Prompt Learning 简介
Posted 秃然变强了
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Prompt Learning 简介相关的知识,希望对你有一定的参考价值。
最近去参会,看到了大量关于Prompt相关的论文,或者说跟NLP NLU相关的新论文或多或少都使用到了Prompt learning的一些思想或者设置。由于本人主业不是是做NLP的,所以对NLP顶会的这一现象觉得很有意思,趁闲暇学习了一下Prompt learning。 网上讲解的帖子很多,我整理了一些帖子的核心内容,也写一下我自己在学习过程中的感悟。
-----手动分割----
1. 大型语言模型的进化史
这里引入刘鹏飞大佬的的观点,他在论文中提到,语言模型在Deep learning 时代,大致经历了四个阶段:
- 完全监督的机器学习:通过构建特征工程,直接解决下游任务。
- 完全监督深度神经网络:通过构建ML模型,训练一个端到端的模型,同样的,直接解决下游任务。实际上,相比于后两种情况,1和2在某些程度上是一个意思。
- 预训练模型微调阶段: 先通过大型的生语料库预训练大型语言模型,比如常见的各种Transformer,再进行Fine Tuning来使大型语言模型适配下游子任务。
- prompt 提示学习阶段: 跟3一样,先获得大型语言模型,然后通过提示学习Promt Learning, 在一定程度上重构下游任务来适配大型语言模型,以完成下游任务。
如图所示,NLP语言模型的四个阶段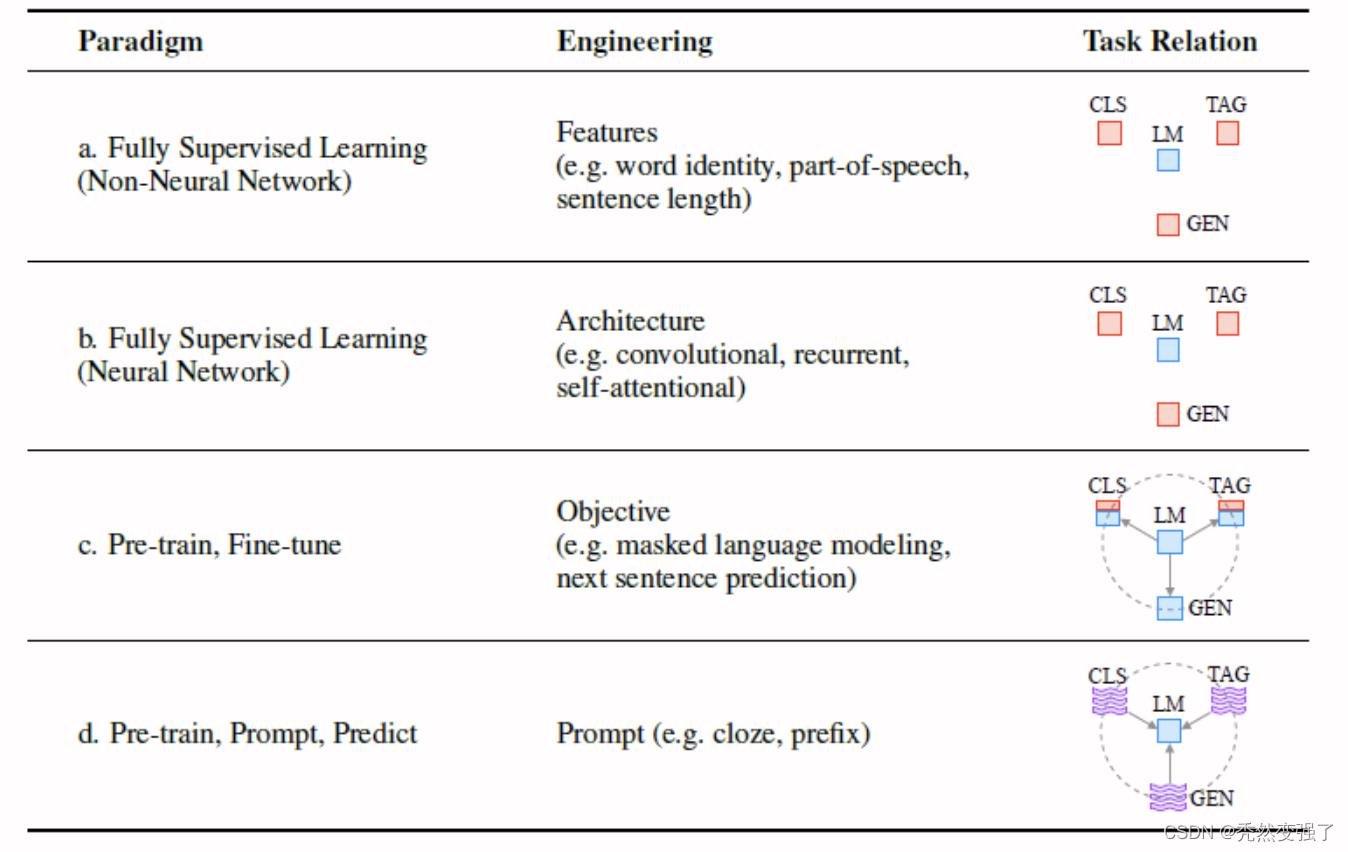
对比一般的Fine-tuning 范式,我们有:
• 左边是传统的 Model Tuning 的范式:对于不同的任务,都需要将整个预训练语言模型进行精调,每个任务都有自己的一整套参数。
• 右边是Prompt Tuning,对于不同的任务,仅需要插入不同的prompt 参数,每个任务都单独训练Prompt 参数,不训练预训练语言模型,这样子可以大大缩短训练时间,也极大的提升了模型的使用率
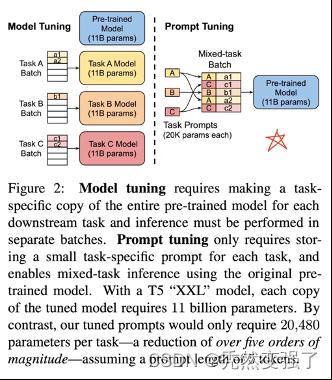
Prompt Learning的基本流程
关于预训练模型的前三种情况就不赘述了,Prompt Engineering的核心思想,主要就是将已有的下游NLP任务重构成token级的预测任务,在不改变原有的pre-trained LM的前提下(也就是说不进行fine tuning)直接将LM应用的过程,换言之,是在用下游任务适配LM。融入了 Prompt 的模式大致可以归纳成 “Pre-train, Prompt, and Predict”,在该模式中 下游任务被重新调整成类似预训练任务的形式
Prompt 的工作流包含以下4部分,如图:
- Prompt 模版(Template)的构造
- Prompt 答案空间映射(Verbalizer)的构造
- 文本代入template,并且使用预训练语言模型进行预测
- 将预测的结果映射回label。
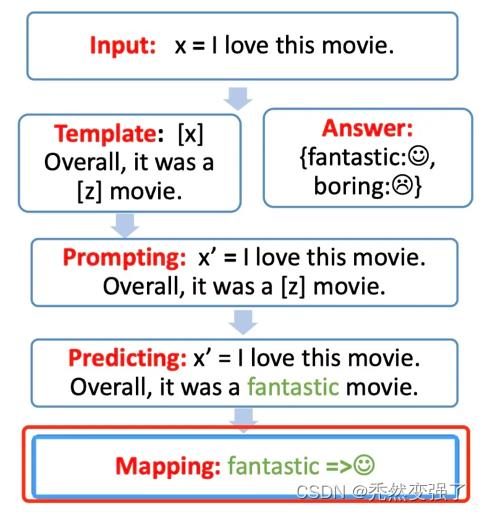
2.1 Prompt Engineering
- cloze prompt:在 prompt 中有插槽 (slot) 的类型为 cloze prompt,这类 prompt 就是需要模型去填充这个 slot。这类可以选用 L2R LM (ELMo) 或者 Masked LM (BERT) 来实现。
- prefix prompt:输入的文本全部在 answer 前的类型为 prefix prompt,这类 prompt 通常是需要模型去预测或者生成这个 slot。这类模型可以选用 L2R LM (RNN),Prefix LM,以及 Encoder-Decoder (GPT) 去实现。
2.2 Template Engineering
根据不同的下游任务,我们需要设计不同的Template形式,如图所示:
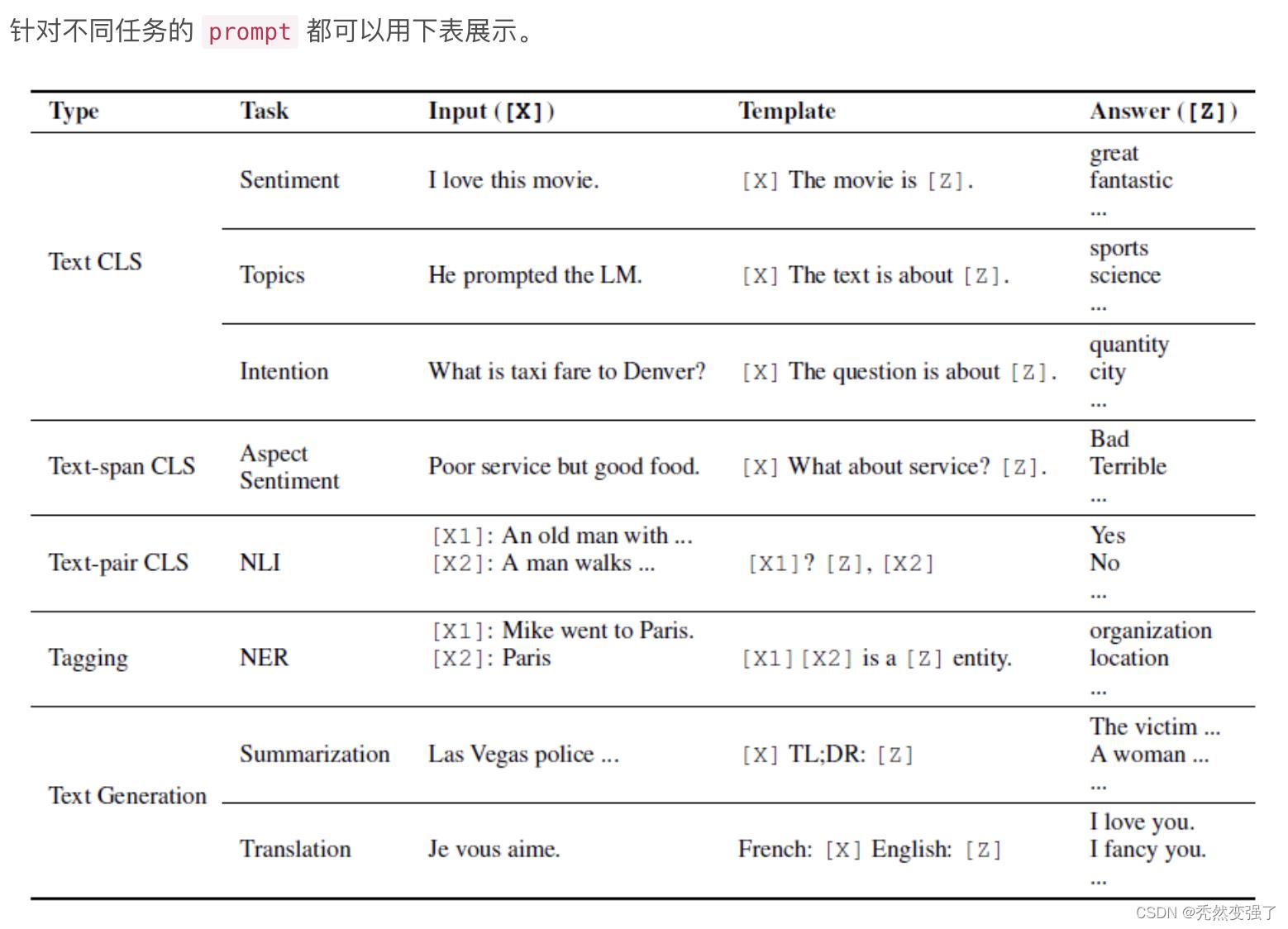
对于 prompt template,有两种方法来生成,分别为人工设计模板和自动生成模板。
- 人工设计模板: 如上面举的例子一样,人工设计模板是最直观的方法。抽象来看,设文本为 X, 插槽为Z,人工设计的模板为[X] template words [Z]。但是人工设计模板有很大的缺陷,尽管这样非常直觉,易于理解,而且无需额外的计算代价,但是:1) 人工设计模板是很花费时间且需要先验知识的;2) 人工设计也会有失败的情况在内。为了解决上面的问题,就提出了通过训练的方式自动生成模板。
- 自动生成模板: 自动生成模板有两种类型。discrete prompts (离散提示,i.e., hard prompts),这类型 prompts 就是让模型在一组离散模板的空间中选择一个最优的模板。continuous prompts (连续提示, i.e., soft prompts),这类型 prompts 就是让语言模型自动训练一个 prompts 出来。
这里需要额外注意的是自动生成模板的两种情况,因为不同的prompts构建对结果的影响非常大(这也是prompt的一个缺陷,从一个炼丹炉跳到了另一个 \\doge)。其中,自动生成模板的过程中,包含了一些可训练的部分。
- 离散的Prompts: 通过数据挖掘构建出一下可读的prompts
- 连续 Prompts:不一定要将 Prompt 的形式设计成人类可以理解的自然语言 只要机器理解就行了 因此,直接作用到模型的 Embedding 空间,连续型 Prompts 去掉了两个约束条件,这也是最关键的两点:(1)模版中词语的 Embedding 可以是整个自然语言的 Embedding,不再只是有限的一些 Embedding;(2)模版的参数不再直接取 PLM 的参数,而是有自己独立的参数,可以通过下游任务的训练数据进行调整。因此,连续Prompts是需要训练,甚至是微调的一组参数。
2.3 Answer Engineering
与 prompt engineering 相同,answer engineering 同样有人工设计与自动获取两种方法。
- 人工设计答案: 人工设计分为两类 空间。Unconstrained spaces 中的空间包含了输出空间的所有结果,token 级的话则是全部词表中的词 (比如 W2V 的输出层),其余类型相同。这类方法可以直接找到 Z 与 y 的映射关系。Constrained spaces,这类方法通常输出是在一个限定范围内 (比如 positive 和 negative),这类方法就需要一个映射关系来映射 Z 与 y。
- 自动学习答案: 与 prompt engineering 相同,有 discrete answer search 和 continuous answer search。
2.4 Language Model Engineering
在根据不同的下游任务选取具体的预训练语言模型时,可以分为如下5类:
• autoregressive-models: 自回归模型,主要代表有 GPT,主要用于生成任务
• autoencoding-models: 自编码模型,主要代表有 BERT,主要用于NLU任务
• seq-to-seq-models:序列到序列任务,包含了an encoder 和 a decoder,主要代表有 BART,主要用于基于条件的生成任务,例如翻译,summary等
• multimodal-models:多模态模型
• retrieval-based-models:基于召回的模型,主要用于开放域问答
2.5 Prompt 训练方式
整个 prompt 的训练分为两部分,LM 的训练和 prompts 的训练。两者都有不训练和训练两种方式,所以就组合为了4种情况:
prompts 没有参数,LM 也不参与训练。
prompts 需要训练,LM 不参与训练 (毕竟 GPT 不是穷人配用的)。
prompts 没有参数,LM 进行微调。
prompts 需要训练,LM 也要进行微调。
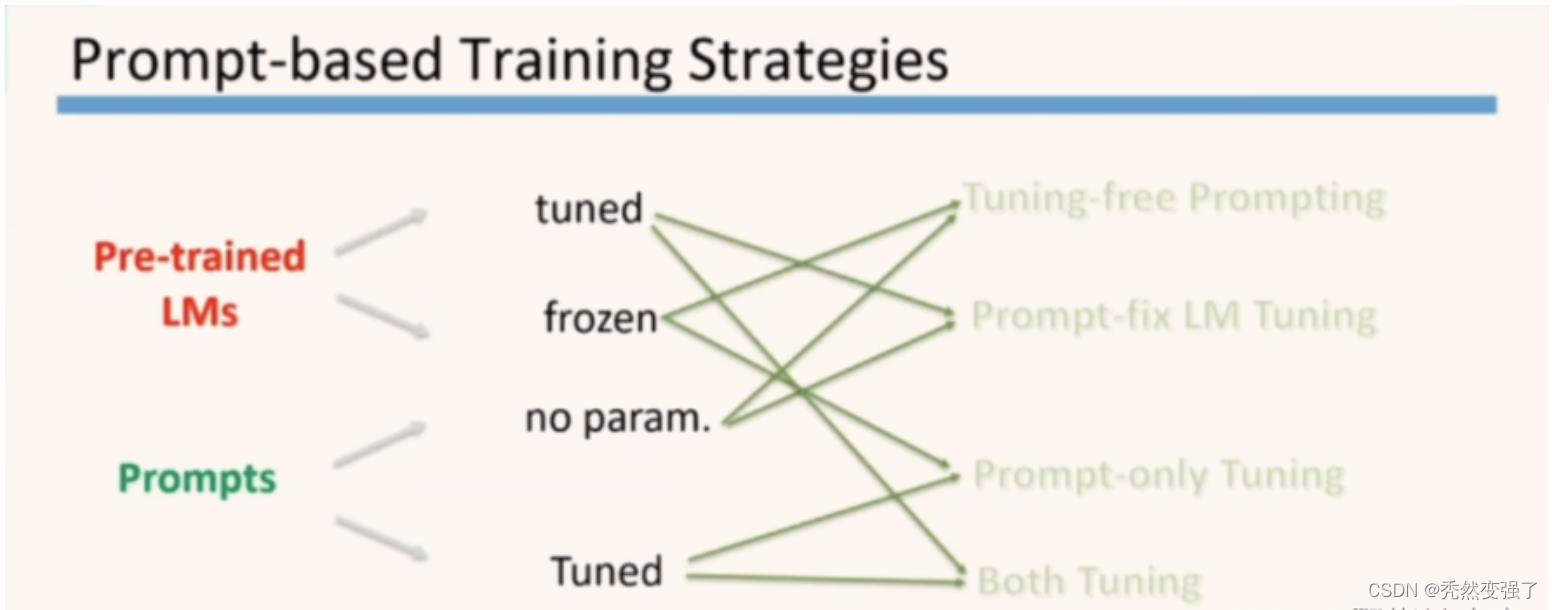
这里需要注意的是,根据我们在下游任务上的数据量的不同,我们选择的训练情况也要有所区分。毕竟GPT3的论文title是LMs are Few Shot Learners, 也就是说,这些我们选用的大语言模型,对于下游任务本身就不是数据敏感型的,这些很powerful的LM在使用prompt策略的时候,更多是由于本地无法做finetuning才选取的妥协之策。那么,在这个基础上,少量的下游数据,对应了更少的下游训练,使用frozen LM+Prompts是更为常见的组合。
总结
Prompt Learning 使得所有的NLP任务成为一个语言模型的问题
• Prompt Learning 可以将所有的任务归一化预训练语言模型的任务
• 避免了预训练和fine-tuning 之间的gap,几乎所有 NLP 任务都可以直接使用,不需要训练数据。
• 在少样本的数据集上,能取得超过fine-tuning的效果。
• 使得所有的任务在方法上变得一致
Prompt Learning 和 Fine-tuning 的范式区别
• Fine-tuning 是使得预训练语言模型适配下游任务
• Prompting 是将下游任务进行任务重定义,使得其利用预训练语言模型的能力,即适配语言模型

一些感想:
过去我们使用BERT的时候,我们先预训练一个模型,然后根据不同的任务,准备不同的数据对预训练的模型进行微调。所以你还是需要收集一些下游任务的数据。而GPT-3想要做的就是拿掉微调部分,它想用来直接解决下游任务。那么这样的背景下,Prompt Learning是无比契合GPT3强大的语言建模能力的。也就是说,从原理上,Prompt Learning更多解决的是小样本问题。能完成few-shot甚至zero-shot 任务。
- Prompt是一种fit大型语言模型到下游任务的一种方式,无需finetuning的过程,可以在无需额外的训练条件下就可以达到下游任务的fitting;
- 因为很多大模型 我们甚至连对其微调也做不到,所以进行Prompt在某种程度上是一种妥协之策,为了在有限的训练条件下挖掘大模型的能力。但是反过来,Prompt并不一定是最优解,当我们有能力做Finetuning时,(比如GPU很强,下游样本很多),我们还是以Fine tuning为优先选择。
- 接着上面的内容,Prompts给了普通人fitting 大模型的能力,也给了大家更多发论文的机会 \\doge
- Prompt work的一个基础是,我们在构建人类语言的文本数据时,言本身的表征是有限的,有确定范围的文字/单词,这是在其他领域一般模型所不具备的。同时,当前的大模拥有强大的表征能力,哪怕是通过Prompt这种反向(实际上是把简单问题复杂化了,如将情绪分类任务重构成了单词预测任务,那么分类难度可能从5分之一变成了万分之一)任务重构,依然能取得很好的效果。
- 构建Prompts在某种程度算是一种trick,虽然这种方式在范式层面有一定的adaptation,但是为每一个下游任务构建templates和prompts engineering,并不是一个很优雅的行为,期待后续有能取代这种feature engineering 的方式。
部分内容搬运自:
【1】 什么是 prompt learning?简单直观理解 prompt learning
【2】【NLP】Prompt Learning 超强入门教程
【3】Prompt Learning-使用模板激发语言模型潜能
【4】OpenAI 官方Instruction
【5】Prompt Learning详解
以上是关于Prompt Learning 简介的主要内容,如果未能解决你的问题,请参考以下文章
大模型系统和应用——Prompt-learning & Delta Tuning
美团获得小样本学习榜单FewCLUE第一!Prompt Learning+自训练实战
ICLR 2023Diffusion Models扩散模型和Prompt Learning提示学习:prompt-to-prompt