3种基于深度学习的有监督关系抽取方法
Posted 华为云开发者社区
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了3种基于深度学习的有监督关系抽取方法相关的知识,希望对你有一定的参考价值。
摘要:本文对几种基于深度学习的有监督关系抽取方法进行了介绍,包括CNN关系抽取、BiLSTM关系抽取以及BERT关系抽取。
本文分享自华为云社区《基于深度学习的有监督关系抽取方法简介》,作者: 一枚搬砖工。
随着互联网的快速发展,大数据、信息化时代悄然来临,如何从海量数据中挑选出有利用价值的信息,是十分具有挑战性的。本文将对基于深度学习的有监督关系抽取方法进行介绍。
1、任务定义
关系抽取是信息抽取的重要子任务之一,其目标在于从文本中抽取出两个或多个实体之间的语义关系。根据关系事实中涉及的实体数量,又可以进一步细分为二元关系抽取和多元关系抽取。本文中,关系抽取特指二元关系抽取。
输入:句子、目标实体对(头实体+尾实体)
输出:目标实体对之间的语义关系
------------------------------------------------
例1:
输入:建安二十五年,曹操去世,葬于高陵,其子曹丕继位魏王。
- 头实体:曹操
- 尾实体:曹丕
输出:儿子在上述例子中,给定输入文本“建安二十五年,曹操去世,葬于高陵,其子曹丕继位魏王。“,其中”曹操“是头实体,”曹丕“是尾实体,两者之间的语义关系为”儿子“,即可抽取关系三元组<曹操,儿子,曹丕>。
2、关系抽取方法
在有监督的关系抽取中,关系抽取任务通常被建模成一个多分类任务,大多数研究工作也围绕着如何提取文本特征用于关系分类展开。本节将介绍三种用于关系抽取的常用方法。
2.1、CNN关系抽取
论文:Relation Classification via Convolutional Deep Neural Network
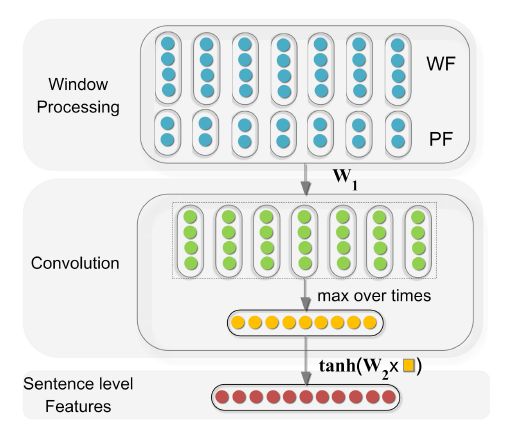
主要思想:
使用CNN结构提取文本的句子级特征用于关系分类。与文本分类任务不同的是,在关系抽取任务中,头实体和尾实体对关系的预测和判断有着重要的影响。例如,在例1中,如果头实体是“曹丕”,尾实体是“曹操”,则实体对之间的关系变成了“父亲”,即<曹丕,父亲,曹操>。因此,在提取文本特征时考虑实体对的位置是十分有必要的。在这篇文章中,通过引入位置向量的方法来指明头实体和尾实体。如下图所示,词“高陵” 与头实体“曹操” 和尾实体“曹丕” 的相对位置距离分别为4 和-3,可分别在头实体和尾实体对应的位置向量表中查询得到对应的位置向量,再拼接得到词“高陵” 的全部位置向量。最后,拼接上词的原本向量表示,得到最后的词向量化表示。最后,使用一个卷积神经网络提取句子级的文本特征,用于关系分类。

2.2、BiLSTM关系抽取
论文:Attention-Based Bidirectional Long Short-Term Memory Networks for Relation Classification
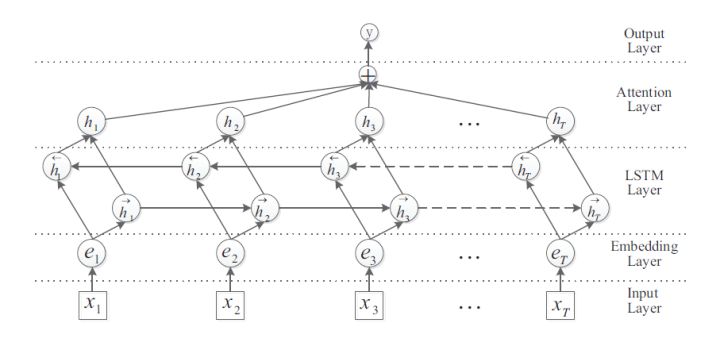
主要思想:
使用BiLSTM作为特征提取器提取文本特征,并结合注意力机制捕捉文本中的重要特征。在这篇文章中,对文本进行编码时,使用了四个位置指示符(<e1>,</e1>,<e2>,</e2>)标记实体的位置。例如,在例1中,输入文本就变成了“建安二十五年,<e1>曹操</e1>去世,葬于高陵,其子<e2>曹丕</e2>继位魏王。”,表明“曹操”是头实体,“曹丕”是尾实体。通过位置指示符,可以使模型感知实体的位置,强化模型对于实体关系的理解。然后,使用BiLSTM提取深层次的文本特征。在关系抽取中,局部特征常常足以推测判断实体对的关系。在例1中,“其子” 一词就是预测“曹操” 和“曹丕” 之间人物关系的最重要特征。在这篇文章中,使用句间注意力机制对BiLSTM提取的文本特征进行组合,提取其中最重要的语义特征信息。具体如下:
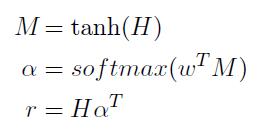
其中,H \\in R^d^\\omega\\times TH∈Rdω×T是BiLSTM的输出, d^\\omegadω 是隐层维度,TT 是句子长度, \\omegaω 、 \\alphaα 、rr的维度分别为 d^\\omegadω 、TT、d^\\omegadω。最后使用特征向量rr进行关系分类。
2.3、BERT关系抽取
论文:Enriching Pre-trained Language Model with Entity Information for Relation Classification
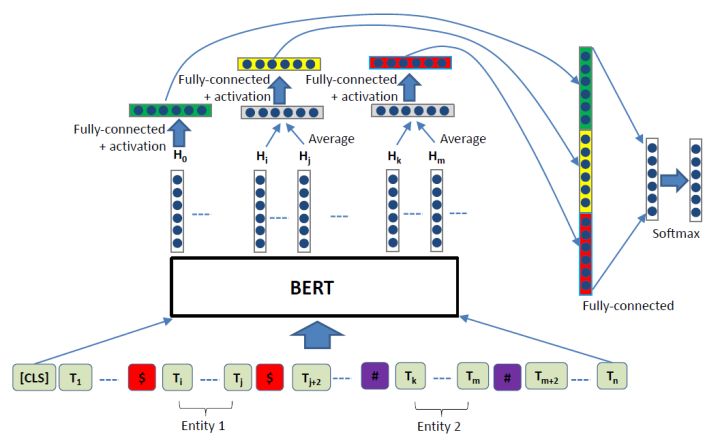
主要思想:
使用BERT抽取句子的文本特征用于关系分类。与上节相似,在这篇文章中,也是用特殊符号标记实体的位置,在头实体和尾实体周围分别插入“$”和“#”,并在每个句子的开始位置添加“[CLS]”,然后将目标文本输入到BERT中。关系分类的特征来自于三个部分:句子的整体特征,头实体特征以及尾实体特征。在BERT 预训练时, “[CLS]”被NSP任务用来判断句子对的关系,从而能够学习到对整个句子的表达。因此,句子的整体特征通过 “[CLS]”来获取:
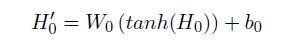
其中,H_0 \\in R^dH0∈Rd是BERT的CLS输出向量,dd是BERT的隐层维度。
而实体对特征则通过对实体的BERT输出做均值化处理获取。具体如下:
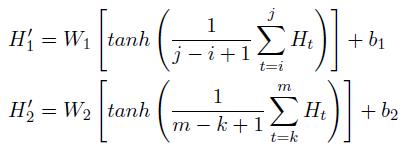
最后,将获取的句子特征及实体特征拼接得到最后的特征向量,进行关系分类。
3、小结
本文对几种基于深度学习的有监督关系抽取方法进行了介绍,包括CNN关系抽取、BiLSTM关系抽取以及BERT关系抽取。
想了解更多的AI技术干货,欢迎上华为云的AI专区,目前有AI编程Python等六大实战营供大家免费学习。(六大实战营link:华为云AI实战营_云主机_云服务器_华为云)
以上是关于3种基于深度学习的有监督关系抽取方法的主要内容,如果未能解决你的问题,请参考以下文章