MySQL基本使用(内容较多建议熟读并背诵)
Posted 'or 1 or 不正经の泡泡
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了MySQL基本使用(内容较多建议熟读并背诵)相关的知识,希望对你有一定的参考价值。
文章目录
前言
千呼万唤始出来~这次总算把sql的基本使用做了一个小结,里面总览了不少内容,有问题的部分,可以留言,有时间我会单独领出来(毕竟这个导向还是以我为中心的,我认为我能看懂,大部分人也能看懂)
本篇文章较长,包括常用指令,概念,建议熟读并背诵~
首先是关于SQL语句的分类,SQL语句分为四种,DDL,DML,DQL,DCL。接下来围绕这几个来聊聊这个操作。
阅读本文的建议,请按照如下顺序阅读
之后再来阅读本文,当然如果有基础只是来复习的,那就直接来看吧~
关于环境准备还是老建议,如果你是Windows不建议直接安装mysql,可以使用继承开发环境,例如phpstudy或者其他的数据库工具,如果你是Linux系统,建议可以直接安装,如果有图形化界面也是可以安装集成工具的,没有的话就直接安装mysql,然后使用vscode or idea 进行连接就可以,当然使用别的工具也可以。使用命令行硬刚也可以,建议pip install mycli(一款命令行sql神器,建议先安装python,如果你是Linux的话内置了python3.x,但是应该是没有pip安装工具的,所以可以考虑安装pip工具或者直接apt install 也是可以的)
从暑假就嚷嚷着要做个总结,现在它终于来了!
DDL
DDL是数据库定义语言,用来定义这个数据库,这个数据表长啥样的。这张表如何,数据库的创建滴。
数据库的创建
-
C(create)创建
创建数据库:create database yourdatabasename;存在判断
create database if not exists yourdatabasename;创建数据库,指定字符集
create database name character set utf8;案例
create database if not exists Huterox character set utf8; -
R(Retrieve)查询
查询所有
show databases;查询某个数据库的创建语句
show create database name; -
U(updata)修改
修改字符集alter database name character set 字符集; -
D(delete)删除
删除drop database name;判断
drop database if exists name; -
使用
进入数据库使用use databasename;查询当前使用的数据库名称
select database();
操作数据库表
-
创建
格式
create table 表名( 列名(字段名), 列名(字段名), 列名(字段名), ... );案例
create table student( id int, name varchar(32), age int, score double(4,1), birthdat date, insert_time timestamp );创建表长得和已有的表一样
create table A like B; -
查询
查询所有数据表
show tables;查看这个表的描述
desc tablename; -
修改
修改表名
alter table 表名 rename to 表名(新的);修改字符集
alter table 表名 character set 字符集;添加一列(字段名)
alter table 表名 add 字段名(列名)数据类型;修改列名,类型
一起修改 alter table 表名 change 字段名 新的字段名 类型; 只是修改属性 alter table 表名 modify 字段名 属性删除列
alter table 表名 drop 字段名(列名) -
删除
案例
drop table if exists 表名
对表的CURD
这里的话其实是对数据库表的操作,但是的话这里拆分了两个玩意一个是 DML,就是对数据库表的
CUD,增,改,删。查询叫做DQL,这个也是比较复杂的点,所以是单独拆开了。
DML
好现在来聊聊这个DML
-
添加数据
insert into 表名(列名,列名。。。) value(值,值...); insert into 表名 value(所有字段的值); -
删除数据
delete from 表名 [条件]; delete from A where id=1;细节
如果你想要删除所有内容delete from 表名但是这样做的话,其实并不好,他是一个一个删的,所以这样
truncate table 表名这个是这样的
create table A like B; drop table B; -
修改数据
update 表名 set 列名 = 值, 列名2=值2 where 列名=值;例如:
update A set age=20 where name = Huterox;同样如果你不加where 那么全部的都会被修改
DQL
这个就是我们比较重要的内容了,
先来看看格式
select
字段名,
字段名,
...
from
表名,
表名
where
条件
group by
分组
having
分组之后的条件操作
order by
排序
limit
排序
这个是完整的操作,当然我们先用最简单的来玩一下。
单表操作
最简单的例子
select * from A
去除重复的结果集
select distinct * from A
简单的运算
在SQL里面支持一些简单的直接运算,例如直接求和,当然我们也有聚合函数,这个如果你看过那个Pandas的基本使用的话应该是知道怎么玩的。而且其实那个Pandas的DataFrame其实和我们数据的表的结构很类似的。
select a,b,c,a+b from A
假设我们的表里面有 a,b,c这三个字段。
当然在这里有个细节,如果a,b其中一个为null 那里相加是null所以我们要解决空值的问题。
select IFNULL(a,0),IFNULL(b,0),c,a+b from A
如果出现了null,用0来代替。
此外你还可以起个别名
select IFNULL(a,0),IFNULL(b,0),c,a+b as sum from A
这个 as 还可以使用空格代替。
之后是咱们的where 这个我想应该不用多说了,记住一个细节就是这里的=不是==了就差不多了,例如
select * from A where id>=20 and id=<30;
select * from A where id between 20 and 30;
模糊查询
此外我们还有模糊查询
这里明确就是 _ 是一个占位符,% 是N个 _ 的意思
看例子就明白了
select * from A where name like '_乐%';
select * from A where name like '乐%';
select * from A where name like '__乐%';
子查询
当然在这里还有一个子查询
select name from student where id in (select id from score where math > 10);
是这个样子的。
之后还有咱们的排序,分组查询,当然还有分页,这部分内容的话在
SQL注入问题有,这里就补充一下我们的聚合函数吧。
聚合函数:将一列数据当做一个整体进行计算。
例如:统计个数
select count(name) from A;
此外我们还有这些函数(记住这些函数排除了null)
count
max
min
sum
avg
之后的话我们来看看这个约束。
这个也是比较重要的。
约束
首先我们的约束也是分为好几类的。
-
主键约束:primary key
-
非空约束 not null
-
唯一约束 unique
-
外键约束 foreign key
添加约束也是有两种方式的,一个就是创建的时候添加
create table student(
id int primary key auto_increment,
name varchar(32) not null,
)charset=utf8;
前面的这三个约束其实非常简单,但是这个外键操作的话就开始要注意了,因为这个外键涉及到我们整个多表操作,也是数据库操作里面比较复杂的部分。
外键
首先这里的话也是创建这个外键也是有两种方式的一种就是直接写嘛,还有就是后面添加嘛
create table student
(
id int primary key auto_increment,
name varchar(32) not null,
constrain 外键名称 foreign key 外键列名 references 另一张表名字(列名)
)charset=utf8
首先这里的话我们得创建两张表。
create table student(id int primary key auto_increment,name varchar(128),age int)charset=utf8;
create table class(id int primary key auto_increment,name varchar(128))charset=utf8;
现在我们创建好了表,那么我们来聊聊什么是级联,这两个操作是一块的。
级联概念
首先先说一下啊,在实际的操作过程当中,据阿里巴巴的开发手册说禁止表的级联,所有的相关操作应该在代码里面实现逻辑级联。这个其实也是为了安全嘛,当然我也是现在才知道,我的哪个White Hole里面不知道用了多少个级联。
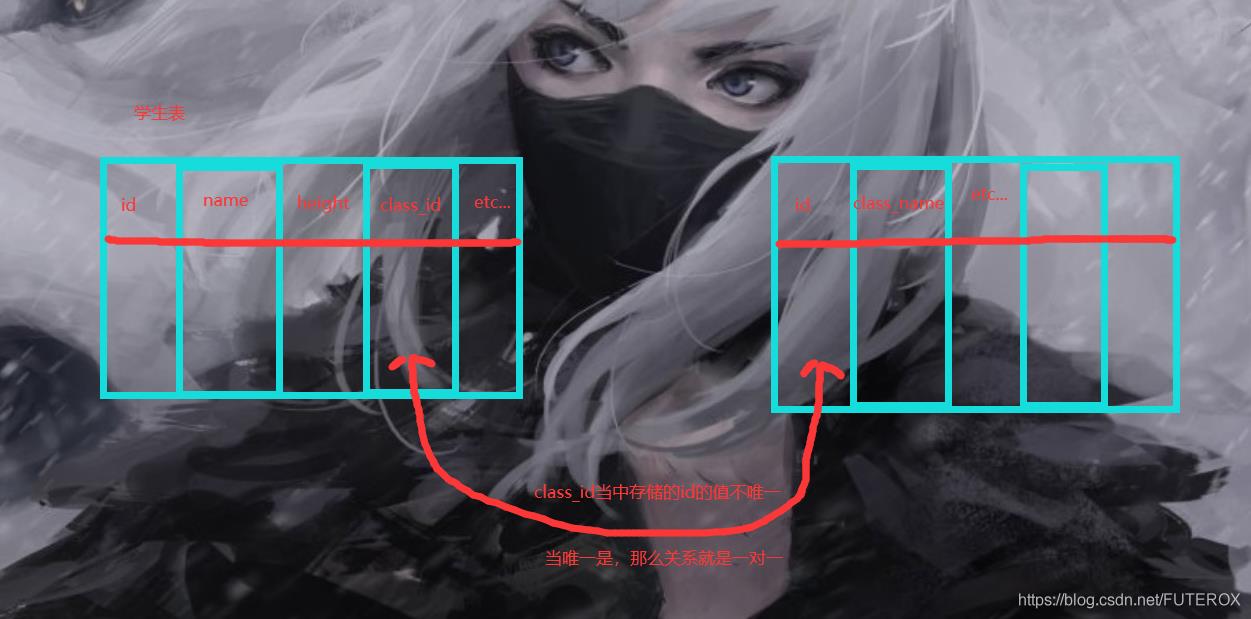
所谓的级联其实很简单,举个以前的老例子就明白了。学生表和班级表。
学生表里面一定有一个字段存放班级的ID,那么这个存放班级ID的字段是不是需要约束。
用这个约束来限定学生表里面存放的班级Id的字段的内容。例如:在班级表里面的ID里面没有“A”,那么显然在学生表存放班级ID的字段里面也不能出现“A”这个值!
接下来我们来演示一下这个具体的操作。
现在我们创建一个 class_id 作为我们的外键
alter table student add class_id int;
之后升级为外键
alter table student add constraint fg_class_id foreign key(class_id) references class(id);
当然如果你想删除的话这样干
alter table student drop constraint fg_class_id;
说到这里的话又扯到了,表的关系,现在我们其实是实现了一个表的一对多关系
其实还有多对多,一对一的关系,这些都是可以通过我们的外键级联操作实现的。
表的关系
一对多
这里我们可以直接以Django的ORM为例子。在sql语句当中我们直接设置一个外键就好了。
它的一个模型是这样的。也就是我们这里的例子。
此外我们直接在Django里面这样操作就行了(是不是比mybatis这种半自动框架厉害多了)
看代码:
class Grade(models.Model):
g_name = models.CharField(max_length=32)
class Student(models.Model):
s_name = models.CharField(max_length=16)
s_grade = models.ForeignKey(Grade) #添加外键约束
一对一
现在用身份证和人的关系来做比喻
 。
。
在我们的sql里面想要实现这个功能你这样就行
alter table student add constraint fg_class_id foreign key(class_id) references class(id);
alter table student add constraint fg_class_id_un unique(fg_class_id );
在Django当中就是这样的。
class Person(models.Model):
p_name = models.CharField(max_length=32)
class Person_id(models.Model):
p_id = models.CharField(max_length=32)
p_person = models.OneToOne(Person)
多对多
这个就要注意一点了,因为操作时不太一样的。
那么是怎么是实现的呢,我们还是先举个例子,购物车和人的关系,这个就是典型的多对多。

我们需要一张中间表来实现。
之后也是外键的绑定。
这个在我的那个
SpringBoot + Vue(前后端分离之博客上传) 有案例,那个表是怎么设计的。
当然现在那个玩意也就当个demo玩玩,重构喽~(这次得用上我全部的技术java技术栈,python技术栈,后面再基于flink打造推送系统,至于选择哪套分布式是springcloud依托咧,还是k8s呢,这个得等我把分布式好好坑坑喽,我就不信我大二下学期完成不了,到时后当毕设应该是OK的,然后再围绕人工智能做一个(那个万一没搞定,就把这个当做备份方案))
class Customer(model.Model):
c_name = models.CharField(max_length=16)
class Goods(models.Model):
g_name = models.CharField(max_length=16)
g_customer = models.MangToMangField(Customer)
现在我们把模型建好了,那么我们先对模型进行操作,后面我们再来说说这玩意是怎么做的。
获取查询部分还是和我们以前一样,但是这里多了一个添加关系,例如我们的购物车里面增加了一个商品。
Phone = Goods()
Phone.g_name="iPhone12"
Phone.save()
Me = Customer.objects.get(c_name="xiaoming")
Me.goods_set.add(Phone)
.remove(Phone)
.set(Phone1,Phone2,...)
当然我们也可以反过来,但是其实这些效果都是一样的,原因看下面的图你就明白了。
那么如果要自己实现的话也是这样开设计,甚至只会更加复杂。
主从表
说到了这里的话,那个在多一嘴就是那个在Django里面的这个中从表的问题。
每次涉及到这多表关系的时候就会出现联表关系的问题,在django当中凡是加了约束的例如人与身份证的那个关系中的身份证表就是从表,当主表删除时,从表也会删除(delete on cascade),这个是默认的,所以有时候为了数据安全,我们应该设置一下,例如只有当从表中对应的数据删了,那么主表才能被删除。(其实这里就是级联操作)
class Person_id(models.Model):
p_id = models.CharField(max_length=32)
p_person = models.OneToOne(Person,ondetele=models.PROTECT)
当然还有其他模式
SETNULL
SET_DEFAULT()
SET()
级联操作
这个东西就是我们刚刚主从表在sql里面的体现,其实也是我们的级联操作。那就是,
这个很好理解那就是班级的ID改了,那么对应的学生的班级ID要不要改,当然这里可以直接在数据库实现,也可以通过代码,不过这里推荐代码实现,也就是把在java里面去做
那么在数据库里面加一个东西就行了
alter table student add constraint fg_class_id foreign key(class_id) references class(id) on delete cascade on update cascade;
慎用!慎用!慎用!默认都是空的,也就是不会有任何操作。
联表查询
这个联表查询其实就是把两张数据表的内容做个整合,其实更加形象一点那就是两张集合之间的交集并集等之间的关系,如果我们把每条查询语句的结果当作集合的话。
这里的话分为三大种,内联,左联,右联。
此外还能细分一下,看下图
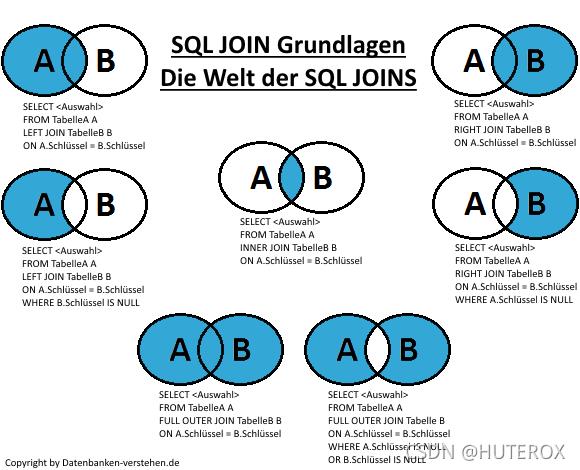
这里我们主要说前面三种,因为其他的无非是在后面加点条件罢了。
这里给个口诀
1.明确需要查询的数据(字段)
2.明确需要从哪几张表里面查询
3.明确筛选条件
下面给个例子。
假设班级里面有个班级 A 它的Id是 1
现在查询A班学生的名字和年龄。
select s.name,s.age
from student as s
inner join class as c
on s.class_id = c.id
where s.id=1;
左/右联表
这个其实还是很简单,但是区别其实就是前面那张图里面的区别。
select s.name,s.age c.name
from student as s
left join class as c
on s.class_id = c.id
where s.id=1;
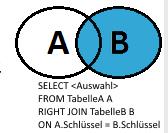
假设有位同学没有分班,也就是没有班级ID那么,此时我们会发现有个c.name的值为空
也就是这样

那么右联也是
其实都是很简单的玩意,但是很重要!
多表联查
这个还是一样的,我们假设现在还有一个表
create table grade(id int primary key auto_increment
grade float,
student_id int,
foreign key(student_id) references student(id) )charset = utf8;
现在我还需要查询出学生姓名,年龄,成绩在A班里面
select name,age,grade
from student as s inner join
class as c on s.class_id = c.id
inner join grade as g
where g.student_id = s.id and c.id=1;
看到了吗,从左到右两两查询的结果为一个左集合
到这里基本的查询就到这里了。想看具体的例子是吧也有
Vue+SpringBoot 前后端分离实战(mybatisplus多表分页查询+博客显示) (现在python,java的例子都有了,下次我看看用Go怎么玩)
你以为这个就结束了吗?NO,NO,到这里你猜学会最基本的使用,后面还有东西呢,这里的话我就一股脑全说了。
范式约束
说人话,设计数据库表的时候,建议遵守的约束,要求,建议。
这里有6大范式
- 第一范式(1NF)
- 第二范式(2NF)
- 第三范式(3NF)
- 巴斯-科德范式(BCNF)
- 第四范式(4NF)
- 第五范式(5NF,又称完美范式)
像我们这个基本上遵从前三个完事。
所以我们聊聊这些范式
- 第一范式(1NF) :每一列都是不可分割的
- 第二范式(2NF) :在1NF的基础上消除对主码的部分函数依赖
- 第三范式(3NF) :在2NF的基础上,任何非主属性不依赖别的主属性
案例
第一范式
首先看这种图就是不满足第一范式的
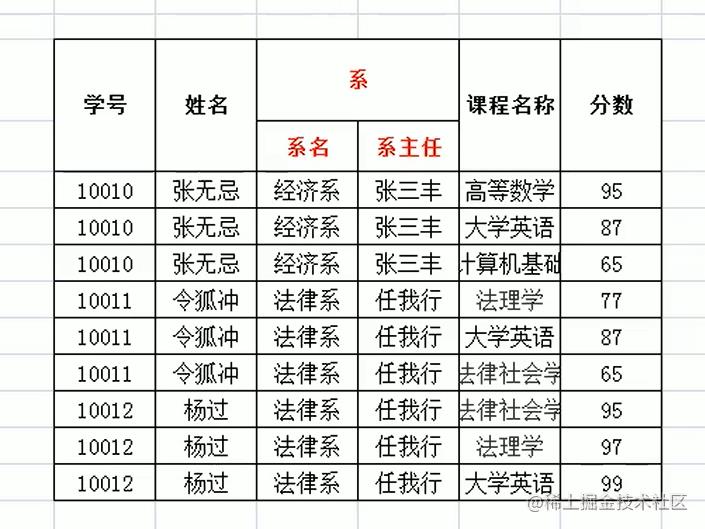
这个列必须是不可拆分的所以得这样改一下

第二范式
这个就比较抽象了,这里得解释清楚函数依赖的问题,例如A–> B
学号 可以 确定姓名
(学号,课程名称)可以确定 分数
用字母表示是
A -> B 部分函数依赖关系
(A,B)->C 完全函数依赖关系
那么这里的码就是我们这里的(A),(A,B)属性组
现在我们想要符合第二范式的话需要把不符合这个完全函数依赖的那个列给拆除,放在别的地方。
于是改造之后是这样的
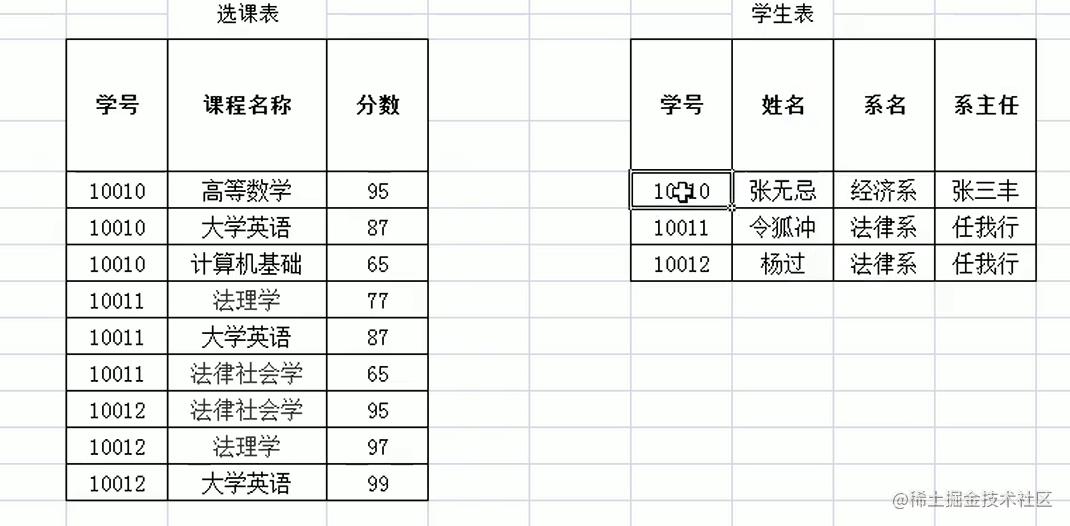
由于 姓名,系名,系主任
在
(A,B)->C 当中只要A,或B满足就成立,所以必须做拆分。
第三范式
在第二范式的基础上,我们把选课表拆了,但是学生表其实还有问题
学号–> 系主任
系名–> 系主任
也就是
A–>C
B–>C
(A,B)->C
出现了先前的问题,所以还得拆
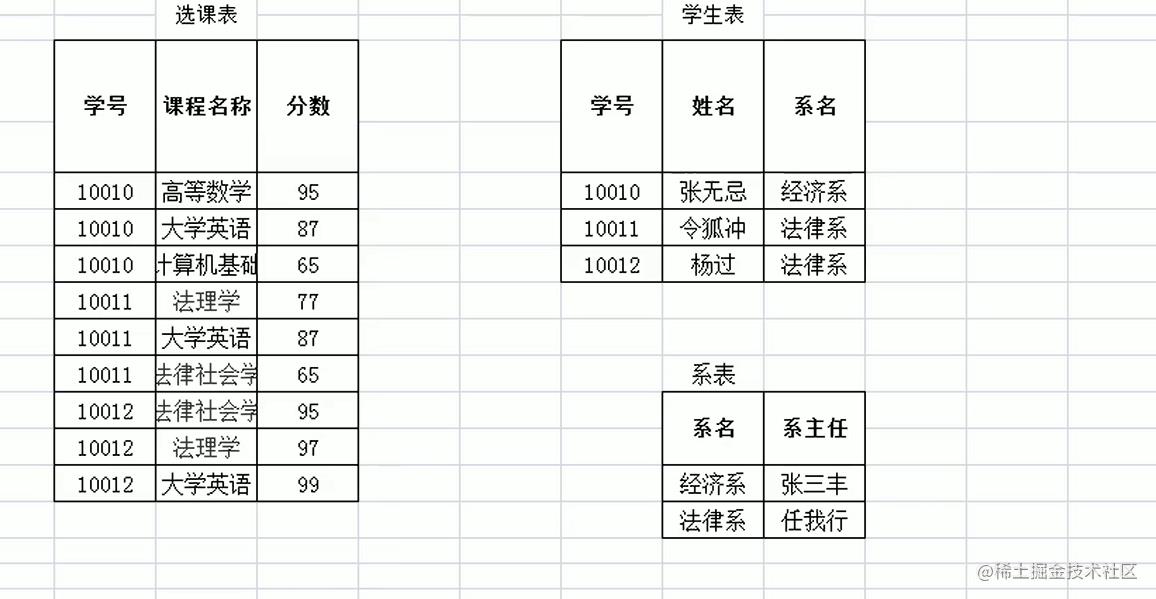
此时看学生表
A,B,C分别表示那个学号,姓名,系名哈
A->B
A->C
B,C 没有关系
拆出来的系表也是
那么这样就满足了第三范式,这个其实说起来很复杂,但是其实我想在设计的时候应该都会考虑一下这方便的问题,不为别的,我可不希望我查用户的时候出现冗余信息,这样又得在代码上处理。
数据库的备份还原
现在在说说这个数据库的备份还原,这个也是有工具或者直接的指令
这个和Redis一样备份的话其实是备份了语句。
mysqldump -u用户名 -p密码 需要备份的数据库 > 路径(保存)
还原
source 你的那个sql文件
那么这个就是数据库的备份还原,其实还是很简单的,那么接下来对于数据库的操作还有几个,一个是那个事务,还有一个是那个视图,还有是那个写sql函数的玩意,最后是我们的DCL,这部分的内容不是很多,绝对不会比DQL复杂。
事务(trans action)
这个事务其实就是原子性操作,就是一些事情不可以分割,例如生孩子这件事情,你得有女朋友,然后才能有老婆,然后才能生孩子(当然没有老婆理论上也是可以的但是你得有个女人,我们按照正常的伦理来说)
这个生孩子,上述环节一个不能少,一但少了,那么这件事情就失败了,那么你又得重头再来,我们叫这个为回滚,所以这个事务就是两部,操作,失败回滚。
(值得一提的是好像在Redis里面的事务是没有回滚的)
这里说说,事务的四大特征,以及事务隔离的东东。
说正紧的,事务是:一系列的事情要么全部成功,要么全部gg。
使用格式:
statrt transaction 开启事务
rollback 回滚
commit 提交
现在我们举个具体的小例子,假设我们有个银行系统,现在要转账(张三,李四,他们的金额都是足够的)
那么我们就先这样
start transaction; 这里使用begin;也是一样的
update account set monery=monery-500 where name='张三';
update account set monery=monery+500 where name='李四';
commit; 如果没有异常提交
rollback; 否则回滚
这里我们再用python演示一下吧。
import pymysql
#建立连接
conn=pymysql.connect(
host='127.0.0.1',port=3306,user='Huterox',
passwd='865989840',db='huterox',charset='utf8'
)
cursor = conn.cursor()
try:
Sqlcomm = """insert into hello(name) value(%s)"""
cursor.execute(Sqlcomm,("小刚"))
conn.commit()#提交
except pymysql.Error as err:
conn.rollback()#回滚
print(err)
finally:
conn.close()
这样就完成了我们的基本事务操作(java太麻烦了,这里直接用python演示)
事务提交细节
这里注意一个点,那就是我们在执行DML语句的时候,MYSQL是自动帮助我们commit了,在Oracle是没有默认的。

你可以设置一下
自己手动提交
set @@autocommit =0;
然后每条语句后面加一个 commit。
事务的四大特征
原子性
最小的不可切分的操作单位,要么全部成功,要么失败全部
持久性
commit rollback 都是持久性的
隔离性
事务之间是相互独立的
一致性
事务操作前后的数据总量不变(A转钱给B,钱的总量不变)
事务的隔离级别
多个事务之间是相互独立的,但是如果多个事务同时操作同一批数据就会发生一些问题,需要设置事务之间的隔离级别来解决问题。
这里会产生如下问题
- 脏读: 一个事务,读取到另一个事务中没有提交到的数据(数据未提交但是有数据缓存)
- 不可重复读(虚读):在同一个事务当中,读取两次的数据都不一样。
- 幻读:一个事务操作(DML)数据表当中的所以记录,另一个事务添加了一条数据,导致第一个查询不了这个修改(漏读了)
在mysql里面提供了四种隔离级别(其实就是多个事务提交的策略,之所以有这个问题其实也是因为我们有多个客户端,可以想象成多线程,此外解决的问题越多,速度就越慢,例如serializable人家是直接把表给锁了)
隔离级别:
- read uncommitted 读未提交
三个问题都会产生的一种策略,但是处理效率最高 - read committed 读取提交后(Oracle默认)
2,3问题解决不了 - repeatable read 可重复的(mysql默认)
幻读解决不了 - serializable 串行话
all 可ok
这些和效率相关联,看你想采取什么策略吧。
级别操作
这个的话就两条指令
查询级别
select @@tx_isolation;
设置
set global transcation isolation level 级别字符串;
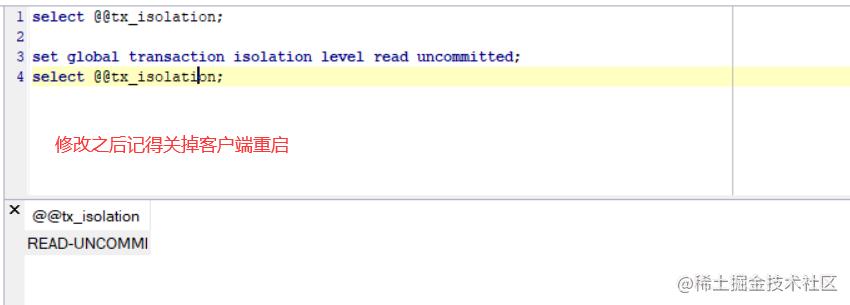
这里的话就不进行演示了,考虑到篇幅的问题,那么后面可以call留言,我在聊聊这个,不然就这样喽~
那么这些就是关于事务的部分
视图
那么接下来就是我们数据库视图的部分喽~这个怎么理解咧,其实就是那啥,保存一下我们的查询结果,这样的话下次可以直接拿过来用,此外还能起到一个权限隔离的作用(在说DCL的时候你就知道了)这个其实也是一个表。
create view 视图名字 as 你的DQL语句;
然后在 show tables;的时候就能简单你创建的view了,这个其实怎么用其实就是一个特殊的表呗,提高一下你的代码效率。但是有个特点,那就是如果原数据发生了改变,那么你的视图表也会发生改变(对应的数据),它是这样的
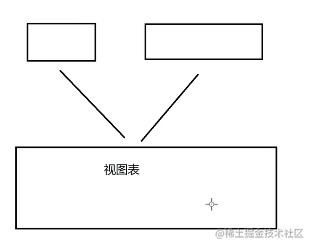
你改视图表原来的联动的表也会被修改。
删除的话,就直接
drop view 视图表名
存储过程
这个就是我们一开始说的如何自己实现聚合函数的玩意了,这玩意(Stored Procedure)是一种在数据库中存储复杂程序,以便外部程序调用的一种数据库对象,存储过程是为了完成特定功能的SQL语句集,经编译创建保存在数据库当中!然后用户调用存储过程的名字进行执行调用。
说白了其实就是相当于函数,不过CURD程序员,这个应该不常用,我是没怎么用过,可能是我的小demo太简单了吧。
在怎么玩之前,我们先来讨论一下,为什么这个sql语句总是 ; 结尾才能运行,我不要这个;结尾行不行。答案是可以的。
delimiter ; 设置;为语句结束符(默认)
delimiter && 设置 && 为语句结束符
好知道了,这个就好办喽。
现在我们手写一个简单的存储过程。
有这样的表
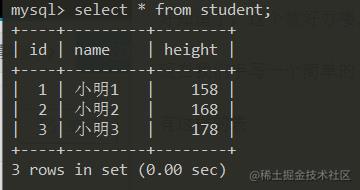
现在我想写一个函数可以直接帮助我查看这个表的信息。
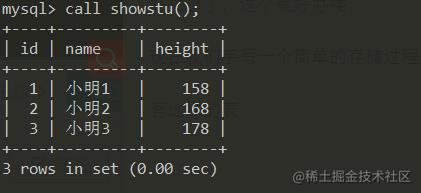
所以我这样干
delimiter &&
create procedure showstu()
begin
select * from student;
end &&
delimiter ;
call showstd();
之后删除的也是
drop procedure showstu;
就行了。
寻找存储过程
这个就简单了
show procedure status like "show%";
而且还支持这个模糊查询

此外
show create procedure showstu;
可以看到里面是啥

可以查看出那个
传参
这样还不行呀,如果我想要获取单独一个同学的信息呢,传递一个id我就能拿到一个信息。这个其实也很简单
我们写一个findbyid()这个函数
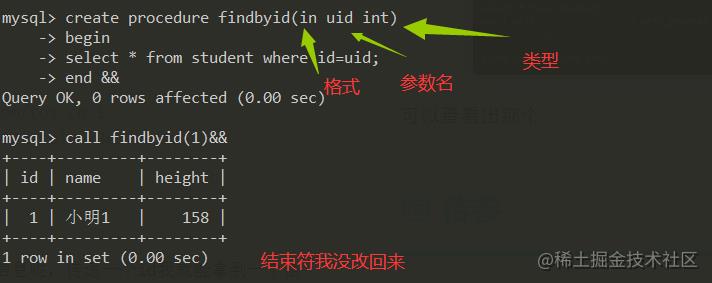
DCL
终于到了我们最后一个喽,这个是我们数据库的管理,权限语句,当然还有用户创建啥的,就比如一开始的那个
mariadb(sql)基本操作
创建用户。
这个主要是给DBA数据库管理人员滴。
这块的内容其实就是我们 mariadb(sql)基本操作 用户操作的内容
用户的创建
创建的基本指令的格式如下:
create users 'usrname'@'指定用户登录的地址' identified by'password';
# 查看用户
select * from mysql.user;
例如:
create users 'Hello'@'localhost' identified by'abc123';
这里的'localhost'是本机IP
'%'则是指任意IP
如果你想要创建以后个可以远程连接的用户的话可以这样
create users 'Hello'@'%' identified by'abc123';
修改用户密码
当不小心忘记密码的话,你可以使用另一个有足够权限的账号登录数据库进行对那个账号的修改.
set password for 'Hello'@'%' = password('abcd123');
用户删除
drop usr 'Hello'@'%';
用户权限
当我们创建一个用户后我们可以通过
show grants for 'Hello'@'localhost';
查看
例如;
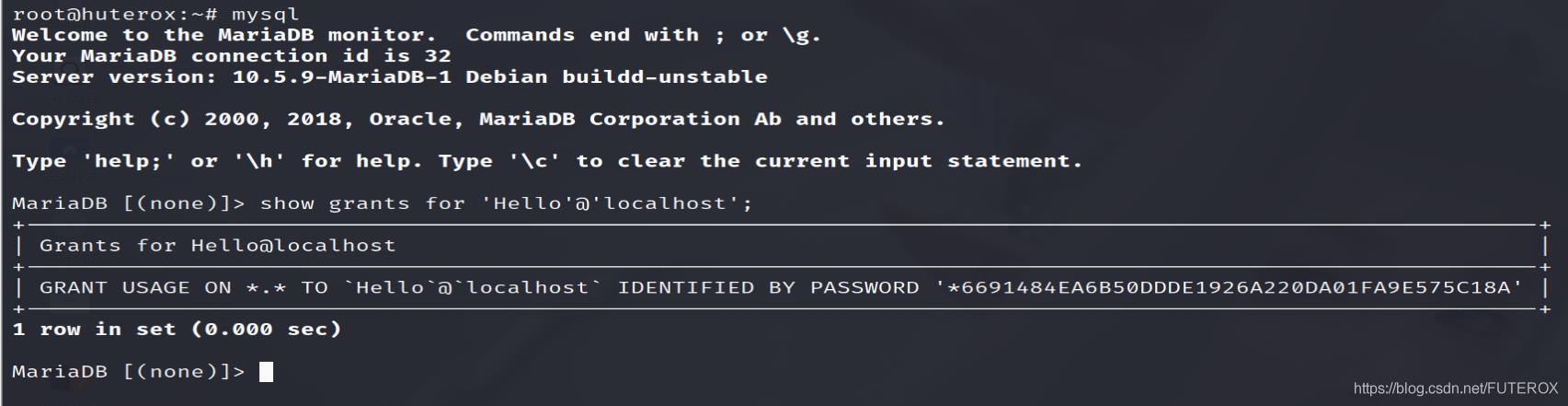
权限修改
先说说有哪些权限;
SELECT
INSERT
CREATE
DELECT
DROP
UPDATE
CRANT OPITON 给予其他用户权限的权限(当别人爸爸的权力)
现在我们给予它除了CREATEOPTION 的权利
grant all privileges on *.* to Hello@localhost;
revoke GRANT OPTION on *.* from Hello@localhost;
flush privileges; 让配置生效

这里我就直接拷过来了。
总结
这个就是我花了一个下午最后总结出来的mysql的基本使用,基本上常用就是这些了,东西还是比较多的,适合拿过来复习用用,或者拿来预习也不错。
以上是关于MySQL基本使用(内容较多建议熟读并背诵)的主要内容,如果未能解决你的问题,请参考以下文章