云原生 etcd 系列-7|深入剖析数据多版本 MVCC 机制
Posted 琦彦
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了云原生 etcd 系列-7|深入剖析数据多版本 MVCC 机制相关的知识,希望对你有一定的参考价值。
云原生 etcd 系列-7|深入剖析数据多版本 MVCC 机制
坚持思考,就会很酷

你以为删掉就没事了?
有些童鞋以前还真是做过些傻事,以为删掉一些东西,覆盖一些东西就能掩盖某一些"不可告人"的秘密。
来看看 etcd 的例子:
./etcdctl put 张三 是个憨憨
哎呀,这可不大对,怎么能说这么羞耻的话呢!黑历史赶紧删掉。
./etcdctl del 张三
再来写过一个正常的:
./etcdctl put 张三 是个大聪明
这就对了嘛,数据我已经删了,也更新了新的数据。这个黑历史已经永远被埋藏了!
万万没想到,直到某一天还是有人把这些黑历史全部捞了出来:
./etcdctl watch 张三 --rev=1
PUT
张三
是个憨憨
DELETE
张三
PUT
张三
是个大聪明
愣主,半天,我的老天啊。。。。。。这是啥呀?太羞耻了吧。
旁白:这就是 MVCC(数据多版本)机制。
存储系统核心功能
存储系统核心功能其实非常简单,聚焦三个操作:读写删。用户把数据写进来好好保存,读的时候安全返回,删的时候释放空间,以便重复利用。
etcd 虽然有很多丰富的功能,也有它特殊的定位,但本质上也是一个存储系统。不过 etcd 有两个特色的功能:watch 机制和 MVCC 机制( 数据多版本 )。
提前思考两个小问题:
- 在用户删除 key 的时候却没有释放空间,为什么呢?此时不释放,还待何时?
- watch 机制监听一个 key 的所有变化,怎么才能做到可靠?
MVCC 是啥东西?这就先聊聊数据多版本的了。
什么是数据多版本?
大白话就是同一份数据有多个版本。更准确的来讲是同一个 key 的多个版本的数据。举个例子,你反复的三次写入一个 key的 value 值:
- 第一次写入 world-1 ;
- 第二次写入 world-2 ;
- 第三次写入 world-3 ;
常规存储来讲是最新的值不断覆盖以前的。但在数据多版本的系统中,每一次写入都写了新的位置,旧的不会动,每一次写入都对应一个版本。所以这三次的数据,用户其实都能读到。
key => v1
=> v2
=> v3
数据多版本本质上就是把同一个 key 的历史变化都留下来了。数据多版本这个其实就是 watch 机制可靠的根源,因为来时的路都在呀。
什么是 MVCC ?
讲了数据多版本,再来看看 MVCC 是个啥?
MVCC 是 Multiversion Concurrency Control 的英文缩写,也叫多版本并发控制。如果仔细观察过各种数据库的话,你会发现 MVCC 的概念经常在其中出没。数据库领域,事务的并发控制是非常核心的一个话题。
那一般大家怎么做事务的并发控制呢?
最简单的思路:加锁呗。遇事不决就上大锁。但通常这一把大锁就基本上让你跟高性能无缘了。
举个例子,锁机制解决覆盖写的场景:
-
程序猿 A:我要写 0 这个位置( 我没搞好之前,不要放人进来哦 );
-
程序猿 B:我要写 0 这个位置;
-
- 旁白:不好意思,有人( A )正在更新,你先等等;
-
程序猿 C:我要读 0 这个位置;
-
- 旁白:不好意思,有人( A )正在更新,还没搞完呢,再等等;
还有更好的策略吗?
有的,MVCC 机制也可以解决并发问题。MVCC 解决并发问题原理其实很容易理解,没有覆盖写了嘛,每次更新都对应一个数据版本。虽然是并发,但是各写各的,那就没啥需要控制的,并发问题自然就没了。并发出现问题的根源就在于大家同一时间搞一个东西嘛。
每次写入都是新的版本,不会更新旧的位置。新的数据写入跟我旧的数据又有啥关系呢。

“大家各搞各的,互不干扰,天下太平。”
所以,小结一下常见的并发控制有两大类:
- 第一种就是锁机制:锁呢,一般还分为悲观锁,或者乐观锁 ;
- 第二种就是 MVCC 机制:核心就是不覆盖更新,每次的写都在新的位置,数据存在多个版本;
下面笔者就不再单独区分数据多版本还有 MVCC 机制了,下面就用 MVCC 指代多版本的机制。
etcd 的 MVCC 带来了什么?
- 可靠的 watch 机制;
- 简单的事务并发控制;
这两点其实非常容易理解,一个 key 的历史版本全部被记录,而不是覆盖更新,那这个对于 watch 就太友好了。毕竟历史都在这嘛,数据又安全读出来又方便。
MVCC 每次写都产生一个版本的数据,并发读写数据各搞各的,并发问题自然就好解决了。
聊聊 revision 是个啥?
这里既然说到多版本,那总有个版本号吧。etcd 里的版本号叫做 revision 。revision 有两个字段:
type revision struct
main int64 // 主版本号
sub int64 // 次版本号
每个不同的写事务都有唯一一个编号,这个编号就是主版本号,它是单调递增的。次版本号呢,其实是为了区分同一个事务里的多次写操作,因为写事务串行化为了提高吞吐,所以尽量是批量操作,把大批量的写操作聚合到一个事务中,这样次版本号就有用途啦。通过 <主版本号,次版本号> 组成的 revision 就能唯一确定 etcd 中的一次更新操作哦。
这里提前提一下:用户通过 etcdctl 能摸到的一个参数就是 rev ,这个 rev 其实是主版本号哦。
直观体验一下
来 put 一个数据:
./etcdctl put hello world-v1 -w=json
"header":"cluster_id":14841639068965178418,"member_id":10276657743932975437,"revision":2,"raft_term":2
我们看到这次的版本号 revision 是 2 。再 put 一个数据
./etcdctl put hello world-v2 -w=json
"header":"cluster_id":14841639068965178418,"member_id":10276657743932975437,"revision":3,"raft_term":2
看到这次的版本号 revision 是 3 。
好了,我们来 get 一下这两个数据:
# 默认 get 是最新的 revision: 3
./etcdctl get hello
hello
world-v2
# 指定获取 revision:3 的数据
./etcdctl get hello --rev=3
hello
world-v2
# 指定获取 revision:2 的数据
./etcdctl get hello --rev=2
hello
world-v1
来把它删了,再看看。
./etcdctl del hello
1
再来读读数据看看?
# 默认 get 是最新的 revision: 4
./etcdctl get hello
# 空
# 看下最新的版本号
./etcdctl get hello -w=json
"header":"cluster_id":14841639068965178418,"member_id":10276657743932975437,"revision":4,"raft_term":2
# 再来指定获取 revision:3 的数据
./etcdctl get hello --rev=3
hello
world-v2
# 再来指定获取 revision:2 的数据
./etcdctl get hello --rev=2
hello
world-v1
神奇不神奇,你删了的 key ,还能获取到历史版本的数据呢,神奇!
什么时候真正释放呢?
上面提到,数据是多版本的,哪怕删除其实也是一个特殊数据的插入。但现实是:空间不是无限的,所以无论怎么花里胡哨的系统,删除的数据空间 100% 是一定要释放出来的。
现在的问题是:什么时候释放?
在数据多版本的设计中,空间的由一个叫做 compact 的操作来实现。MVCC 的设计中,可以认为用户的删除都是标记删除( 让你有足够的信息识别到删除 ),compact 回收则完全由内部或者外部触发。
常规的删除就现场释放了空间,而 MVCC 显式的把空间回收的动作拆成了两个步骤:
- 用户删除:标记删除;
- 系统回收:compact 空间回收;
原理剖析
好,讲了那么多,这里来浅析一下 etcd 的原理,来看看 etcd 的具体实现。
1 用户写了个 key ,变了个身
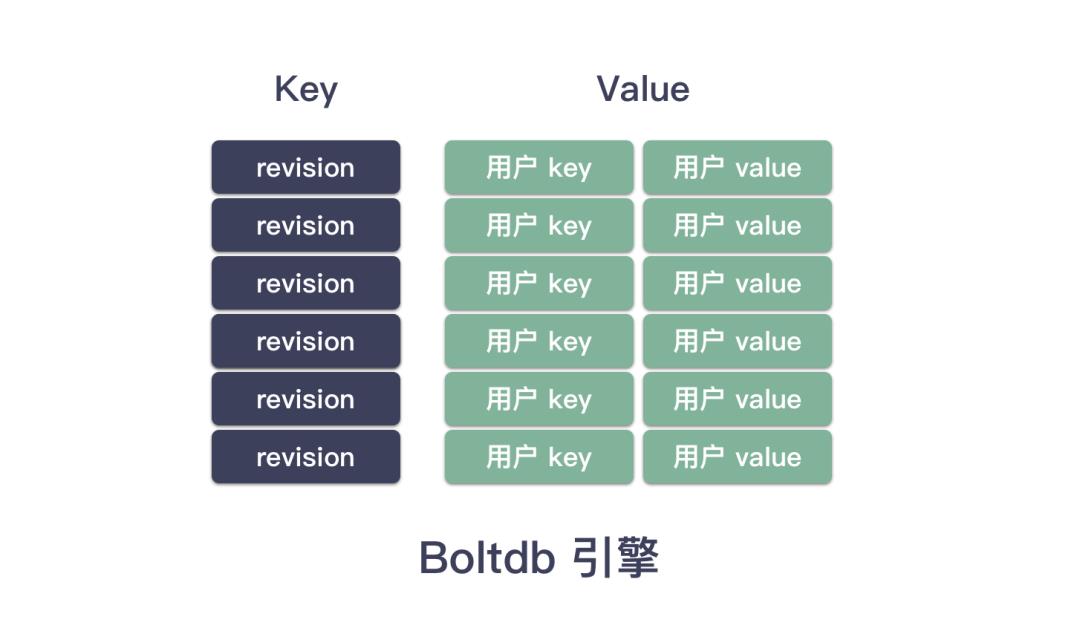
很早我们就知道,etcd 底层用的是 boltdb 做持久化的存储引擎,boltdb 是一个纯粹的 kv 存储。那现在问题来了,etcd 是怎么来存储用户的 key/value 呢?是否是直接把用户的 key 做 key,用户的 value 做 value,存入 boltdb 呢?
不用问,肯定不是的。etcd 内部生成了一个唯一 id 用作 boltdb 的 key,用户的 key/value 打包在一起作为 boltdb 的 value 存入 boltdb 的。
而这个所谓的 “内部唯一 id” 其实就是 revision 结构,一个主版本号(单调递增),一个次版本号。所以实际写入 boltdb 的 key/value 格式如下:
key:revision
value:< 用户 key, 用户 value >
举个例子,上面举例的用户存储两对键值( hello ,world-v1 ),( hello ,world-v2 )这样的 key/value 。上面两次的 put 操作,其实 boltdb 内部是存储成(注意,版本号我随意写的):
<boltdb>
key: revision=11, value: <"hello", "world-v1">
key: revision=12, value: <"hello", "world-v2">
划重点:boltdb 存储的 key 是内部的 revision 结构,value 则是一整个打包 <用户 key,用户 value> 。 整个映射关系搞成一维平坦的样子。
2 可这,叫我怎么索引呢?
既然存储到 boltdb 的 kv 已经和用户理解的 kv 大变样了。但用户对存储系统内部的原理是不关心的,他们只关系自己的 key/value ,所以必须有个手段能通过用户的 key 找到 boltdb 的 key ,从而捞出用户的 value 。怎么实现呢?
这其实是一个查找需求,查找需求的话,最简单的就是链表,但显然不够高级(查找复杂度太高,随着节点个数的增多,时间线型递增),所以 etcd 用的是 B 树,一个来自开源的库 github.com/google/btree 。
这颗 B 树存储管理的就是用户 key 到 revision 的索引。etcd 把所有的 boltdb 的 key( revision )都解析过一遍,在内存中构建了一颗完整的 B 树,B 树的查找复杂度 O(logN),并且是纯内存操作,查找过程不涉及到磁盘操作,所以速度稳定而高效。
找到 revision 之后,就可以去 boltdb 中捞数据了,捞到数据返回给用户即可。
划重点:这是一颗纯内存的 B 树,里面有所有的用户 key ,还有对应的 revision 记录。

有两个问题大家要想一下:
- 这颗 B 树的 key 是啥?
- 这颗 B 树的 value 又是个啥?
第一个问题很简单,这棵树是用来查找用户 key 到 revision 的映射的。那么自然 B 树的 key 就是用户的 key 。
第二个问题稍微要想下,我们大体知道是 revision,但这个 revision 也是组织了一下的。etcd 用了一个叫做 keyIndex 的结构体来装这个用户所有的 revision 。
来看一下 keyIndex 这个结构体,这个结构体还挺有意思的,记录着 key 的“生死轮回”:
type keyIndex struct
key []byte // 用户 key
modified revision // 最新的版本号;
generations []generation // 一个key有可能是有多次创建,删除的,每一次的轮回都是一个 generation
每个 generation 代表 key 一次轮回,这里是个数组,那就是说可以记录多次轮回呗。
举个用户增删的例子:
-
写入用户 kv 键值对,key 是 hello,value 是 world-v1 ;
-
- 产生的 revision 11.0
-
写入用户 kv 键值对,key 是 hello,value 是 world-v2 ;
-
- 产生的 revision 12.0
-
写入用户 kv 键值对,key 是 hello,value 是 world-v3 ;
-
- 产生的 revision 13.0
-
删除用户 kv ,key 是 hello ;
-
- 产生的 revision 14.0
-
写入用户 kv 键值对,key 是 hello,value 是 world-v4 ;
-
- 产生的 revision 15.0
-
写入用户 kv 键值对,key 是 hello,value 是 world-v5 ;
-
- 产生的 revision 16.0
-
删除用户 kv ,key 是 hello ;
-
- 产生的 revision 17.0
-
写入用户 kv 键值对,key 是 hello,value 是 world-v6 ;
-
- 产生的 revision 18.0
上面对 key:hello 进行了反复的摩擦,不断的写入删除,经过来上面的操作,在内存中形成的 keyIndex 如下:
世代轮回:
第一代: 11.0 , 12.0 , 13.0 , 14.0(t)
第二代: 15.0 , 16.0 , 17.0(t)
最新代: 18.0
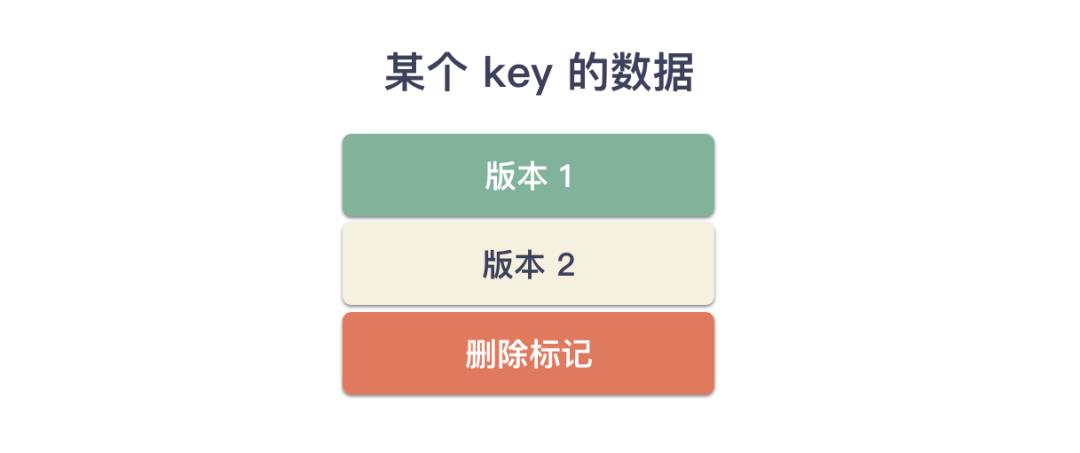
3 用户删除了个 key,做了啥?
既然在多版本的系统中写入的数据上做了一层转化,每一次的更新操作都对应了一条数据并且记录了下来。很多人其实都忘了所谓的“删除”其实本质也是更新。划重点:删除也是写入,一条特殊的数据。 用户删除一个 key 的时候,etcd 其实在 boltdb 里面又写入了一条数据,这个数据格式是这样的:
key:revision
value:< 用户 key >
想必眼尖的小伙伴应该看出来了,这个 value 它只有用户的 key ,没有用户 value ,而这条数据则恰恰是用来用户 key 被删除的标记。举个例子,还是以上面 < hello, world > 为例,用户删除 key: hello 的话,在 boltdb 里面的数据如下:
<boltdb>
key: revision=11, value: <"hello", "world-v1">
key: revision=12, value: <"hello", "world-v2">
key: revision=13, value: <"hello">
当然了,上面说的是持久化的数据,内存里面肯定也是要改的,比如用来索引的那颗 B 树。
4 哎,空间总归还是要释放的
现在思考另一个核心的问题:空间总归是要释放的,虽迟但到。只增不减的话,空间一定是会满的。用户既然要删除,那还是说明了这之前的数据用户不要了的。为了防止空间不够用,必须定期释放一些用户已经声明删除的数据。这个动作就叫做 compact !
compact 需要一个版本号。这个版本号就是写事务递增的那个版本号。划重点:这个用的是主版本号。
比如 compact 7 ,就是说把版本 7 以前的标记删除了的数据释放掉。
注意到一个细节,这里其实并不能非常精细的控制每一个 key 的回收。因为它用的是一个全局的版本号。那比这个版本号小的 key/value 都会被回收吗?
当然不是。用户没删除的数据肯定不能回收,即使版本号比 compact 传入的小。
举个例子:
// k1 有 3 个版本的数据
revision: 1, key: k1,value:v1
revision: 4, key: k1,value:v2
revision: 7, key: k1,value:v3
// k2 有两个版本的数据
revision: 10, key: k2,value:v1
revision: 12, key: k2,value:v2
现在做 compact 9 :
// k1 留下一个在用版本的数据
revision: 7, key: k1,value:v3
// k2 有两个版本的数据
revision: 10, key: k2,value:v1
revision: 12, key: k2,value:v2
你看,这不就释放了 revision 1,revision 4 这两条数据嘛。
总结
- 数据多版本,不覆盖更新,并发的时候各搞各的,MVCC 嘛。在具有 MVCC 的系统中要小心哦,所有的黑历史都记着呢;
- 版本用 revision 表示,其内有两个:主版本号和次版本号,主版本在每次写事务单调递增,次版本号在事务内多次更新时候递增;
- 在 MVCC 的设计中,删除被显式搞成两个步骤,用户的删其实是写入一个删除标记,真正的空间释放是异步的,;
- compact 使用的参数是主版本号,释放这个版本以前所有的被标记删除的数据;
- etcd 用的 B 树是全内存的,解析了所有的用户 key ,用来管理用户 key 到 revision 的映射关系;
- boltdb 是一个纯粹的 kv 存储引擎,内部无覆盖写,B+ 树索引 kv 的映射,适合读多写少的场景(写事务串行,读事务并发);
- etcd 在 boltdb 的基础上又给每一个 key 实现了多版本数据,能够很方便的实现事务并发的控制;
- etcd 的 MVCC 其实并没有给性能带来多大提升,很容易理解,因为底层用的是 boltdb ,天然就是读并发、写串行的引擎,上层无论怎么做,都逃不掉这一点,但在 etcd 中 MVCC 机制对于 watch 机制却很关键;
etcd 里的 MVCC 是占比非常大的模块,MVCC 也是很多数据库系统的核心,理解它非常有用。点赞、在看 是对奇伢最大的支持。
以上是关于云原生 etcd 系列-7|深入剖析数据多版本 MVCC 机制的主要内容,如果未能解决你的问题,请参考以下文章
深入浅出etcd系列Part 1 – etcd架构和代码框架