大数据场景下的消息队列:Kafka3.0快速入门
Posted Java鱼仔
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了大数据场景下的消息队列:Kafka3.0快速入门相关的知识,希望对你有一定的参考价值。
(一)什么是Kafka
Kafka是一个分布式的基于发布/订阅模式的消息队列,同时它又是一个分布式的事件流平台。既可作为消息队列,又可作为数据管道、流分析的应用。目前Kafka的最大应用还是消息队列。
市面上主流的消息队列有RabbitMQ,ActiveMQ、Kafka等等,其中RabbitMQ,ActiveMQ这些主要是Java应用中的队列,而Kafka主要在大数据场景下使用。
消息队列主要应用场景有如下几种:削峰、限流、解耦、异步通信等。
(二)消息队列的实现模式
消息队列的实现主要有两种模式,一种叫点对点模式:生产者将消息发送到队列中后,消费者从队列中取出并且消费消息。这种模式保证一个消息只会被一个消费者消费一次,不可以重复消息。
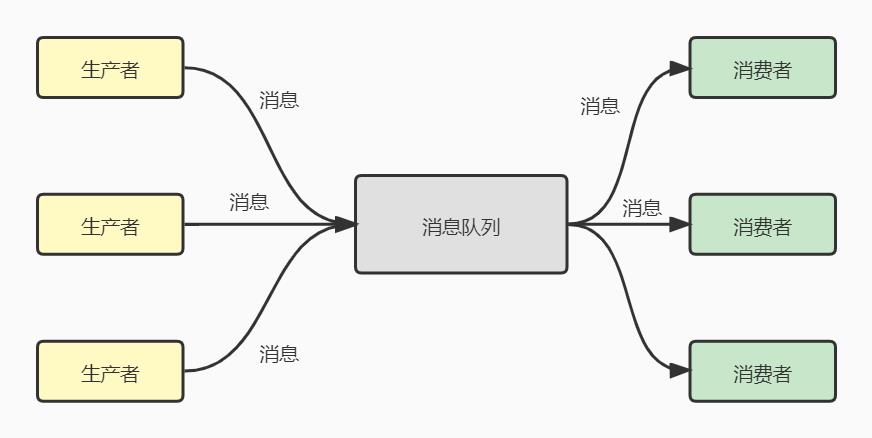
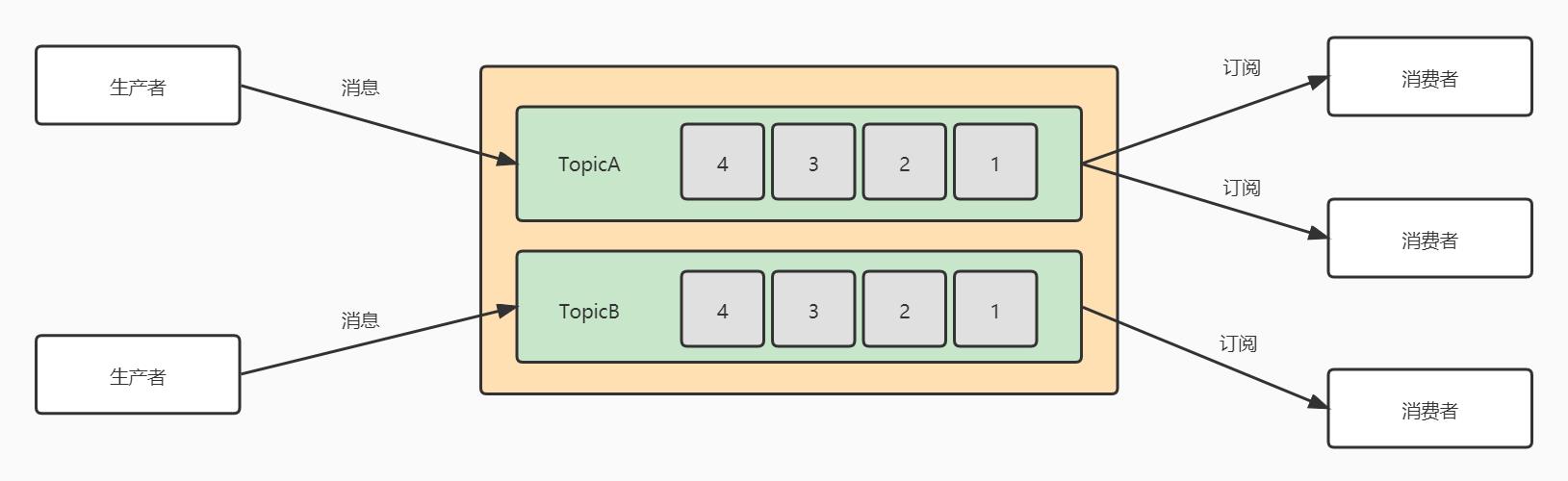
第二种是发布/订阅模式,也就是Kafka所使用的模式。在发布/订阅模式中,队列中存在多个topic主题,生产者将消息发送到队列的topic中,消费者可以订阅某个topic消费数据。并且消费者消费数据之后,不会删除数据。
(三)Kafka的架构设计
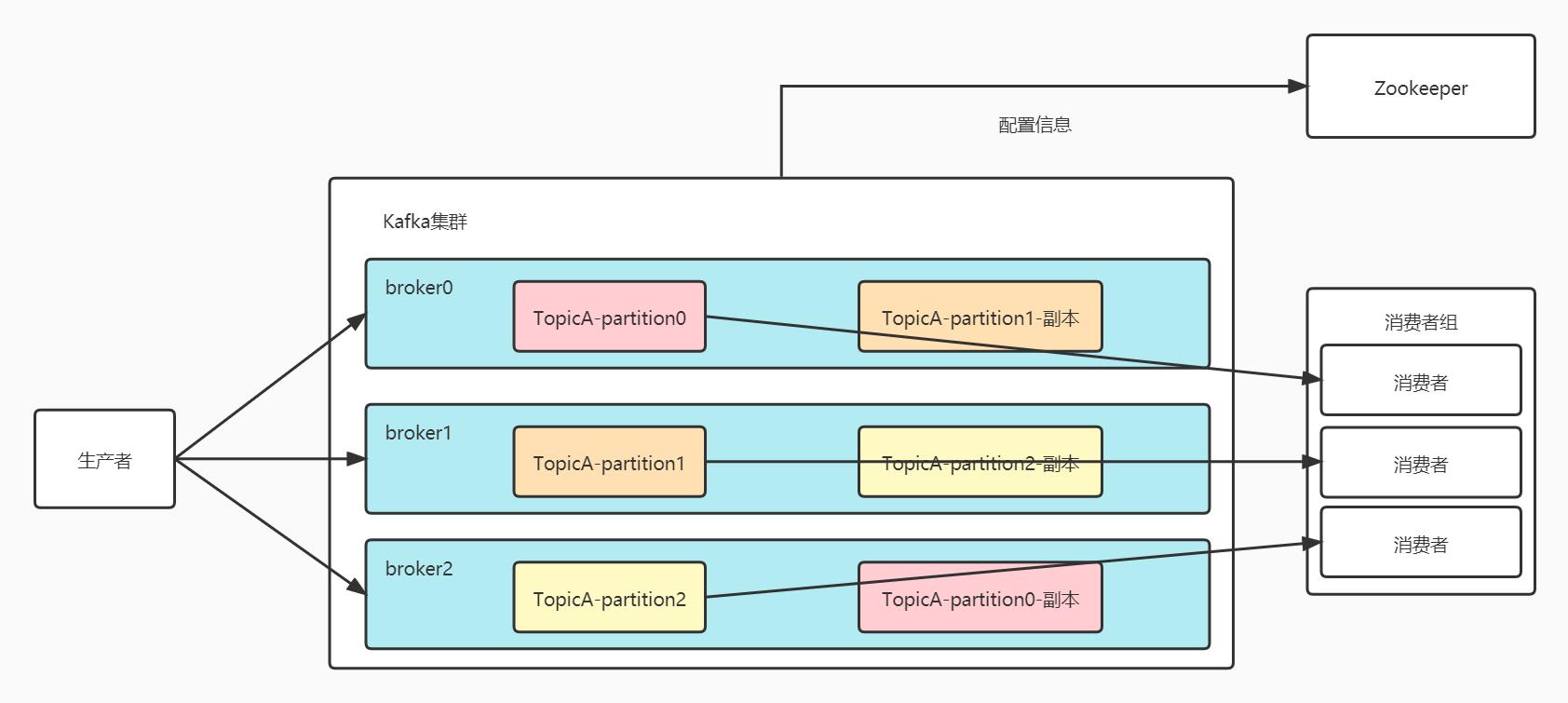
前面讲到Kafka主要用于大数据环境,那避免不了的要接触海量的数据。当遇到TB级别的数据时,目前最优的设计架构是分而治之,也就是将数据分散到不同的机器上去,Kafka就应用了这样的设计方式。
Kafka集群会将一个Topic分为多个partition(分区),每个Topic还可以指定副本的数量,并分配到不同的机器中。同时为了提高消费者的消费能力,运用消费组的方式,使得消费组中的消费者并行消费。为了提高可靠性,采用副本的方式保证可用性。通过Zookeeper等方式记录配置信息。
(四)Kafka的快速安装
kafka的配置信息默认存放在zookeeper中,因此需要提前将zookeeper安装完成并启动,不然kafka会报连接失败。
首先是Kafka的下载,我这里选择的是kafka3.0,对应的安装包名为:kafka_2.13-3.0.0.tgz,下载地址如下:
https://downloads.apache.org/kafka/3.0.0/
下载完成后将文件上传至linux服务器,接下来就可以开始安装了
tar -xzf kafka_2.13-3.0.0.tgz
mv kafka_2.13-3.0.0 kafka
解压完成后修改一下相应的配置文件,首先需要对kafka服务的配置进行修改,进入kafka/config,修改server.properties,主要修改一下数据的存放地址,默认log.dirs的地址是/tmp下的路径,修改为自定义的目录下、另外将zookeeper的地址改成自己的地址。
log.dirs=/usr/local/kafka/datas
zookeeper.connect=localhost:2181
接着在kafka目录下启动kafka:
./bin/kafka-server-start.sh -daemon ./config/server.properties
在kafka/logs目录下查看server.log,如果提示started,则表示启动成功,不然就根据错误的原因重新修改配置或命令。

(五)Kafka的命令行操作
Kafka在结构上可以分为生产者、消费者和服务本身,这一节主要介绍Kafka自身的kafka-topics.sh一些命令行操作,常用的命令行参数通过表格的形式给出
| 参数 | 描述 |
|---|---|
| –boostrap-server | 连接Kafka |
| –topic | 操作的topic名称 |
| –create | 创建topic |
| –delete | 删除topic |
| –alter | 修改topic |
| –list | 查看所有主题 |
| –describe | 查看主题详细描述 |
| –partitions | 设置分区的数量 |
| –replication-factor | 设置分区的副本数 |
5.1 创建Topic
使用下面的命令可以创建一个名为testTopic,分区数为1,副本数为1的Topic
./bin/kafka-topics.sh --bootstrap-server 127.0.0.1:9092 --topic testTopic --create --partitions 1 --replication-factor 1
5.2 查看Topic
–list 可以查看所有的Topic,–describe 可以查看某个topic的详细信息:
./bin/kafka-topics.sh --bootstrap-server 127.0.0.1:9092 --list
./bin/kafka-topics.sh --bootstrap-server 127.0.0.1:9092 --topic testTopic --describe
5.3 删除Topic
删除的操作和上面的写法一致:
./bin/kafka-topics.sh --bootstrap-server 127.0.0.1:9092 --topic testTopic --delete
5.4 简单的消息生产与消费
创建完Topic之后可以简单地对消息进行生产和消费,创建完一个Topic之后,通过生产者的命令行发送一条消息:
./bin/kafka-console-producer.sh --bootstrap-server 127.0.0.1:9092 --topic testTopic
接着可以输入一些消息,比如输入hello world
在另一个会话中使用消费者的命令行消费消息:
./bin/kafka-console-consumer.sh --bootstrap-server 127.0.0.1:9092 --topic testTopic --from-beginning
(六)总结
本文主要介绍了Kafka是什么、Kafka的架构、Kafka的安装和基本使用。接下来会有更多有关kafka的文章,我是鱼仔,我们下期再见
以上是关于大数据场景下的消息队列:Kafka3.0快速入门的主要内容,如果未能解决你的问题,请参考以下文章
大数据技术之KafkaKafka概述Kafka快速入门Kafka架构深入
大数据技术之KafkaKafka概述Kafka快速入门Kafka架构深入
大数据技术之KafkaKafka概述Kafka快速入门Kafka架构深入