Hadoop之WEBUi界面功能介绍及日志配置查看
Posted 月疯
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Hadoop之WEBUi界面功能介绍及日志配置查看相关的知识,希望对你有一定的参考价值。
启动Hadoop服务器
sbin/start-all.sh
浏览器访问
http:// hadoop-senior01.test.com:8088
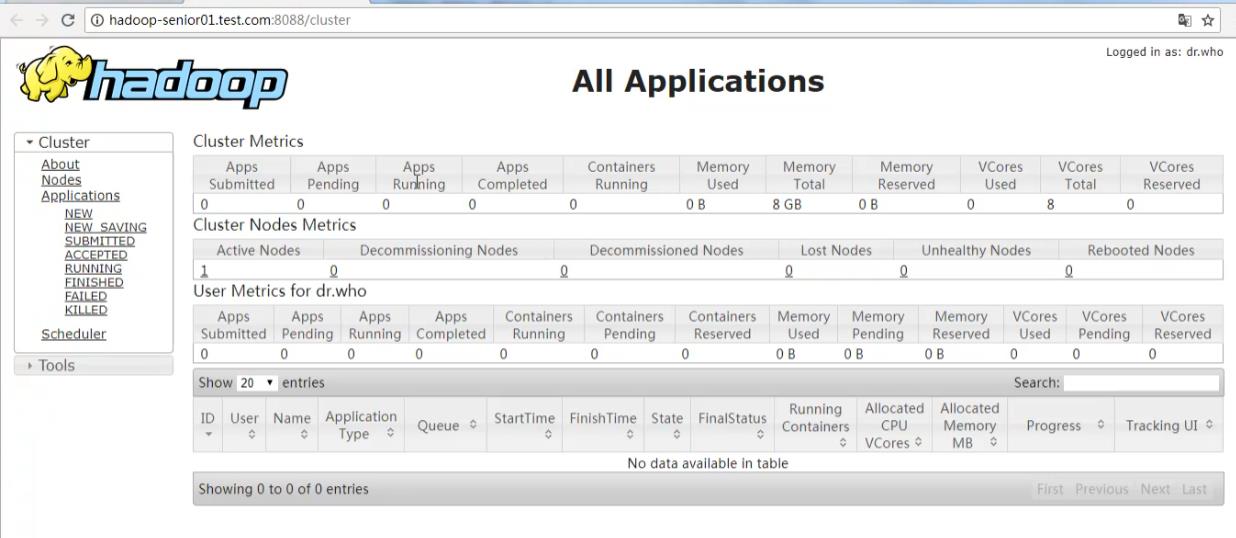
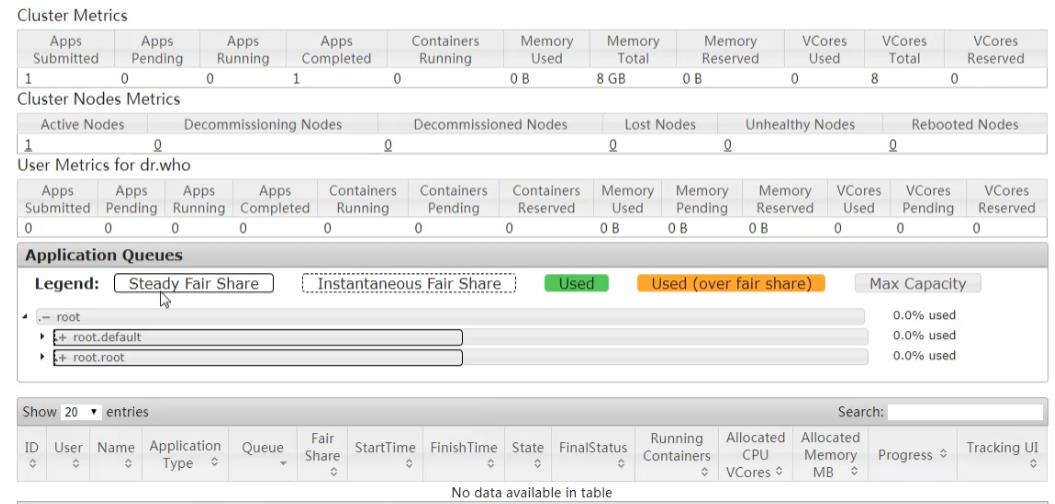
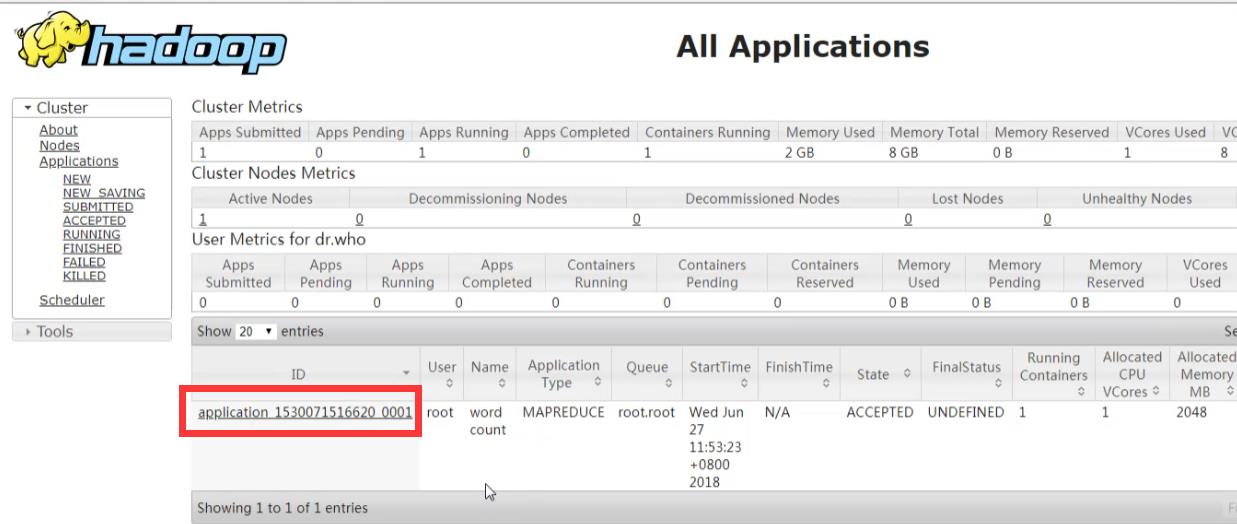
Cluster Metrics:集群指标
apps(提交、排队、运行、完成)
Containers:容器数
Memory:(使用的内存、总共内存、剩余内存)
VCores(CPU虚拟内核书):(使用的、总共的,剩余的)
Cluster Nodes Metrics:集群节点指标
activenode:正在运行的
decommissioning node:正在退出的
lost node:丢失的
unhealthy:不健康的
rebootedNode:重启的
User metrics for dr.who:通过浏览器访问的默认用户
apps:同上
containers:(运行的、排队的、剩余的)
memory同上
vcores同上
show entries:
id、user、name、application(应用)、queue(队列)、starttime开始时间、state状态、finalState结束状态、runningContainers(container进程)、memory内存、VCores(cpu)、
progress(进度)、TrackIngUI(ApplicationMaster正在跑的时候会被打开,查看应用的情况)
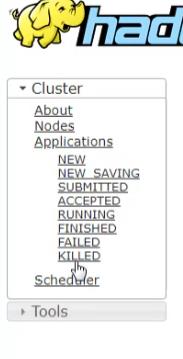
Application应用:
new新的
new Saving:新保存的
SUbmitted:提交的
Accepted:已经接受的
RUNNING:正在跑的作业
Finished:结束的作业
Failed:失败的作业
KIlled:杀死的作业
Scheduller:资源调度器
聚合日志:
先启动hadoop:
sbin/start-alll.sh
一个mapreduce如何放到yarn上进行执行
WordCound程序
单机访问:
bin/hadoop jar share/hadoop/mapreduce/hadoop-mapreduce-examples-2.x.x.jar wordcount <input> <input>
服务器访问本地
bin/hadoop jar share/hadoop/mapreduce/hadoop-mapreduce-examples-2.x.x.jar wordcount file:<input> file:<input>
WEB UI监控
节点状况
MapreduceApplication状况
Container分配状况
a、含义:
分布式计算作业放到NodeManager运行,日志信息放到NodeManager本地目录:
yarn.nodemanager.log-dirs:$yarn.log.dir/userlogs
通过配置将本地日志放到HDFS服务器上,即集合日志的概念
聚合日志配置yarn-site.xml:
#启用日志聚合功能
<property>
<name>yarn.log-aggregation-enable</name>
<value>true</value>
</property>
#存放多长时间
<property>
<name>yarn.log-aggregation.retain-seconds</name>
<value>3600</value>
</property>
yarn.log-aggregation-enable
是否启用日志聚合功能,日志聚合开启后保存到HDFS上
yarn.log-aggregation.retain-seconds
聚合后的日志在HDFS上保存多长时间,单位为s
yarn.log-aggregation.retain-check-interval-seconds
删除任务在HDFS上执行的间隔,执行时候将满足条件的日志删除(超过保存时间的日志),
如果是0或者负数,则为参数2设置值的1/10
yarn.nodemanager.log.retain-seconds
当不启用日志聚合此参数生效,日志文件保存本地的时间,单位为s
yarn.nodemanager.remote-app-log-dir
当应用程序运行结束后,日志被转移到的HDFS目录(启用日志聚集功能时有效),修改为保存的日志文件夹
yarn.nodemanager.remote-app-log-dir-suffix
远程日志目录子目录名称(启用日志聚集功能时有效)
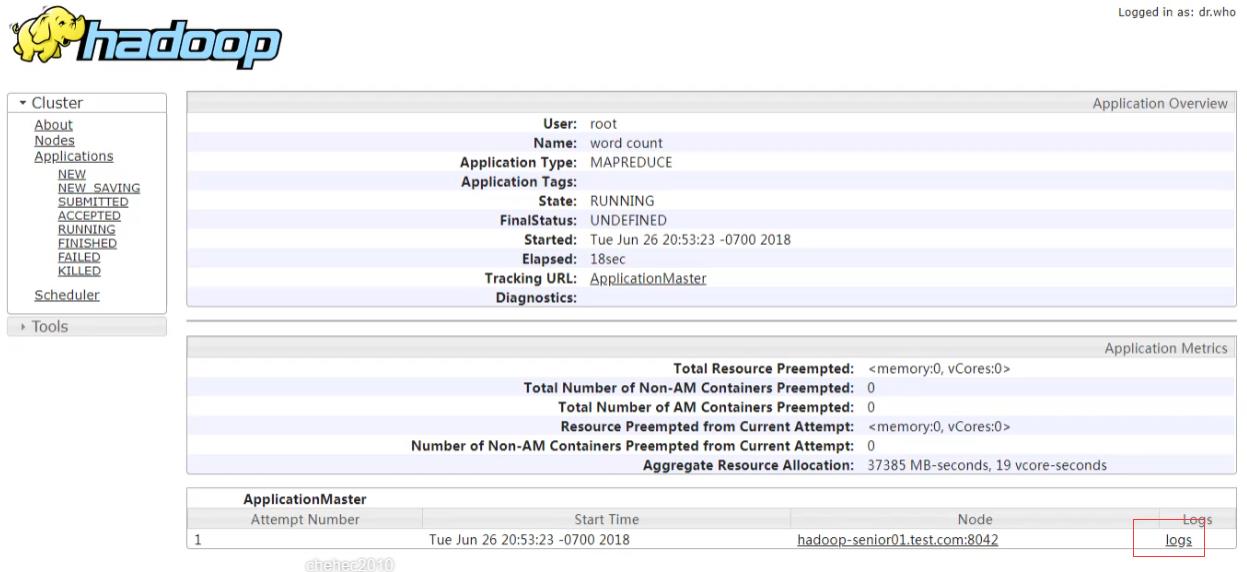
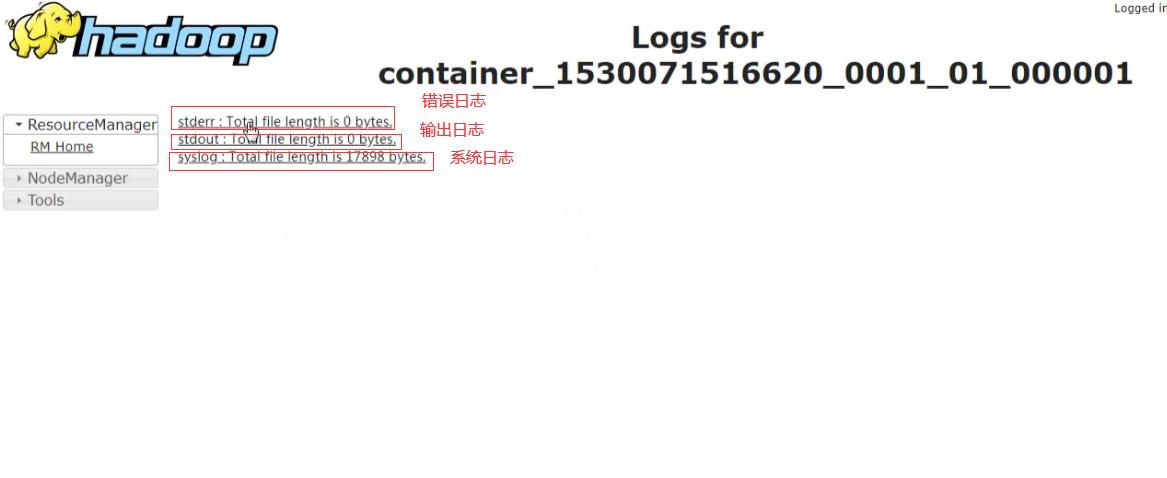
启动历史服务器:
mapreduce.jobhitory.address
jobhistory的rpc访问地址
mapreduce.jobhistory.webapp.address
jobhistory的http访问地址
启动:sbin/mr-jobhistory-daemon.sh start historyserver
WEB UI
http:// <主机名>:19888
停止:sbin/mr-jobhistory-daemon.sh stop historyserver

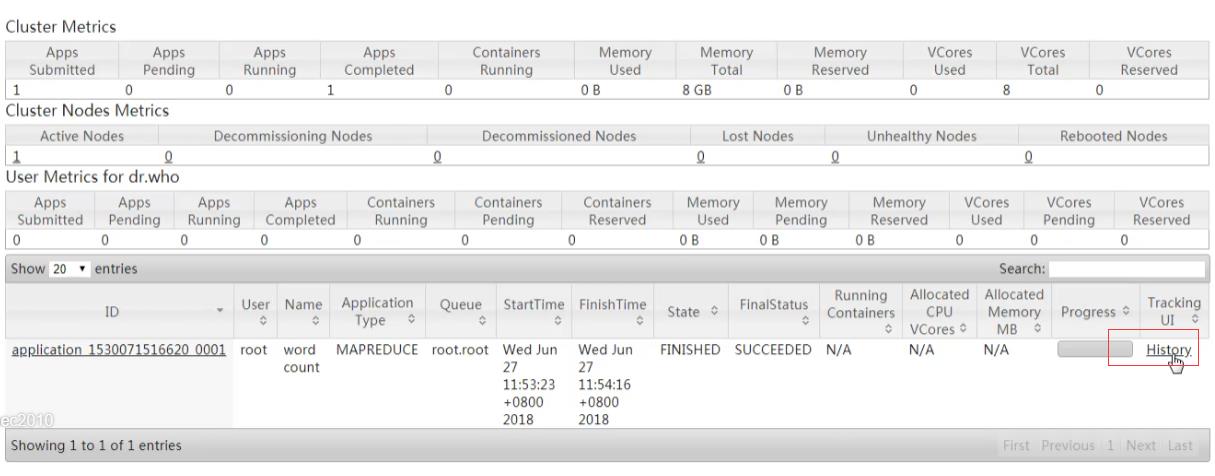
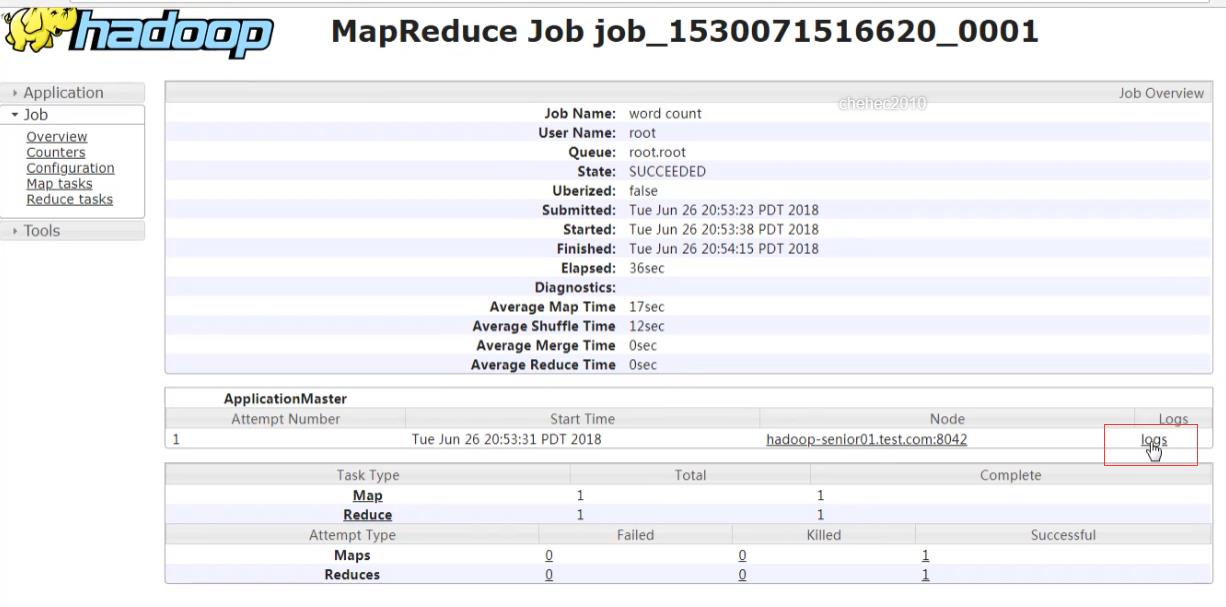
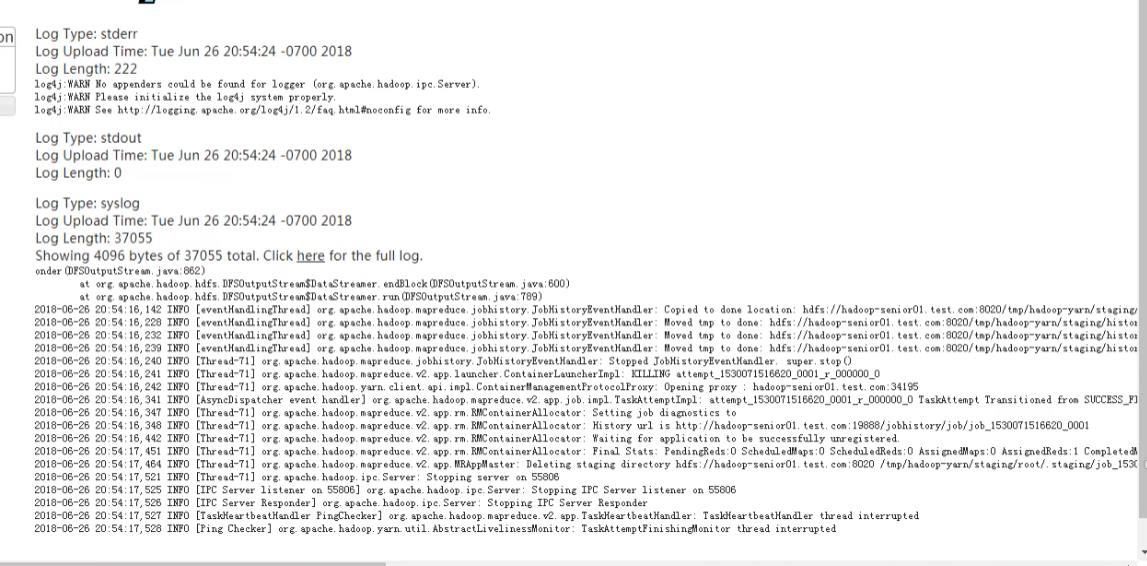
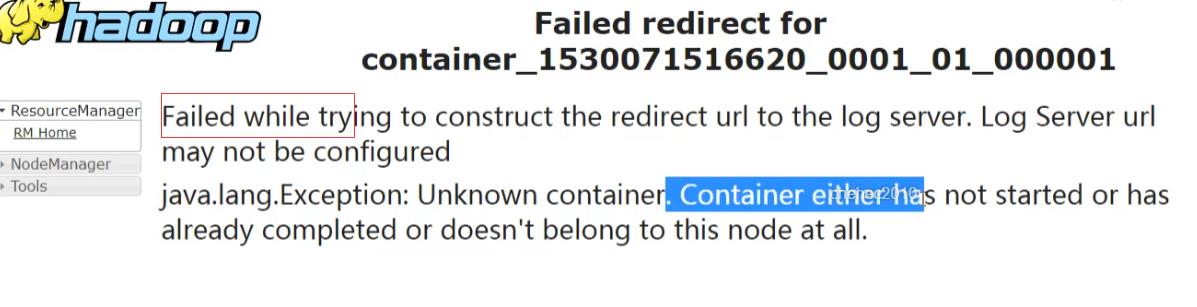
作业执行完成之后,无法访问container,无法访问
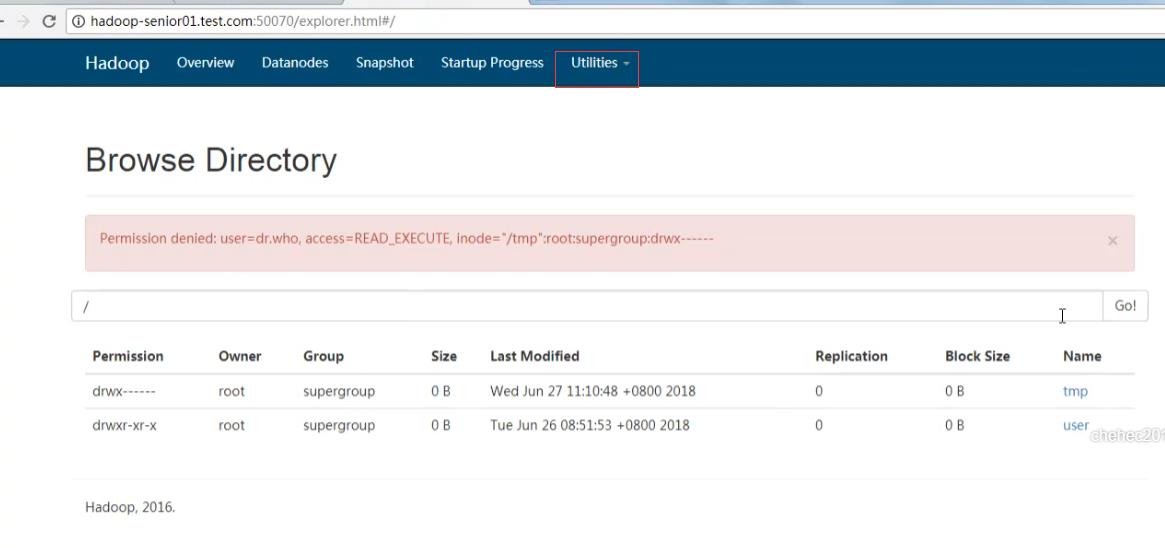
也可以通过50070查看日志:
以上是关于Hadoop之WEBUi界面功能介绍及日志配置查看的主要内容,如果未能解决你的问题,请参考以下文章