从零开始的神经网络构建历程
Posted Donald_Shallwing
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了从零开始的神经网络构建历程相关的知识,希望对你有一定的参考价值。
这是构建神经网络历程系列的第一篇博文。本篇博文主要讲述Python中torch库在神经网络构建中的相关用法。
torch库成员与神经网络中相关模块的对应关系
由于逻辑回归以及其他机器学习算法解决不了非线性分类/回归问题,所以深度学习理论诞生了,上世纪60年代由此产生了神经网络模型。最早的一大批神经网络都是全连接的前馈神经网络,其特点在于当前层的神经元和前后两层神经元之间是处处相连的,每一层参数的个数是两层神经元数目之间的乘积。到了世纪90年代末,卷积神经网络开始产生,并于1998年产生了第一个真正用于商业的神经网络模型——LeNet5,此神经网络模型最初是用于支票上手写数字的识别,LeNet5是经典的卷积神经网络模型,此网络本人会在此系列后面的博文中复现。
先看一下全连接前馈神经模型图:
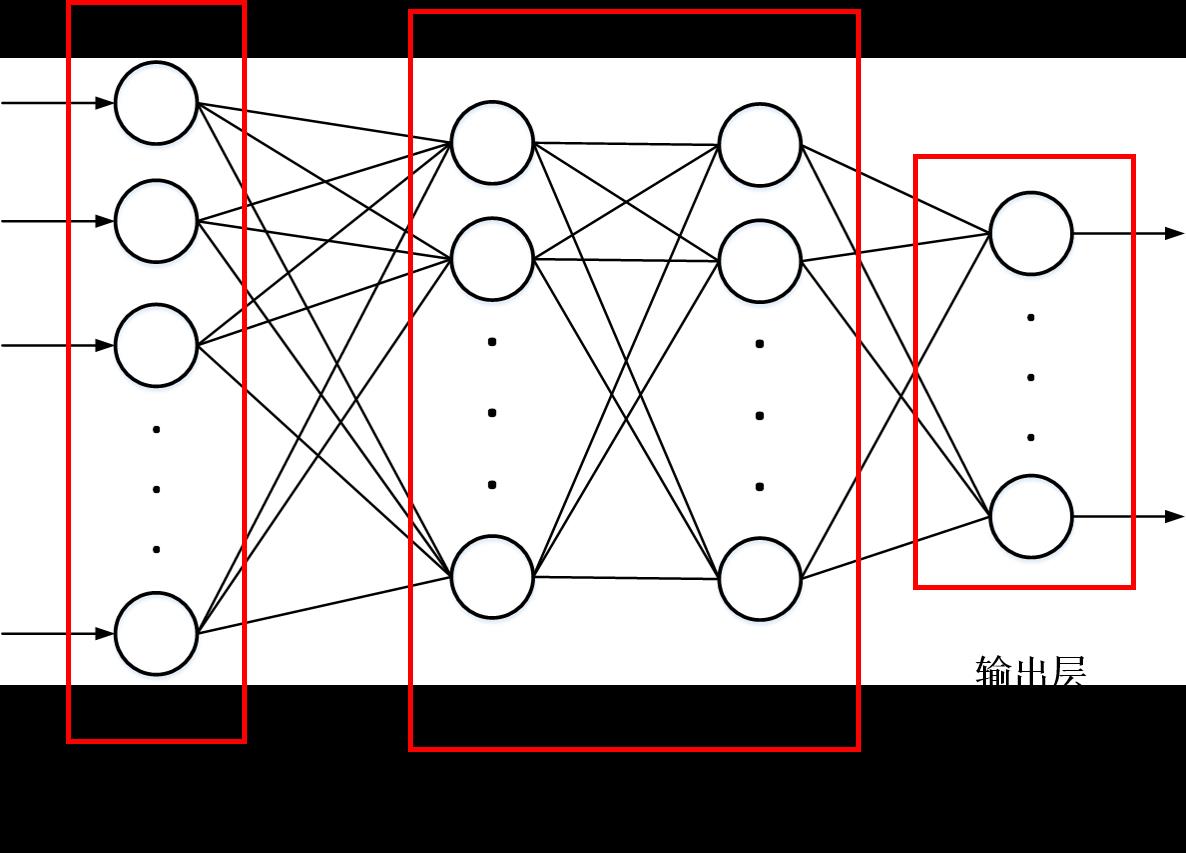
其中每一层神经元之间还包括激活函数,在最终的输出层还有用于概率归一化的softmax函数。网络最终的输出是一个列向量yhat(prediction of y),此向量便和标准输出值之间形成损失函数Loss。BP算法便是通过最小化Loss来达到每层神经元之间参数更新的目的。

由BP算法我们就可以构建出前馈型神经网络的数学模型,网络的输入是一个行向量或者列向量,层与层之间存在权值矩阵W与偏置向量b,W的维度同层层之间神经元的个数有关,b的维度依赖于W与当前层输入的矩阵乘积XW,XW+b运算得到的是一个向量,此向量经过激活函数后成为了下一层的输出…
以上便是前馈神经网络模型的基本介绍。不难发现,一个全连接前馈神经网络就包含三个部分:权值矩阵和偏置、激活函数、softmax。因此此三种模块与torch.nn中一下成员对应:
torch.nn.Linear(self, in_features, out_features, bias=True) ##对应于层与层之间的权重W与偏置b
torch.nn.Sigmoid()
torch.nn.ReLU() ##这四种都是神经网络中常用的激活函数
torch.nn.Tanh()
torch.nn.PReLU()
torch.nn.functional.softmax(input, dim=None, _stacklevel=3, dtype=None) ##softmax函数
nn是Neural Network的简写,也就是神经网络,一般来说,我们都是通过定义Python类的方式搭建神经网络模型。此时不得不提到一个类——torch.nn.Module。以下是对于module.py文件中类Module的部分英文介绍:
class Module(object):
r"""Base class for all neural network modules.
Your models should also subclass this class.
Modules can also contain other Modules, allowing to nest them in
a tree structure. You can assign the submodules as regular attributes::
import torch.nn as nn
import torch.nn.functional as F
class Model(nn.Module):
def __init__(self):
super(Model, self).__init__()
self.layer1 = nn.Linear(20, 10)
self.layer2 = nn.Linear(10, 5)
def forward(self, x):
x = F.relu(self.layer1(x))
return F.relu(self.layer2(x))
这段英文介绍了一个构建神经网络的例子,其构建的神经网络结构是这样的:
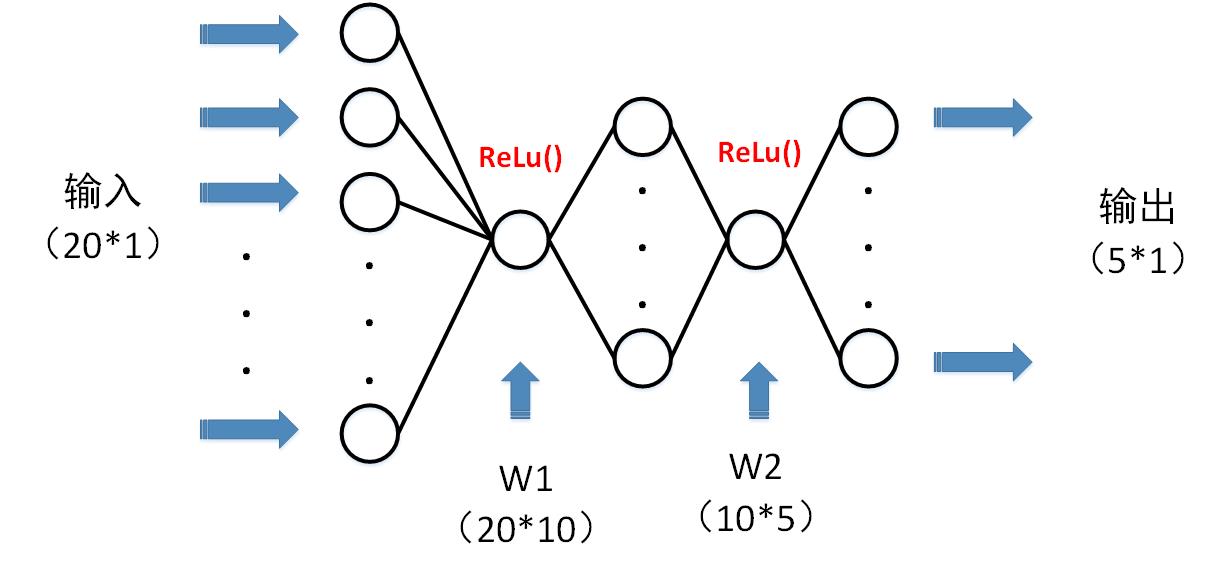
让我们来单独看看这一段代码:
class Model(nn.Module):
def __init__(self):
super(Model, self).__init__()
self.layer1 = nn.Linear(20, 10)
self.layer2 = nn.Linear(10, 5)
def forward(self, x):
x = F.relu(self.layer1(x))
return F.relu(self.layer2(x))
这段代码定义了一个类Model,该类继承于父类nn.Module。类中的方法成员forward也是父类Module中的成员,在子类Model中进行了重写,forward表示的就是这个网络前向传播的过程,对应于BP算法中的前向传播,当前项传播之后就能产生损失函数Loss。(20,10)与(10,5)表示的就是这两层神经元之间的权重大小。forward方法中的self.layer1(x)就相当于前向传播中的运算:

x就相当于式子中的hn,b随着Model类中Linear的定义会自动生成。
以上的代码是用torch构建神经网络的标准代码,几乎所有的神经网络的代码都是通过这个格式衍生而来的。
问题
前面我们讲了torch中如何通过代码构建神经网络的,现在思考一个问题,如果我们要用torch实现下面的神经网络,代码该怎么写?
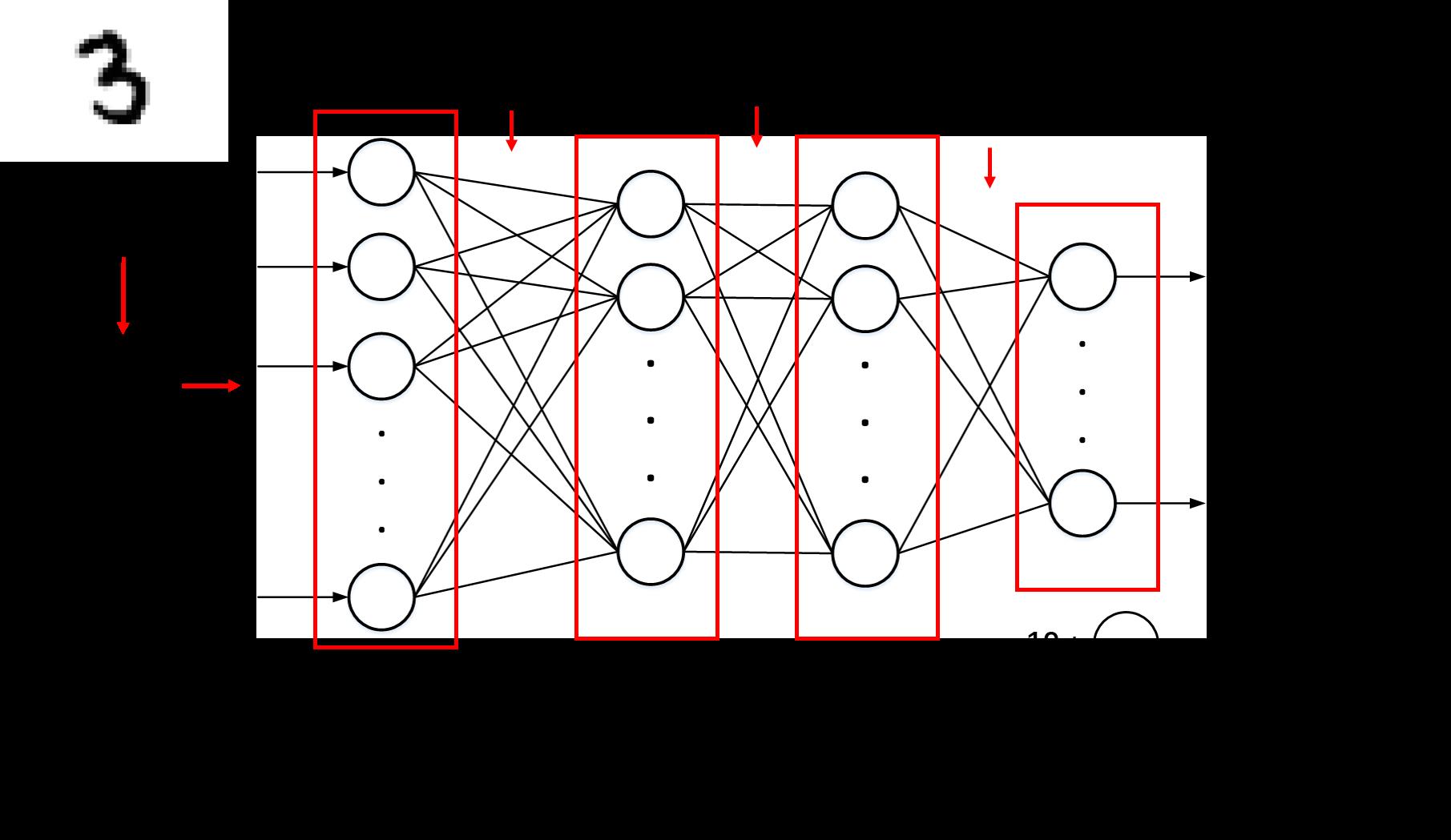
这是一个基于全连接前馈神经网络用于数字识别的例子,各位读者可以先自己思考思考,本系列的下一篇博文将来复现此神经网络。
以上是关于从零开始的神经网络构建历程的主要内容,如果未能解决你的问题,请参考以下文章
不怕学不会 | 使用TensorFlow从零开始构建卷积神经网络