第十七篇:信息抽取Information Extraction
Posted flying_1314
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了第十七篇:信息抽取Information Extraction相关的知识,希望对你有一定的参考价值。
目录
信息抽取
• 根据下面这句话:
‣ “Brasilia, the Brazilian capital, was founded in 1960.”
• 得到:
‣ capital(Brazil, Brasilia)
‣ founded(Brasilia, 1960)
• 主要目标:将文本转化为结构化数据
应用
• 股票分析
‣ 从新闻和社交媒体中收集信息
‣ 将文本汇总为结构化格式
‣ 决定是否以当前股价买入/卖出
• 医学研究
‣ 从有关疾病和治疗的文章中获取信息
‣ 决定为新患者申请哪种治疗
如何?
• 两个步骤:
‣ 命名实体识别 (NER):找出“Brasilia”和“1960”等实体
‣ 关系抽取:使用上下文查找“Brasilia”和“1960”(“founded”)之间的关系
IE 中的机器学习
• 命名实体识别(NER):序列模型,例如RNN、HMM 或CRF。
• 关系提取:主要是分类器,二元或多类。
• 本讲座:如何构建这两个任务以应用序列标记器和分类器。
大纲
• 命名实体识别
• 关系抽取
• 其他 IE 任务
命名实体识别
典型实体标签
• PER:人物、人物
• ORG:公司、运动队
• LOC:地区、山脉、海洋
• GPE:国家、州、省(在某些标签集中,这被标记为 LOC)
• FAC:桥梁、建筑物、机场
• VEH:飞机、火车、汽车
• 标签集依赖于应用程序:一些域处理特定实体,例如 蛋白质和基因
NER作为序列标记
• NE 标签可能不明确:
‣ “Washington” 可以是个人、地点或政治实体
• 做 POS 标记时的类似问题
‣ 合并上下文
• 我们可以为此使用序列标记器吗(例如 HMM)?
‣ 否,因为实体可以跨越多个标记
‣ 解决方法:修改标签集
IO 标记
• “I-ORG”代表一个实体(在本例中为 ORG)内部的令牌。
• 所有不是实体的令牌都获得“O”令牌(用于外部)。
• 无法区分:
‣ 具有多个标记的单个实体
‣ 具有单个标记的多个实体
IOB 标签
• B-ORG 代表 ORG 实体的开始。
• 如果实体具有多个单词,则后续标签表示为 I-ORG。
NER作为序列标记,继续
• 给定这样的标记方案,我们可以训练任何序列标记模型
• 理论上,可以使用 HMM,但首选 CRF 等判别模型
NER:特征
• POS 标签/句法块:许多实体是名词或名词短语。
• 地名录中的存在:实体列表,例如地名、人名和姓氏等。
NER 的深度学习
• 最先进的方法使用带有字符和单词嵌入的 LSTM(Lample 等人,2016 年)
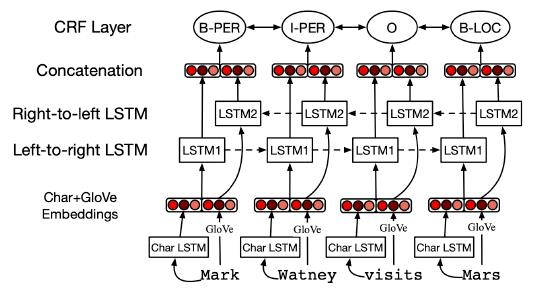
关系抽取
• 传统上被定义为三元组提取:
‣ 单位(美国航空、AMR Corp.)
‣ 发言人(Tim Wagner,美国航空公司)
• 关键问题:我们是否知道所有可能的关系?
方法
• 如果我们可以访问固定关系数据库:
‣ 基于规则
‣ 监督
‣ 半监督
‣ 远程监管
• 如果对关系没有限制:
‣ 无监督
‣ 有时称为“OpenIE”
基于规则的关系抽取
• NP0 比如 NP1 → 下义词(NP1, NP0)
• 词汇句法模式:高精度、低召回率、需要人工
有监督的关系抽取
• 假设一个带有注释关系的语料库
• 两个步骤。 首先,查找实体对是否相关(二元分类)
‣ 对于每个句子,收集所有可能的实体对
‣ 注释对被视为正例
‣ 未标注的对作为反例
• 其次,对于预测为正的对,使用多类分类器(例如 SVM)获得关系
半监督关系抽取
• 带注释的语料库的创建成本非常高
• 使用种子元组引导分类器
1. 给定种子元组: hub(Ryanair, Charleroi)
2. 在种子元组中查找包含术语的句子
• 以沙勒罗瓦为枢纽的廉价航空公司瑞安航空取消了所有周末离开机场的航班。
3.提取一般模式
• [ORG],使用 [LOC] 作为中心
4. 用这些模式寻找新的元组
• 枢纽(捷星、阿瓦隆)
5. 将这些新元组添加到现有元组并重复步骤 2
语义漂移
• Pattern: [NP] has a {NP}* hub at [LOC]
• Sydney has a ferry hub at Circular Quay
‣ hub(Sydney, Circular Quay)
• 从此元组中提取出更多错误模式……
• 应该只接受具有高置信度的模式
远程监管
• 半监督方法假设存在种子元组以挖掘新元组
• 我们可以直接挖掘新元组吗?
• 远程监督从范围中获取新元组
来源:
‣ DBpedia
‣ Freebase
• 生成海量训练集,可以使用更丰富的特征,并且没有语义漂移的风险
无监督关系提取(“OpenIE”)
• 没有固定或封闭的关系集
• 关系是子句; 通常有一个动词
• “United has a hub in Chicago, which is the headquarters of United Continental Holdings.”
‣“has a hub in”(United, Chicago)
‣ “is the headquarters of”(芝加哥,联合大陆控股)
• 主要问题:将关系映射到规范形式
评估
• NER:F1-实体级别的度量。
• 已知关系集的关系抽取:F1-measure
• 未知关系的关系抽取:更难评估
‣ 通常需要一些人工评估
‣ 这些设置中使用的海量数据集无法手动评估(使用样本)
‣ 只能获得(近似)精度,不能获得召回率。
其他 IE 任务
时间表达提取
• 锚定:“上周”是什么时候?
‣ “last week” → 2007−W26
• 规范化:将表达式映射到规范形式。
‣ July 2, 2007 → 2007-07-02
• 主要基于规则的方法
事件提取
• 与NER 非常相似,包括注释和学习方法。
• 事件排序:检测一组事件在时间线中是如何发生的。
‣ 涉及事件提取和时间表达式提取。
最后
• 信息提取是一个包含许多不同任务和应用的广阔领域
‣ 命名实体识别
‣ 关系抽取
‣ 事件提取
• 机器学习方法涉及分类器和序列标记模型。
今天就到这里了,感谢小伙伴们的观看,谢谢!有问题评论区交流!
以上是关于第十七篇:信息抽取Information Extraction的主要内容,如果未能解决你的问题,请参考以下文章