一致性hash算法深入探究
Posted 赵广陆
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了一致性hash算法深入探究相关的知识,希望对你有一定的参考价值。
目录
1产生背景
负载均衡策略中,我们提到过源地址hash算法,让某些请求固定的落在对应的服务器上。这样可以解决会话信息保留的问题。
同时,标准的hash,如果机器节点数发生变更。那么请求会被重新hash,打破了原始的设计初衷,怎么解决呢?
一致性hash上场。
2 原理探究
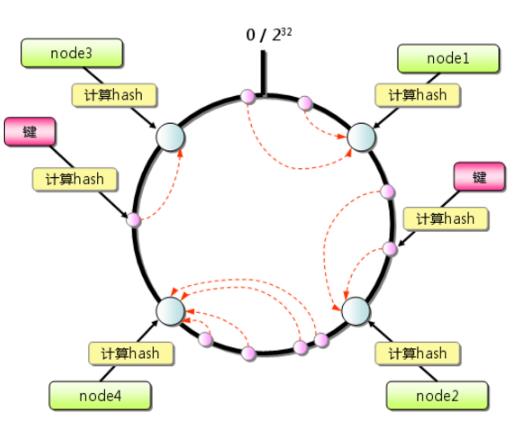
以4台机器为例,一致性hash的算法如下:
首先求出各个服务器的哈希值,并将其配置到0~2 32 的圆上
然后采用同样的方法求出存储数据的键的哈希值,也映射圆上
从数据映射到的位置开始顺时针查找,将数据保存到找到的第一个服务器上
如果到最大值仍然找不到,就取第一个。这就是为啥形象的称之为环
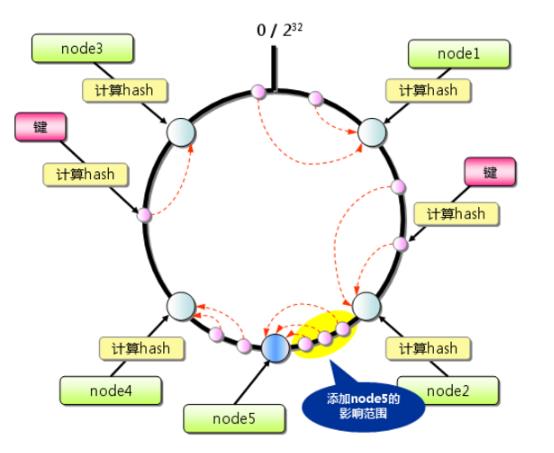
添加节点:
删除节点原理雷同
3 特性
单调性(Monotonicity):单调性是指如果已经有一些请求通过哈希分派到了相应的服务器进行处理,又有新的服务器加入到系统中时候,应保证原有的请求可以被映射到原有的或者新的服务器中去,而不会被映射到原来的其它服务器上去。
分散性(Spread):分布式环境中,客户端请求时可能只知道其中一部分服务器,那么两个客户端看到不同的部
分,并且认为自己看到的都是完整的hash环,那么问题来了,相同的key可能被路由到不同服务器上去。以上图为例,加入client1看到的是1,4;client2看到的是2,3;那么2-4之间的key会被俩客户端重复映射到3,4上去。分散性反应的是这种问题的严重程度。
平衡性(Balance):平衡性是指客户端hash后的请求应该能够分散到不同的服务器上去。一致性hash可以做到尽量分散,但是不能保证每个服务器处理的请求的数量完全相同。这种偏差称为hash倾斜。如果节点的分布算法设计不合理,那么平衡性就会收到很大的影响。
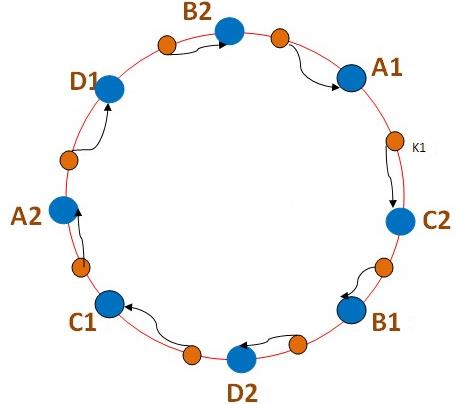
4 优化hash算法
增加虚拟节点可以优化hash算法,使得切段和分布更细化。即实际有m台机器,但是扩充n倍,在环上放置m*n
个,那么均分后,key的段会分布更细化。
5 实现
package com.oldlu.hash;
import java.util.Random;
import java.util.SortedMap;
import java.util.TreeMap;
/**
* 一致性Hash算法
*/
public class Hash
//服务器列表
private static String[] servers = "192.168.0.1",
"192.168.0.2", "192.168.0.3", "192.168.0.4" ;
//key表示服务器的hash值,value表示服务器
private static SortedMap<Integer, String> serverMap = new TreeMap<Integer, String>();
static
for (int i=0; i<servers.length; i++)
int hash = getHash(servers[i]);
//理论上,hash环的最大值为2^32
//这里为做实例,将ip末尾作为上限也就是254
//那么服务器是0‐4,乘以60后可以均匀分布到 0‐254 的环上去
//实际的请求ip到来时,在环上查找即可
hash *= 60;
System.out.println("add " + servers[i] + ", hash=" + hash);
serverMap.put(hash, servers[i]);
//查找节点
private static String getServer(String key)
int hash = getHash(key);
//得到大于该Hash值的所有server
SortedMap<Integer, String> subMap = serverMap.tailMap(hash);
if(subMap.isEmpty())
//如果没有比该key的hash值大的,则从第一个node开始
Integer i = serverMap.firstKey();
//返回对应的服务器
return serverMap.get(i);
else
//第一个Key就是顺时针过去离node最近的那个结点
Integer i = subMap.firstKey();
//返回对应的服务器
return subMap.get(i);
//运算hash值
//该函数可以自由定义,只要做到取值离散即可
//这里取ip地址的最后一节
private static int getHash(String str)
String last = str.substring(str.lastIndexOf(".")+1,str.length());
String last = str.substring(str.lastIndexOf(".")+1,str.length());
return Integer.valueOf(last);
public static void main(String[] args)
//模拟5个随机ip请求
for (int i = 1; i < 8; i++)
String ip = "192.168.1."+ i*30;
System.out.println(ip +" ‐‐‐> "+getServer(ip));
//将5号服务器加到2‐3之间,取中间位置,150
System.out.println("add 192.168.0.5,hash=150");
serverMap.put(150,"192.168.0.5");
//再次发起5个请求
for (int i = 1; i < 8; i++)
String ip = "192.168.1."+ i*30;
System.out.println(ip +" ‐‐‐> "+getServer(ip));
6 验证结果
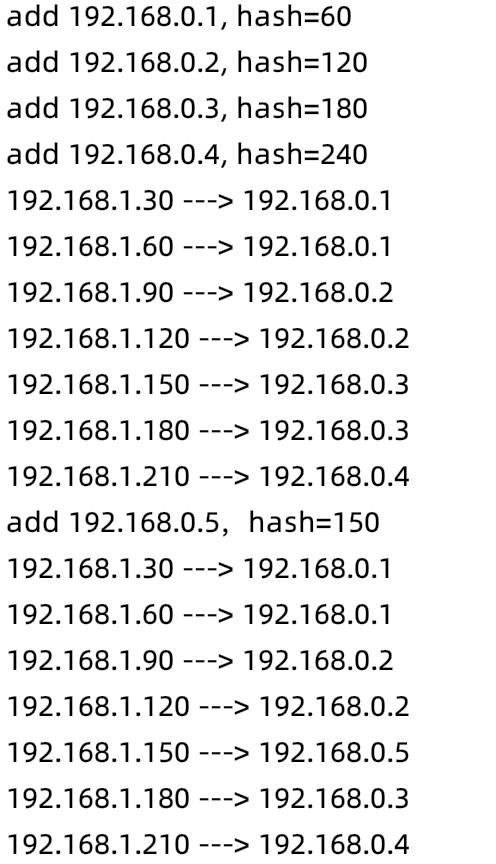
4台机器加入hash环
模拟请求,根据hash值,准确调度到下游节点
添加节点5,key取150
再次发起请求
以上是关于一致性hash算法深入探究的主要内容,如果未能解决你的问题,请参考以下文章