NLP Prompt系列——Prompt Engineering方法详细梳理
Posted fareise
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了NLP Prompt系列——Prompt Engineering方法详细梳理相关的知识,希望对你有一定的参考价值。
微信公众号“圆圆的算法笔记”,定期更新深度学习/CV/NLP/搜推广私人干货笔记
在NLP中的Prompt方法中,Prompt Engineering是一项基础工作。Prompt Engineering指的是如何针对当前任务生成prompt模板。最基础的prompt构造方法为人工构造,针对目标问题设计合适的文本模板。Prompt模板的构造方式对效果的影响非常大,是prompt方法成功与否至关重要的因素。那么如何构建对下游任务有效的prompt模板呢?这篇文章详细汇总了近2年10篇论文中3种Prompt Engineering方法,主要包括人工构造prompt、自动生成prompt、隐空间prompt3种类型,看看顶会论文中都是如何构造prompt模板并以此提升prompt效果的。
1. 人工构造prompt
最基础的方法就是基于人工知识来定义prompt模板。Prompt模板可以分为prefix prompt和cloze prompt两类。其中cloze prompt表示在句子中填空,prefix prompt表示在一个前缀的基础上填后续文本。
Language Models as Knowledge Bases?(2019)这篇文章探讨了预训练语言模型中学习到的语言知识,主要方式是利用多种数据集构造cloze prompt,看预训练模型是否能预测出缺失词。例如Dante was born in (?)就是一个cloze prompt,模型预测空缺位置的词,预测正确说明预训练语言模型学到了这些知识。本文利用一些知识库构造了一批cloze prompt去对比不同预训练模型的效果,并发现Bert-Large能够取得很好的效果。这篇文章最后构造了LAMA数据集,根据多个数据得到的cloze prompt模板,用来检验预训练语言模型中包含的知识情况。
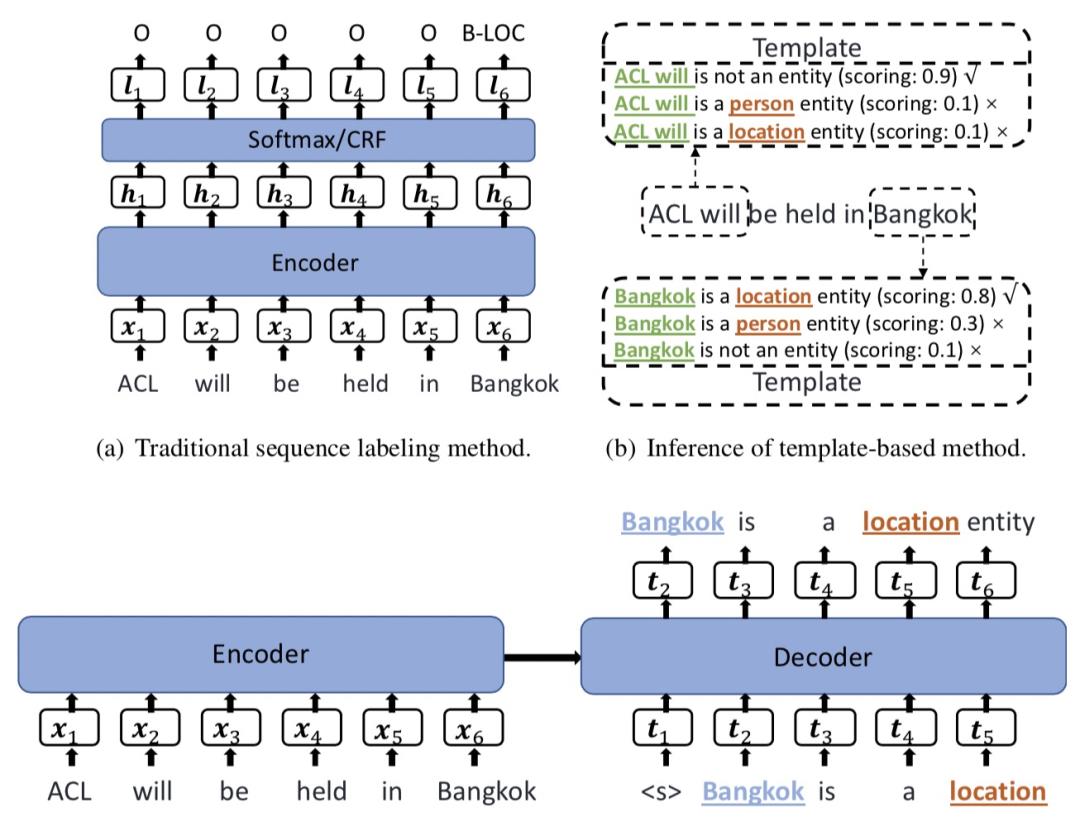
Template-Based Named Entity Recognition Using BART(ACL 2021)采用cloze prompt解决小样本下的NER任务。对于一个句子,如果某个词组是实体,那么其对应的模板就是<xi:j> is a <yk>;如果某个词组不是实体,那么其对应的模板为<xi:j> is not an entity。例如对于一个输入文本ACL will be held in Bangkok来说,需要构造出多组模板文本,对应每个词组是否为某个entity,如Bangkok is a location entity。将构建好的句子送到预训练+其他领域finetune的BART上打分,根据打分高低判断每句话描述的对应词是否为实体的正确性。
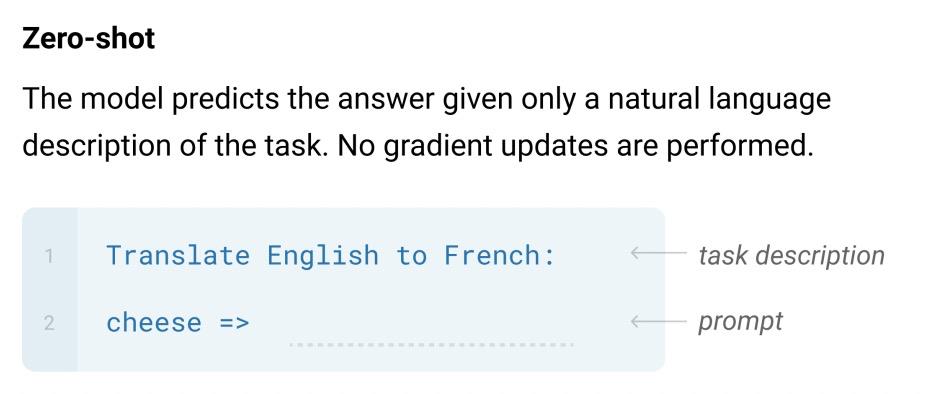
Language Models are Few-Shot Learners(2020)设计了多种prefix prmopt模板用来解决各种NLP任务。例如下面的例子中将翻译任务转换成了prompt,让模型预测句子末尾的单词,在文前提供了对于任务的描述文本。
Exploiting Cloze Questions for Few Shot Text Classification and Natural Language Inference(ACL 2021)采用cloze prompt+finetune的方法解决文本分类问题。对于每种任务,会构造一组PVP。这里的PVP有两个组成部分,一个用来将该任务的输入样本转换成一个cloze prompt任务,另一个用来将分类的label映射到一个具体的word上。例如某个判断两个句子是否矛盾的任务样本为(Mia likes pie, Mia hates pie),那么会将其转换为Mia likes pie? , [x] Mia hates pie,目标为预测[x]位置应该填什么词。同时,分类任务的每个label都会映射到某一个词上。首先会使用少量这样的数据进行finetune,然后在inference阶段预测[x]位置为各个label对应词的概率,选概率最大的。
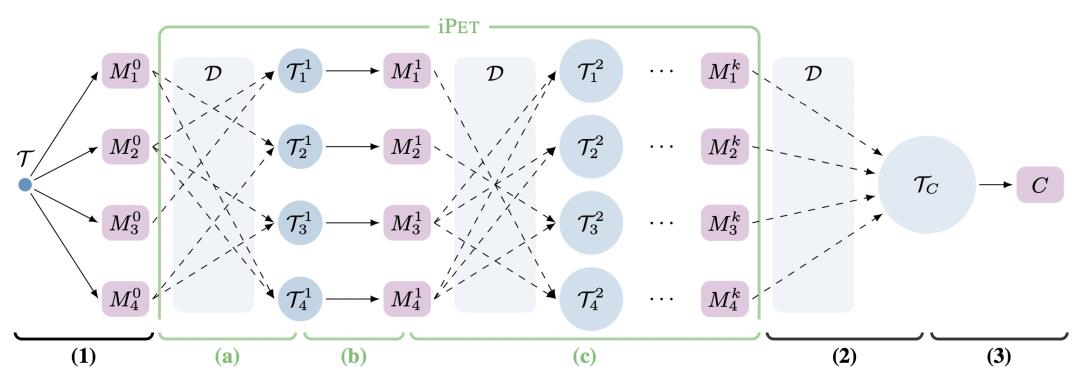
由于不同的prompt构造方法会影响效果,本文采用了一种知识蒸馏的方法,对于一个任务会构造多个prompt,每一个prompt finetune生成一个模型,最后使用知识蒸馏的方法融合各个finetune模型的预测结果。为了让各个prompt模板的信息能够融合,会进行多轮的finetune,每轮每个prompt的finetune数据使用上一个某些finetune模型产出的标签扩充训练数据。
2. 自动生成prompt
人工构造的prompt依赖人工经验,并且效果也难以保障,一般采用构造多组prompt,对每组prompt的效果分别进行验证对比,或者多组prompt融合的方法提升效果。那么如何能够自动化的构造出大量的prompt模板呢?
一种构造方法是在大量语料中去挖掘一些可以作为prompt的模板。例如当确定了prompt的输入X和label对应的Y后,可以去海量文本库做匹配,看哪些句子包含[X] ... [Y],就用这些模板作为构造prompt的依据,How Can We Know What Language Models Know?(2019)一文中就采用了这种方法。
另一种方法被称为prompt paraphrasing,首先生成一个种子prompt,然后在此基础上利用一些诸如回译(翻译成一种语言再翻译回来)、关键词替换等方法,扩展出更多的prompt模板,然后对比各个prompt模板的效果选择最优的prompt模板,或对多个prompt模板结果进行融合。
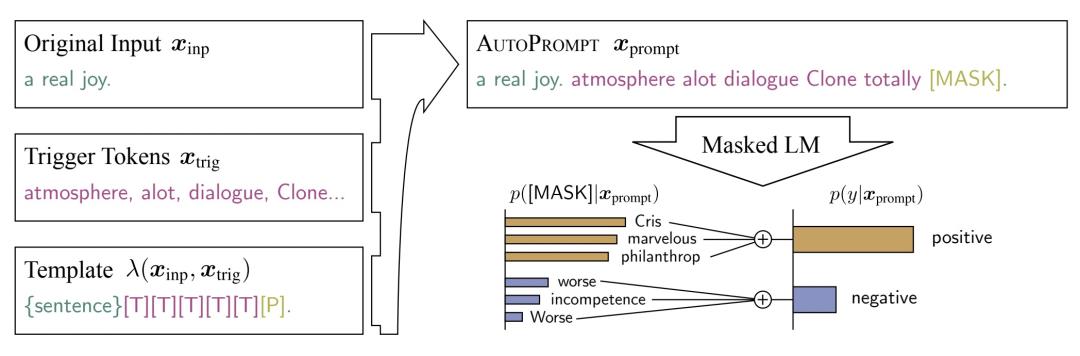
AutoPrompt: Eliciting knowledge from language models with automatically generated prompts(2020)提出了采用自动搜索prompt模板词的方法,其基本思路建立在,从词表中遍历所有词,看哪些词组成的prompt模板能最终生成训练数据中待填充的词,相当于一个逆向操作。Prompt模板需要填充的词最开始用[MASK]初始化,然后去看使用其他词替换[MASK]会让label的概率最大,逐步替换[MASK],得到template。
还有一类方法将prompt模板的构造看成是一个生成式的任务。Making pre-trained language models better few-shot learners(2021)提出不同的label到word的映射方法,以及不同的prompt模板会对效果造成很大影响。对于label的选择,使用每个类别的训练样本,让预训练的语言模型预测[MASK]为各个词的概率,选择概率最大的几个词。这几个词都会作为label到word的映射方法,分别finetune模型,最终再选择在验证集上表现最好的。
对于prompt模板的生成,本文使用了预训练的T5模型。T5模型在预训练阶段采用了mask span任务,输入一个被mask掉多个span的文本,在decoder处对mask掉的span进行还原,这正好可以用于prompt生成。具体例子如下图,对于任务的每个类别构造如下的输入,将prompt部分的除了已经确定好的label对应的词外都mask掉,让T5模型去生成各个模板的各个位置应该填什么,最后再进行finetune看哪个生成的prompt效果最好。

3. 隐空间中的prompt
上面介绍prompt模板都是具体文本的prompt,另一种类型的prompt是在隐空间的prompt。相比于文本prompt,隐空间的prompt不需要强制让prompt模板必须是真实的文本表示,而是在隐空间学习一个文 本向量,它可能无法映射到具体的单词,但是和各个词的embedding在同一个向量空间下。这种自动生成的prompt也可以不用保证必须是真实的文本,给prompt的生成带来了更大的灵活空间。
Prefix-Tuning: Optimizing Continuous Prompts for Generation(2021)提出的方法只finetune 0.1%的参数就取得和finetune相当的效果,并且在少样本任务上效果由于finetune。本文提出针对自然语言生成任务(如摘要生成、table-to-text等任务)的迁移预训练大模型的方法。该方法的具体实现为,将预训练的Transformer模型参数整体Freeze住,当正常输入文本序列的时候,在最前端添加几个prefix id,每一个prefix id都对应一个随机初始化的embedding,不同的任务有不同的prefix id。这样在模型中,prefix之后每个时刻的表示都会受到prefix的影响,prefix代表某个对应具体任务的上下文信息。在Finetune过程中,模型的其他参数都Freeze,只Finetune prefix的embedding,以及prefix后面接的一些全连接层,Finetune参数量只占整体模型的0.1%,远小于其他的Finetune方法。该方法核心思想利用了prefix embedding去学习对于某个任务来说,需要从预训练语言模型中提取什么样的信息。这里用到的prompt并非直接生成具体的文本模板,而是在向量空间中生成的一个embedding,是一个隐式的prompt模板,每个任务都有一个隐式的prefix prompt。
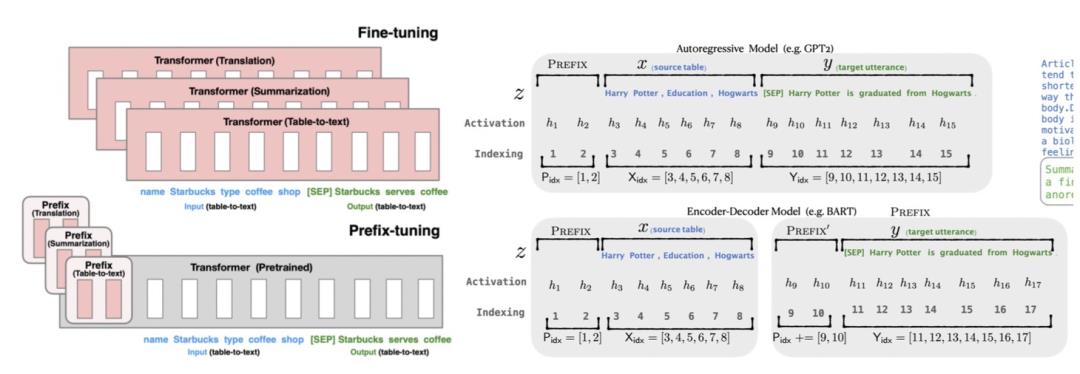
The Power of Scale for Parameter-Efficient Prompt Tuning(2021)将所有NLP任务都看成是文本生成任务,通过加入prefix prompt给模型一个额外的条件信息来指导模型生成后续的文本。当给定一个输入token序列后,正常对这些token进行embedding,然后拼接在prefix prompt的embedding之后,输入到encoder-decoder中。对于prompt embedding的初始化,除了随机初始化外,本文提出了采用预训练模型中某个word的embedding作为初始化,或者对于分类问题使用分类标签对应的token embedding进行初始化,指导生成阶段产出相应类别对应的文本。

另一种方式是在文本prompt的基础上进行finetune,相当于将明文prompt作为一个初始点,然后在embedding空间finetune一个更适用于当前任务的隐式prompt。Factual Probing Is [MASK]: Learning vs. Learning to Recall(2020)的基本思路也是在隐空间学习prompt模板中各个token的embedding,在此基础上,本文提出使用一些文本prompt模板进行初始化,也就是隐空间prompt包含的单词数量、位置以及初始化参数都用一个人工定义好的文本prompt,然后在此基础上进行finetune得到更好的prompt。
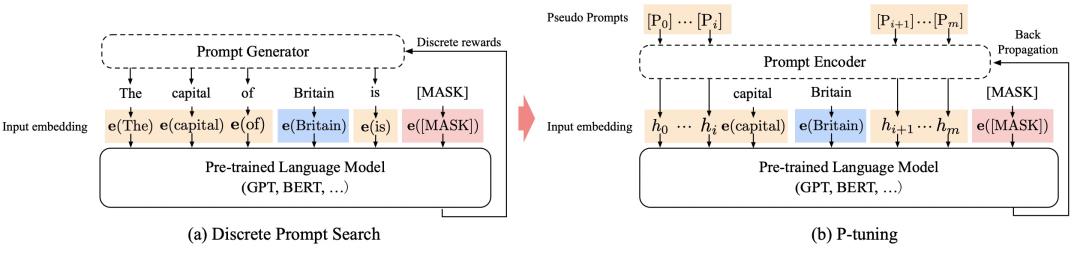
GPT Understands, Too(2021)采用的思路是将人工定义的prompt的token对应的embedding从预训练模型输出的改为一个可学习的hidden向量,让模型去优化。为了建立模板中各个token之间的关系,文中采用了双向LSTM这种序列建模的方式生成每个prompt token的表示,第i个token的向量可以表示为如下公式:

4. 总结
本文详细梳理了近2年10篇顶会论文中Prompt Engineering的方法,主要包括人工构造prompt、自动生成prompt以及隐空间中的prompt三种类型。Prompt的构造方式对基于prompt方法的预测任务非常重要,选择合适的prompt构造方法使prompt应用成功的关键。
微信公众号“圆圆的算法笔记”,定期更新深度学习/CV/NLP/搜推广私人干货笔记
【历史干货算法笔记,更多干货公众号后台查看】
花式Finetune方法大汇总
NLP中的绿色Finetune方法
一文读懂CTR预估模型的发展历程Domain Adaptation:缺少有监督数据场景下的迁移学习利器
从ViT到Swin,10篇顶会论文看Transformer在CV领域的发展历程
缺少训练样本怎么做实体识别?小样本下的NER解决方法汇总
以上是关于NLP Prompt系列——Prompt Engineering方法详细梳理的主要内容,如果未能解决你的问题,请参考以下文章
训练CV模型新思路来了:用NLP大火的Prompt替代微调,性能全面提升
NLP新秀prompt跨界出圈,清华刘知远最新论文将它应用到VLM图像端
NLP新秀prompt跨界出圈,清华刘知远最新论文将它应用到VLM图像端