Transformer自学笔记(李宏毅课:Self-attention+Transformer)
Posted Duskku_go
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Transformer自学笔记(李宏毅课:Self-attention+Transformer)相关的知识,希望对你有一定的参考价值。
目录
怎么解决sequence label(即上述第一种输出)的问题?
Self-attention进阶版本->Multi-head Self-attention
训练的一些Tips(不局限于transformer,seq2seq均适用)【略】
Self-attention
Input是什么?
输入不是一个单独的向量,输入的是sequence且长度会改变
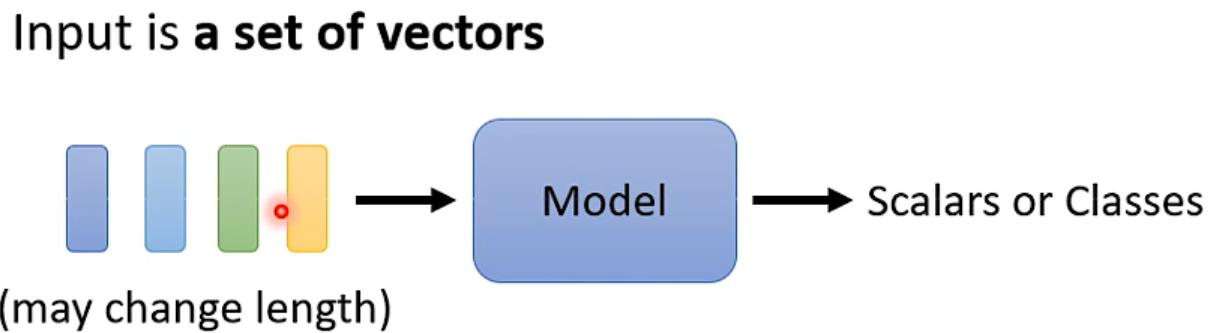
例如语音文字识别,可以以下输入
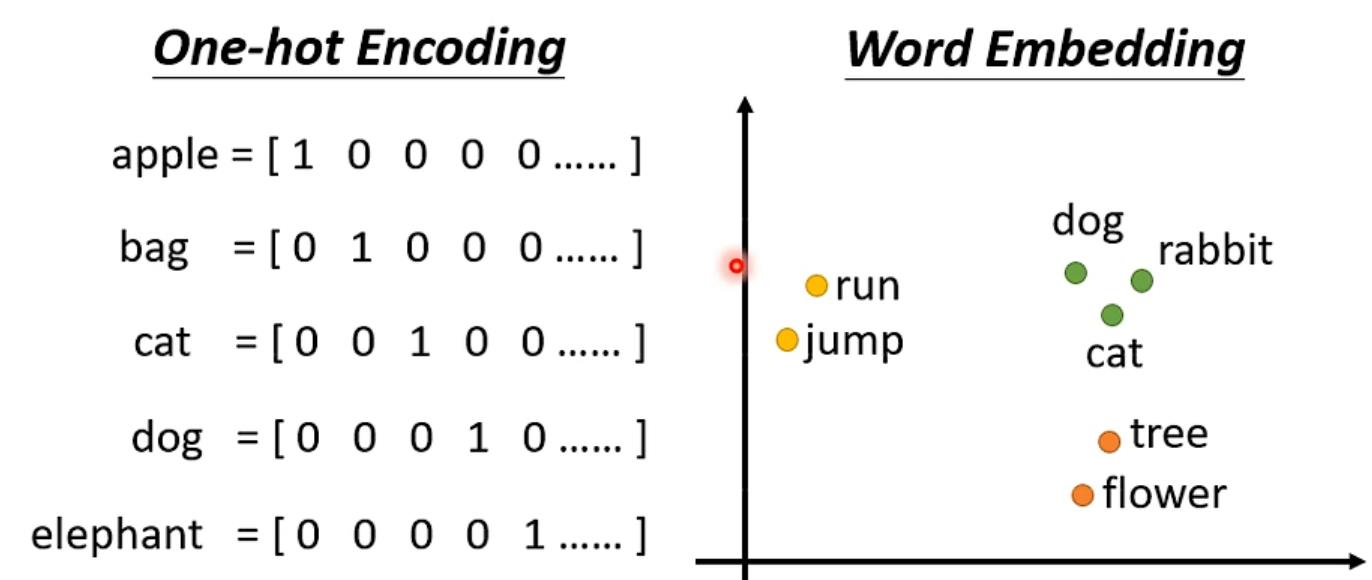
还有语音输入,可以25ms一个frame,之后window向又10ms一次移动
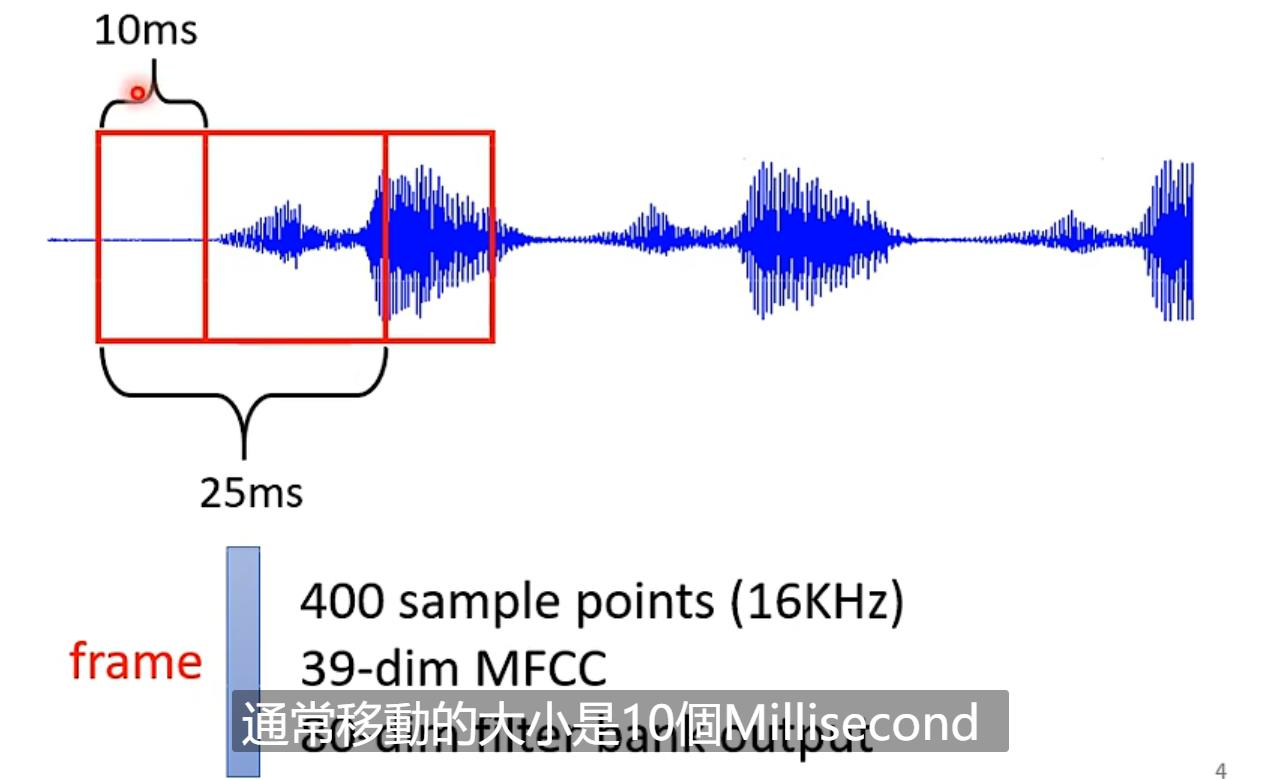
还有graph(例如social network)
还有可以是一个分子
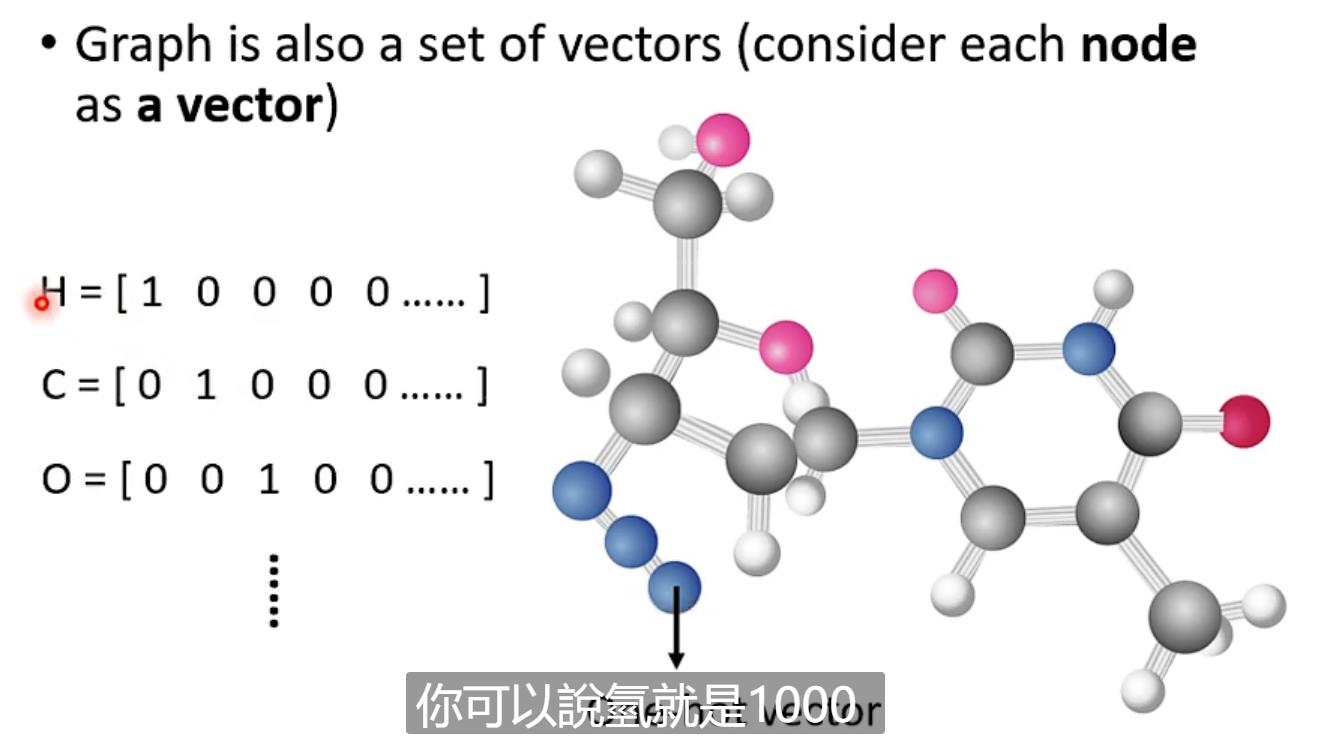
Output是什么?
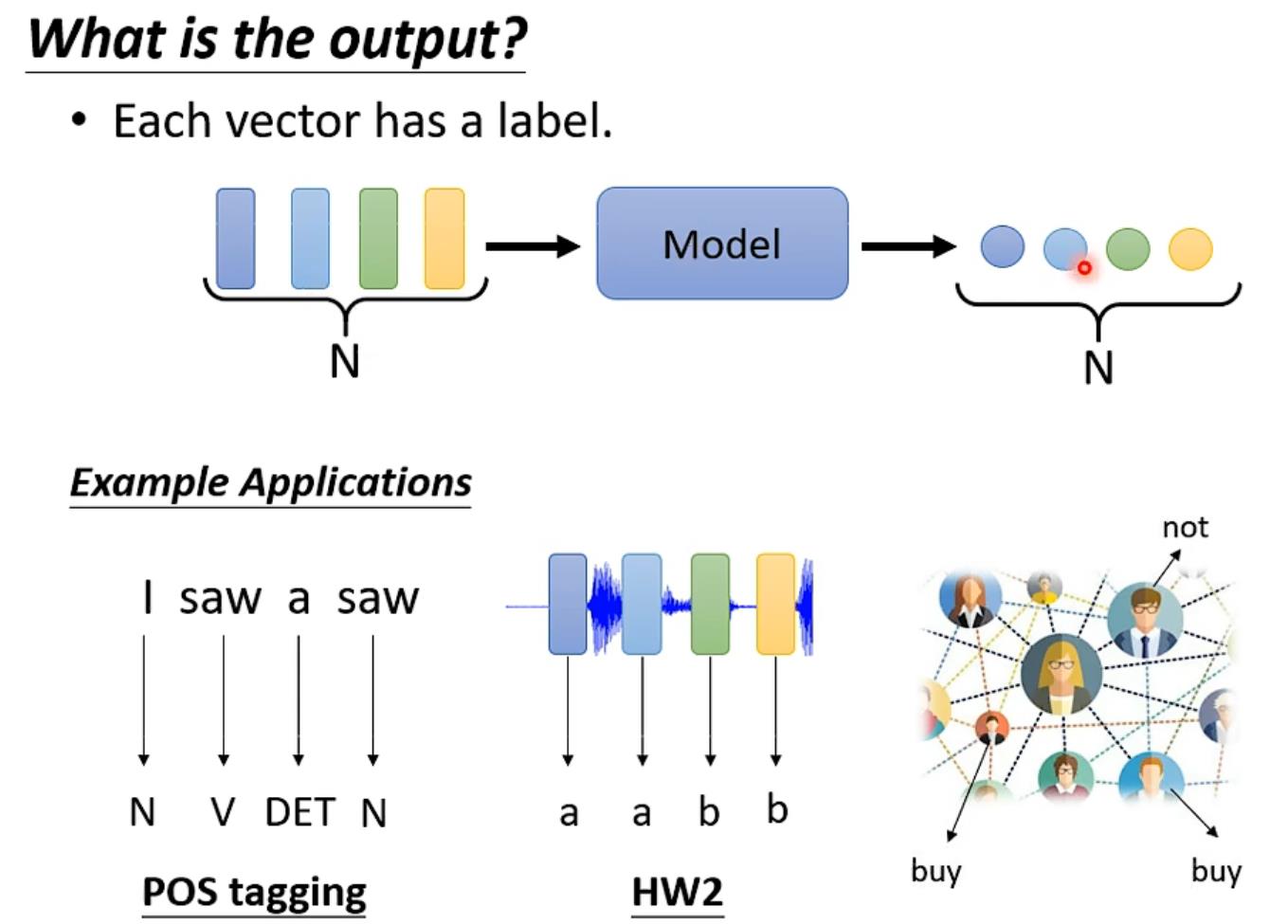
三种可能性:(视频只讲第一种情况)
每一个input对应一个label(Pos tagging、语音辨识、social network)
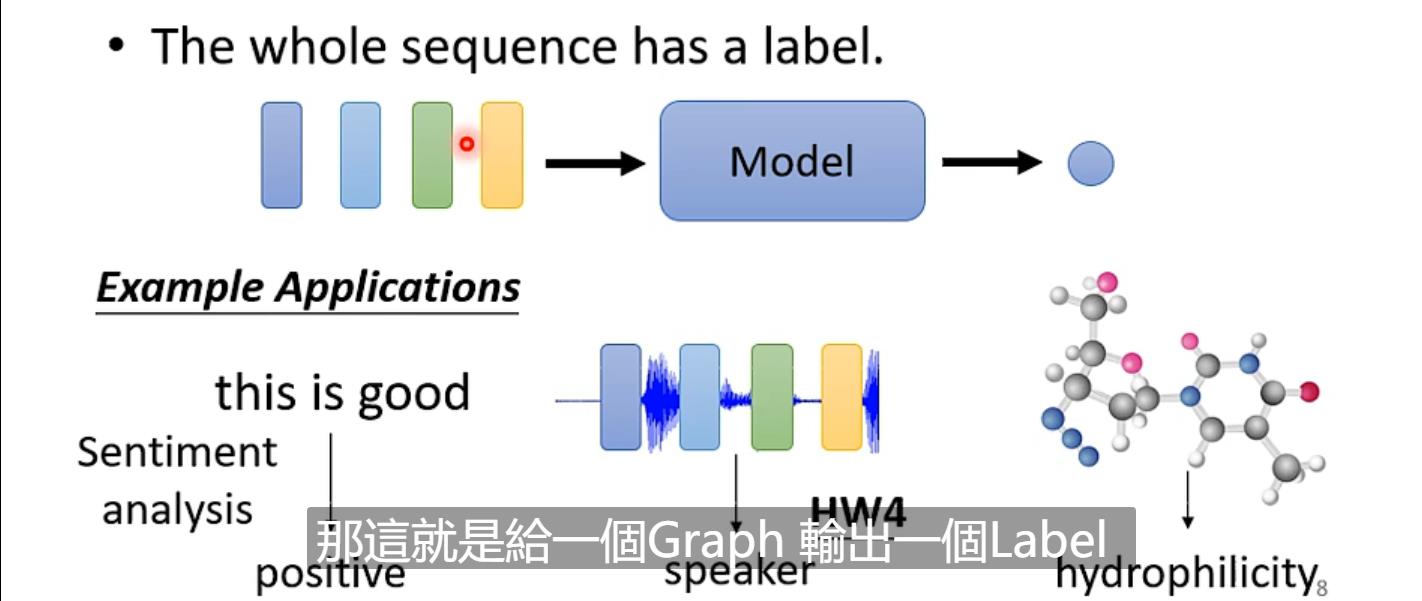
一整个sequence只要一个label(sentiment analysis、辨识语音是谁讲的、给出graph的label)
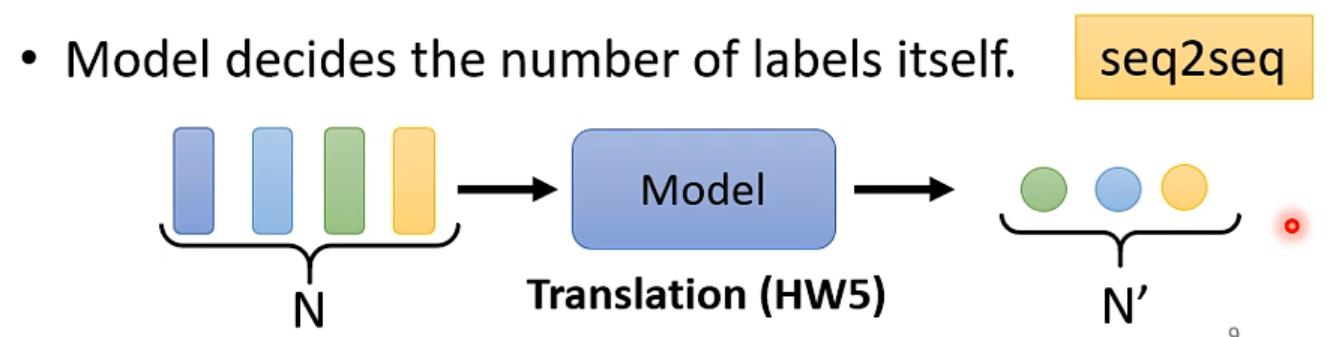
不知道要输出多少个label,机器要自己决定(亦叫seq2seq)
怎么解决sequence label(即上述第一种输出)的问题?
最开始想的是使用一个Fully-Connected的network对于每个输出逐个击破,但是例如语句识别,上下文的context是有一定的关系的,所以这种方法不可行(例如I saw a saw,saw有动词也有名词)
接着会像可不可以前后几个向量串起来放到Fully-Connected的network。但是这次输入有长有短,用一个很大的window盖住所有的输入不合适。
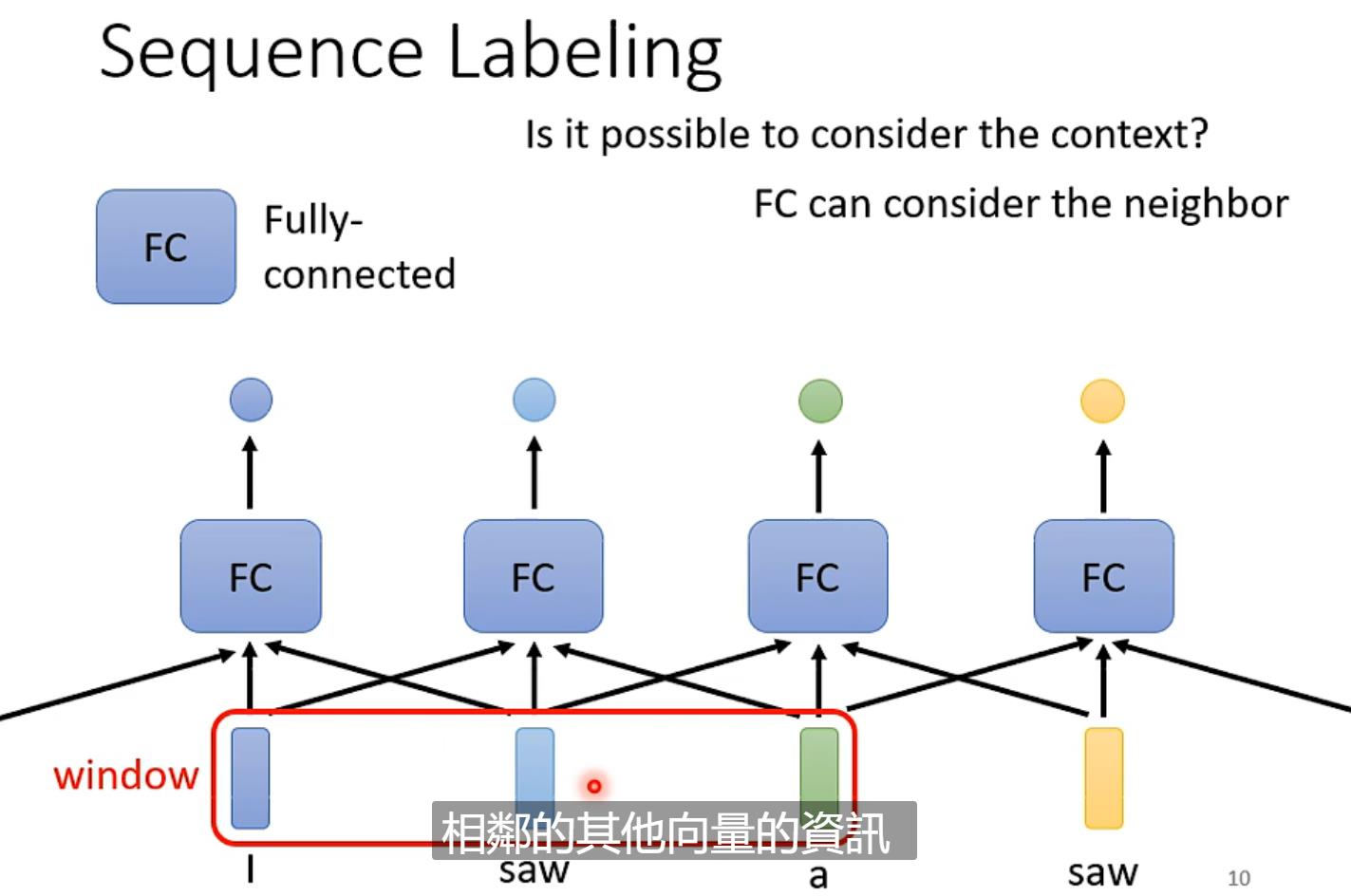
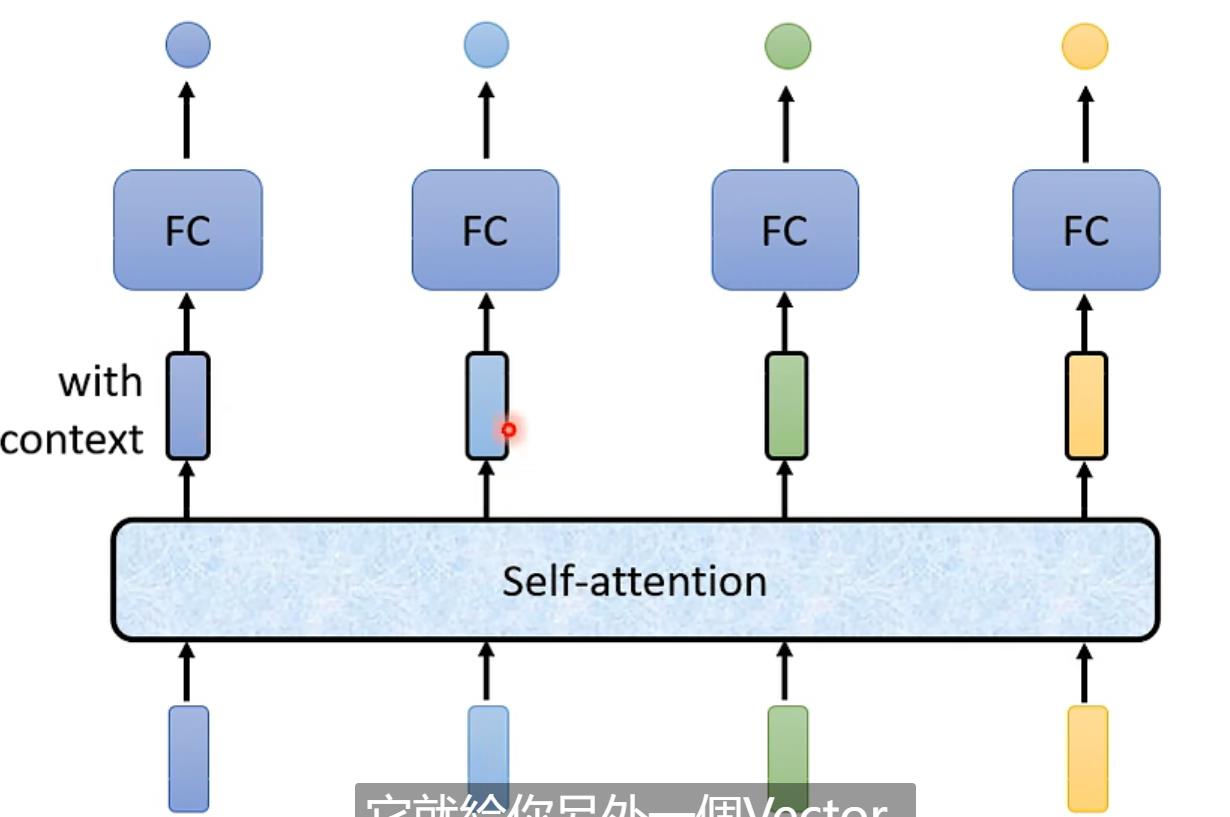
于是就引出了Self-attention(可以交替使用)
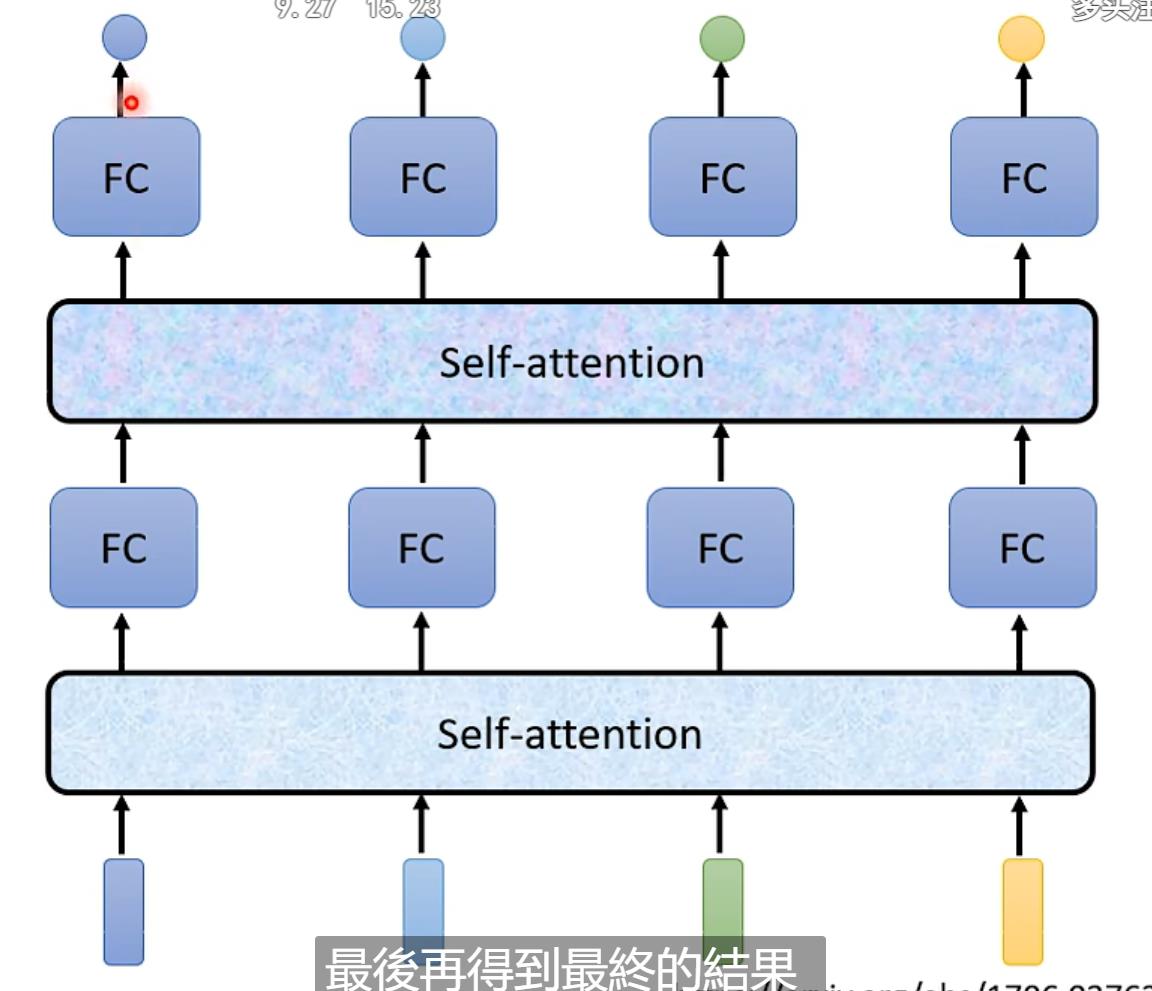
实际当中Self-attention的输入可能会是任意一层layer的输出
Self-attention的计算
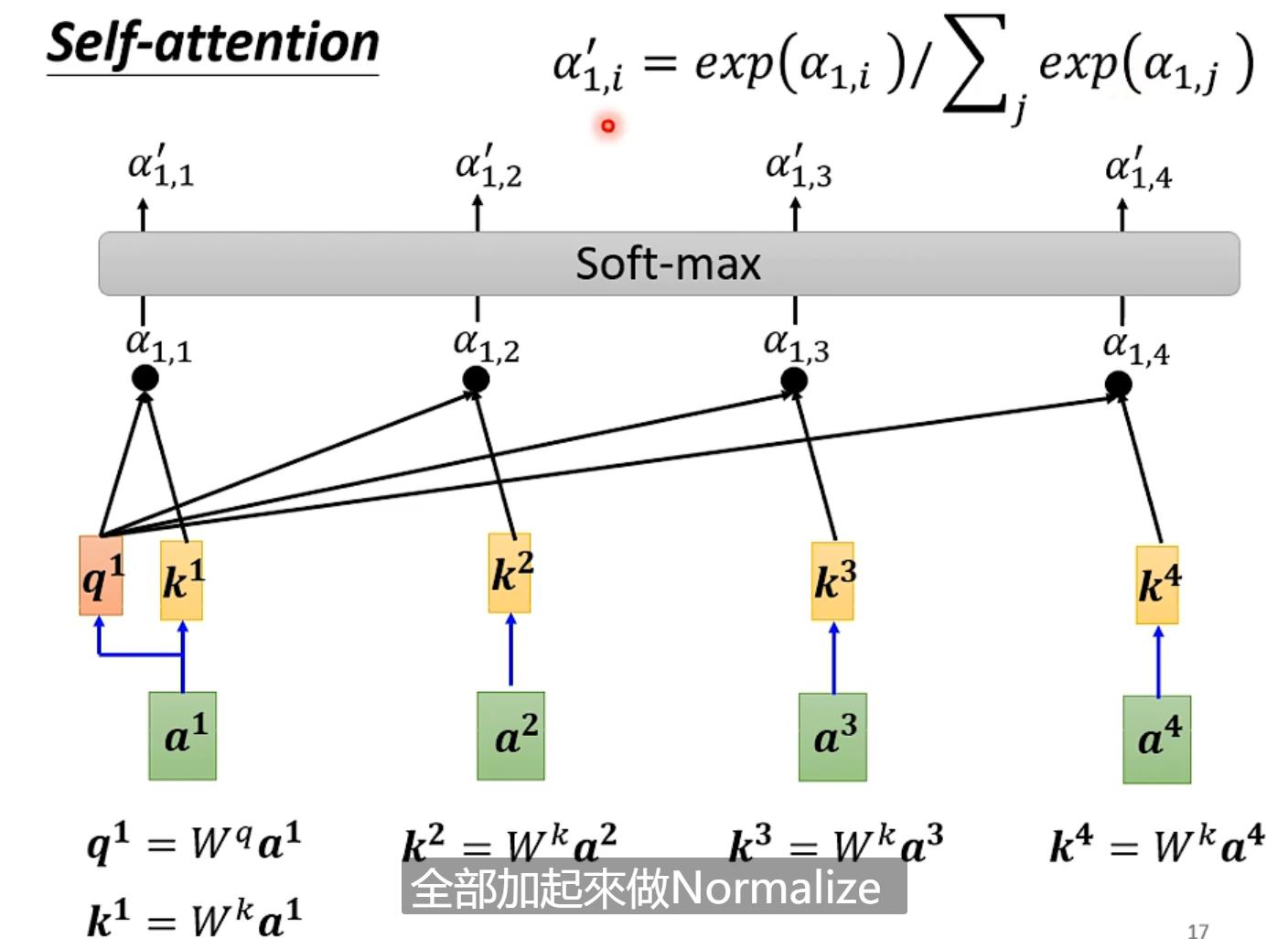
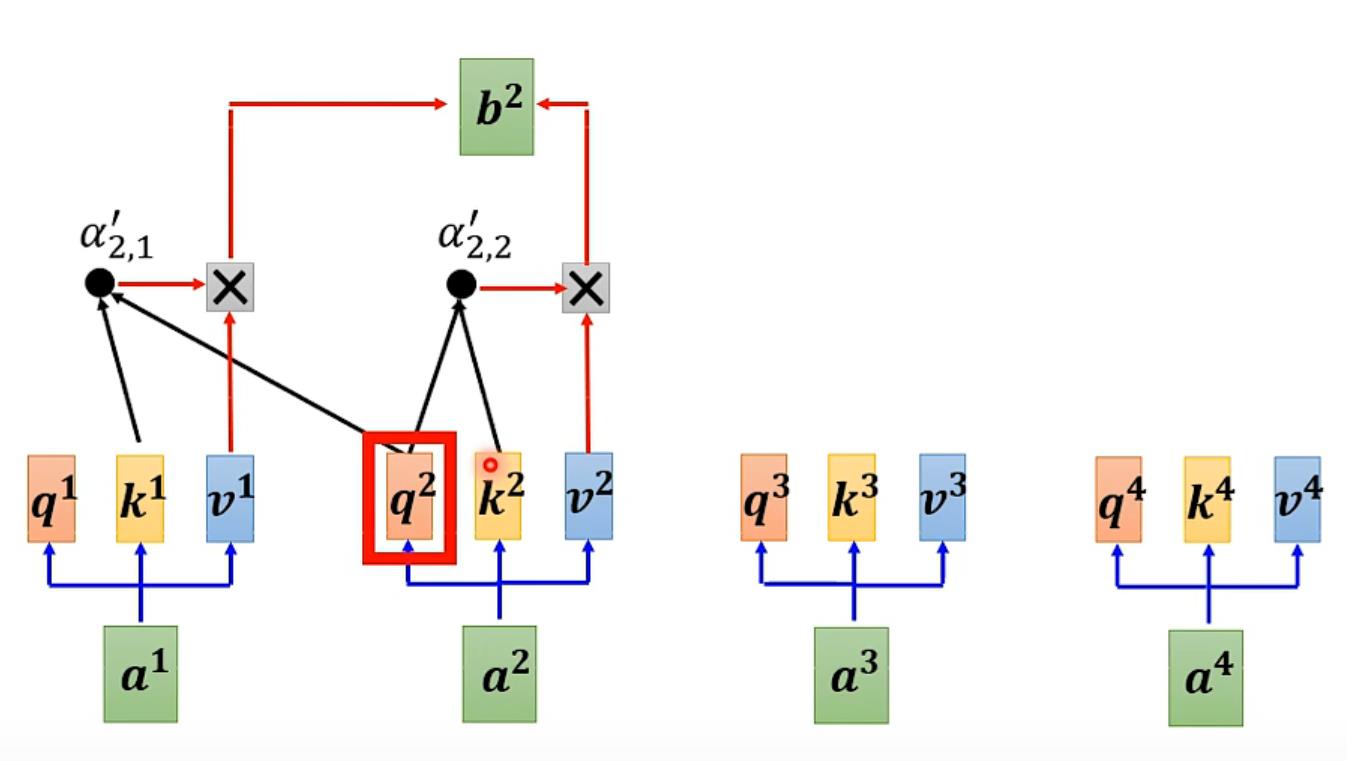
1.例如我们先对a1计算,先找到其他输入对于a1的相关性,用α表示(b是输出)
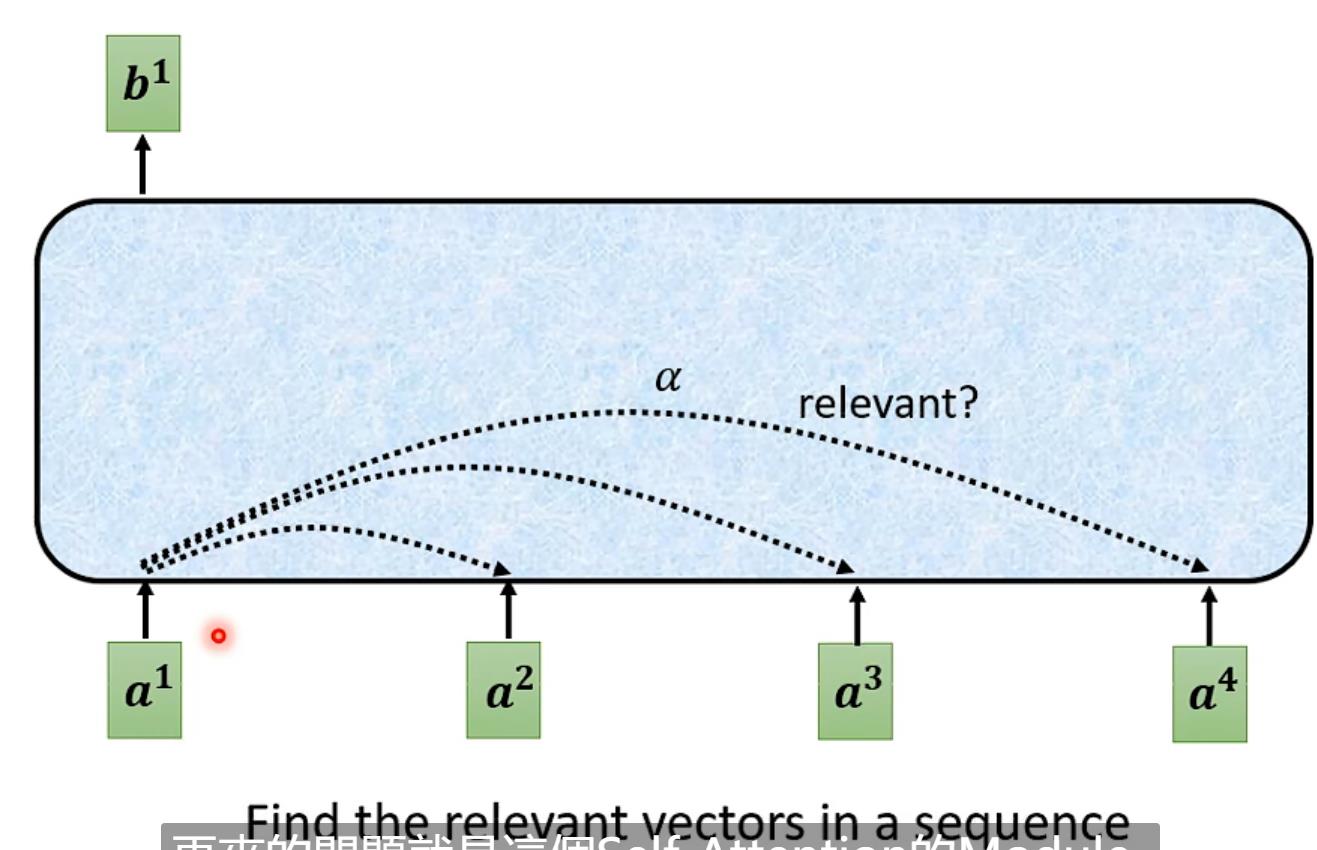
计算α可以用Dot-product、Additive等,本文用Dot-product
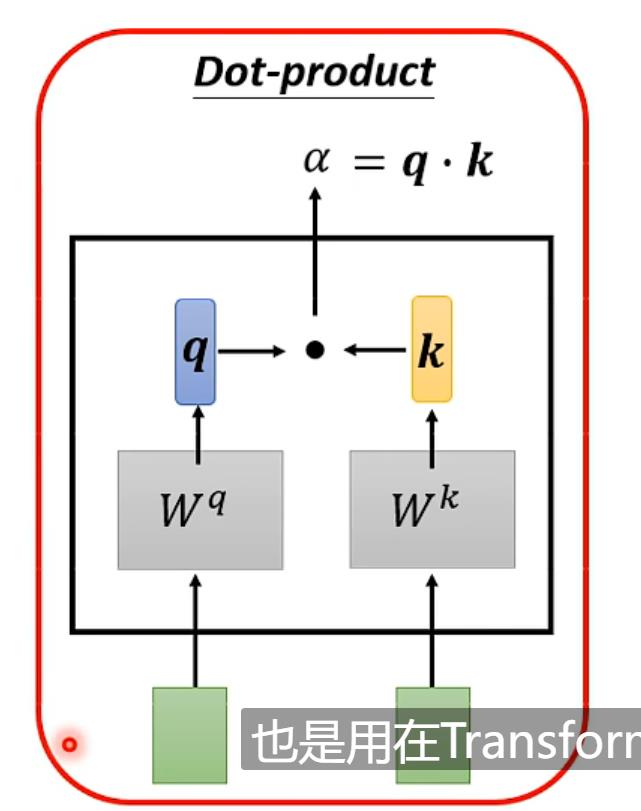
实际计算:
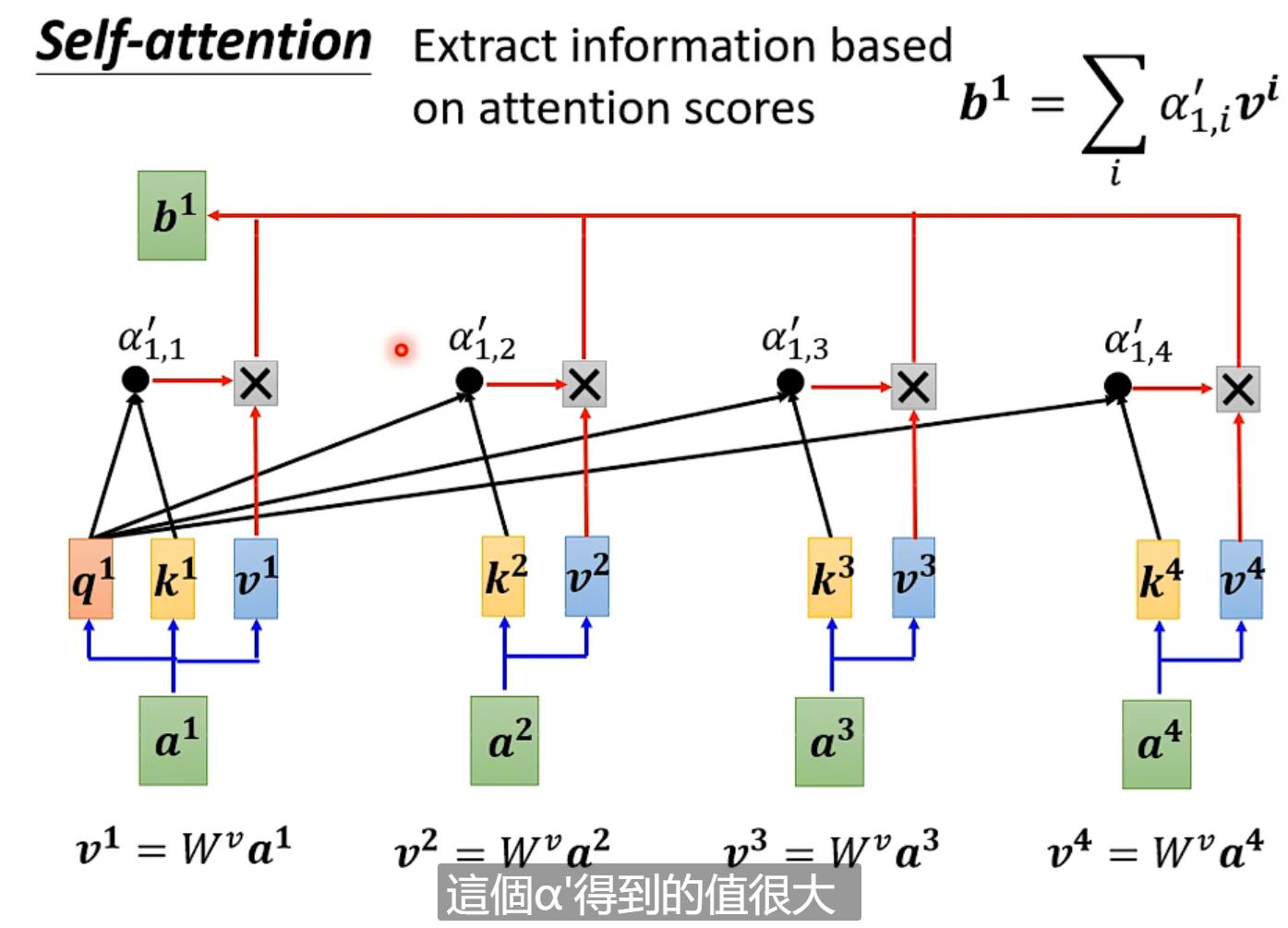
用文字表示:如计算a1时要算其query(Wq*a1)其余包括a1算key(Wk*ai)计算每一个attention score = q1*ki,之后过一个softmax(也可以用其他的function)得到α',最后每一个α'*vi(vi = Wv*ai)相加求出b1【vi哪个最大就会dominant你抽出的结果】
用矩阵表达:
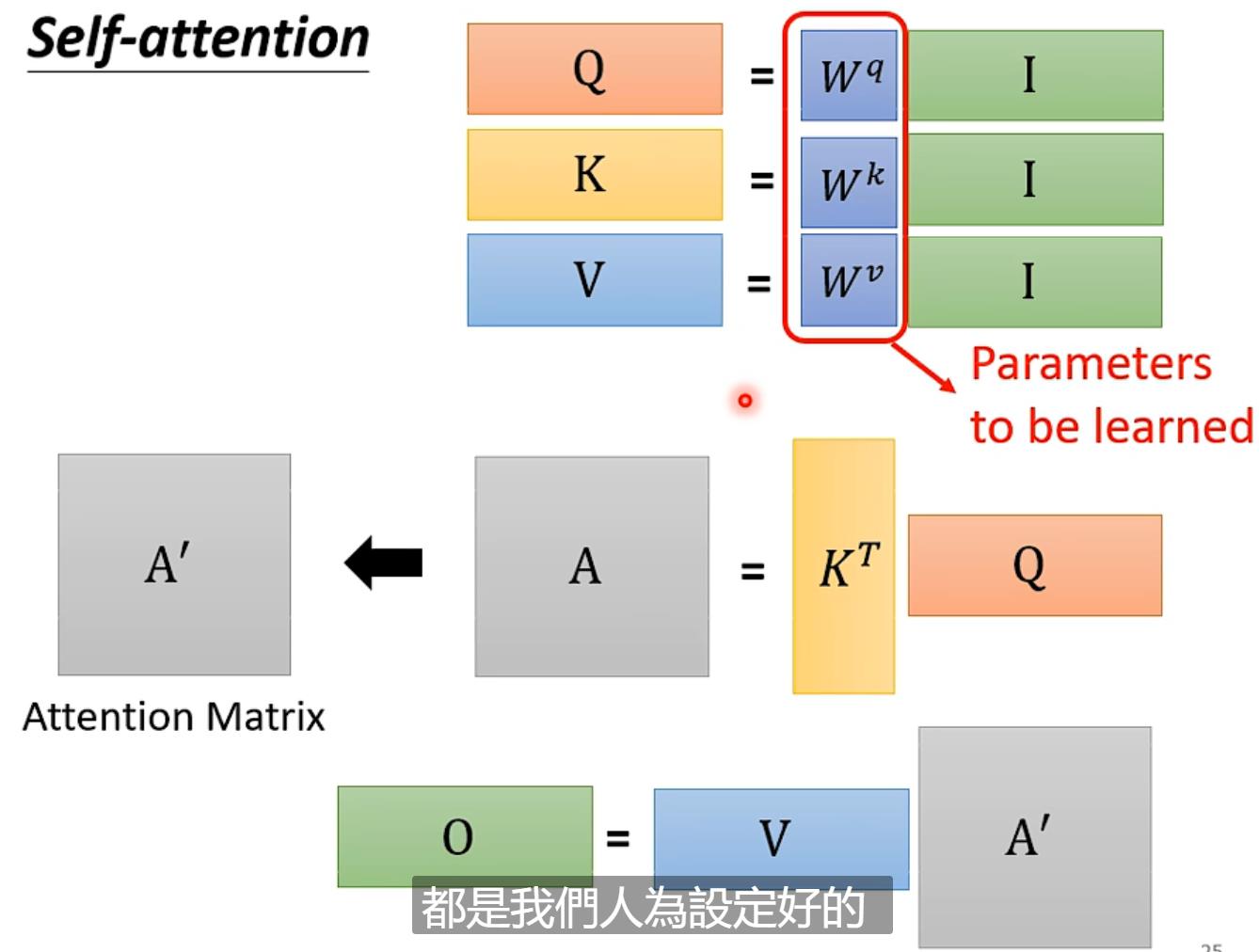
这其中的未知数只有Wq、Wk、Wv(通过training-data找出)
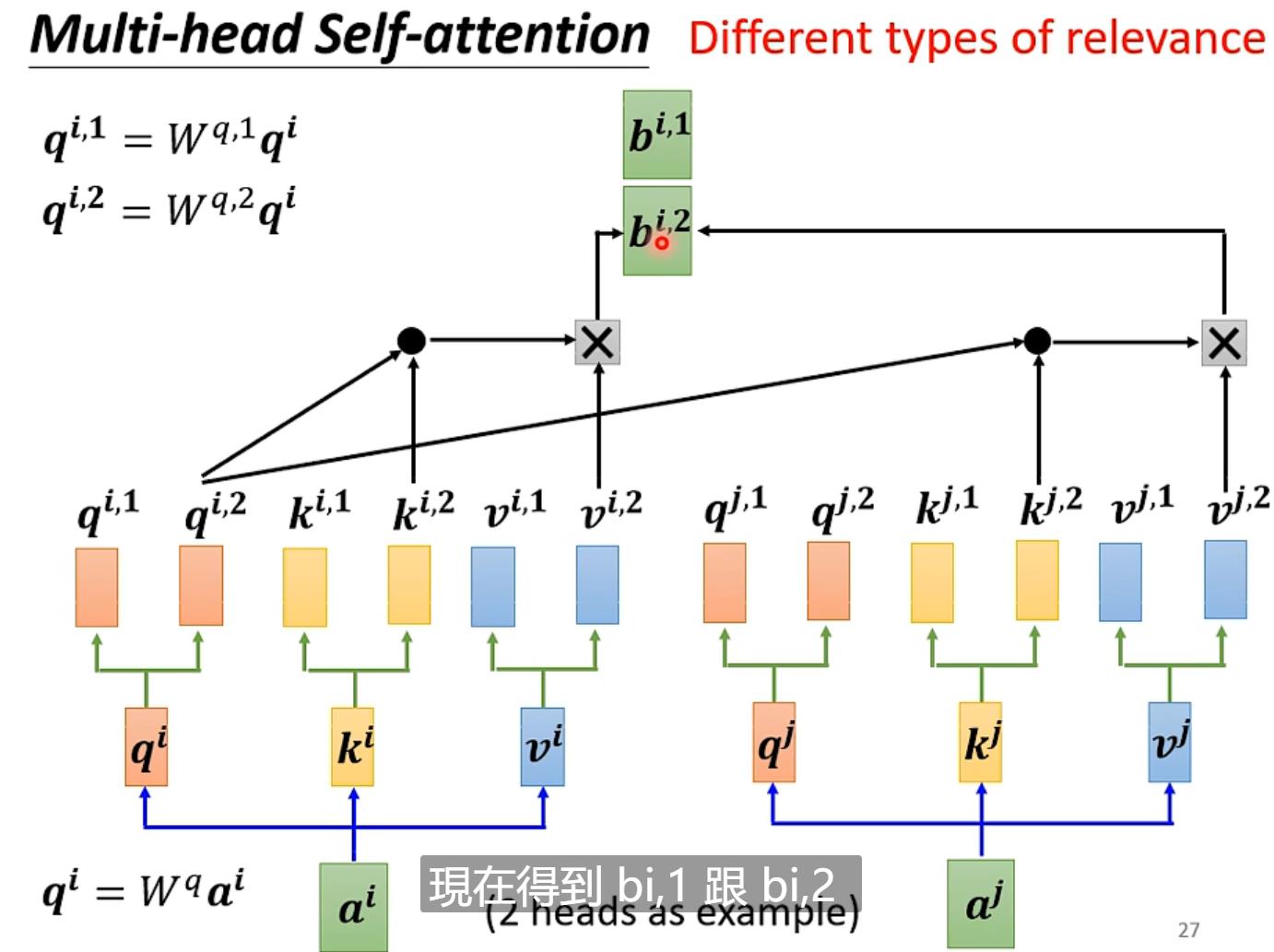
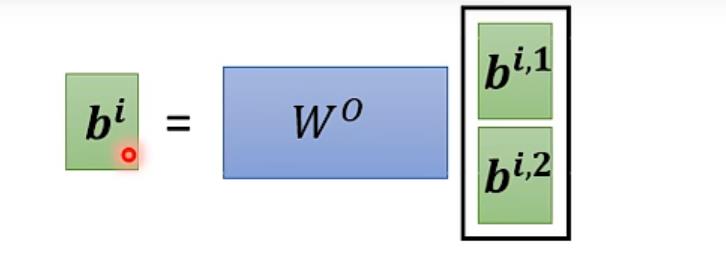
Self-attention进阶版本->Multi-head Self-attention
即每个qi、ki、vi各自分成两个(或多个)qi1、qi2...
位置信息怎么处理?
用到position encoding的技术将位置信息输入
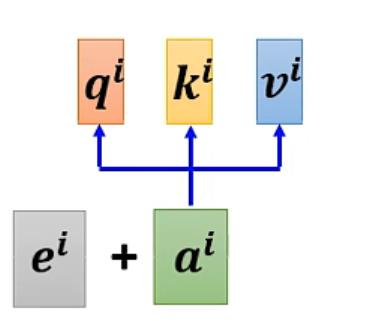
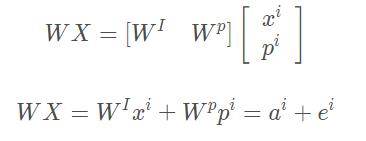
计算position vector的ei可以使用多种方法(尚待研究)
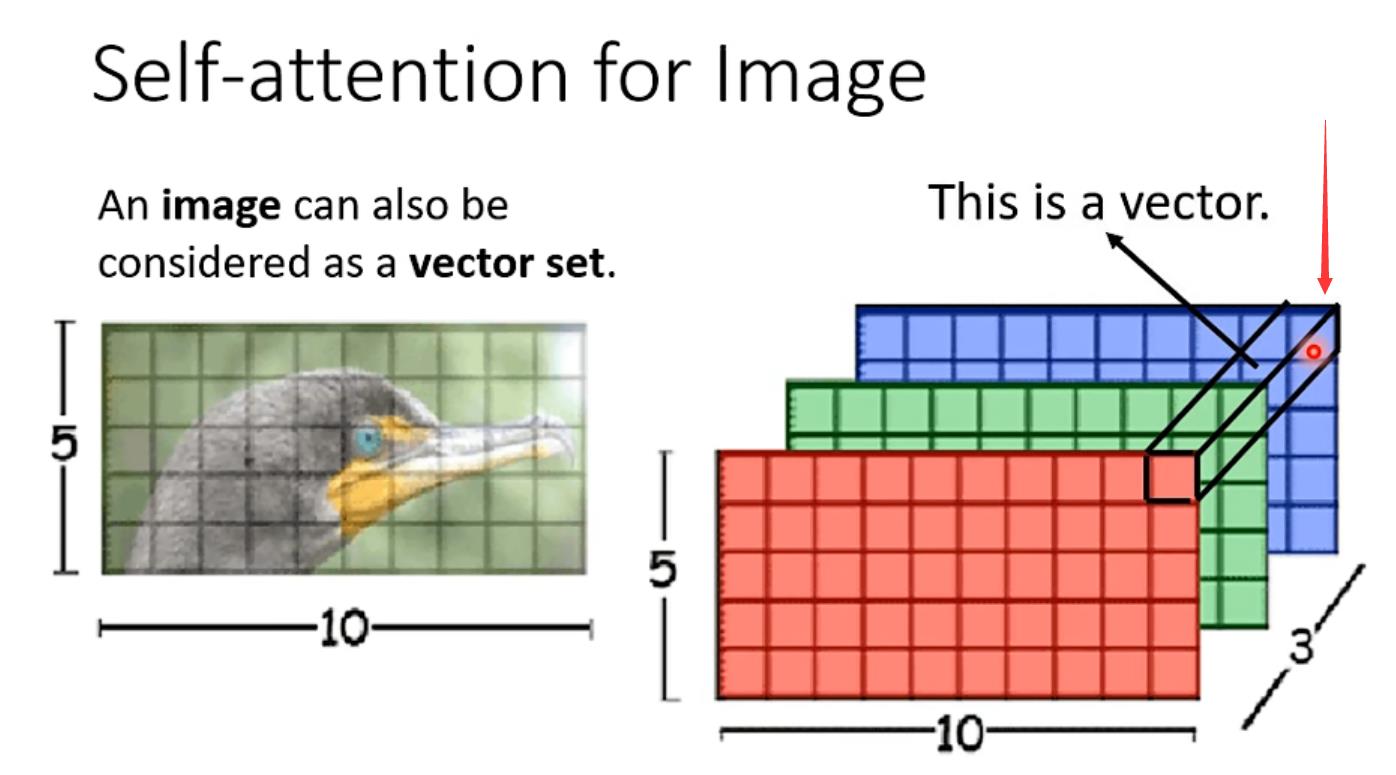
Self-attention用在影像上(我关注的点)
如一个5*10*3(3是channel的数量)图像,以箭头所标注的地方看作一个向量,则整张图像就可以看作是一个5*10的vector set
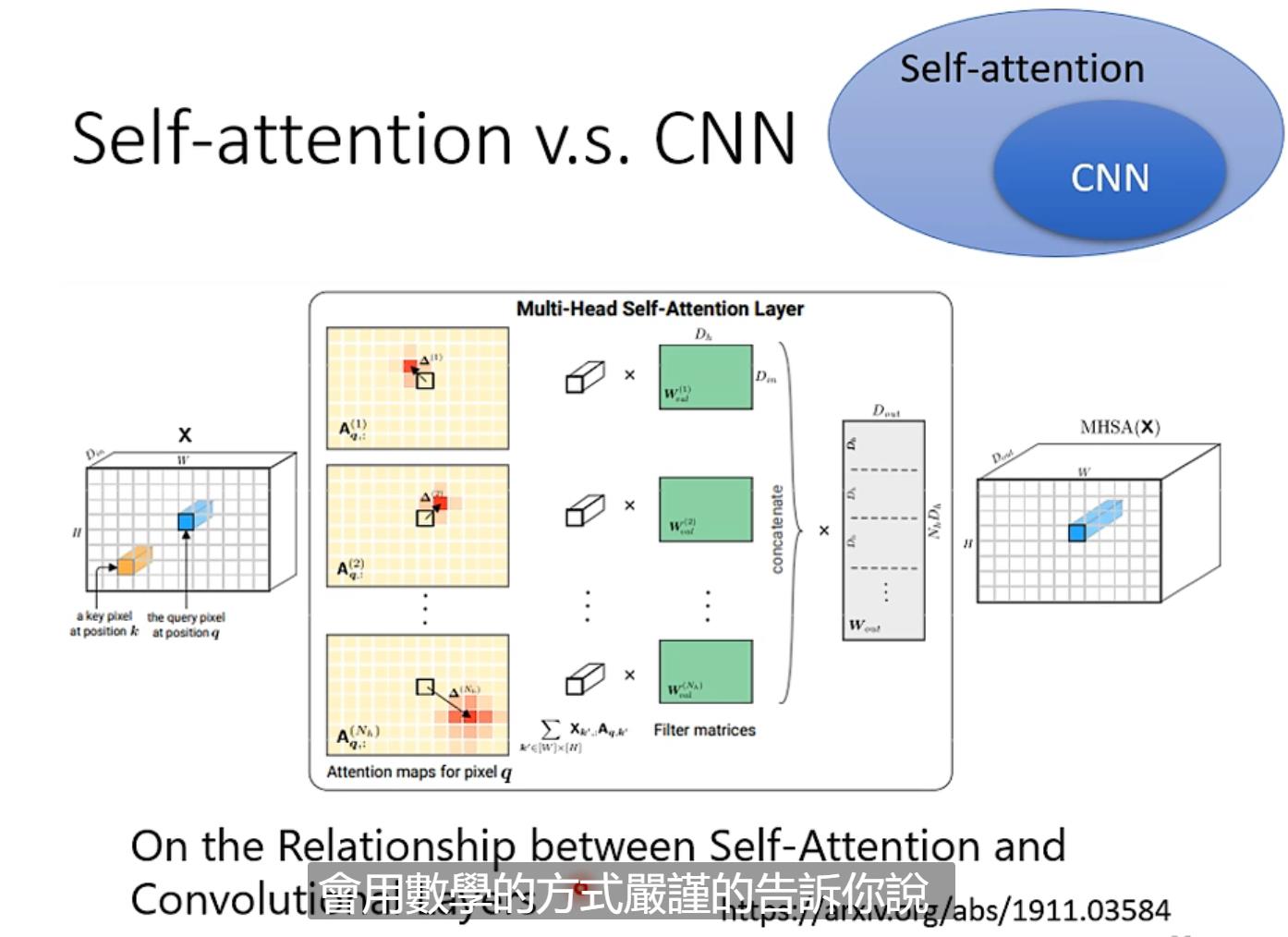
Self-attention和CNN区别
CNN只考虑receptive filed范围内的信息,但是Sa(即Self-attention)考虑的是整个范围。于是可以说CNN是Sa的特例,简化版的Sa;Sa是复杂化的CNN。
(视频也讲了Sa和GNN的关系,我没有了解过GNN所以没有观看记录;与graph也没有继续了解)
Transformer
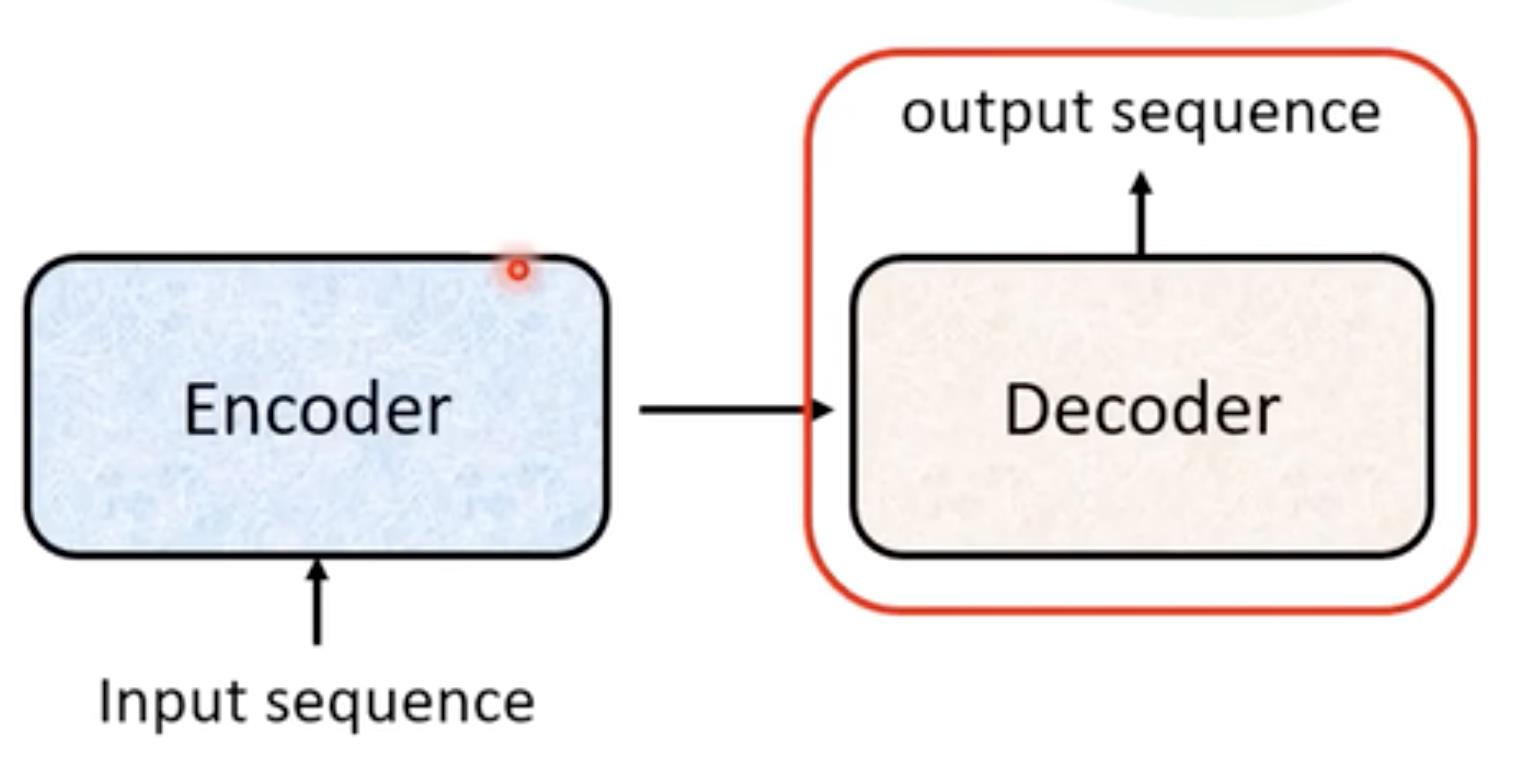
首先transformer是Sequene-to-Sequence的model(这一次本视频讲的是不知道输出多少,由机器自己学习决定)【transformer模型是seq2seq结构的一种具体的模型,是完全基于Attention机制的seq2seq结构】
Seq2Seq架构
首先有一个Encoder和Decoder
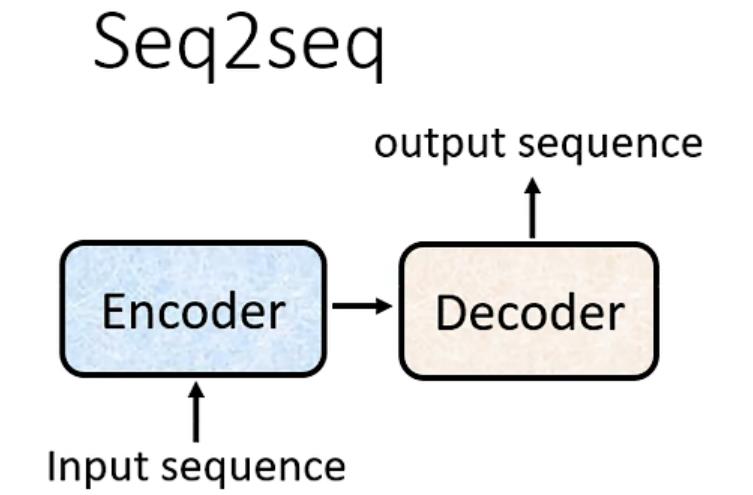
Encoder部分
给一排向量输出另外一排向量(transformer中的Encoder部分用的就是Self-attention)
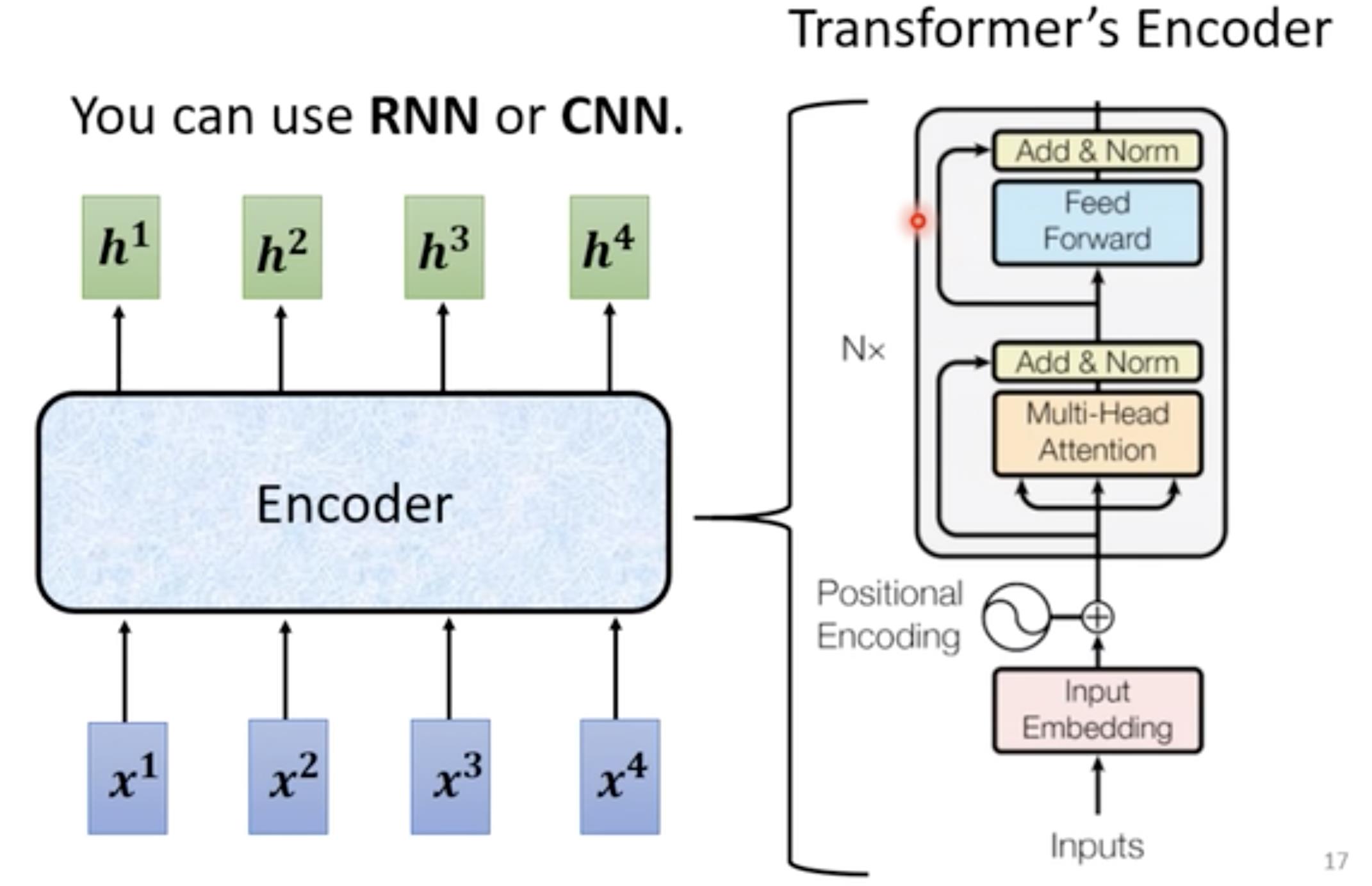
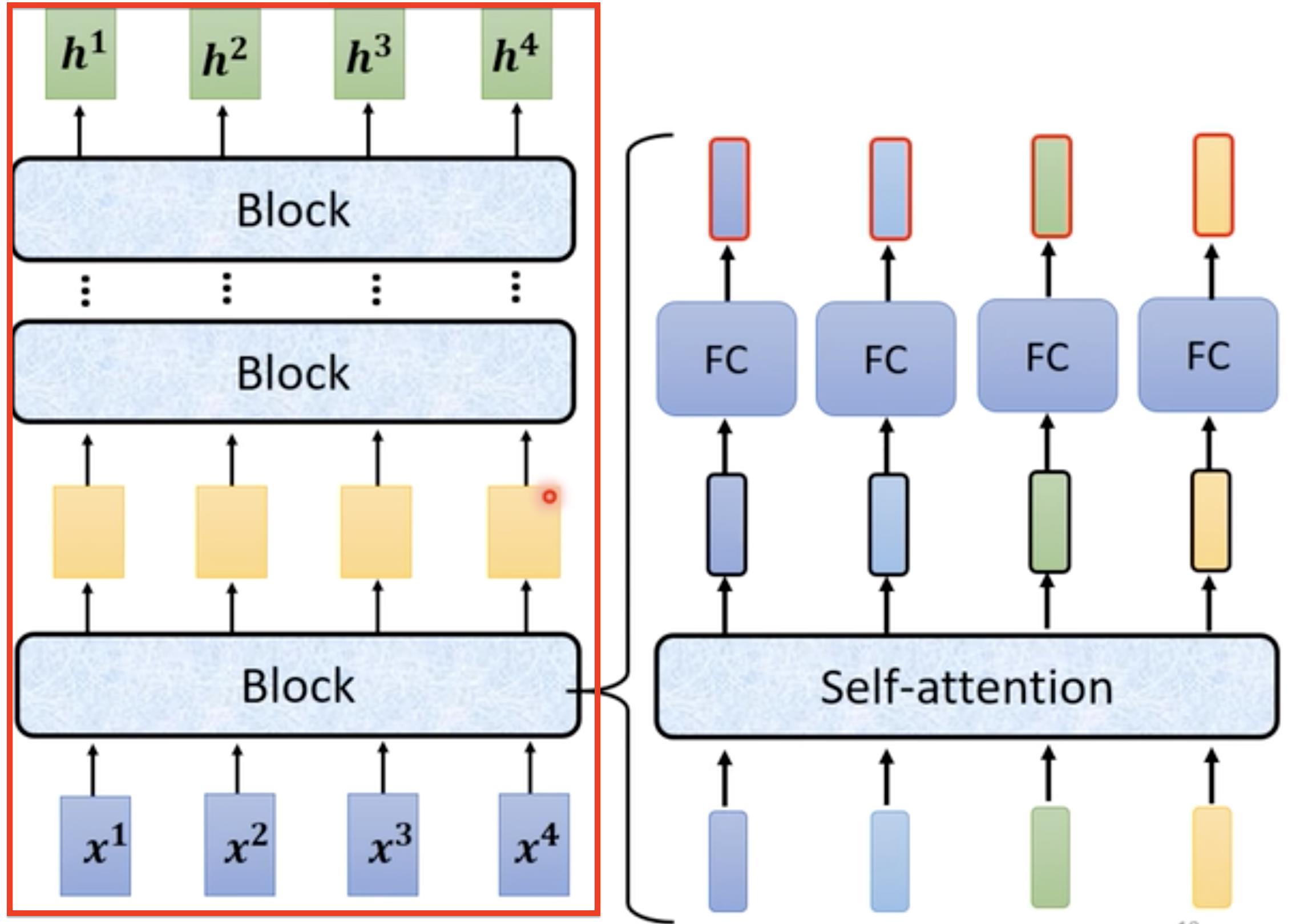
Encoder的基本架构,就是红色框中,输入一堆向量然后经过一个block输出一堆向量,然后接着输入到下一个block中…最后输出h1, h2, h3, h4,在Transformer网络中每一个block里面是下图中右面这部分组成,对输入的向量进行self-attention操作,每个向量都考虑与其它向量的关联性之后然后输出,然后接入到FC(feed forward network前馈神经网络)中输出结果。
实际transformer中的Self-attention用到了residual connection,即通过一层Self-attention的输出要加上原有的input作为最后的output(残差)【FC中也用到了residual connection、norm】,之后进行layer normallization(norm对应的操作)【这个就是对向量中每个元素求mean[平均值], standard deviation[标准差] 】
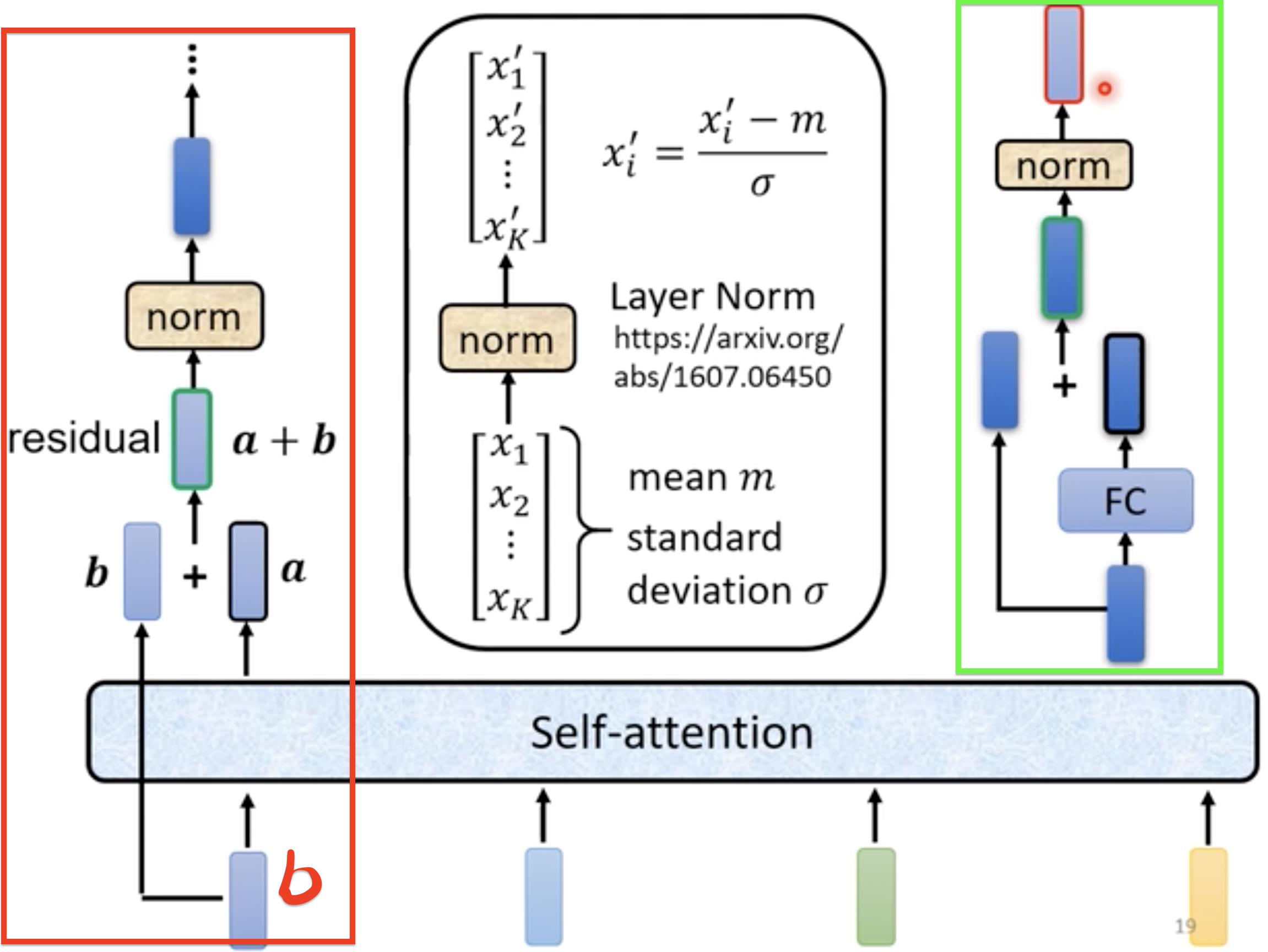
以上就是下图红色区域的操作,总结一下,就是输入向量如果需要位置信息的话,加上位置Positional向量,然后经过Self-attention(Multi-Head Attention),做add&Norm操作,其中add就是(Residual操作,将输入向量加到self-attention结果输出上),然后将add结果做Layer Norm操作,接着放入到Feed Forward网络中输出结果继续做add&Norm操作。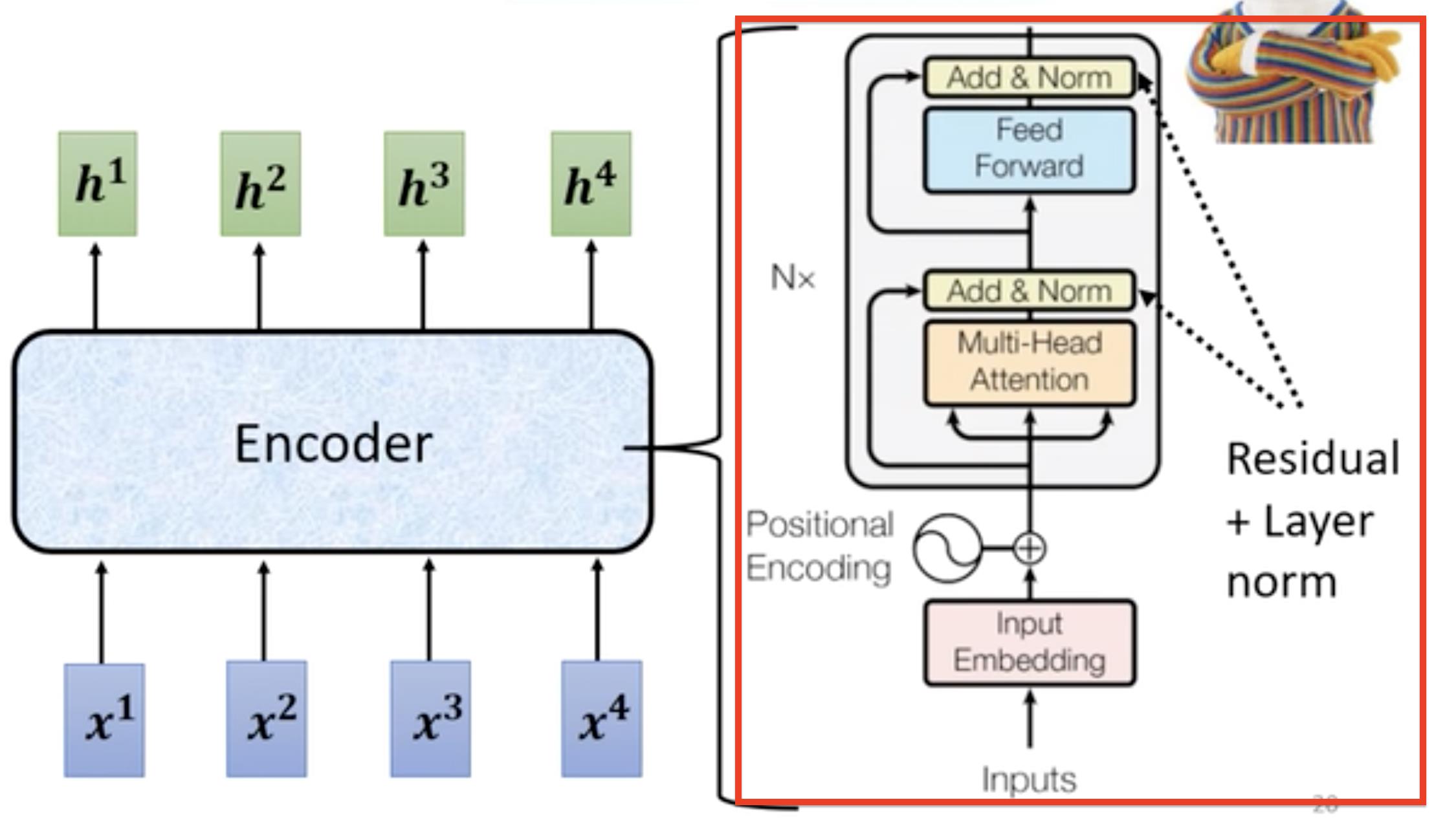
以上讲的Encoder是transformer原文论讲的,目前有很多其他的
Decoder部分
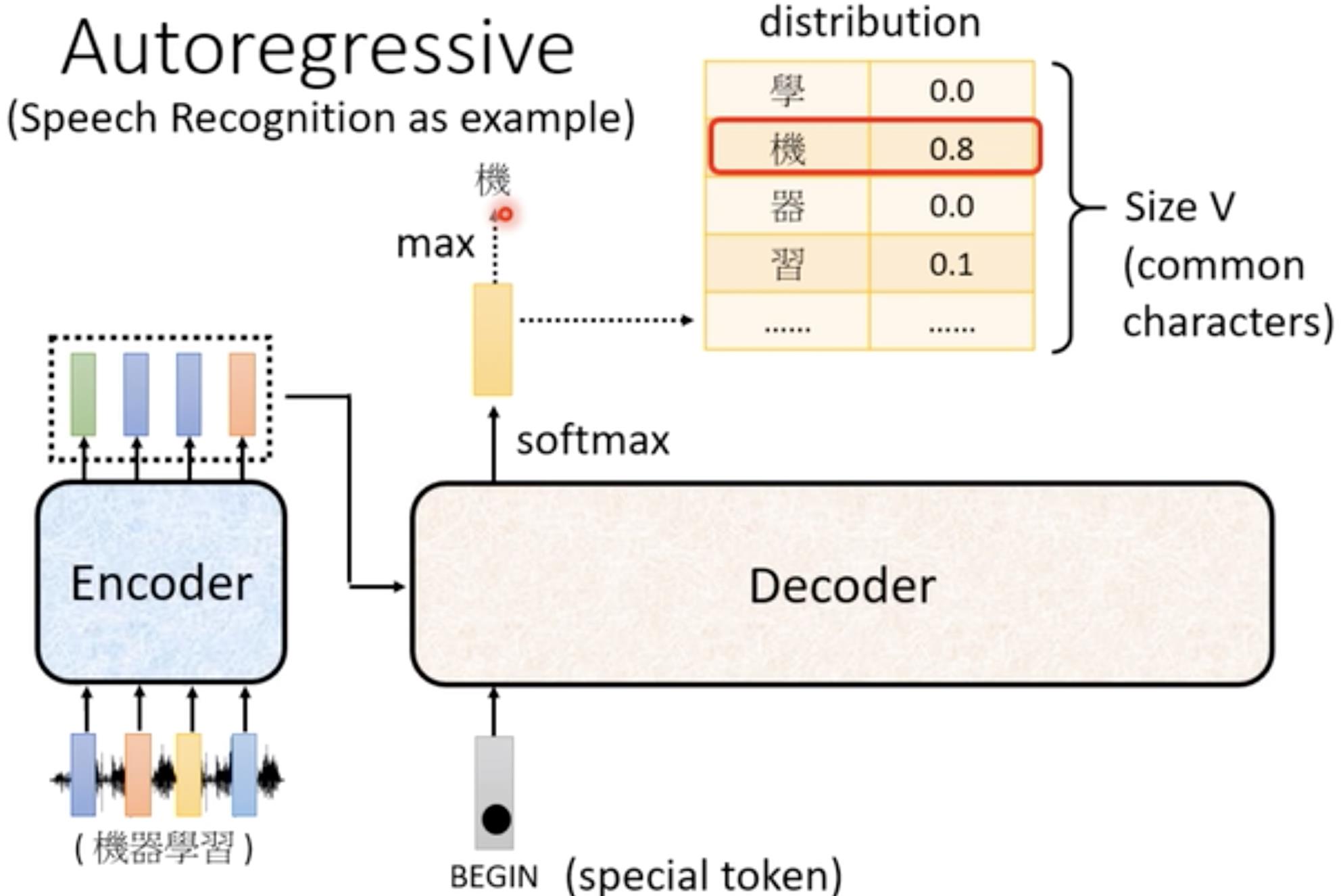
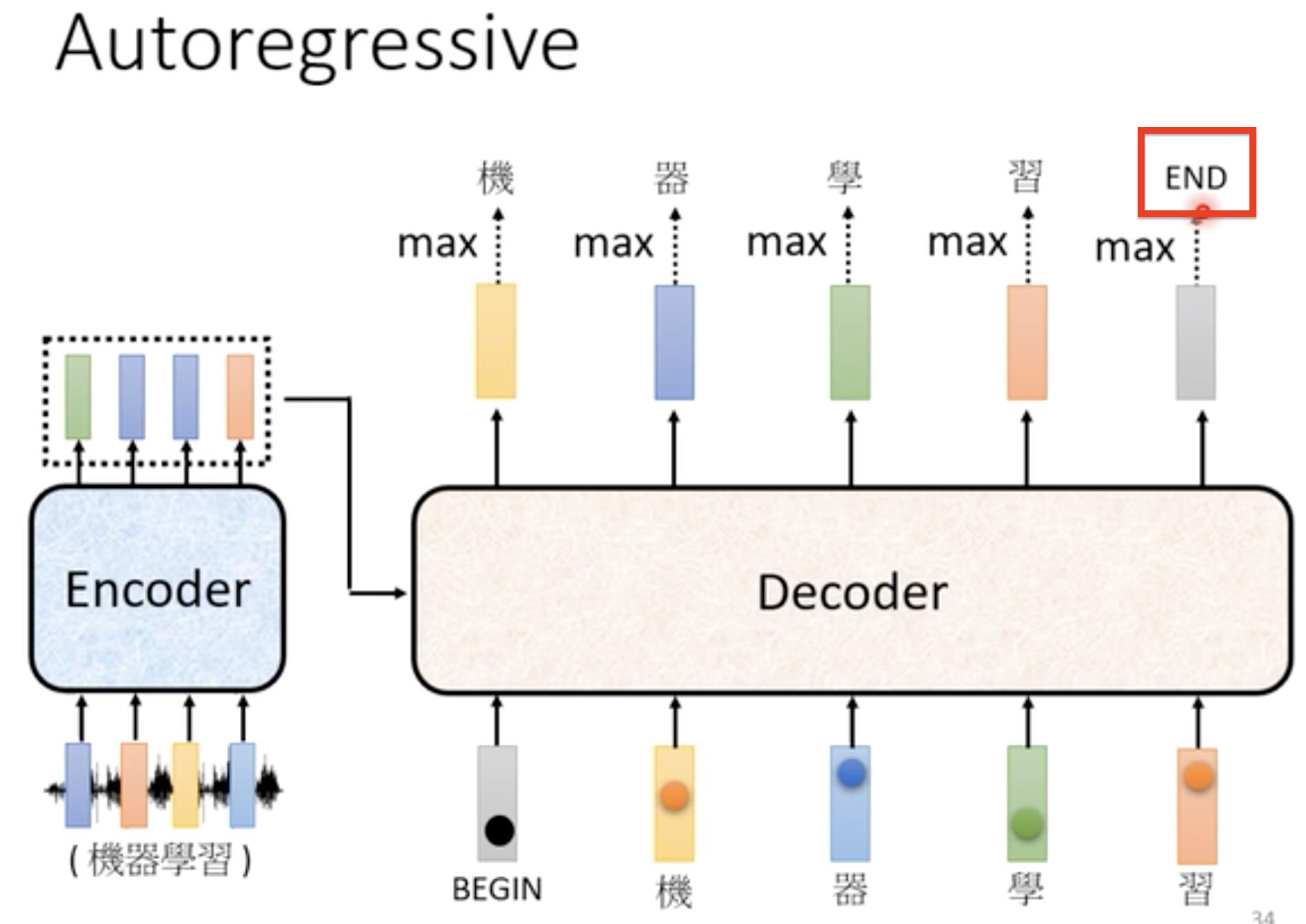
本视频中讲解的是比较常见的Autoregressive(AT)的Decoder,以语音辨识为例子。我们需要将Encoder的输出输入到Decoder当中,这个后面再讲。
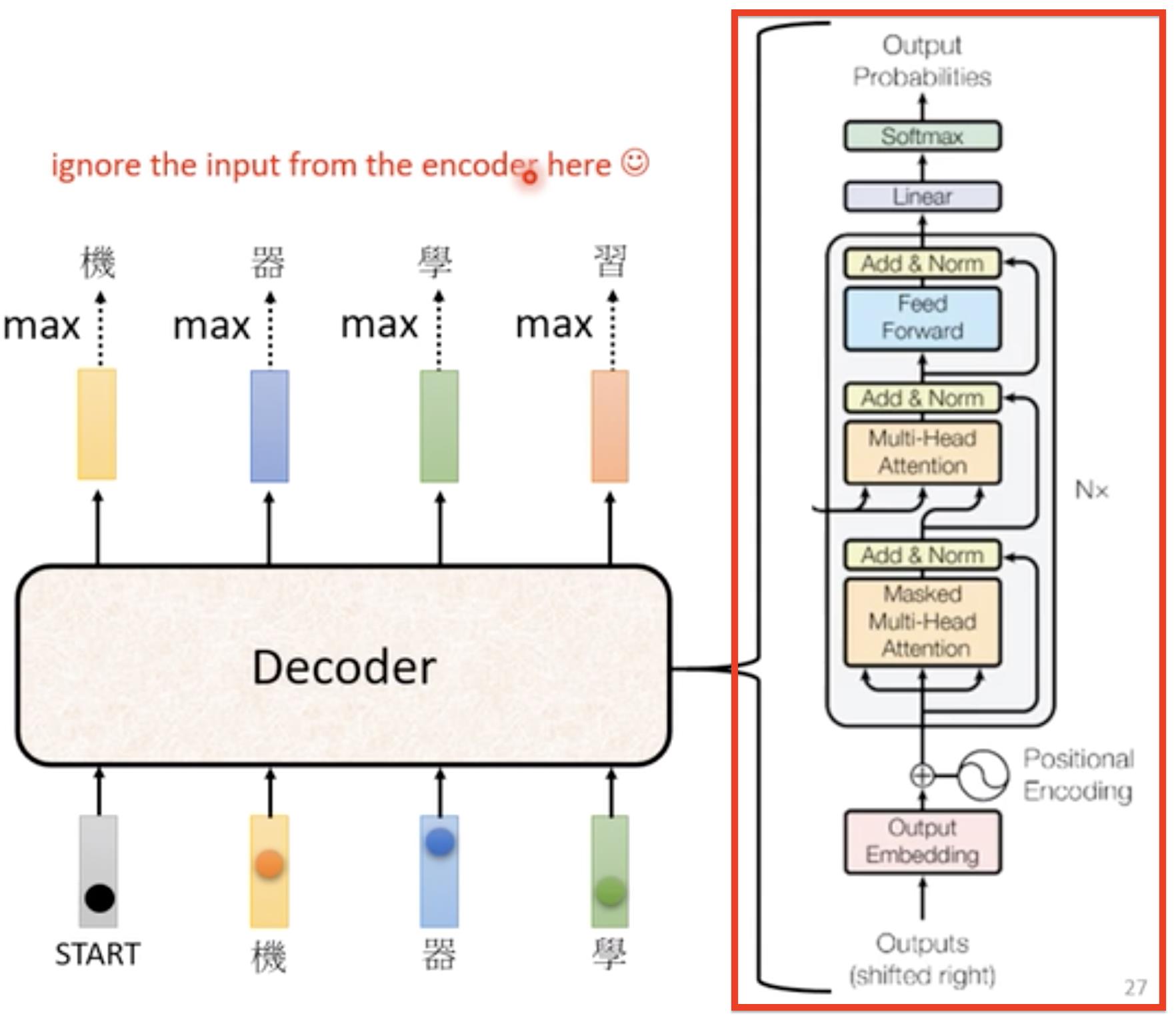
首先我们把Encoder输出的向量,读入到Decoder中,这时给Decoder一个专门的记号(special token)Begin,告诉Decoder开始了,然后Decoder输出向量(这里的向量大小取决于你想输出的内容,如果你想输出文字,那么它的长度就是所有文字的数量,如果是英文单词,那么它的长度就是所有英文单词的数量…),再对向量整体做softmax(求每个中文的概率,所有中文概率加起来为1),求其中最大值就是它的第一个输出结果。【输出结果是一个one-hot向量】
之后我们将第一个输出结果作为第二个输入,同Begin一同作为输入再次以上述方式输出第二个结果。反复执行上述操作->Decoder每次输入都是上一次输出的结果累加起来的。
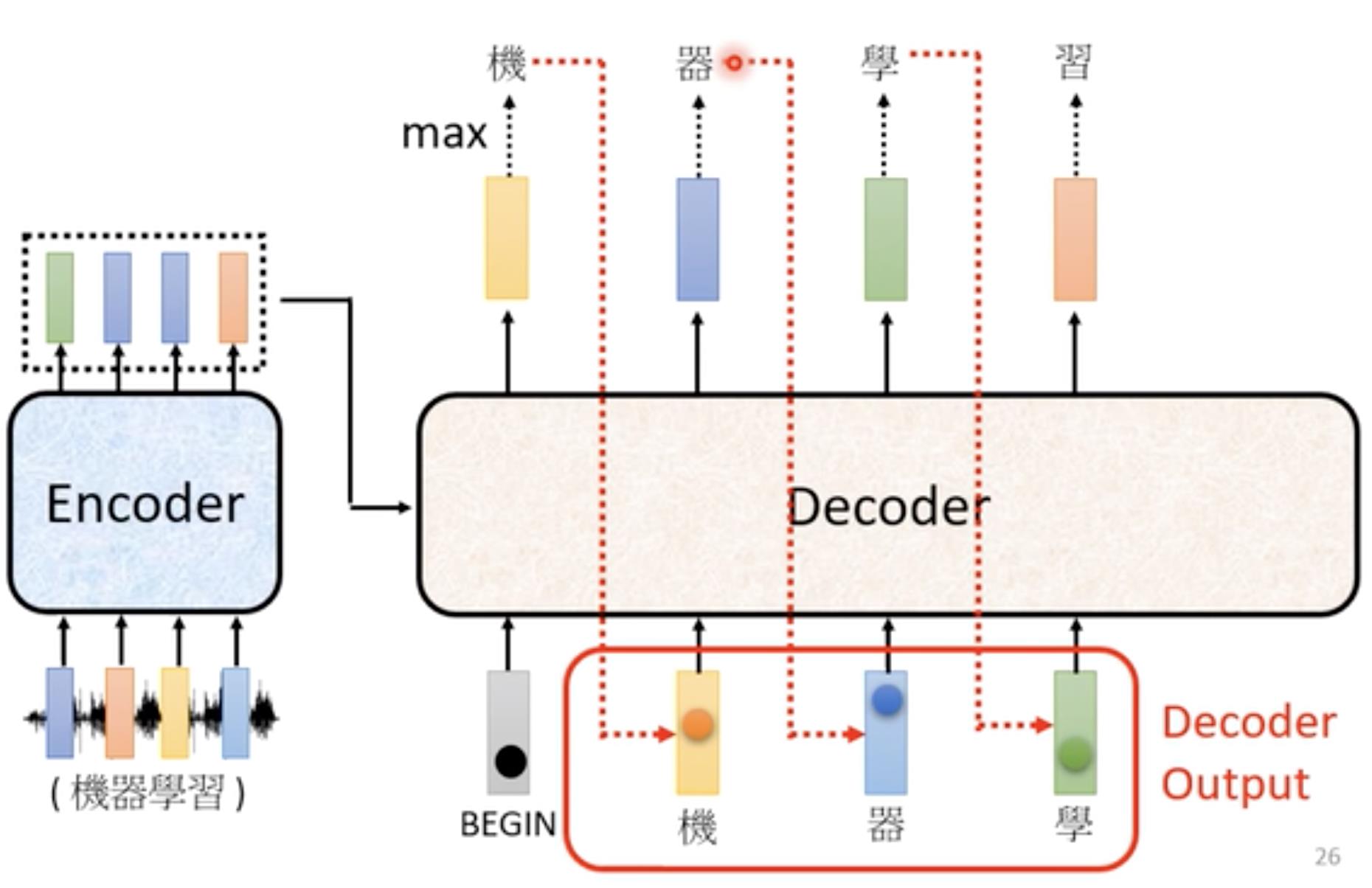
在这里提出了一个问题,会不会Decoder输出一个错误的结果,之后作为新一轮的输入导致一步错,步步错。下面会讲解。【见training部分】
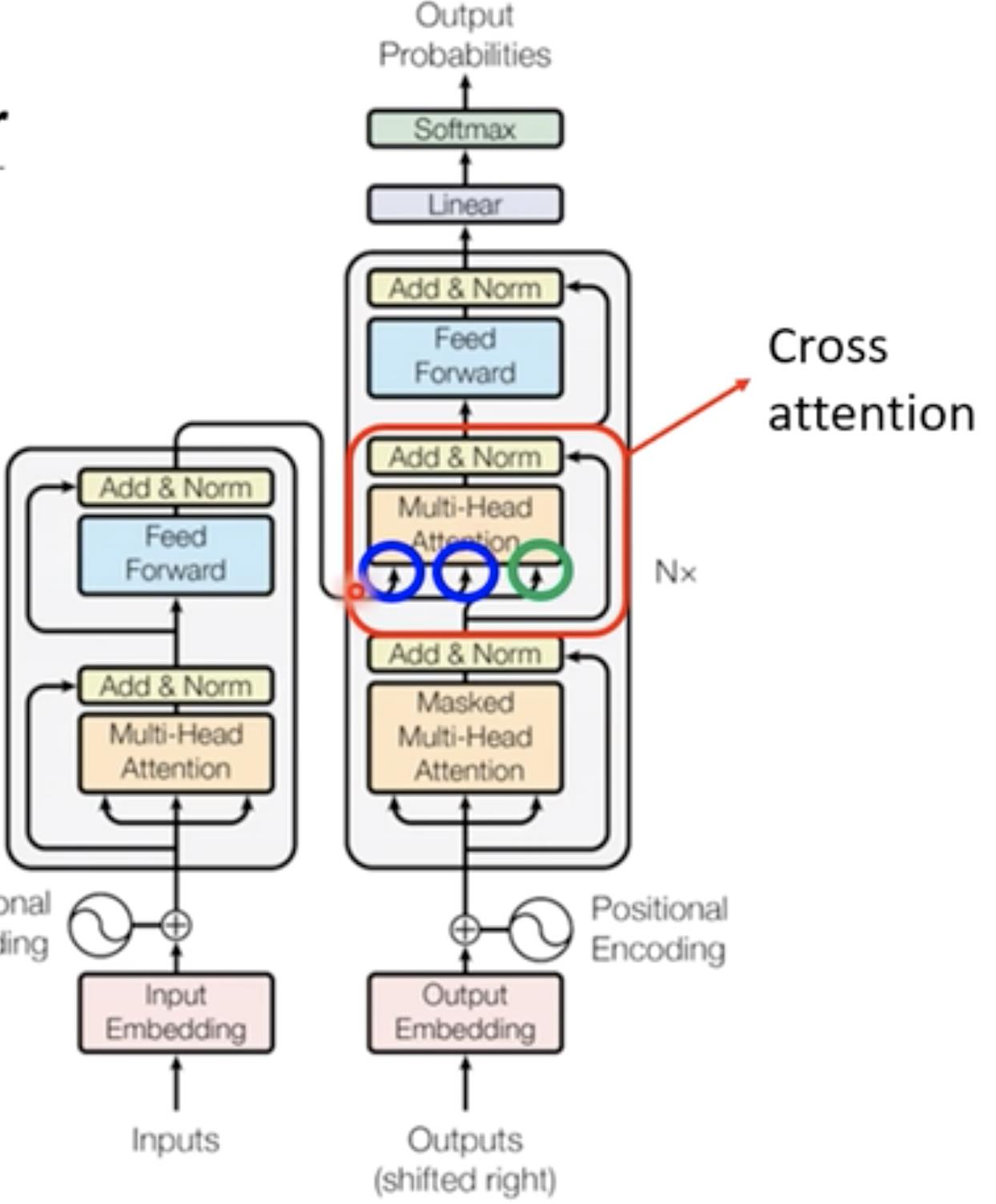
Decoder内部结构
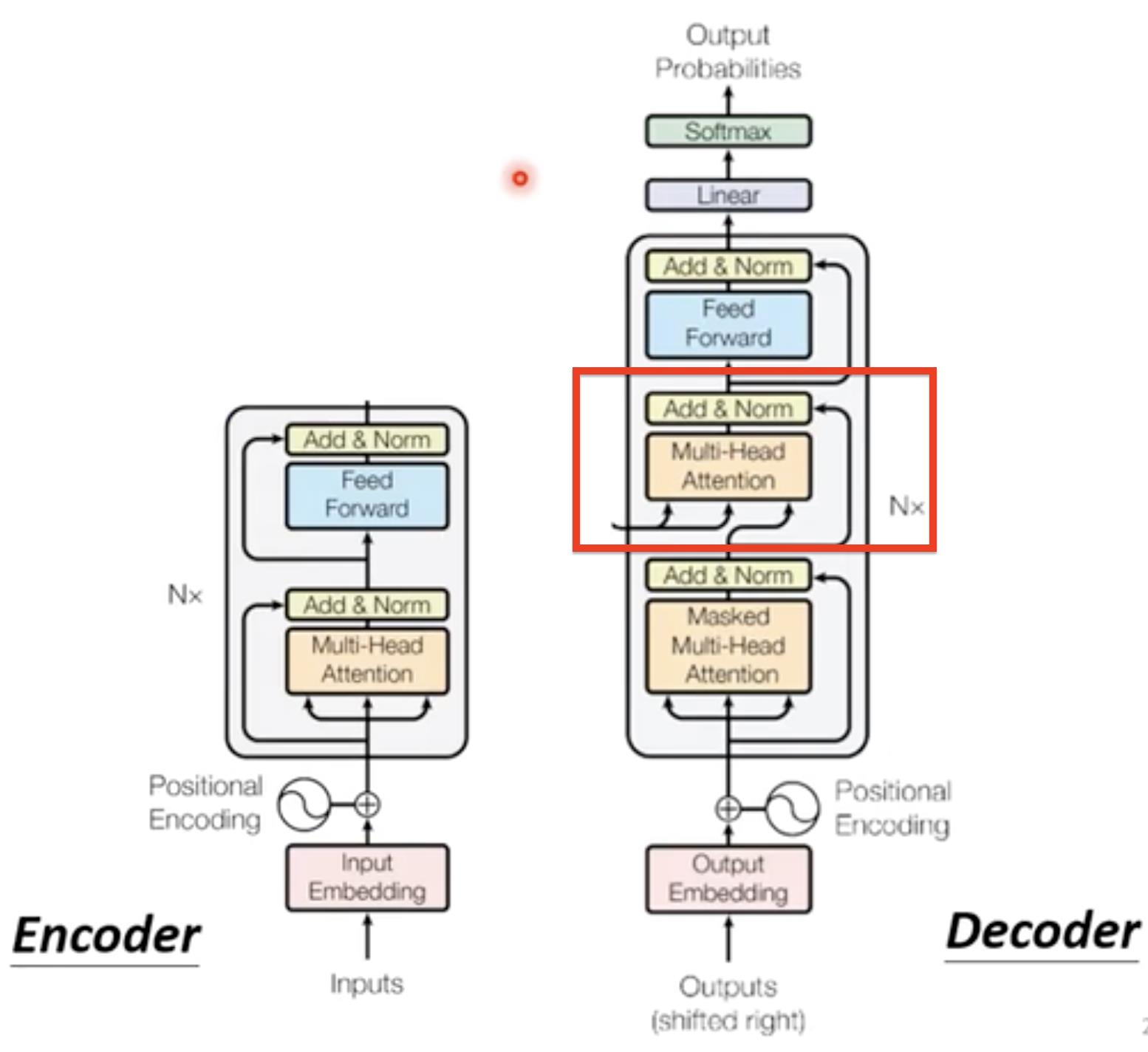
由下图我们可以看出,Decoder和Encoder的结构类似。不同的是红色部分,以及第一个Multi-head使用了Masked Multi-Head Attention
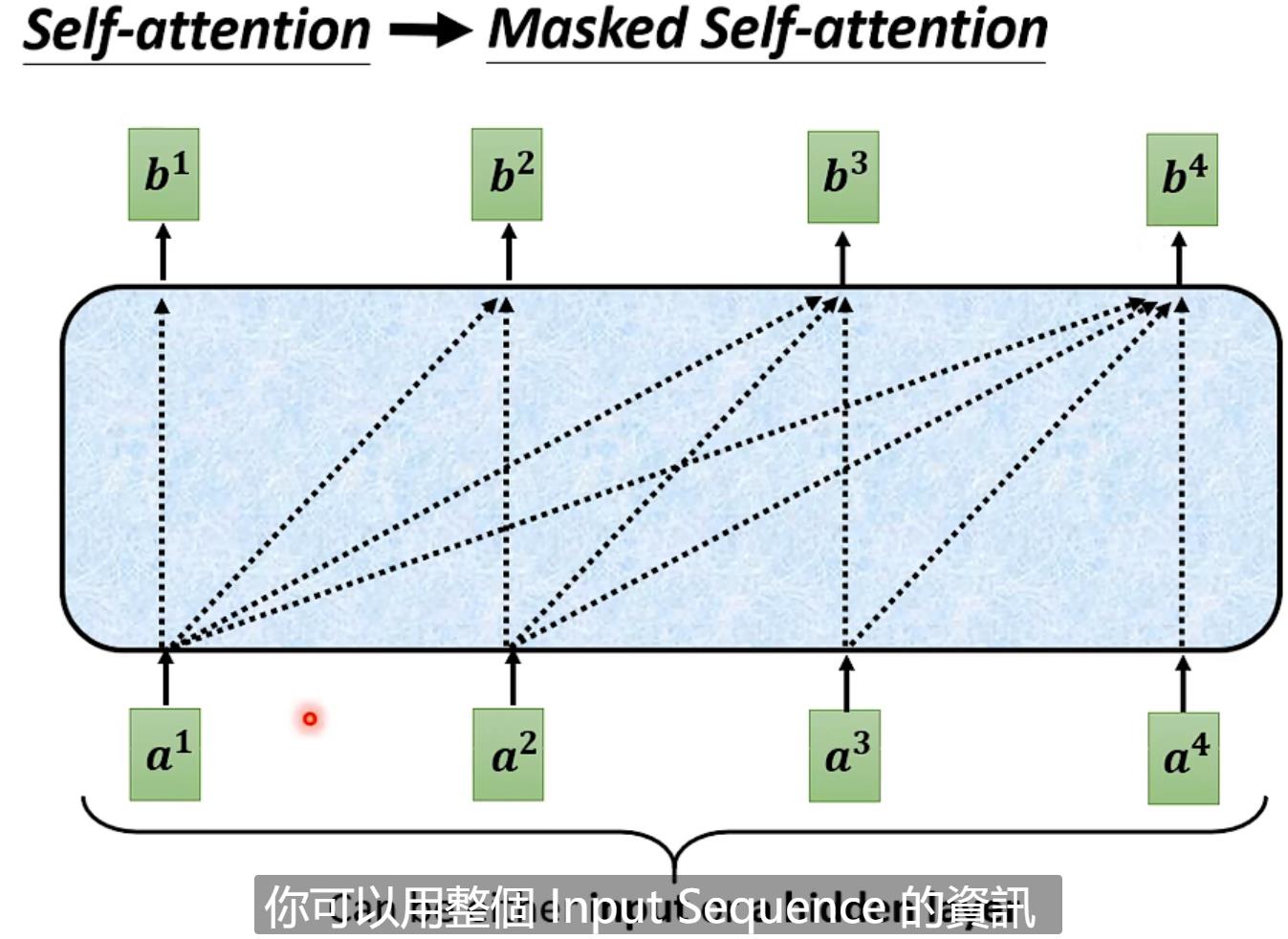
Masked Multi-Head Attention 就是b1,b2,b3,b4,每一个向量输出的时候只考虑左边输入的向量关联性得到的输出。(简单来说从左到右输入a1,a2,a3,a4,输出b1的时候只能考虑a1,输出b2的时候只能考虑a1,a2,输出b3只能考虑a1,a2,a3....)【之所以这样是因为在Decoder当中,输入是依次产生的,a1->a2->a3....】
有了Begin开始,那么我们亦要有停下来操作---->End
我们需要给输出向量中加一个end标识,它与其它的中文文字类似,这样当输入”机”“器”“学”“习“时候,经过Decoder输出向量,然后softmax处理后取最大值得到”end“
这里也简单的讲解了一下Non-autoregressive(NAT):
AT是一次产生一个字,而NAT是一次性产生一个句子
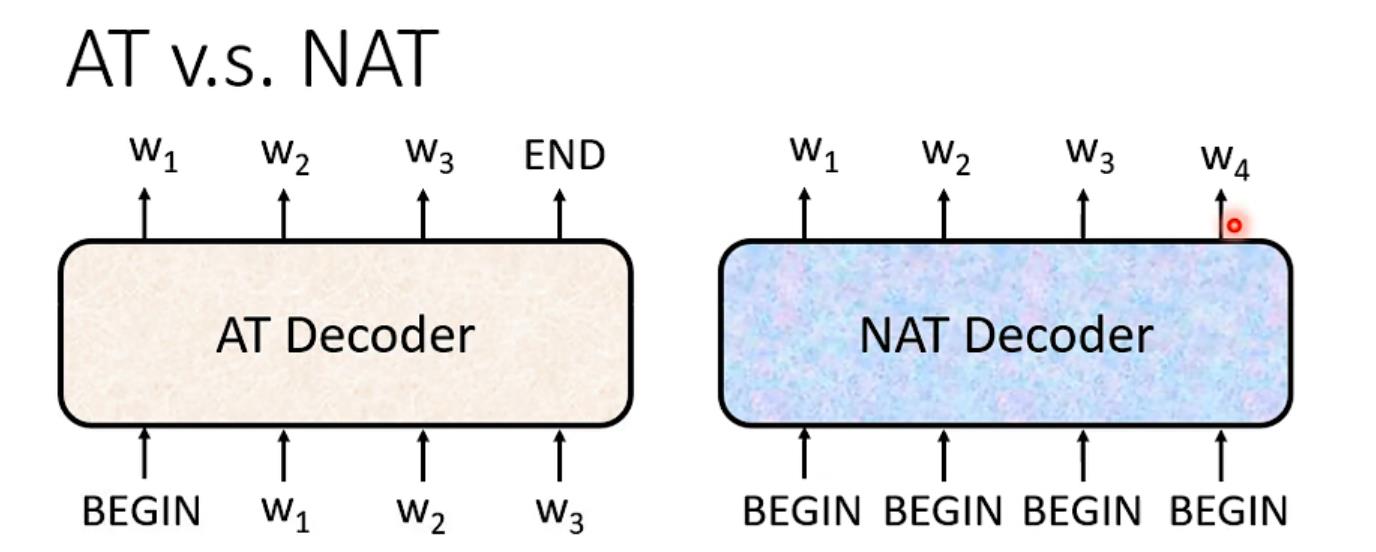
这里可能会有问题:
1.不知道输出长度,怎么确定BEGIN数量呢?
(1)另外使用一个classifier,输入Encoder的输出,输出一个数字即最后应当输出的长度
(2)设定一个输出上限,例如我最大输出长度为300,那么就给300个BEGIN,等到输出END的位置结束即可
2.有什么优点呢?
(1)平行化,速度快
(2)能够控制输出的长度
Encoder到Decoder的转换
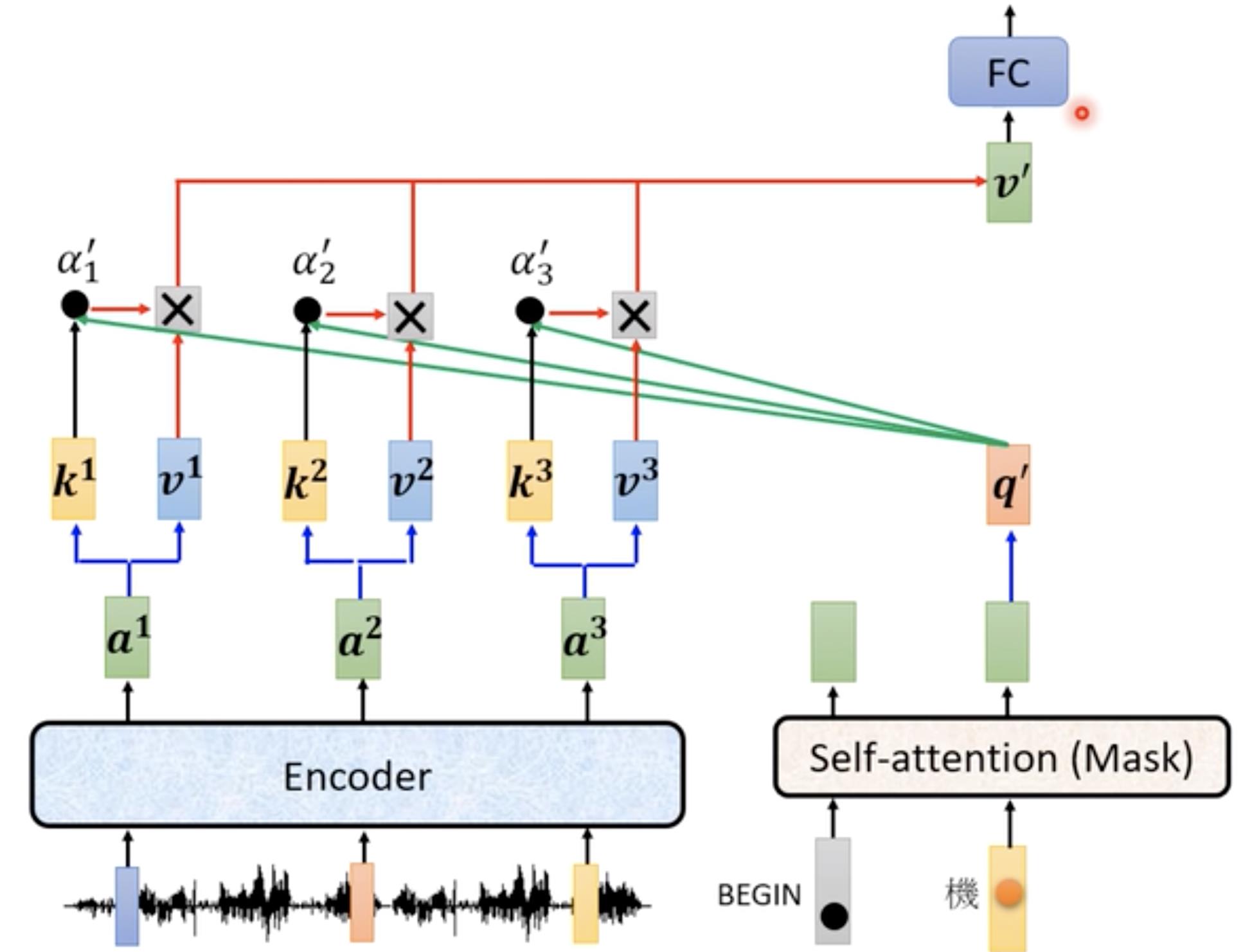
主要讲的就是Decoder与Encoder不同的地方(上面讲的时候画红框的位置)是一个Cross attention【连接Decoder和Encoder的桥梁】
Cross attention有三个输入,两个输入为Encoder的输出(蓝色部分)一个输入为Decoder一部分处理后的输出(绿色)
具体的操作:我们可以并行来看,最下面的大红色框,首先左边对所有的输入做Encoder操作,输出a1,a2,a3,右边对begin输入做self-attention操作得到输出向量b,然后看b与a1,a2,a3关联性也就是self-attention一系列操作。
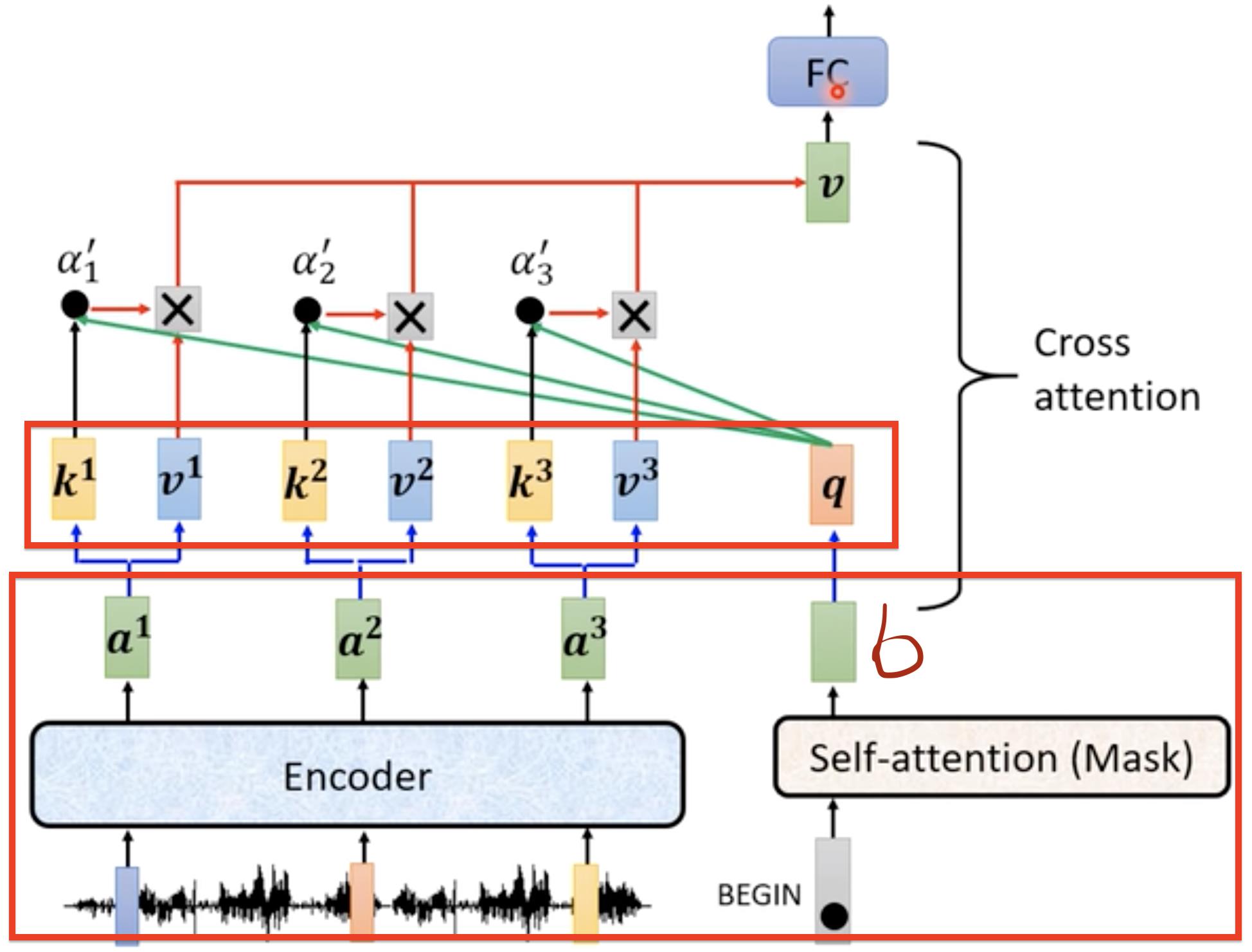
其他部分也是如此
Training
综述
以上讲的都是testing,接下来讲的是对模型的training
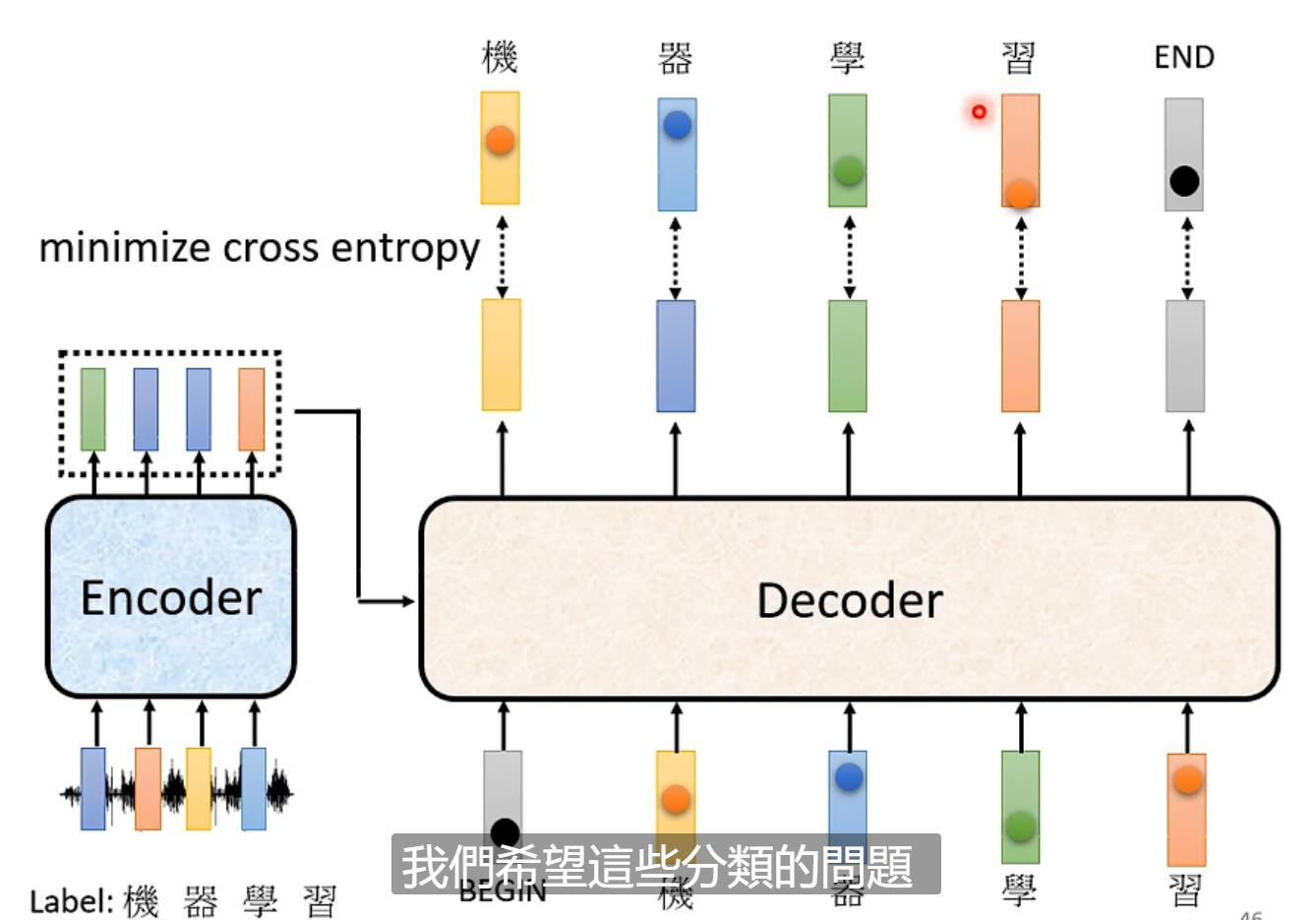
首先我们要收集材料,例如一段语音讯号,我们会给出其label(例如一段语言我们要求其识别出“机器学习”)我们每一次经过Decoder就相当于经过了一次分类问题,要求输出结果与我们要求的尽可能一样(那个字概率要大)
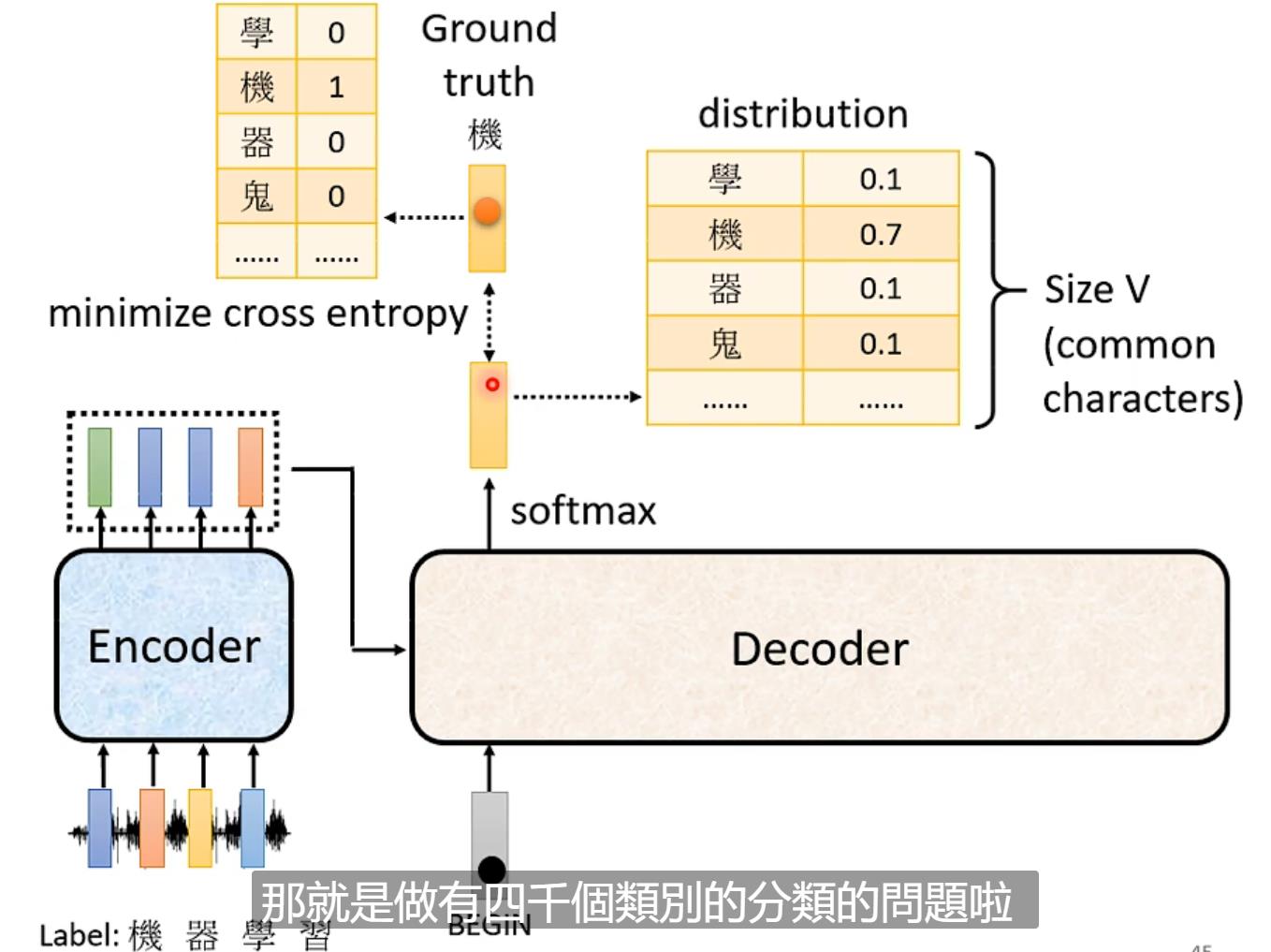
经过Decoder的每一次输出与label之前都会有一个cross entropy(交叉熵)loss,我们要求所有输出的损失和最小【笔记 | 什么是Cross Entropy - 知乎这篇文章讲解很简单】要注意的是假设我们要求识别四个字,但是结果要有五个结果的交叉熵(最后的end也要算入其中)
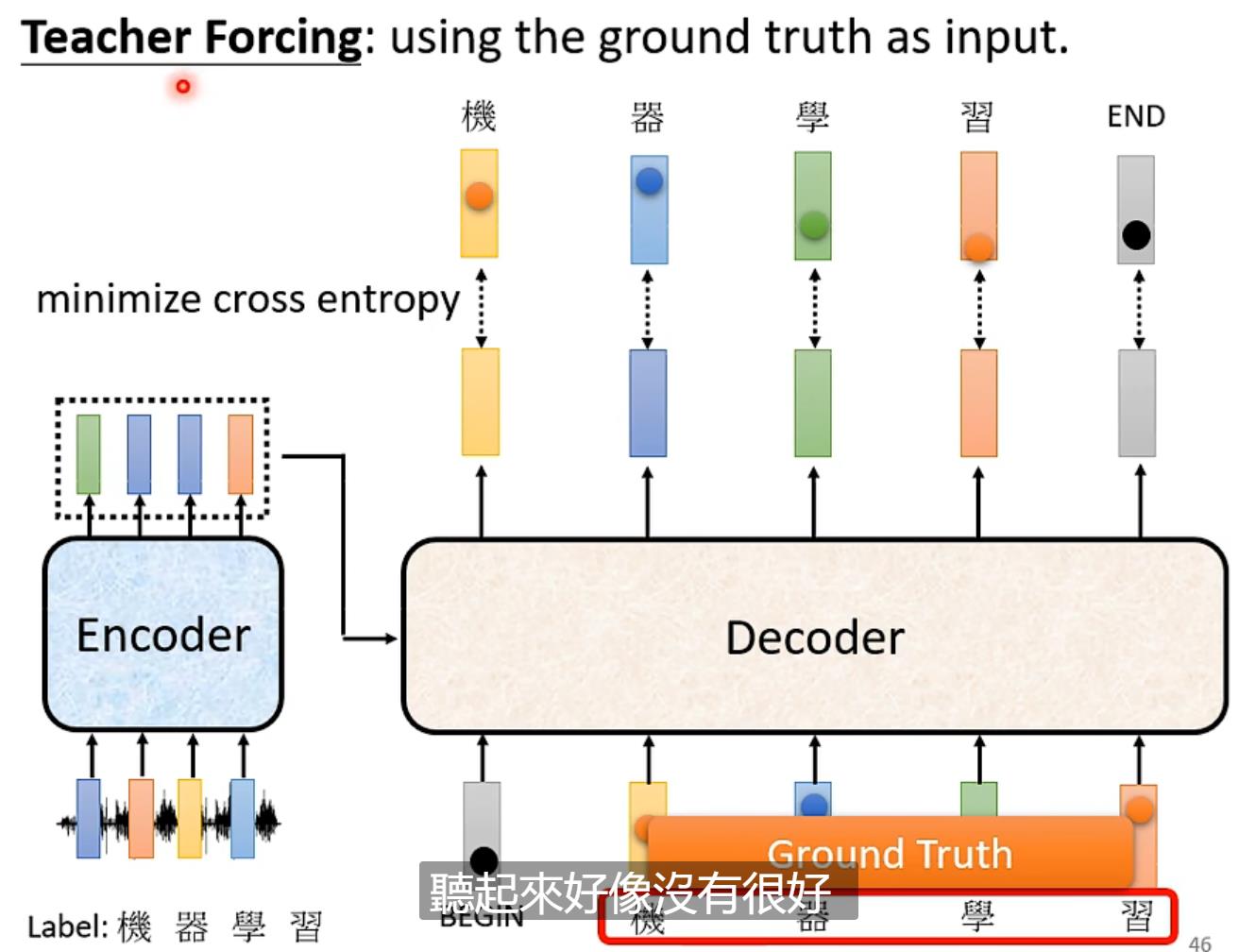
另外我们可以看到,每一次输出的结果的输入都有begin以及之前输出的结果,这个叫Teacher Forcing
训练的一些Tips(不局限于transformer,seq2seq均适用)【略】
1.copy mechanism:
上述的Encoder的输入都是从输出来的,那有没有一种可能是从输入的一部分copy而来呢?例如 又例如用很多篇文章train,然后让机器自动对一篇文章产生摘要
又例如用很多篇文章train,然后让机器自动对一篇文章产生摘要
(1)pointer network

2.Guided attention
强制使得机器把输入的所有内容...后面就没看了
文中部分内容参考了李宏毅Transformer_蒋思的博客-CSDN博客_李宏毅transformer当中的内容,本文章只限于自我记录笔记学习,如果有什么问题希望大家不吝赐教,谢谢。
以上是关于Transformer自学笔记(李宏毅课:Self-attention+Transformer)的主要内容,如果未能解决你的问题,请参考以下文章
学习笔记李宏毅2021春机器学习课程第5.1节:Transformer
可解释机器学习(Explainable/ Interpretable Machine Learning)的原理和应用(李宏毅视频课笔记)