云原生 etcd 系列-2|Leader 是怎么选举出来的?
Posted 琦彦
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了云原生 etcd 系列-2|Leader 是怎么选举出来的?相关的知识,希望对你有一定的参考价值。
云原生 etcd 系列-2|Leader 是怎么选举出来的?
raft 核心问题
raft 是针对 paxos 的简化版本,拆解为三个核心问题:
- Leader 选举;
- 日志复制;
- 正确性的保证;
奇伢本次不对 raft 算法做详细的证明和阐述,分享几个基础的知识点:
- 在 raft 集群中,对外的服务只由 Leader 这个角色来提供;
- 集群只会有一个有效 Leader,换句话说,有效的入口只有一个,就算是发给 Follower 的,最后也是会转发 Leader 处理;
- 日志数据是单向传输的,只由 Leader 分发给 Follower,learner 等角色;
那有朋友可能会疑惑?
这么多重要的事情只能由 Leader 来做,那岂不是系统存在严重的单点?
重点就在于:虽然同一时刻只会有一个 Leader,但是 Leader 可以选举,任何完备的节点都可以成为 Leader 。
一个 Leader 倒下了,还有千万个可以顶上去。
那么 Leader 怎么选举出来的呢?
raft 的 Leader 选举
简单铺垫 raft 协议的理论基础。
在 raft 协议中角色分为三种:
- Leader :绝对领导者,集群中只会有一个有效 Leader ,Leader 负责把日志复制到其他节点,并且周期性向 Follower 发出心跳维持统治;
- Follower :跟随者,被动接收日志;
- Candidate :候选者,中间状态,竞选 Leader 的状态中;
看下 raft 论文中的角色转化:
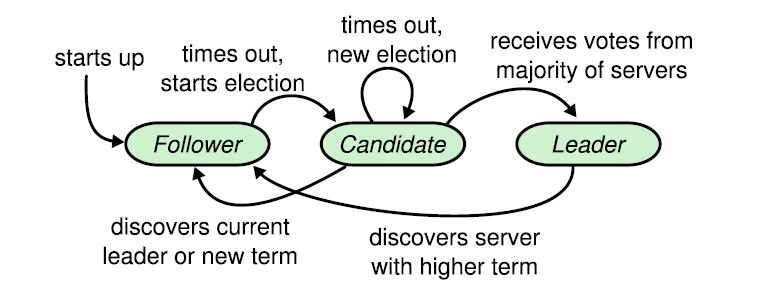
从论文很清晰能得到几个要点:
- 节点角色从 Follower 开始;
- Follower 超时之后变成 Candidate ,竞选成功变成 Leader ,竞选失败变回 Follower ;
- Leader 发现自己不配,比如收到更高任期的消息时候会自动变成 Follower ;
请求响应参数:
- term :当前任期号,term 会随着 Leader 的变更而变更,任期是线性递增的;
- index :日志的 id 号,线性递增的;
成为 Leader 有很多判断,这个此文不表,有一个最关键的点:具备完备的数据。算法证明以后再议。
本篇看一下 Etcd 的具体实现,梳理几个事情:
- 初始状态是什么?
- 怎么超时选举?
- 怎么进行的角色切换,切换之后有什么差别?
Etcd 的实现
下面从 Etcd 的具体实现来梳理一遍 Leader 选举的过程。
1 节点初始化
每个节点在初始化的时候,构造自己的 raft 状态机过程必不可少,调用 newRaft 函数创建一个 raft 状态机对象。在函数中有一个关键操作,每个节点从成为 Follower 开始:
func newRaft(c *Config) *raft
// ...
// 加载出持久化了的 raft 的状态,比如 term,vote,commit index 等
if !IsEmptyHardState(hs)
r.loadState(hs)
// 大家都是从 Follower 开始做起
r.becomeFollower(r.Term, None)
// ...
划重点:从 Follower 做起。来看下 Follower 角色的特色吧:
func (r *raft) becomeFollower(term uint64, lead uint64)
// 定制状态机的处理逻辑
r.step = stepFollower
// 定制 tick 逻辑
r.tick = r.tickElection
// ...
如上 becomeFollower 最重要的是两个逻辑定制,tick 其实是由外层业务定时驱动的,t.tickElection 可太有意思了,里面藏着一个时刻反叛 Leader 的心:时刻准备竞争领导权。
func (r *raft) tickElection()
// 每次计数加一
r.electionElapsed++
// 如果条件允许,并且已经超时,那么开始你的竞争之路吧
if r.promotable() && r.pastElectionTimeout()
// MsgHup 消息有内部产生,开始竞选之路
r.Step(pb.MessageFrom: r.id, Type: pb.MsgHup)
func (r *raft) pastElectionTimeout() bool
// 计数超过了一个数值,那么则去竞争选举
return r.electionElapsed >= r.randomizedElectionTimeout
划重点:Follower 角色 tick 计数超过一定阈值( r.randomizedElectionTimeout )的时候,就准备开始竞选。
2 谁都有可能超时 !
假设有集群有三个节点,A,B,C 各自 tick ,谁都有可能先超时,先到 pastElectionTimeout 这个条件,因为这个每个节点阈值是随机生成的。r.randomizedElectionTimeout 是一个随机值。
func (r *raft) resetRandomizedElectionTimeout()
// 随机加了一个随机因子
r.randomizedElectionTimeout = r.electionTimeout + globalRand.Intn(r.electionTimeout)
划重点:每个节点选举超时阈值是随机的。
3 从 MsgHup 消息开始
tick 谁先超时,谁先发出一个 MsgHup 消息投递到 raft 状态机中,一切从此开始。继续往后看吧,raft 状态机是怎么处理的。
r.Step(pb.MessageFrom: r.id, Type: pb.MsgHup)
4 raft 状态机处理 campaign 开始
raft 状态机怎么处理 MsgHup 消息?
位置在 raft.Step 公共部分:
// etcd/raft/raft.go
func (r *raft) Step(m pb.Message) error
// ...
switch m.Type
case pb.MsgHup:
// 本地产生的竞争选举的消息,说明超时了,下一步就是要开启选举了
if r.state != StateLeader
if r.preVote
// 开启预投(可配)
r.campaign(campaignPreElection)
else
// 开启竞选
r.campaign(campaignElection)
else
r.logger.Debugf("%x ignoring MsgHup because already leader", r.id)
关键事件:
- 如果开启了 preVote 开关,那么走预投的流程;
- 如果没有开启 preVote ,那么直接开启选举;
预投流程这个我们稍后单独讲,我们先直接发起投票的流程。
什么叫发起投票呢?
发送 MsgVote 的消息给集群的其他节点,等请求响应回来之后就唱票,得到大多数人的支持(没明确拒绝),那么就成为 Leader 角色。
发起投票的目的是?
当然是成为那至高无上的 Leader 。
来看下 raft.compaign 的逻辑:
func (r *raft) campaign(t CampaignType)
// ...
if t == campaignPreElection
else
// 变成候选者,准备发送选举消息 MsgVote
r.becomeCandidate()
// 消息类型为:MsgVote
voteMsg = pb.MsgVote
// 轮询所有节点,除本节点外,其他所有节点将收到一条 MsgVote 的消息;
for _, id := range ids
if id == r.id
continue
var ctx []byte
if t == campaignTransfer
ctx = []byte(t)
r.send(pb.MessageTerm: term, To: id, Type: voteMsg, Index: r.raftLog.lastIndex(), LogTerm: r.raftLog.lastTerm(), Context: ctx)
关键事件:
- 角色变成 Candidate ( 很关键 );
- 发送 MsgVote 消息;
而成为 Candidate (候选者)有两个不得不提的处理:
- r.step 由 stepFollower 修改为 stepCandidate ;
- raft 状态机的
任期+1( 新人用新任期嘛 );
消息发出去之后,就等待结果回来之后唱票啦。而唱票的逻辑,自然是在 stepCandidate 中触发喽。
5 投票结果回来了,唱票!
唱票啦,Candidate 群发 MsgVote 消息之后,就等着响应回来,只要得到多数人的支持就算成功。
func stepCandidate(r *raft, m pb.Message) error
if r.state == StatePreCandidate
else
// 响应消息类型
myVoteRespType = pb.MsgVoteResp
switch m.Type
// 投票的结果回来了( vote 或者 prevote )
case myVoteRespType:
// 唱票啦啦啦
gr, rj, res := r.poll(m.From, m.Type, !m.Reject)
// 唱票结果判断一下
switch res
case quorum.VoteWon:
if r.state == StatePreCandidate
// 如果是预投的情况,获得了大多数的认可,觉得自己能赢,那么现在就稳了,就可以正式开始拉票选举
r.campaign(campaignElection)
else
// 如果是投票的场景,这就成功了呀,变成 Leader
r.becomeLeader()
// 广播日志消息(哪怕一条空消息)
r.bcastAppend()
case quorum.VoteLost:
// 失败了呀
r.becomeFollower(r.Term, None)
上面 r.poll 函数就是一个计票、唱票的具体实现,非常简单,做两件事:
- 把对应节点的回应结果记录下来,是支持?还是拒绝?这个由 m.Reject 表示;
- 然后统计当前收到的所有结果,比如集群规模是 3 ,已经有 2 个支持,那么就可以出结果了;
唱票的结果分三种:
- VoteWon :结果明确,得到多数人的支持,成了;
- VoteLost :结果明确,确定得不到多数人的支持,确认失败(比如说集群 5 个节点,已经收到 3 个拒绝,那么就算还有一个响应没收到,那么也是没希望了);
- VotePending :结果未知,还有人的响应没收到,不足以做出判断,这种情况继续等待;
如果选举成功了,那么就把角色转变一下,并且广播日志( 如果没有有效日志,那么也会广播一条空的 Message )。
r.becomeLeader()
r.bcastAppend()
如果选举失败,那也转变角色,等待日志复制消息即可。
r.becomeFollower(r.Term, None)
6 Leader 怎么维护自己的统治呢?
在上面我们知道,每个 Follower 都有一颗不甘的心,有个定时器在不断计数,超过阈值就想要去竞争 Leader ,这个也是系统自驱力的一部分。
那现在已经有合法的 Leader 之后,Leader 怎么才能维护自己的稳定呢?
划重点:方法很简单,就是 Leader 也起一个定时器,不断的告诉 Follower ,让 Follower 的计数器清零( pua Follower ?)。
下面来看一下这个逻辑,在 becomLeader 方法里面:
func (r *raft) becomeLeader()
// Leader 的定时器(和 Follower 是不一样的)
r.tick = r.tickHeartbeat
// ...
Leader 维护统治的秘密就在 tickHeartbeat :
// etcd/raft/raft.go
func (r *raft) tickHeartbeat()
// 心跳加计数
r.heartbeatElapsed++
// 下面的逻辑是 Leader 专享
if r.state != StateLeader
return
// 心跳计数超过一定阈值了,是时候告诉 Follower 们,我还在,你们别想了
if r.heartbeatElapsed >= r.heartbeatTimeout
// 由 MsgBeat 消息开始
r.Step(pb.MessageFrom: r.id, Type: pb.MsgBeat)
tickHeartbeat 是 Leader 的 tick 定时逻辑,很简单,每过一小会就会投递一个 MsgBeat 消息到自身的 raft 状态机。这个消息进到状态机内部之后,在 stepLeader 函数中处理:
func stepLeader(r *raft, m pb.Message) error
switch m.Type
case pb.MsgBeat:
// 广播心跳
r.bcastHeartbeat()
return nil
处理方法非常简单,就是广播心跳。给所有的 Follower 一个 Message ,告诉它们,别想了,我还在,你们该打消竞选的念头了。
这个消息的类型为:MsgHeartbeat 。
那 Follower 收到 MsgHeartbeat 消息会怎么做呢?它又是怎么打消竞选的念头呢?这个才是配合的关键。
Follower 角色嘛,那就看的是 stepFollower 的处理逻辑。
func stepFollower(r *raft, m pb.Message) error
switch m.Type
// ...
case pb.MsgHeartbeat:
// 划重点:简单粗暴,计数直接清零
r.electionElapsed = 0
r.lead = m.From
// 回复 Leader 响应
r.handleHeartbeat(m)
// 回复 Leader 响应
func (r *raft) handleHeartbeat(m pb.Message)
r.raftLog.commitTo(m.Commit)
r.send(pb.MessageTo: m.From, Type: pb.MsgHeartbeatResp, Context: m.Context)
童鞋们看到了吗?
处理非常简单,Follower 直接当面清零 r.electionElapsed ,在上面我们知道的,这个是判断是否发起最重要竞选的条件。所以,这样 Leader 每次都及时用心跳打压 Follower ,它就永远不会反叛,一直保持稳定。
举个形象的例子:
Follower 是假设一秒计数一次,超过 10 次就发起竞选。Leader 则是每 2 秒发一个 MsgHeartbeat 消息过来。就能时刻把 Follower 摁的死死的。
发现了一个重要知识点:Leader 和 Follower 的定时器间隔有讲究。
划重点:Leader 的 tick 的间隔要小于 Follower 的 tick 间隔。 这样才能稳定,如果不满足这个关系,会导致不断的发起无意义的竞选。
一般来说,Leader 的 tick 间隔是 1,Follower 的间隔是 10 。
那有些人可能会想,我把 Follower 的 tick 间隔设置到非常大,这样也没问题吧?
有问题。选举超时间隔影响到 Leader 异常之后集群的恢复间隔。
raft 集群没有 Leader 是无法对外提供服务。一旦 Leader 阵亡,要有其他 Follower 能够顶上来,成为新 Leader 之后,系统才能重新运转,这个时间窗口就是停服窗口。
所以,这个发起选举的时间间隔也是要权衡的一个值。
7 预投是什么意思?
Leader 竞选的流程上面已经梳理了,在前面提到 becomeCandidate 的时候有一个非常关键的操作:任期+1 ,然后发 MsgVote 消息给其他节点。在集群新节点扩容的时候,会引发集群可用性问题。
怎么引发的?
- 假设有 A,B,C 三个节点,当前任期是 7 ,Leader 是 A ,正在对外提供服务呢;
- 现在新扩( 或者是网络分区之后的恢复 )一个 D 节点( 假设它的数据完备 ),如果 D 节点上来就增加任期为 8 ,向所有节点发起投票;
- 如果还真有人投了它,比如 C ,那 C 接受的任期就变成了 8 。这会导致 A 再发过来的请求被拒绝,不满足 quorum,A 就提供不了对外服务,整个集群停摆,超时之后集群走重新选举。
重新选举意味着?
意味着 Leader 一小段的空窗期。没有 Leader 的这段时间对外服务是暂停的。
所以,针对这种扩容,还有网络分区又恢复的各种场景,可能会因为不必要的重新选举导致服务中断。预投则是为了解决这个问题的。
预投是怎么解决?
不发起真正的竞选,而是提前咨询其他节点(不增加节点的任期,意味着请求无害)。确认自己能够胜出之后,再去竞选。
这样的话,D 节点先发给 A,B,C ,我可以吗?
- A:你不可以;
- B:你不可以;
- C:你可以;
D 只得到 2 票,不满足多数,所以乖乖的做 Follower 吧。
总结
- **选举****流程:**Follower tick 超时 -> 产生 MsgHup -> 广播 MsgVote 消息 -> 收到 MsgVoteResp(唱票)-> 心跳 PUA ;
- **心跳流程:**Leader tick 超时 -> 产生 MsgBeat -> 广播 MsgHeartbeat 消息 -> Follower 清零计数;
- Leader 心跳超时要小于 Follower 竞选超时间隔,但竞选超时间隔又不能过大;
- 预投不会导致其他节点任期增加,这是一个无害咨询消息;
以上是关于云原生 etcd 系列-2|Leader 是怎么选举出来的?的主要内容,如果未能解决你的问题,请参考以下文章