张流程图:
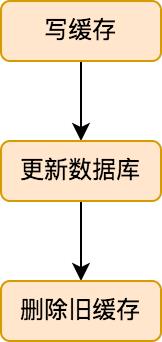
这个写缓存的流程就比较简单,先更新数据库中的数据,然后删除旧的缓存即可。
流程虽然简单,但是却引伸出来两个问题:
- 为什么是删除旧缓存而不是更新旧缓存?
- 为什么不先删除旧的缓存,然后再更新数据库?
我们来分别回答这两个问题。
为什么是删除旧缓存而不是更新旧缓存?
- 更新缓存,说着容易做起来并不容易。很多时候我们更新缓存并不是简简单单更新一个 Bean。很多时候,我们缓存的都是一些复杂操作或者计算(例如大量联表操作、一些分组计算)的结果,如果不加缓存,不但无法满足高并发量,同时也会给 mysql 数据库带来巨大的负担。那么对于这样的缓存,更新起来实际上并不容易,此时选择删除缓存效果会更好一些。
- 对于一些写频繁的应用,如果按照
更新缓存->更新数据库的模式来,比较浪费性能,因为首先写缓存很麻烦,其次每次都要写缓存,但是可能写了十次,只读了一次,读的时候读到的缓存数据是第十次的,前面九次写缓存都是无效的,对于这种情况不如采取先写数据库再删除缓存的策略。 - 在多线程环境下,这样的更新策略还有可能会导致数据逻辑错误,来看如下一张流程图:
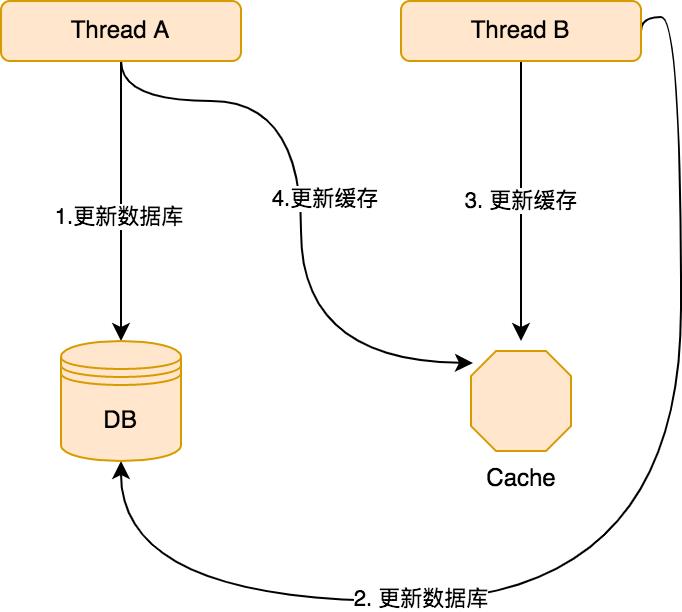
可以看到,有两个并发的线程 A 和 B:
- 首先 A 线程更新了数据库。
- 接下来 B 线程更新了数据库。
- 由于网络等原因,B 线程先更新了缓存。
- A 线程更新了缓存。
那么此时,缓存中保存的数据就是不正确的,而如果采用了删除缓存的方式,就不会发生这种问题了。
为什么不先删除旧的缓存,然后再更新数据库?
这个也是考虑到并发请求,假设我们先删除旧的缓存,然后再更新数据库,那么就有可能出现如下这种情况:
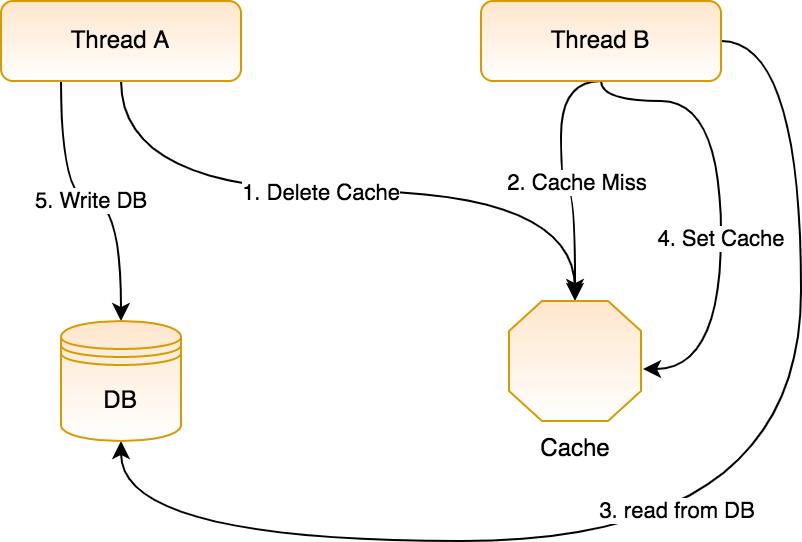
这个操作是这样的,有两个线程,A 和 B,其中 A 写数据,B 读数据,具体流程如下:
- A 线程首先删除缓存。
- B 线程读取缓存,发现缓存中没有数据。
- B 线程读取数据库。
- B 线程将从数据库中读取到的数据写入缓存。
- A 线程更新数据库。
一套操作下来,我们发现数据库和缓存中的数据不一致了!所以,在 Cache-Aside 中是先更新数据库,再删除缓存。
2.3 延迟双删
其实无论是先更新数据库再删除缓存,还是先删除缓存再更新数据库,在并发环境下都有可能存在问题:
假设有 A、B 两个并发请求:
- 先更新数据库再删除缓存:当请求 A 更新数据库之后,还未来得及进行缓存清除,此时请求 B 查询到并使用了 Cache 中的旧数据。
- 先删除缓存再更新数据库:当请求 A 执行清除缓存后,还未进行数据库更新,此时请求 B 进行查询,查到了旧数据并写入了 Cache。
当然我们前面已经分析过了,尽量先操作数据库再操作缓存,但是即使这样也还是有可能存在问题,解决问题的办法就是延迟双删。
延迟双删是这样:先执行缓存清除操作,再执行数据库更新操作,延迟 N 秒之后再执行一次缓存清除操作,这样就不用担心缓存中的数据和数据库中的数据不一致了。
那么这个延迟 N 秒,N 是多大比较合适呢?一般来说,N 要大于一次写操作的时间,如果延迟时间小于写入缓存的时间,会导致请求 A 已经延迟清除了缓存,但是此时请求 B 缓存还未写入,具体是多少,就要结合自己的业务来统计这个数值了。
2.4 如何确保原子性
但是更新数据库和删除缓存毕竟不是一个原子操作,要是数据库更新完毕后,删除缓存失败了咋办?
对于这种情况,一种常见的解决方案就是使用消息中间件来实现删除的重试。大家知道,MQ 一般都自带消费失败重试的机制,当我们要删除缓存的时候,就往 MQ 中扔一条消息,缓存服务读取该消息并尝试删除缓存,删除失败了就会自动重试。如果小伙伴们还不懂 RabbitMQ 的使用,可以在公众号江南一点雨后台回复 rabbitmq,有免费的视频+文档。
3. Read-Through/Write-Through
这种缓存操作模式,松哥印象最深的是在 Oracle Coherence 中有应用,不知道小伙伴们有没有用过 Oracle Coherence,这是一个内存数据网格,通过这个,应用开发人员和管理人员可快速访问键值数据,Coherence 可提供集群式低延迟数据存储、多语言网格计算和异步事件流处理,从而为客户企业应用赋予超高水平的可扩展性和性能。
Oracle Coherence 我们就不讨论了,我们就来说说 Read-Through。
3.1 Read-Through
这里为了省事,我就不自己画图了,网上找了一张图片,如下:
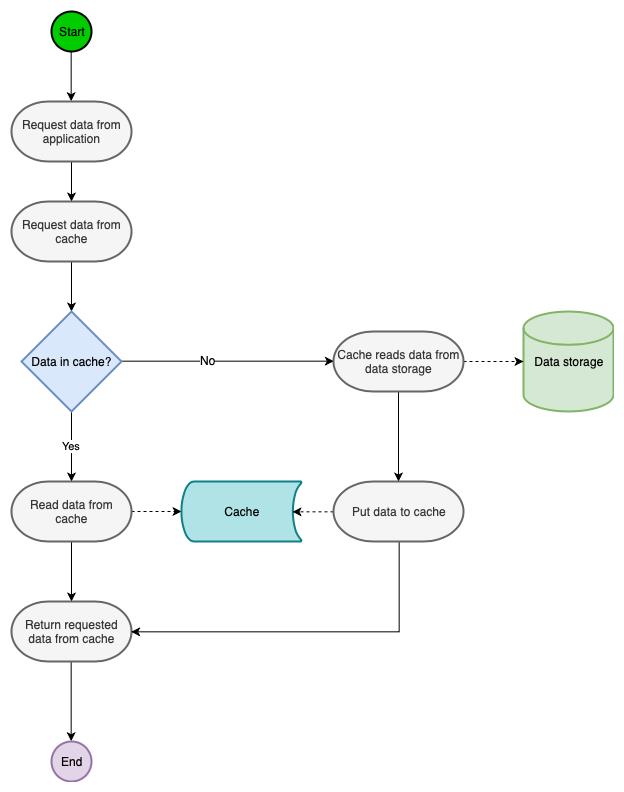
乍一看,很多人感觉这和 Cache-Aside 一样呀,没啥区别!是的,单看流程是不太容易看到区别。
Read-Through 是一种类似于 Cache-Aside 的缓存方法,区别在于,在 Cache-Aside 中,由应用程序决定去读取缓存还是读取数据库,这样就会导致应用程序中出现了很多业务无关的代码;而在 Read-Through 中,相当于多出来了一个中间层 Cache Middleware,由它去读取缓存或者数据库,应用层的代码得到了简化,松哥之前写过 Spring Cache 的用法,大家回忆下 Spring Cache 中的 @Cacheable 注解,感觉像不像 Read-Through?
我画一个简单的流程图大家来看下:
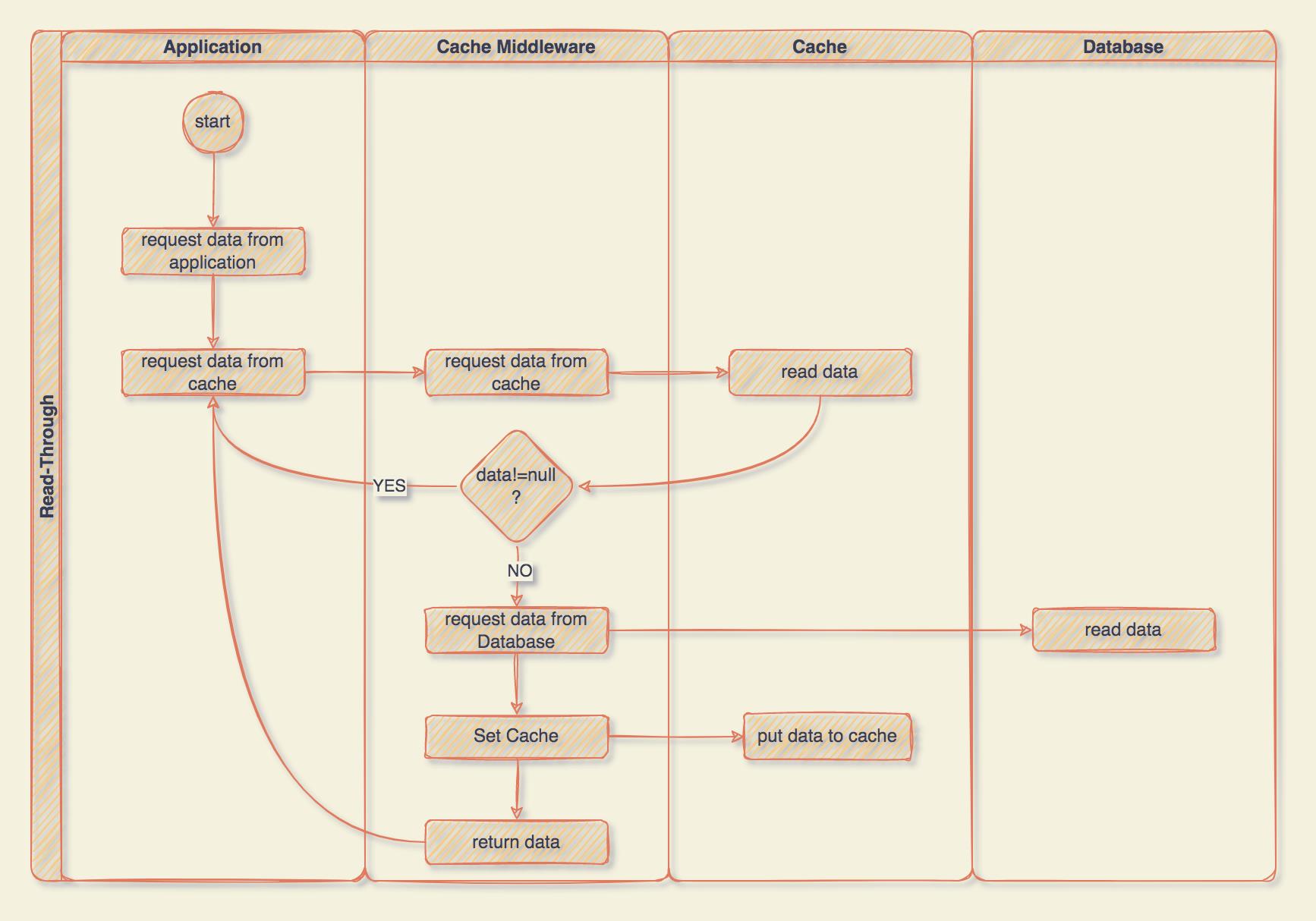
可以看到,和 Cache-Aside 相比,其实就相当于是多了一个 Cache Middleware,这样我们在应用程序中就只需要正常的读写数据就行了,并不用管底层的具体逻辑,相当于把缓存相关的代码从应用程序中剥离出来了,应用程序只需要专注于业务就行了。
3.2 Write-Through
Write-Through 其实也是差不多,所有的操作都交给 Cache Middleware 来完成,应用程序中就是一句简单的更新就行了,我们来看看流程:
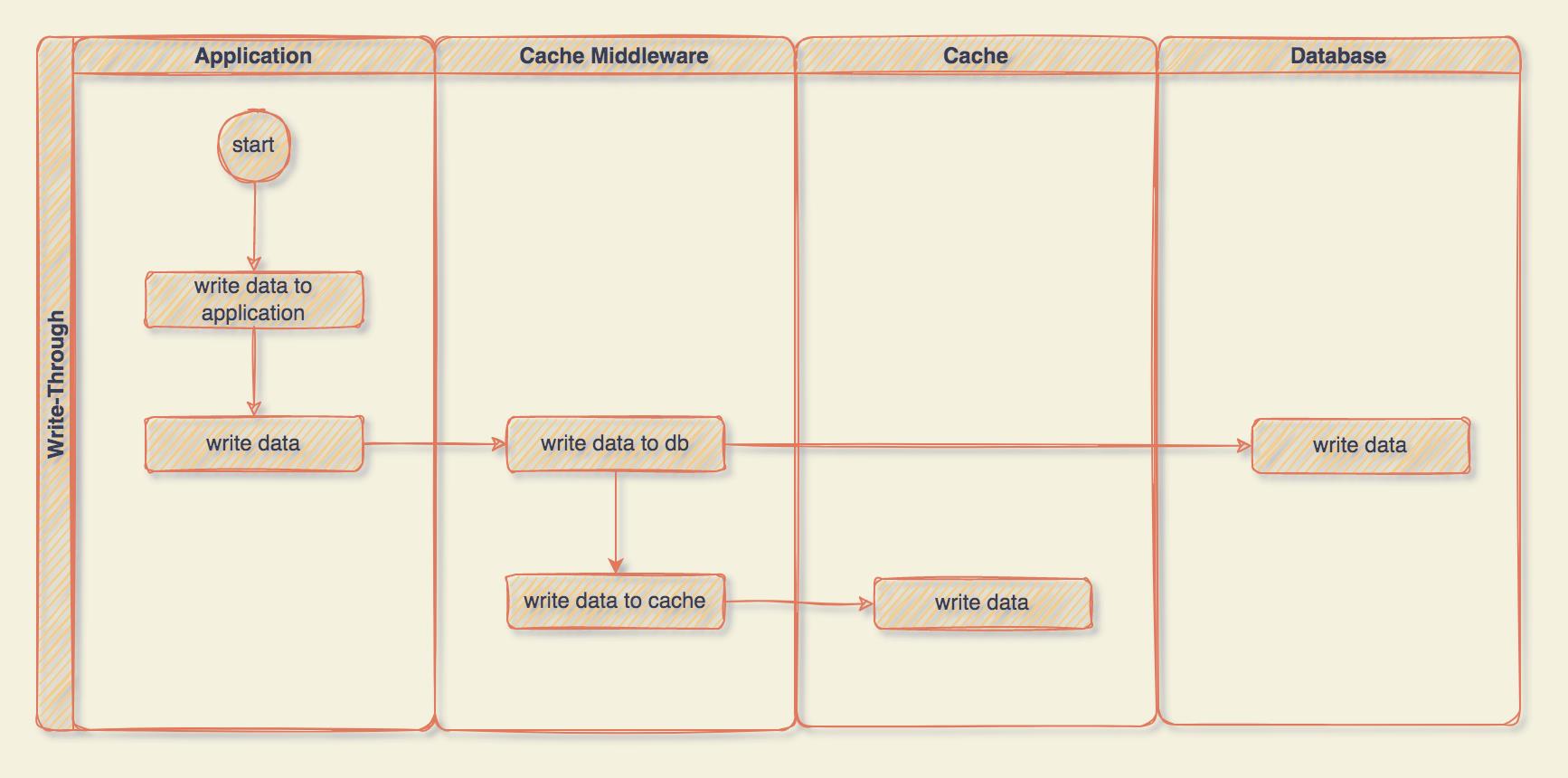
在 Write-Through 策略中,所有的写操作都经过 Cache Middleware,每次写入时,Cache Middleware 会将数据存储在 DB 和 Cache 中,这两个操作发生在一个事务中,因此,只有两个都写入成功,一切才会成功。
这种写数据的优势在于,应用程序只与 Cache Middleware 对话,所以它的代码更加干净和简单。
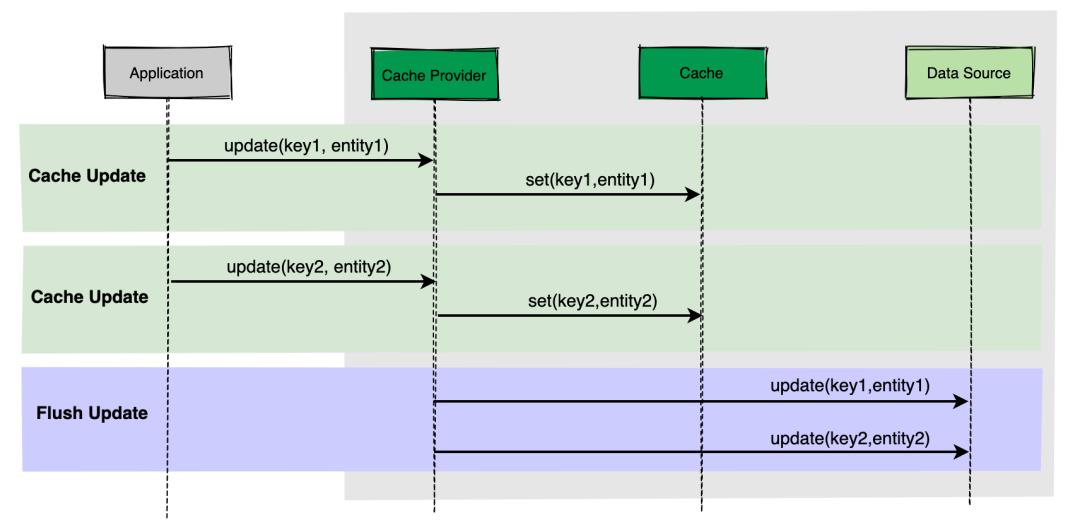
4. Write Behind
Write-Behind 缓存策略类似于 Write-Through 缓存,应用程序仅与 Cache Middleware 通信,Cache Middleware 会预留一个与应用程序通信的接口。
Write-Behind 与 Write-Through 最大的区别在于,前者是数据首先写入缓存,一段时间后(或通过其他触发器)再将数据写入 Database,并且这里涉及到的写入是一个异步操作。这种方式下,Cache 和 DB 数据的一致性不强,对一致性要求高的系统要谨慎使用,如果有人在数据尚未写入数据源的情况下直接从数据源获取数据,则可能导致获取过期数据,不过对于频繁写入的场景,这个其实非常适用。
将数据写入 DB 可以通过多种方式完成:
- 一种是收集所有写入操作,然后在某个时间点(例如,当 DB 负载较低时)对数据源进行批量写入。
- 另一种方法是将写入合并成更小的批次,例如每次收集五个写入操作,然后对数据源进行批量写入。
这个流程图就不想画了,在网上找了一张,小伙伴们参考下:
好啦,和小伙伴们简单聊了下双写一致性的问题,有问题欢迎留言讨论。
参考资料:
- https://www.jianshu.com/p/a8eb1412471f
- https://catsincode.com/caching-strategy/
以上是关于如何保证缓存和数据库的一致性?的主要内容,如果未能解决你的问题,请参考以下文章
REDIS11_缓存和数据库一致性如何保证解决方案提供Canel解决数据一致性问题