基于Confluent+Flink的实时数据分析最佳实践
Posted 阿里云云栖号
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了基于Confluent+Flink的实时数据分析最佳实践相关的知识,希望对你有一定的参考价值。
简介:在实际业务使用中,需要经常实时做一些数据分析,包括实时PV和UV展示,实时销售数据,实时店铺UV以及实时推荐系统等,基于此类需求,Confluent+实时计算Flink版是一个高效的方案。
业务背景
在实际业务使用中,需要经常实时做一些数据分析,包括实时PV和UV展示,实时销售数据,实时店铺UV以及实时推荐系统等,基于此类需求,Confluent+实时计算Flink版是一个高效的方案。
Confluent是基于Apache Kafka提供的企业级全托管流数据服务,由 Apache Kafka 的原始创建者构建,通过企业级功能扩展了 Kafka 的优势,同时消除了 Kafka管理或监控的负担。
实时计算Flink版是阿里云基于 Apache Flink 构建的企业级实时大数据计算商业产品。实时计算 Flink 由 Apache Flink 创始团队官方出品,拥有全球统一商业化品牌,提供全系列产品矩阵,完全兼容开源 Flink API,并充分基于强大的阿里云平台提供云原生的 Flink 商业增值能力。
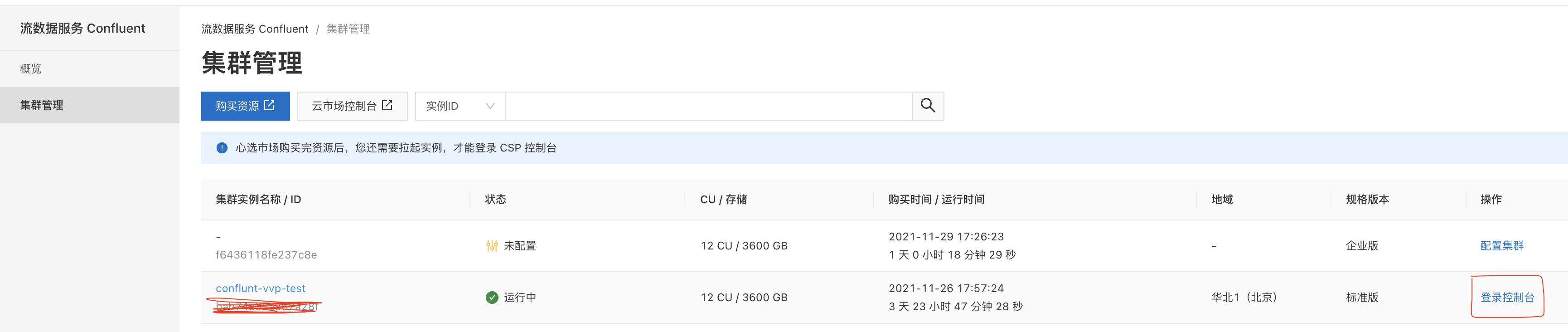
一、准备工作-创建Confluent集群和实时计算Flink版集群
- 登录Confluent管理控制台,创建Confluent集群,创建步骤参考 Confluent集群开通
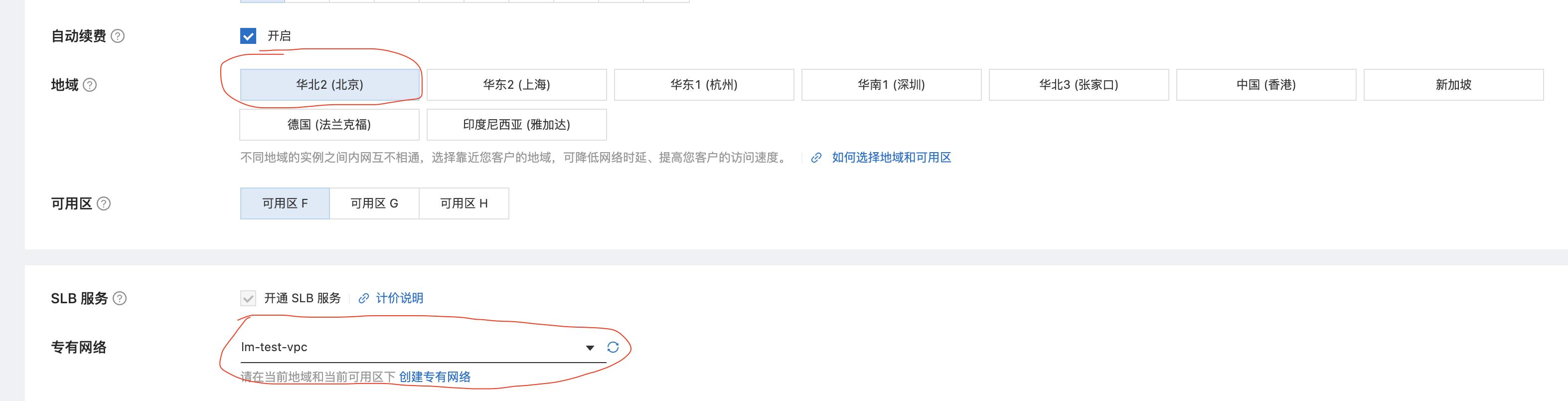
- 登录实时计算Flink版管理控制台,创建vvp集群。请注意,创建vvp集群选择的vpc跟confluent集群的region和vpc使用同一个,这样可以在vvp内部访问confluent的内部域名。
二、最佳实践-实时统计玩家充值金额-Confluent+实时计算Flink+Hologres
2.1 新建Confluent消息队列
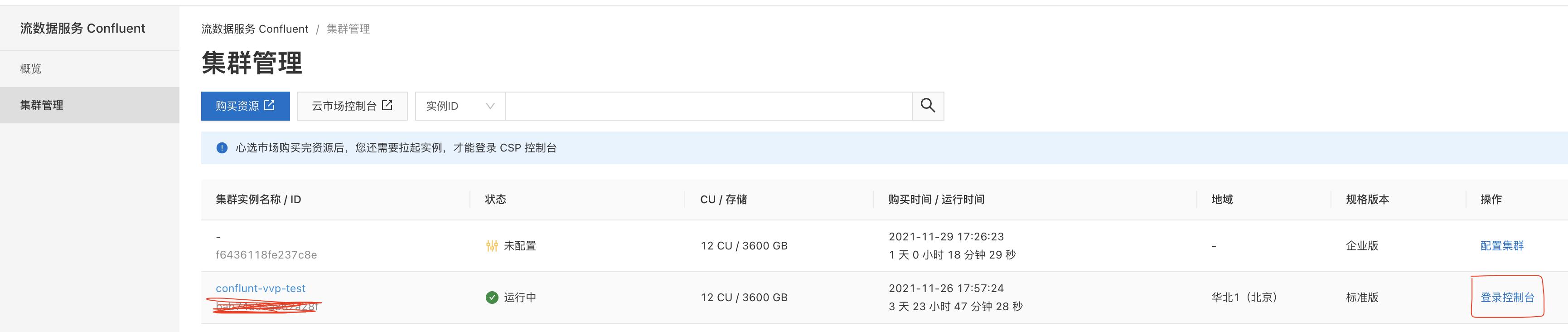
- 在confluent集群列表页,登录control center
- 在左侧选中Topics,点击
Add a topic按钮,创建一个名为confluent-vvp-test的topic,将partition设置为3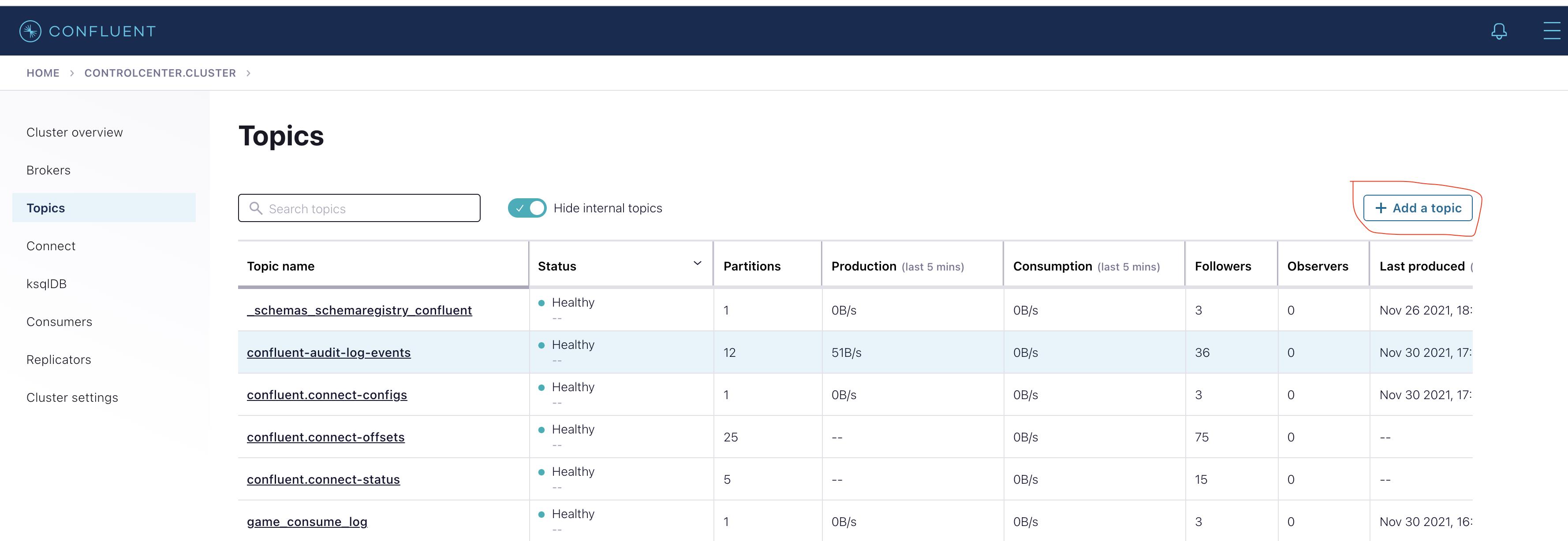
2.2 配置结果表 Hologres
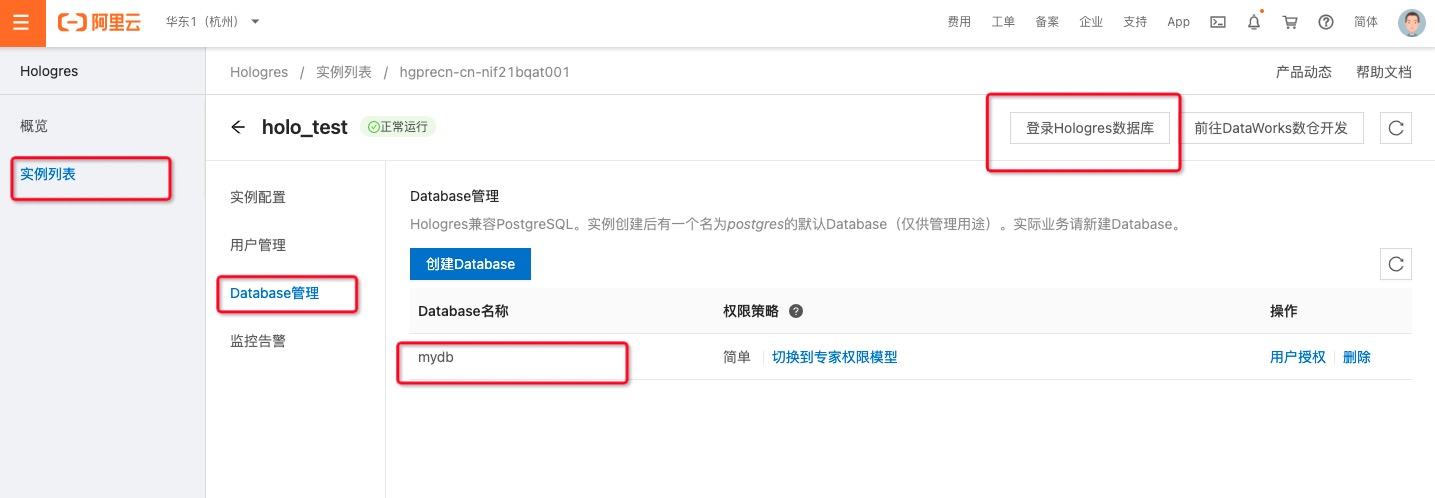
- 进入Hologres控制台,点击Hologres实例,在DB管理中新增数据库`mydb`
- 登录Hologres数据库,新建SQL
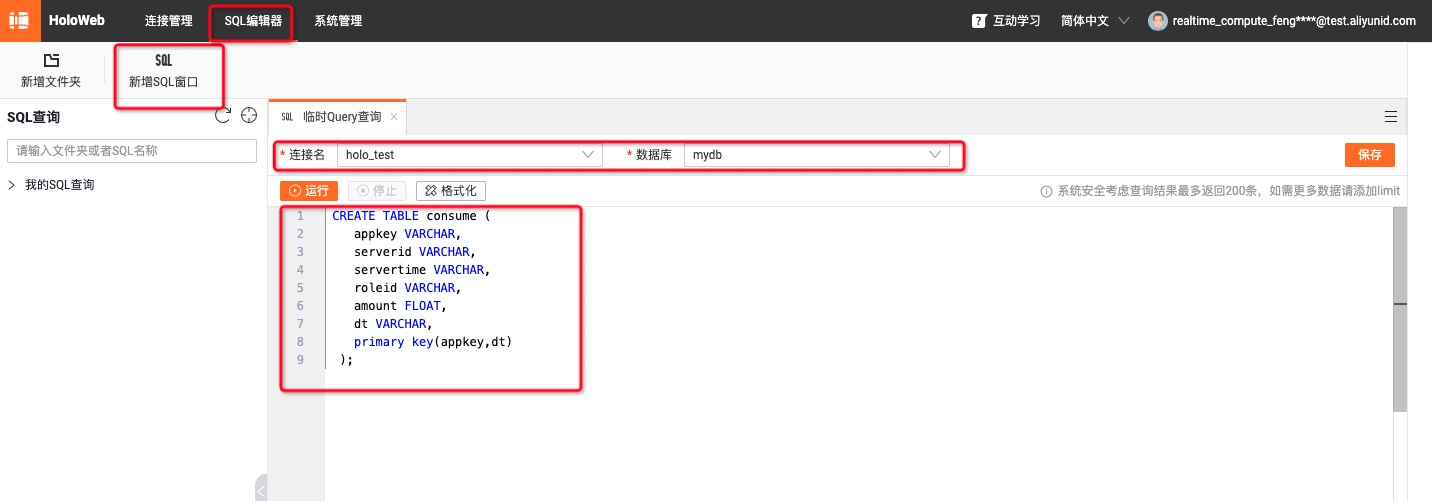
- Hologres中创建结果表 SQL语句
--用户累计消费结果表
CREATE TABLE consume (
appkey VARCHAR,
serverid VARCHAR,
servertime VARCHAR,
roleid VARCHAR,
amount FLOAT,
dt VARCHAR,
primary key(appkey,dt)
);
2.3 创建实时计算vvp作业
- 首先登录vvp控制台,选择集群所在region,点击控制台,进入开发界面
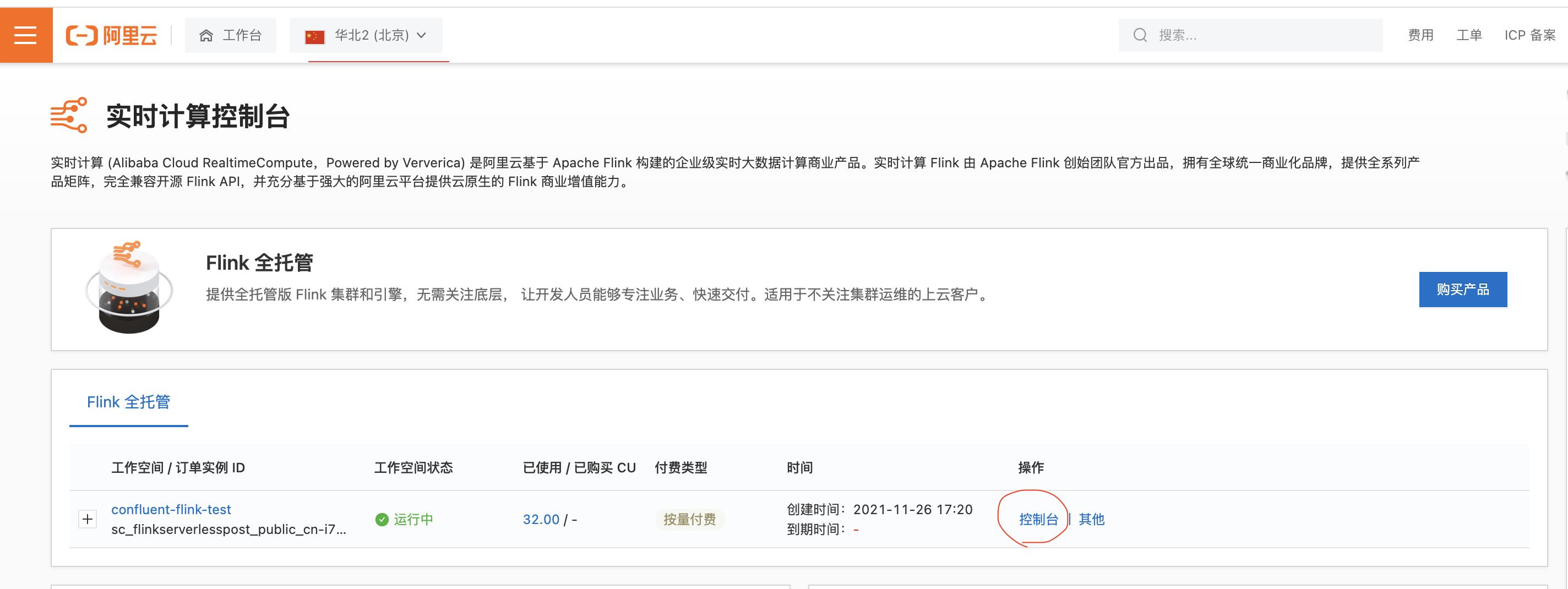
- 点击作业开发Tab,点击新建文件,文件名称:confluent-vvp-hologres,文件类型选择:流作业/SQL
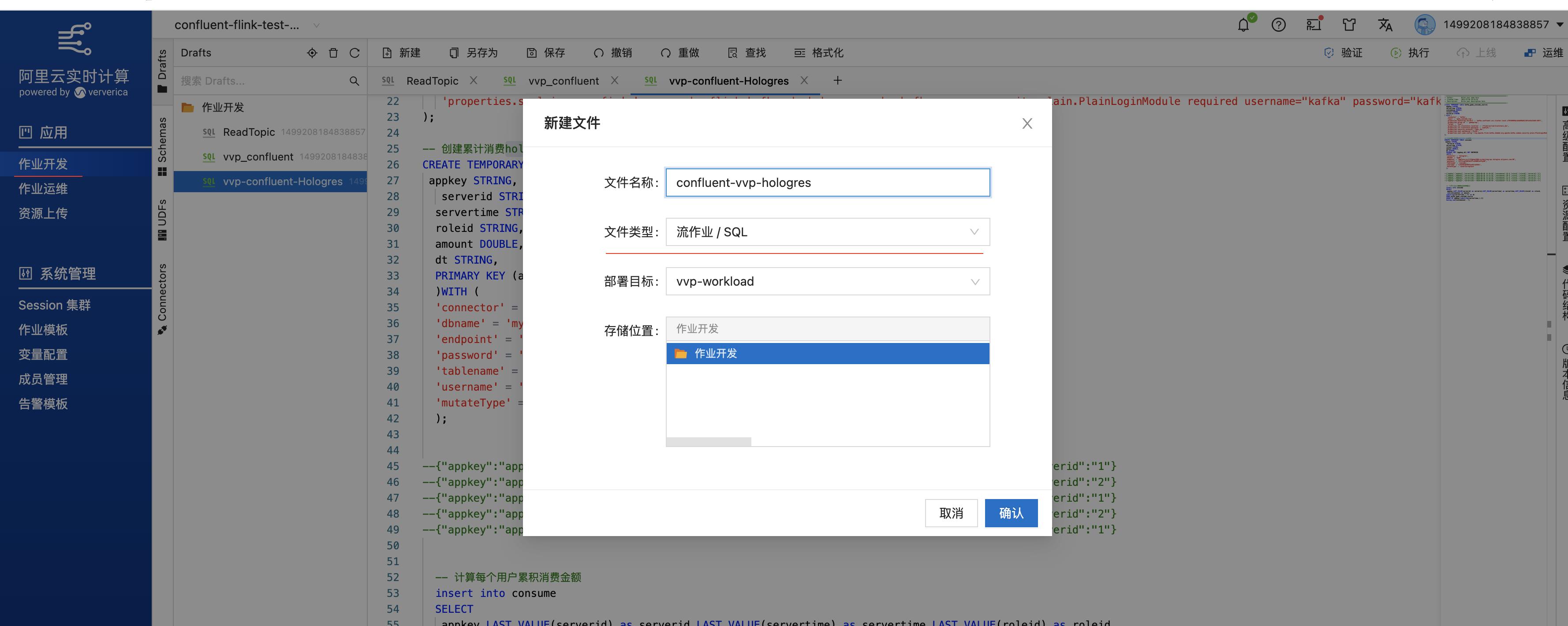
- 在输入框写入以下代码:
create TEMPORARY table kafka_game_consume_source( appkey STRING, servertime STRING, consumenum DOUBLE, roleid STRING, serverid STRING ) with ( 'connector' = 'kafka', 'topic' = 'game_consume_log', 'properties.bootstrap.servers' = 'kafka.confluent.svc.cluster.local.xxx:9071[xxx可以找开发同学查看]', 'properties.group.id' = 'gamegroup', 'format' = 'json', 'properties.ssl.truststore.location' = '/flink/usrlib/truststore.jks', 'properties.ssl.truststore.password' = '[your truststore password]', 'properties.security.protocol'='SASL_SSL', 'properties.sasl.mechanism'='PLAIN', 'properties.sasl.jaas.config'='org.apache.flink.kafka.shaded.org.apache.kafka.common.security.plain.PlainLoginModule required username="xxx[集群的用户]" password="xxx[相应的密码]";' ); -- 创建累计消费hologres sink表 CREATE TEMPORARY TABLE consume( appkey STRING, serverid STRING, servertime STRING, roleid STRING, amount DOUBLE, dt STRING, PRIMARY KEY (appkey,dt) NOT ENFORCED )WITH ( 'connector' = 'hologres', 'dbname' = 'mydb', 'endpoint' = 'hgprecn-cn-tl32gkaet006-cn-beijing-vpc.hologres.aliyuncs.com:80', 'password' = '[your appkey secret]', 'tablename' = 'consume', 'username' = '[your app key]', 'mutateType' = 'insertorreplace' ); --"appkey":"appkey1","servertime":"2020-09-30 14:10:36","consumenum":33.8,"roleid":"roleid1","serverid":"1" --"appkey":"appkey2","servertime":"2020-09-30 14:11:36","consumenum":30.8,"roleid":"roleid2","serverid":"2" --"appkey":"appkey1","servertime":"2020-09-30 14:13:36","consumenum":31.8,"roleid":"roleid1","serverid":"1" --"appkey":"appkey2","servertime":"2020-09-30 14:20:36","consumenum":33.8,"roleid":"roleid2","serverid":"2" --"appkey":"appkey1","servertime":"2020-09-30 14:30:36","consumenum":73.8,"roleid":"roleid1","serverid":"1" -- 计算每个用户累积消费金额 insert into consume SELECT appkey,LAST_VALUE(serverid) as serverid,LAST_VALUE(servertime) as servertime,LAST_VALUE(roleid) as roleid, sum(consumenum) as amount, substring(servertime,1,10) as dt FROM kafka_game_consume_source GROUP BY appkey,substring(servertime,1,10) having sum(consumenum) > 0;
- 在高级配置里,增加依赖文件truststore.jks(访问内部域名得添加这个文件,访问公网域名可以不用),访问依赖文件的固定路径前缀都是/flink/usrlib/(这里就是/flink/usrlib/truststore.jks)
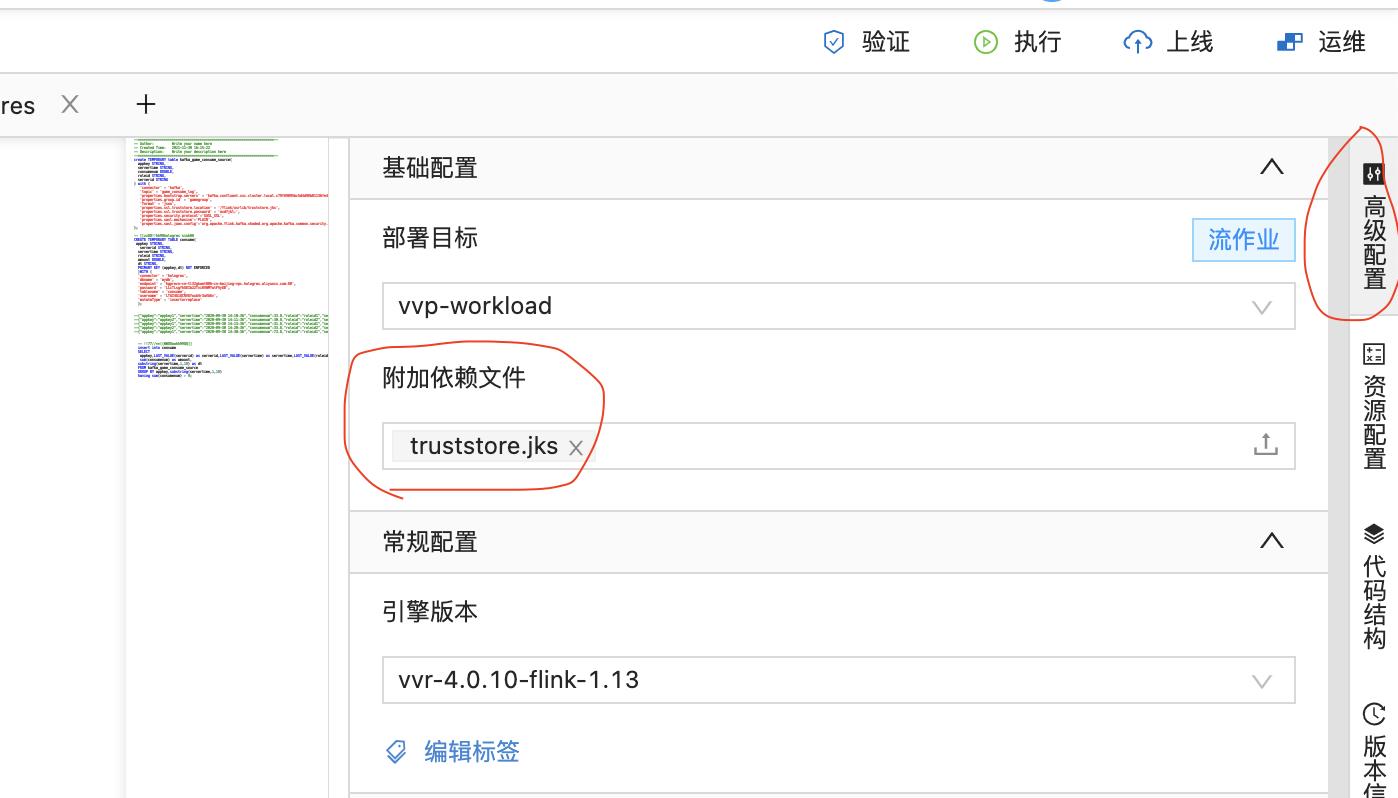
- 点击上线按钮,完成上线
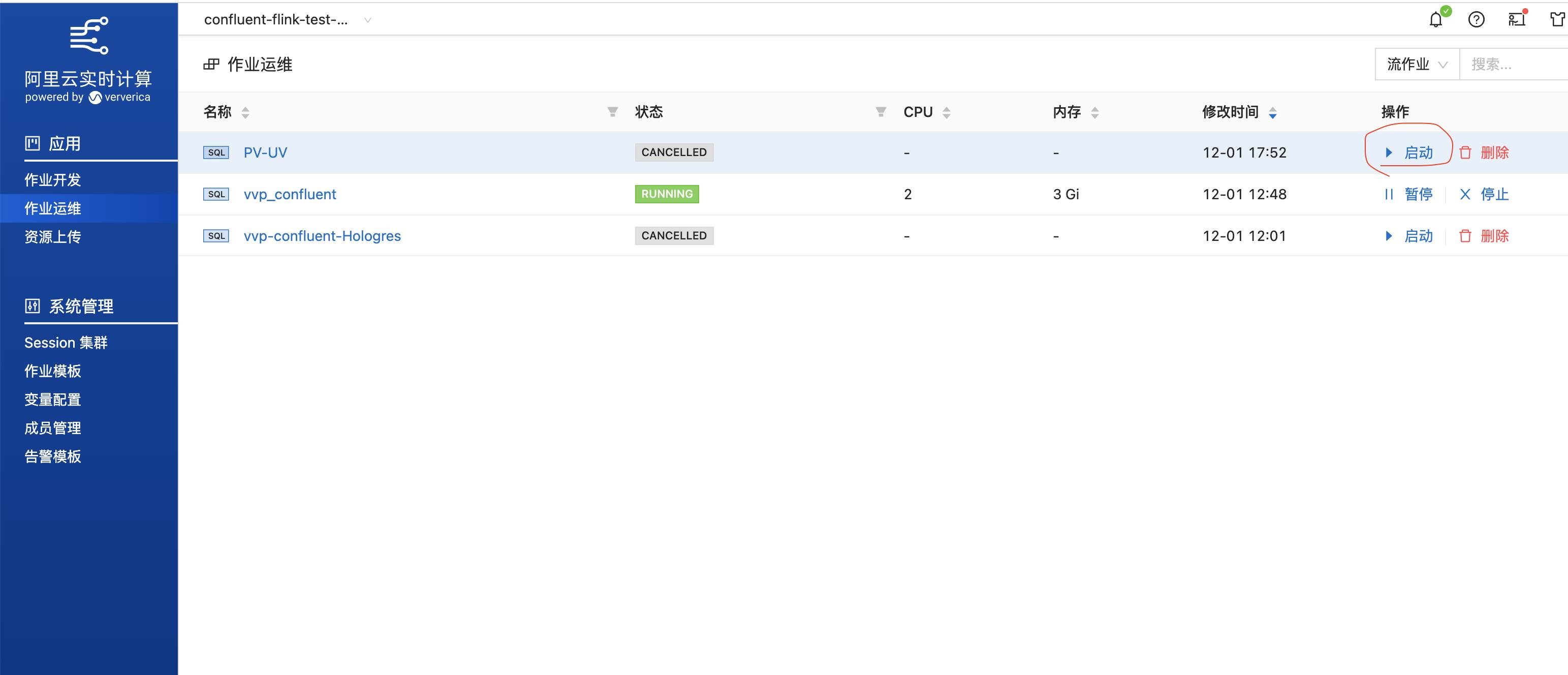
- 在运维作用列表里找到刚上线的作用,点击启动按钮,等待状态更新为running,运行成功。
- 在control center的【Topics->Messages】页面,逐条发送测试消息,格式为:
"appkey":"appkey1","servertime":"2020-09-30 14:10:36","consumenum":33.8,"roleid":"roleid1","serverid":"1" "appkey":"appkey2","servertime":"2020-09-30 14:11:36","consumenum":30.8,"roleid":"roleid2","serverid":"2" "appkey":"appkey1","servertime":"2020-09-30 14:13:36","consumenum":31.8,"roleid":"roleid1","serverid":"1" "appkey":"appkey2","servertime":"2020-09-30 14:20:36","consumenum":33.8,"roleid":"roleid2","serverid":"2" "appkey":"appkey1","servertime":"2020-09-30 14:30:36","consumenum":73.8,"roleid":"roleid1","serverid":"1"
2.4 查看用户充值金额实时统计效果
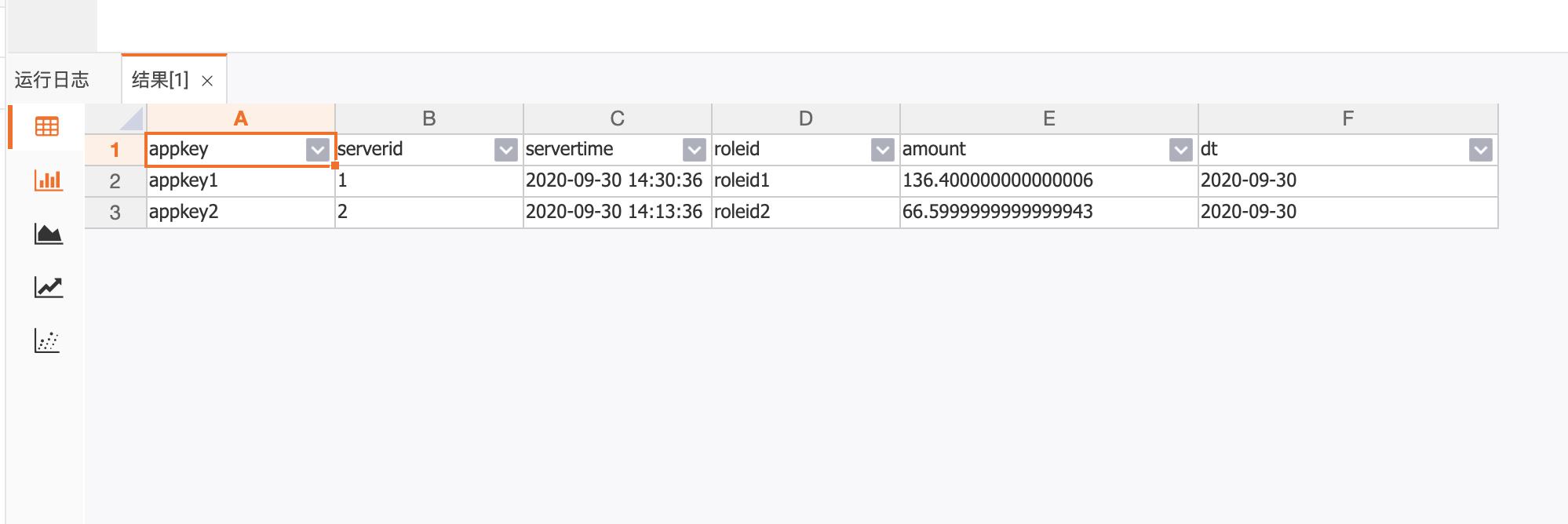
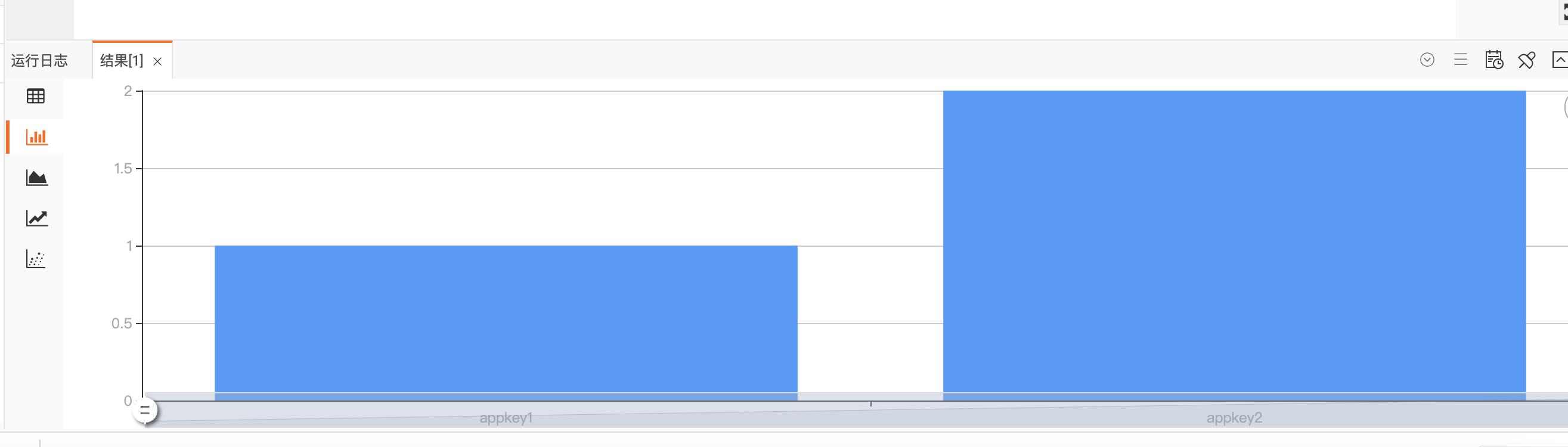
三、最佳实践-电商实时PV和UV统计-Confluent+实时计算Flink+RDS
3.1 新建Confluent消息队列
- 在confluent集群列表页,登录control center
- 在左侧选中Topics,点击
Add a topic按钮,创建一个名为pv-uv的topic,将partition设置为3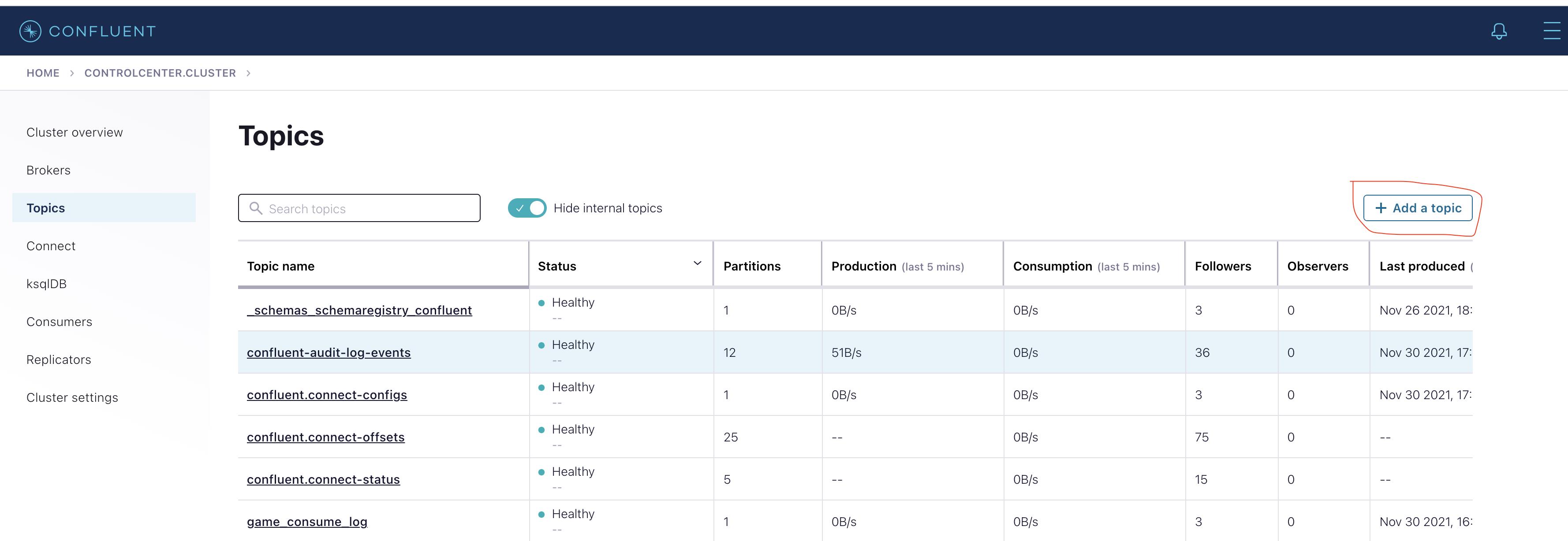
3.2 创建云数据库RDS结果表
- 登录 RDS 管理控制台页面,购买RDS。确保RDS与Flink全托管集群在相同region,相同VPC下
- 添加虚拟交换机网段(vswitch IP段)进入RDS白名单,详情参考:设置白名单文档
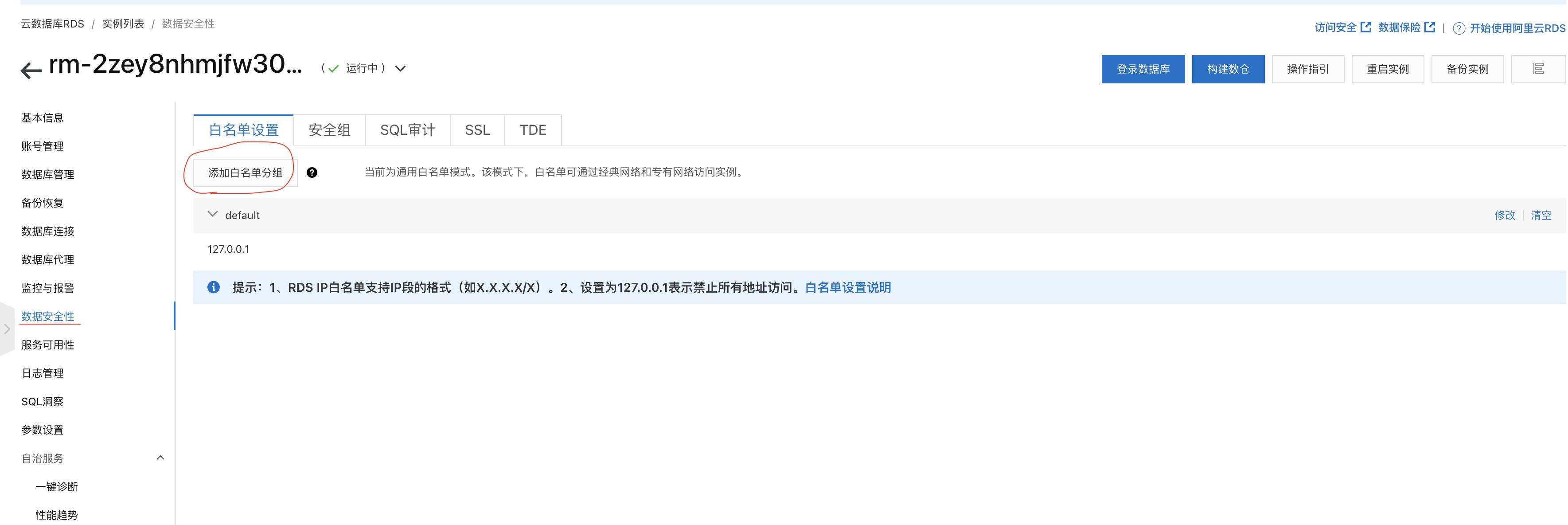
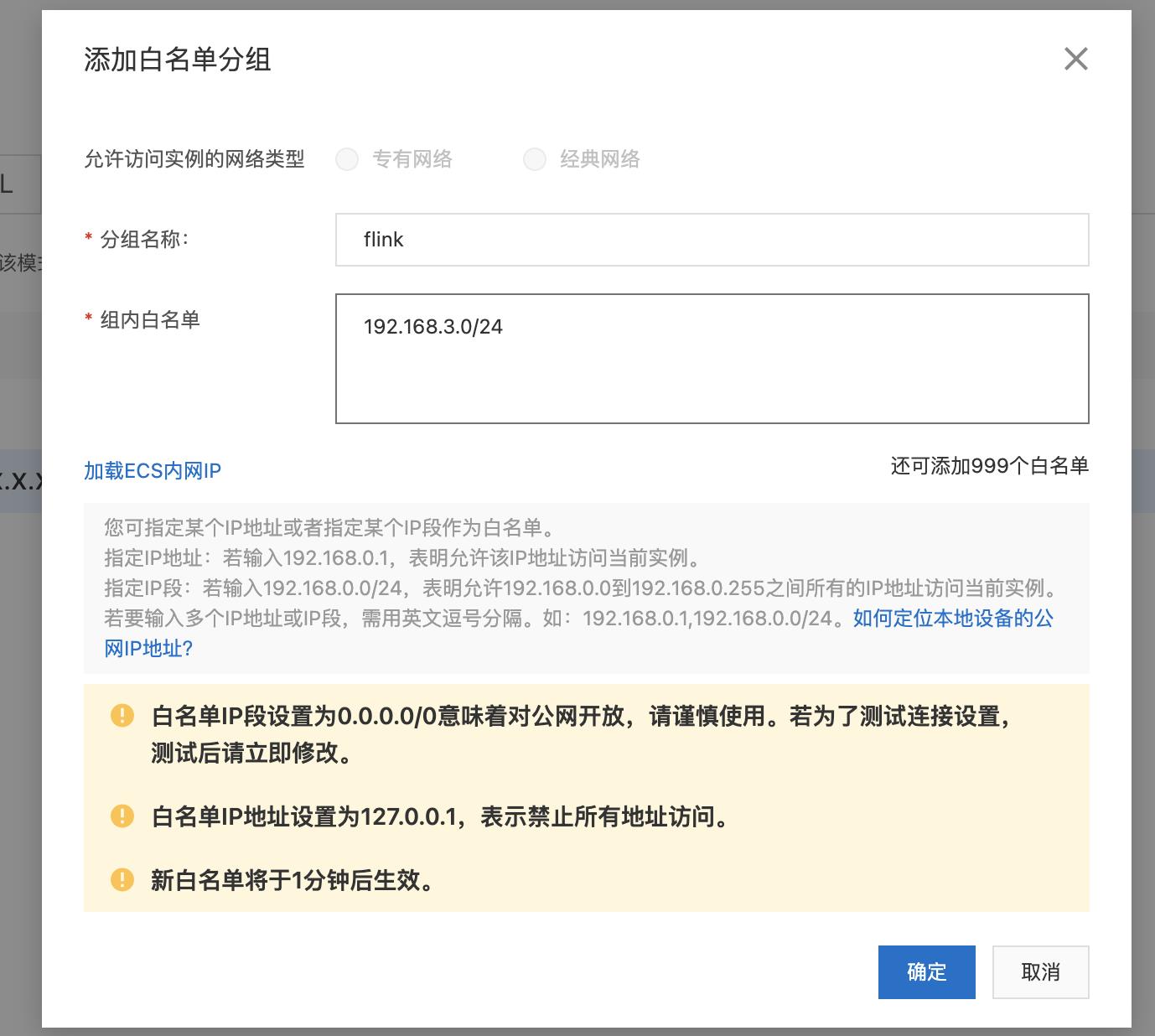
3.【vswitch IP段】可在 flink的工作空间详情中查询

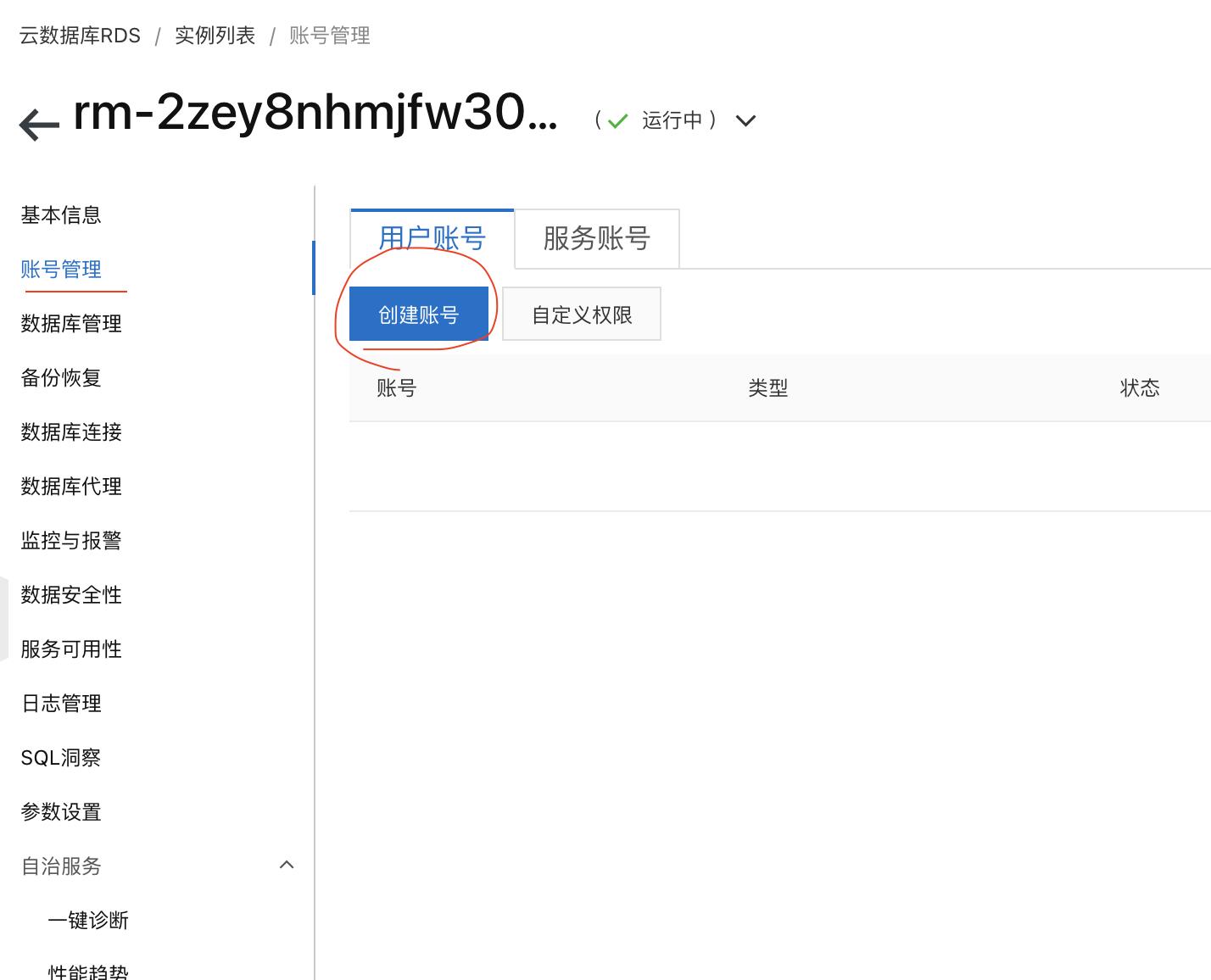
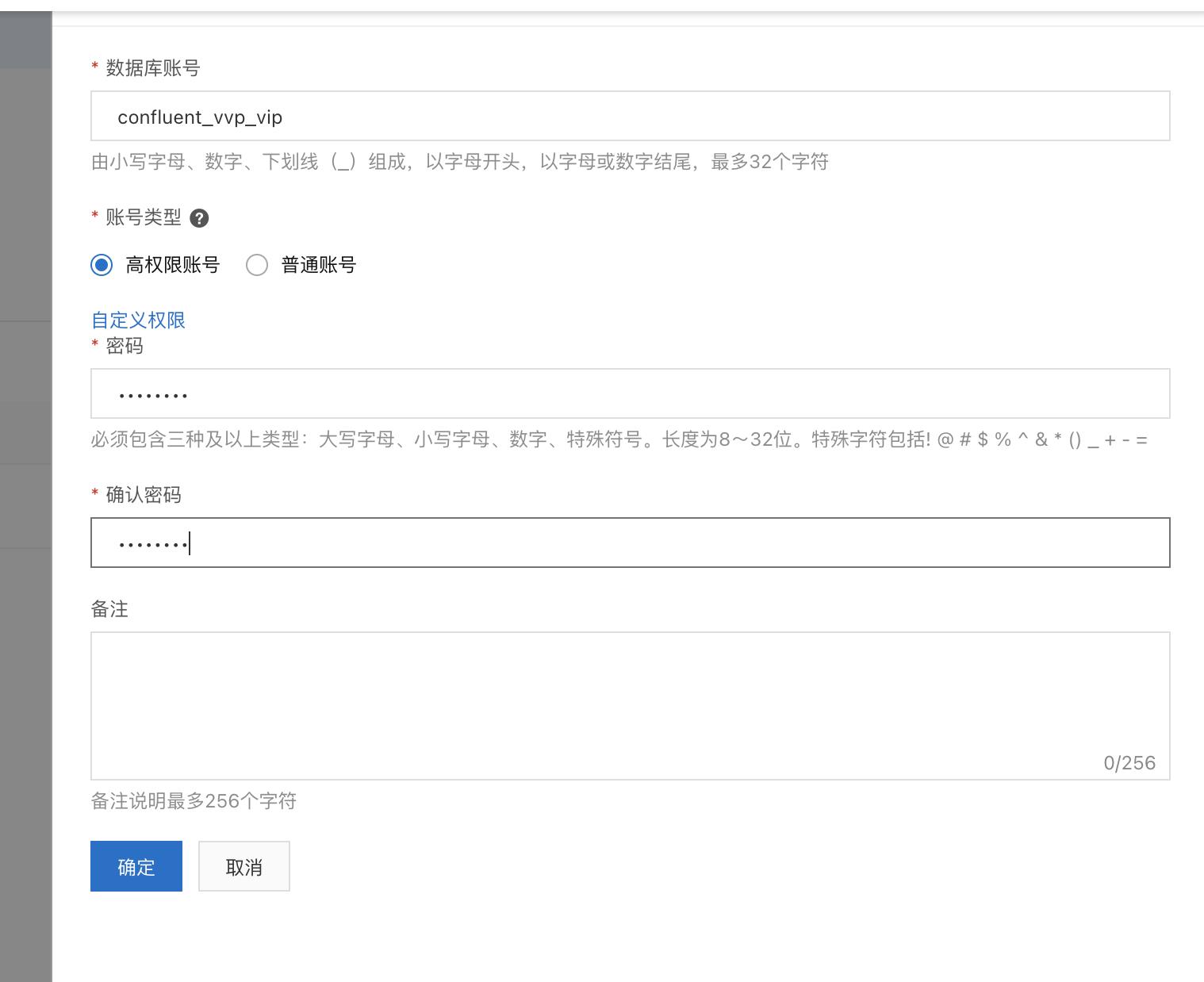
- 在【账号管理】页面创建账号【高权限账号】
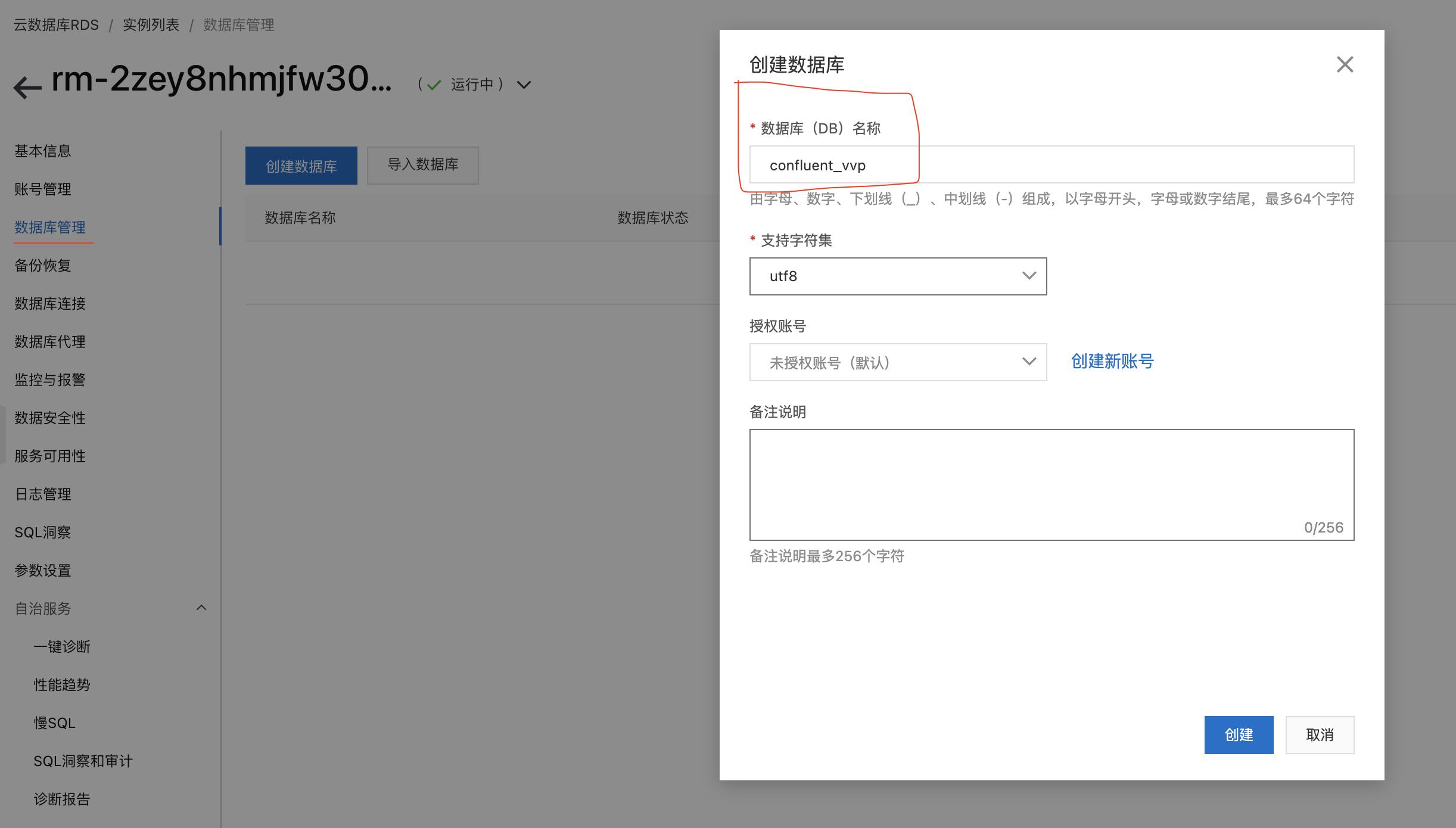
- 数据库实例下【数据库管理】新建数据库【conflufent_vvp】
- 使用系统自带的DMS服务登陆RDS,登录名和密码输入上面创建的高权限账户
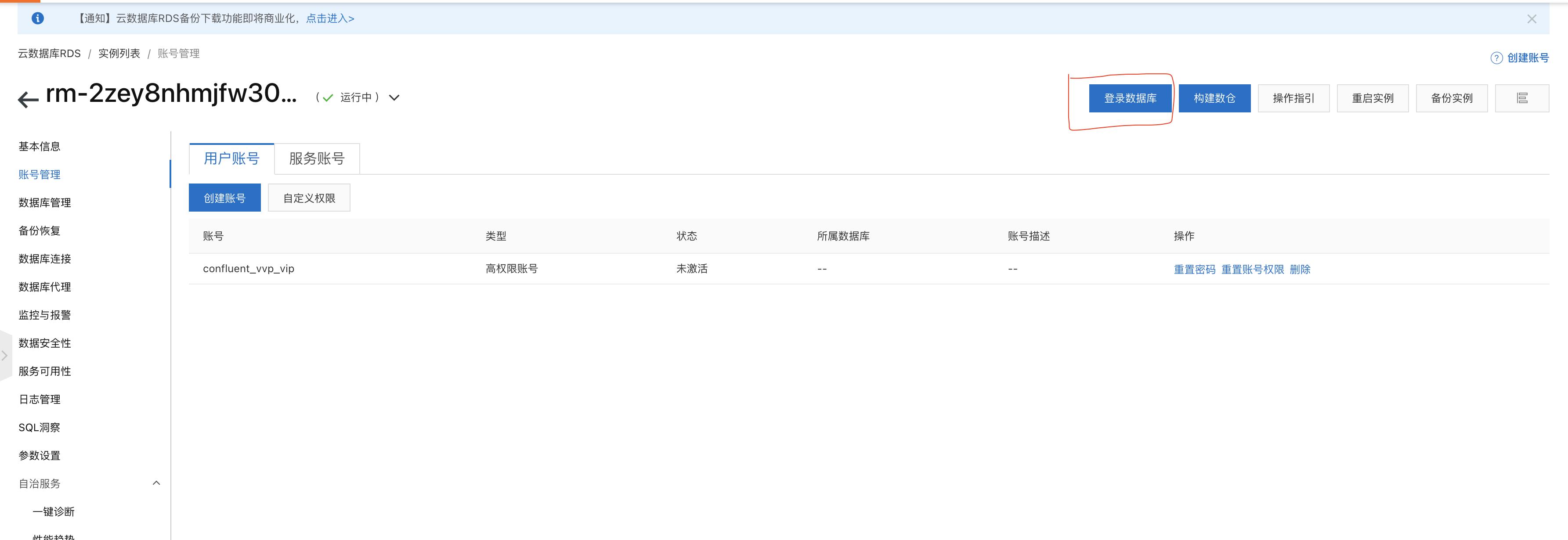
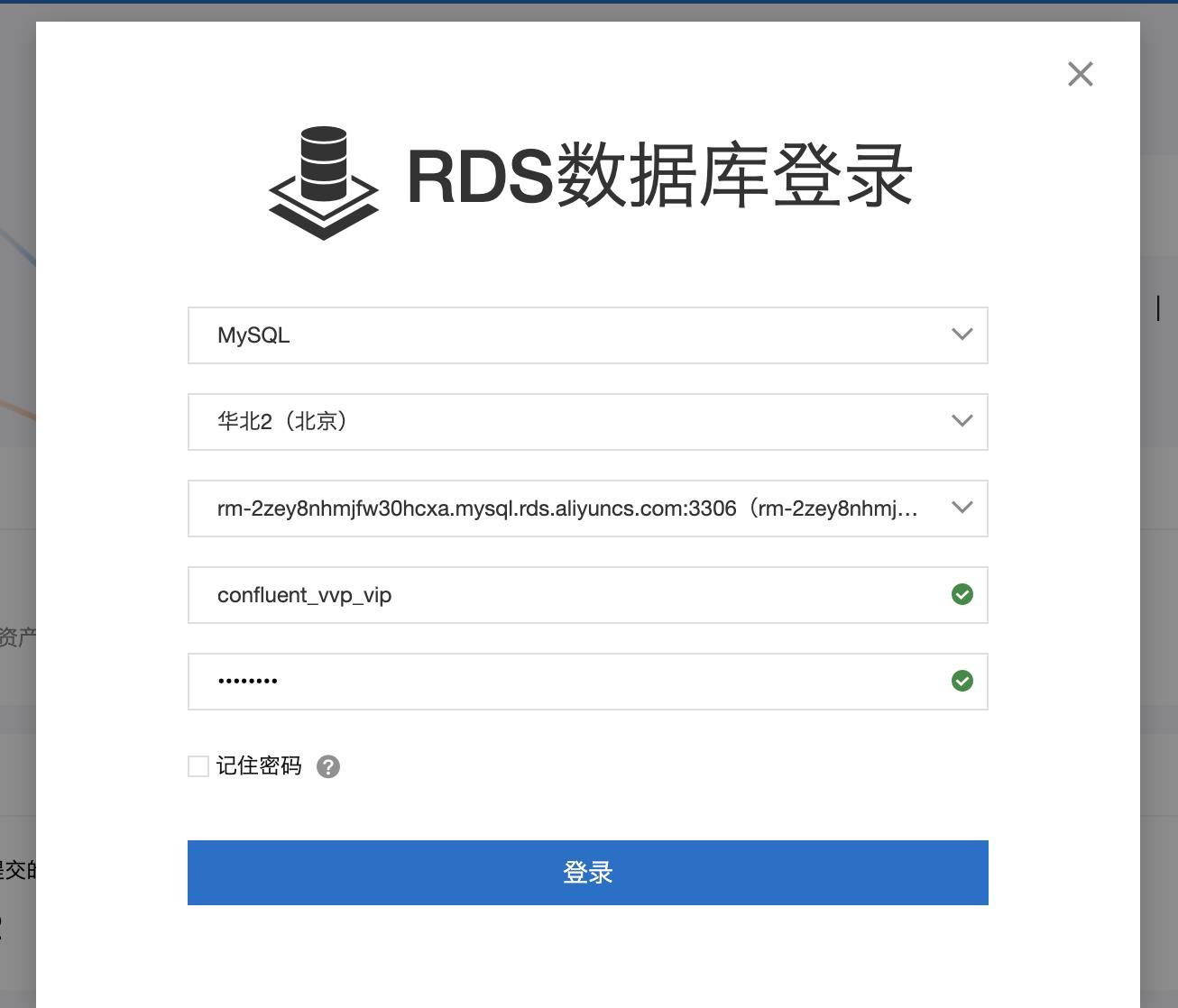
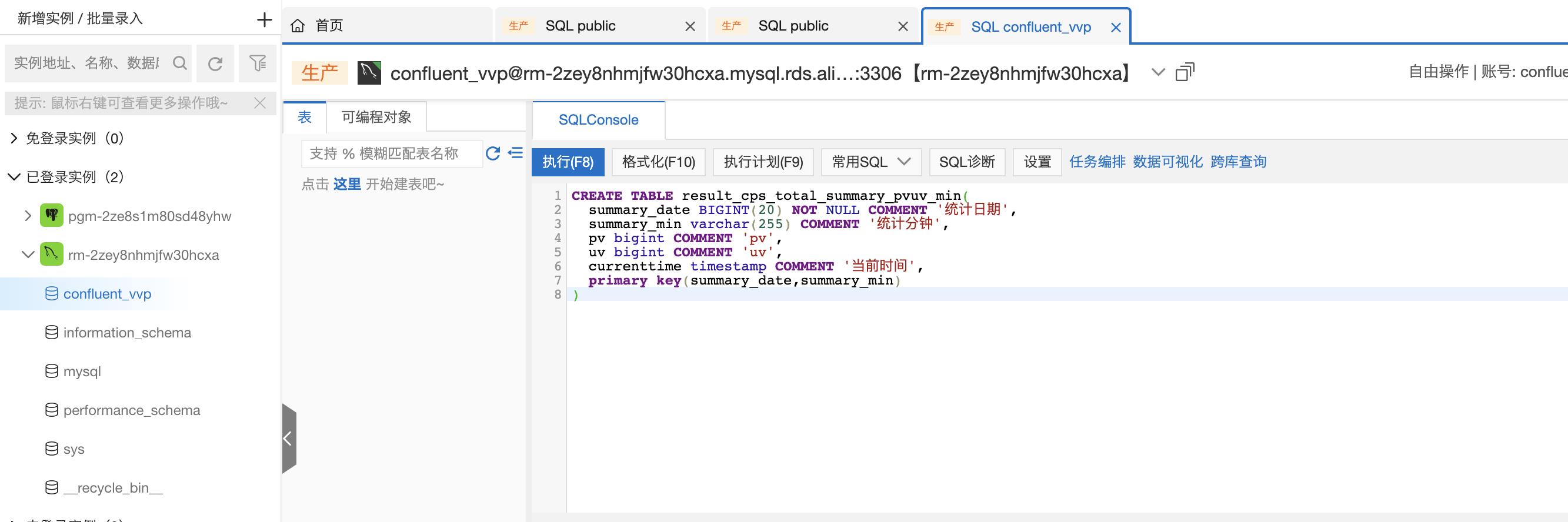
- 双击【confluent_vvp】数据库,打开SQLConsole,将以下建表语句复制粘贴到 SQLConsole中,创建结果表
CREATE TABLE result_cps_total_summary_pvuv_min( summary_date date NOT NULL COMMENT '统计日期', summary_min varchar(255) COMMENT '统计分钟', pv bigint COMMENT 'pv', uv bigint COMMENT 'uv', currenttime timestamp COMMENT '当前时间', primary key(summary_date,summary_min) )
3.3 创建实时计算VVP作业
1.【[VVP控制台】新建文件
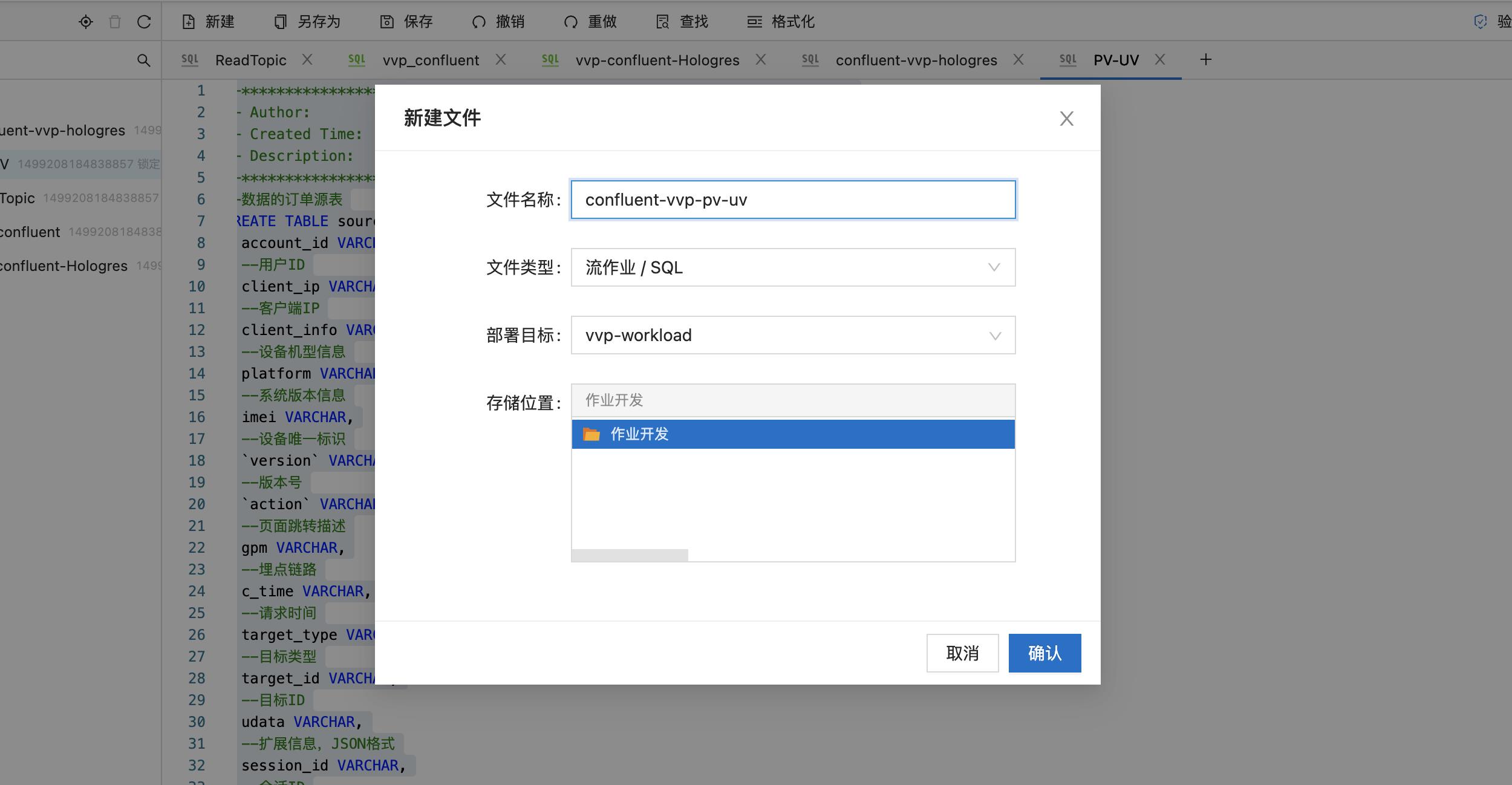
- 在SQL区域输入以下代码:
--数据的订单源表 CREATE TABLE source_ods_fact_log_track_action ( account_id VARCHAR, --用户ID client_ip VARCHAR, --客户端IP client_info VARCHAR, --设备机型信息 platform VARCHAR, --系统版本信息 imei VARCHAR, --设备唯一标识 `version` VARCHAR, --版本号 `action` VARCHAR, --页面跳转描述 gpm VARCHAR, --埋点链路 c_time VARCHAR, --请求时间 target_type VARCHAR, --目标类型 target_id VARCHAR, --目标ID udata VARCHAR, --扩展信息,JSON格式 session_id VARCHAR, --会话ID product_id_chain VARCHAR, --商品ID串 cart_product_id_chain VARCHAR, --加购商品ID tag VARCHAR, --特殊标记 `position` VARCHAR, --位置信息 network VARCHAR, --网络使用情况 p_dt VARCHAR, --时间分区天 p_platform VARCHAR --系统版本信息 ) WITH ( 'connector' = 'kafka', 'topic' = 'game_consume_log', 'properties.bootstrap.servers' = 'kafka.confluent.svc.cluster.local.c79f69095bc5d4d98b01136fe43e31b93:9071', 'properties.group.id' = 'gamegroup', 'format' = 'json', 'properties.ssl.truststore.location' = '/flink/usrlib/truststore.jks', 'properties.ssl.truststore.password' = '【your password】', 'properties.security.protocol'='SASL_SSL', 'properties.sasl.mechanism'='PLAIN', 'properties.sasl.jaas.config'='org.apache.flink.kafka.shaded.org.apache.kafka.common.security.plain.PlainLoginModule required username="【your user name】" password="【your password】";' ); --"account_id":"id1","client_ip":"172.11.1.1","client_info":"mi10","p_dt":"2021-12-01","c_time":"2021-12-01 19:10:00" CREATE TABLE result_cps_total_summary_pvuv_min ( summary_date date, --统计日期 summary_min varchar, --统计分钟 pv bigint, --点击量 uv bigint, --一天内同个访客多次访问仅计算一个UV currenttime timestamp, --当前时间 primary key (summary_date, summary_min) ) WITH ( type = 'rds', url = 'url = 'jdbc:mysql://rm-【your rds clusterId】.mysql.rds.aliyuncs.com:3306/confluent_vvp',', tableName = 'result_cps_total_summary_pvuv_min', userName = 'flink_confluent_vip', password = '【your rds password】' ); CREATE VIEW result_cps_total_summary_pvuv_min_01 AS select cast (p_dt as date) as summary_date --时间分区 , count (client_ip) as pv --客户端的IP , count (distinct client_ip) as uv --客户端去重 , cast (max (c_time) as TIMESTAMP) as c_time --请求的时间 from source_ods_fact_log_track_action group by p_dt; INSERT into result_cps_total_summary_pvuv_min select a.summary_date, --时间分区 cast (DATE_FORMAT (c_time, 'HH:mm') as varchar) as summary_min, --取出小时分钟级别的时间 a.pv, a.uv, CURRENT_TIMESTAMP as currenttime --当前时间 from result_cps_total_summary_pvuv_min_01 AS a;
- 点击【上线】之后,在作业运维页面点击启动按钮,直到状态更新为RUNNING状态。
- 在control center的【Topics->Messages】页面,逐条发送测试消息,格式为:
"account_id":"id1","client_ip":"72.11.1.111","client_info":"mi10","p_dt":"2021-12-01","c_time":"2021-12-01 19:11:00" "account_id":"id2","client_ip":"72.11.1.112","client_info":"mi10","p_dt":"2021-12-01","c_time":"2021-12-01 19:12:00" "account_id":"id3","client_ip":"72.11.1.113","client_info":"mi10","p_dt":"2021-12-01","c_time":"2021-12-01 19:13:00"

3.4 查看PV和UV效果
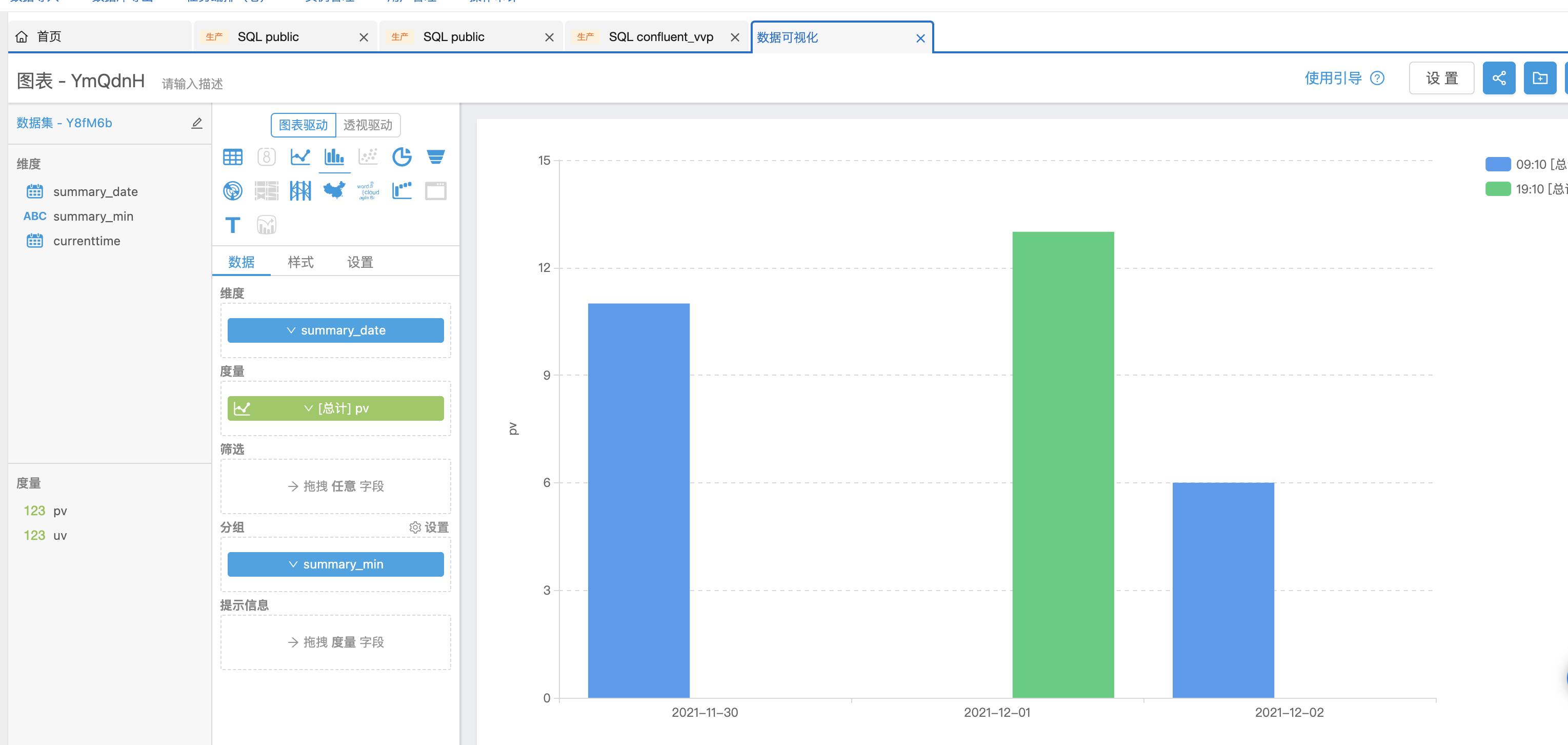
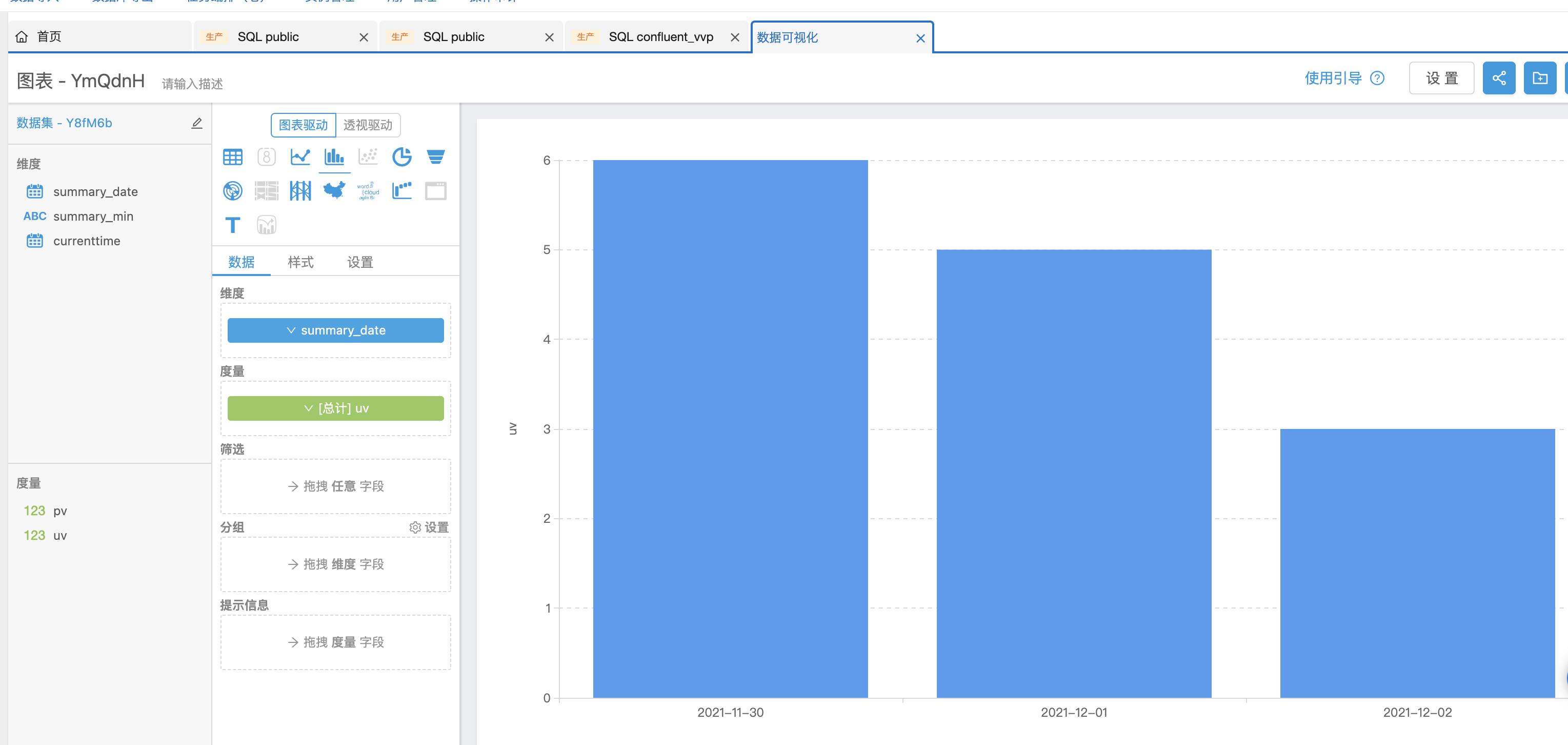
可以看出rds数据表的pv和uv会随着发送的消息数据,动态的变化,同时还可以通过【数据可视化】来查看相应的图表信息。
pv图表展示:
uv图表展示:
本文为阿里云原创内容,未经允许不得转载。
以上是关于基于Confluent+Flink的实时数据分析最佳实践的主要内容,如果未能解决你的问题,请参考以下文章