开发规约的意义与细则
Posted 阿里巴巴淘系技术团队官网博客
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了开发规约的意义与细则相关的知识,希望对你有一定的参考价值。

众所周知,制订交通法规表面上是要限制行车权,实际上是保障公众的人身安全。试想如果没有限速,没有红绿灯,没有靠右行驶条款,谁还敢上路。消防局最主要的工作不是灭火,而是为了不发生火灾建立很多规范。如果发生火灾,说明前面的工作没有做到位。同理,对软件来说,开发规约绝不是消灭代码内容的创造性、优雅性,而是限制过度个性化,推行相对标准化,以一种普遍认可的方式一起做事。
综上所述,开发规约的目标:
码出高效:标准统一,提升沟通效率和研发效能。
码出质量:防患未然,提升质量意识和系统可维护性,降低故障率。
码出情怀:工匠精神,追求极致的卓越精神,打磨精品代码。
开发规约从无到有,只是短期的目标;使大家遵守开发规约的成本极大降低,发布上线的应用符合开发规约是中期目标;而远期目标是从有到无,因为人人自觉遵守,规约和谐地融入代码的字里行间,规约似乎消失了,但又无处不在。
最近,结合新品技术团队的现状,分析了系统架构背后的问题,并制定了一系列团队开发规约,可以从以下三方面展开。
大纲
开发规约之道
开发规约之术
开发规约执行方法论
开发规约之道
代码规范不应该被定为 KPI
大部分团队应该都是有KPI的,而且一般重要的事情都会被定成 KPI,所以有些团队为了强调代码规范,将其定为某些员工的KPI,但是这并不能达成好的效果,因为代码规范不应该是一个文档,代码规范应该是一种行为,一种持续的行为,而 KPI是要求可以量化有明确目标的。若把代码规范当KPI,背了KPI的员工为了让KPI可量化,通常情况会写出来一个代码规范文档,众所周知文档最可量化的当然是页数,故最终可能会产出一个几十页的代码规范,几乎面面俱到,看起来很高大上。但是要求大家按照文档落地就很难,让大家理解认可执行它,并且还需要有相应的监督机制、审查机制来保证大家确实按规范在写代码。结合当前团队现状考虑,后者是整个代码规范实施的难点,因为大部分人会赞同:一个被 100% 彻底执行了的 40 分代码规范应该是好于一个被执行了 40%的100分代码规范。
制定代码规范要循序渐进
代码规约的实施不是一蹴而就的,是一个过程,需要团队能够在编写代码过程完全做到规范是需要时间的,所以初期技术有必要在评估项目开发周期中做好时间buffer,后期慢慢形成一种行为意识时,便是做到从无到有的状态。通常情况新项目需求节奏都会非常快,基础框架、基础组件、大批量业务需求要开发,又因为是新项目,通常不会有特别多的人力投入,这种情况下,一个很严格冗长的代码规范,要求大家在拼命跑的过程中还要去理解执行你的规范,可能性大吗?所以这个时期的代码规范需要非常简单易于理解,要在所有人即使在赶需求,也能忍受的范围内制定规范。这个阶段最急迫的需求是用简单的代码规范让大家养成习惯,提升意识,宣告这个项目是有规范的。
制定代码规范要独裁
上面一段提到代码规范应该循序渐进,之前看到过的一种做法是:团队内大家一起讨论,民主决定某一些规范的细节,因为这样可以出来一个适配这个团队的代码规范。
这听起来很美好,非常民主,但是这么做的结果是什么?我猜应该会有很多人又回忆起“大括号应不应该换行”、“else 是否应该换行”、“是否允许空两行”、“JS 结尾带不带分号”等类似的争论,然而这些争论是有必要的吗?说白了,大部分争论找的理由都只是在为自己的代码习惯争取更多空间。这样的争论还只是“民主”引发问题的开始,更严重的是这会在所有开发人员心中形成一种“规范是可以商量和讨论的”心理暗示,这必对后续规范的执行成为阻碍,特别是一些本身就有争议的点。
正因为上述原因,制定规范时需要“独裁”。我们的目标很清晰,就是要求代码写法一致,“独裁”的基础上可以选择一个第三方的标准,例如细的条目可以完全选择集团内部的标准。首先可以保证的是这些规范都是有理有据;其次,“独裁”使用的规范来源于权威的标准体系,对团队内所有人公平;最后,这样的规范和行业更亲近。
开发规约之术
▐ 设计规约
传统分层架构
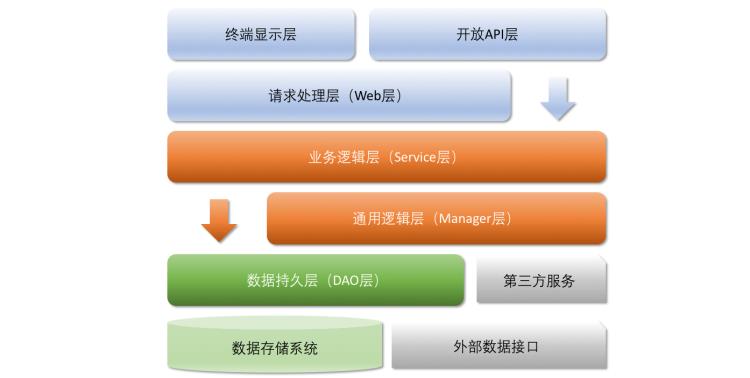
传统分层架构通过Controller,Service,Manager, DAO层来组织业务逻辑,通过贫血模型来传递上下文数据,所有的业务逻辑不需要考虑怎么组织,统统往Manager和Service中写。如果遇到更加复杂的逻辑,那就加一些设计模式来处理(本质还是封装Service和Manager)。这种方式属于面向过程开发的事务脚本模式,该方式在一些比较简单的CRUD场景下比较适用,但当逻辑越来越复杂的时候Manager和Service会越来越膨胀和难以维护。
举个例子,我们使用ServiceItemService(服务项相关服务)来处理服务项相关的逻辑,我们需要维护以下层次:
存储逻辑;
数据转换;
依赖中间件;
各种业务逻辑;
你会发现一个service承担了太多职责,即要与中间件打交道,又要了解存储细节,还要承担各式各样的业务逻辑。当业务逻辑越来越复杂,未来service和manager会变得越来越难以维护。<阿里巴巴Java开发手册>中使用的架构,很难解决以上耦合的问题。
六边形架构
传统分层的问题核心就在于耦合,而面对复杂的业务系统,我们要做的事情就是解耦。
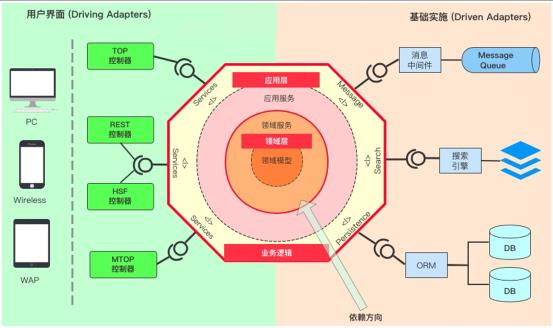
六边形架构将整体的软件系统一分为二,六边形之外是系统的依赖,六边形之内是系统内部需要实现的业务系统,六边形外部是我们与外部系统用户的交互,左边是我们的下游,右边是上游依赖。内外部通过适配器来进行交互和解耦。
六边形架构落地时与传统的分层模型很类似,但是更加明确了不同分层的职责和边界。
代码层次
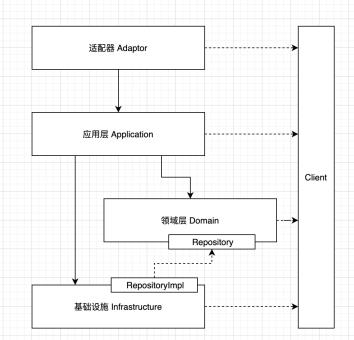
Client层:对外的接口,DTO,Enum等等,是最轻量的包,所有层都可以依赖client,client不应该依赖任何其他层;
Adaptor层:负责对外系统的适配,Controller,HSF,MTOP接口实现都属于这一层;
Application层:Application按照业务场景进行组织,主要负责交互参数的处理(入参校验,出参错误信息转换),领域逻辑的组织编排;
Domain层:封装了核心的业务逻辑,通过领域服务DomainService和领域对象DomainEntity对外提供业务实体对象和计算逻辑。
Infrastructure层:负责外部依赖引入,数据库,外部hsf依赖,cache,mq等等。同时也是领域层与外部系统的防腐层(Anti-Corruption-Layer)。
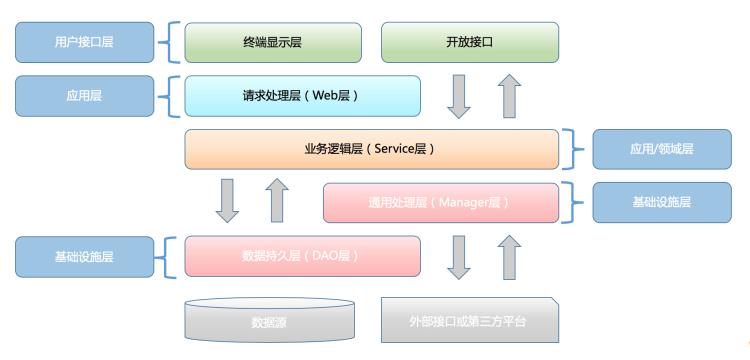
新老分层对比
两者其实非常相似,核心区别在于业务逻辑层新增了领域和应用层,进行了更细化的职责划分。
▐ 异常处理
Java 类库中定义的可以通过预检查方式规避的RuntimeException异常不应该通过catch 的方式来处理,比如:NullPointerException,IndexOutOfBoundsException等等。说明:无法通过预检查的异常除外,比如,在解析字符串形式的数字时,可能数字格式错误,不得不通过catch NumberFormatException来实现。正例:if (obj != null) ...反例:try obj.method() catch (NullPointerException e) …
异常捕获后不要用来做流程控制,条件控制。说明:异常设计的初衷是解决程序运行中的各种意外情况,且异常的处理效率比条件判断方式要低很多。
catch时请分清稳定代码和非稳定代码,稳定代码指的是无论如何不会出错的代码。对于非稳定代码的catch尽可能进行区分异常类型,再做对应的异常处理。说明:对大段代码进行try-catch,使程序无法根据不同的异常做出正确的应激反应,也不利于定位问题,这是一种不负责任的表现。正例:用户注册的场景中,如果用户输入非法字符,或用户名称已存在,或输入密码过于简单,在程序上作出分门别类的判断,并提示给用户。
捕获异常是为了处理它,不要捕获了却什么都不处理而抛弃之,如果不想处理它,请将该异常抛给它的调用者。最外层的业务使用者,必须处理异常,将其转化为用户可以理解的内容。
事务场景中,抛出异常被catch后,如果需要回滚,一定要手动回滚事务。
finally块必须对资源对象、流对象进行关闭,有异常也要做try-catch。说明:如果JDK7,可以使用try-with-resources方式。
不要在finally块中使用return。说明:try块中的return语句执行成功后,并不马上返回,而是继续执行finally块中的语句,如果此处存在return语句,则在此直接返回,无情丢弃掉try块中的返回点。
反例:
private int x = 0; public int checkReturn() try // x等于1,此处不返回 return ++x; finally // 返回的结果是2 return ++x;捕获异常与抛异常,必须是完全匹配,或者捕获异常是抛异常的父类。说明:如果预期对方抛的是绣球,实际接到的是铅球,就会产生意外情况。
方法的返回值可以为null,不强制返回空集合,或者空对象等,必须添加注释充分说明什么情况下会返回null值。说明:本规约明确防止NPE是调用者的责任。即使被调用方法返回空集合或者空对象,对调用者来说,也并非高枕无忧,必须考虑到远程调用失败,运行时异常等场景返回null的情况。
防止NPE,是程序员的基本修养,注意NPE产生的场景:
1) 返回类型为基本数据类型,return包装数据类型的对象时,自动拆箱有可能产生NPE。 反例:public int f() return Integer对象,如果为null,自动解箱抛NPE。 2) 数据库的查询结果可能为null。 3) 集合里的元素即使isNotEmpty,取出的数据元素也可能为null。 4) 远程调用返回对象时,一律要求空指针判断,防止NPE。 5) 对于session中获取的数据,建议进行NPE检查,避免空指针。 6) 级联调用obj.getA().getB().getC();易产生NPE。
▐ 日志规约
应用中不可直接使用日志系统(Log4j、Logback)中的API,而应依赖使用日志框架(SLF4J、JCL--Jakarta Commons Logging)中的API。什么是日志框架和日志系统,请参考webx作者宝宝的文章,文章里也详细说明了为什么不能直接依赖使用日志系统而是日志框架,以及应用的pom中如何做dependencyManagement。说明:日志框架(SLF4J、JCL--Jakarta Commons Logging)的使用方式(推荐使用SLF4J):使用SLF4J:
import org.slf4j.Logger; import org.slf4j.LoggerFactory; private static final Logger logger = LoggerFactory.getLogger(Test.class);在日志输出时,字符串变量之间的拼接使用占位符的方式。说明:因为String字符串的拼接会使用StringBuilder的append()方式,有一定的性能损耗。使用占位符仅是替换动作,可以有效提升性能。正例:
logger.debug("Processing trade with id: and symbol: ", id, symbol);生产环境禁止直接使用System.out 或System.err 输出日志或使用e.printStackTrace()打印异常堆栈。说明:标准日志输出与标准错误输出文件每次Jboss重启时才滚动,如果大量输出送往这两个文件,容易造成文件大小超过操作系统大小限制。
异常信息应该包括两类信息:案发现场信息和异常堆栈信息。如果不处理,那么往上抛。正例:logger.error("inputParams: and errorMessage:", 各类参数或者对象toString(), e.getMessage(), e);
日志打印时禁止直接用JSON工具将对象转换成String。说明:如果对象里某些get方法被覆写,存在抛出异常的情况,则可能会因为打印日志而影响正常业务流程的执行。正例:打印日志时仅打印出业务相关属性值或者调用其对象的toString()方法。
谨慎地记录日志。生产环境禁止输出debug日志;有选择地输出info日志;如果使用warn来记录刚上线时的业务行为信息,一定要注意日志输出量的问题,避免把服务器磁盘撑爆,并记得及时删除这些观察日志。说明:大量地输出无效日志,不利于系统性能提升,也不利于快速定位错误点。记录日志时请思考:这些日志真的有人看吗?看到这条日志你能做什么?能不能给问题排查带来好处?
▐ 日志规约
建表规约
表达是与否概念的字段,必须使用is_xxx的方式命名,数据类型是unsigned tinyint(1表示是,0表示否),此规则同样适用于odps建表。说明:任何字段如果为非负数,必须是unsigned。注意:POJO类中的任何布尔类型的变量,都不要加is前缀,所以,需要在<resultMap>设置从is_xxx到xxx的映射关系。数据库表示是与否的值,使用tinyint类型,坚持is_xxx的命名方式是为了明确其取值含义与取值范围。正例:表达逻辑删除的字段名is_deleted,1表示删除,0表示未删除。
表名、字段名必须使用小写字母或数字,字段命名可参考附2;禁止出现数字开头,禁止两个下划线中间只出现数字。数据库字段名的修改代价很大,因为无法进行预发布,所以字段名称需要慎重考虑。说明:mysql在Windows下不区分大小写,但在Linux下默认是区分大小写。因此,数据库名、表名、字段名,都不允许出现任何大写字母,避免节外生枝。正例:getter_admin,task_config,level3_name反例:GetterAdmin,taskConfig,level_3_name
表名不使用复数名词。说明:表名应该仅仅表示表里面的实体内容,不应该表示实体数量,对应于DO类名也是单数形式,符合表达习惯。
保留字,如desc、range、match、delayed等,参考官方保留字
唯一索引名为uk_字段名;普通索引名则为idx_字段名。说明:uk_ 即 unique key;idx_ 即index的简称。
小数类型为decimal,禁止使用float和double。说明:在存储的时候,float 和 double 都存在精度损失的问题,很可能在比较值的时候,得到不正确的结果。如果存储的数据范围超过 decimal 的范围,建议将数据拆成整数和小数并分开存储。
如果存储的字符串长度几乎相等,使用CHAR定长字符串类型。
varchar是可变长字符串,不预先分配存储空间,长度不要超过5000,如果存储长度大于此值,定义字段类型为TEXT,独立出来一张表,用主键来对应,避免影响其它字段索引效率。
表必备三字段:id, gmt_create, gmt_modified。说明:其中id必为主键,类型为bigint unsigned、单表时自增、步长为1;分表时改为从TDDL Sequence取值,确保分表之间的全局唯一。gmt_create, gmt_modified的类型均为date_time类型,前者现在时表示主动式创建,后者过去分词表示被动式更新。
表的命名最好是遵循“业务名称_表的作用”,避免上云梯后,再与其它业务表关联时有混淆。正例:tiger_task / tiger_reader / force_codereview
库名与应用名称尽量一致。
如果修改字段含义或对字段表示的状态追加时,需要及时更新字段注释。
SQL规约
不要使用count(列名)或count(常量)来替代count(*),count(*)就是SQL92定义的标准统计行数的语法,跟数据库无关,跟NULL和非NULL无关。说明:count(*)会统计值为NULL的行,而count(列名)不会统计此列为NULL值的行。
count(distinct col) 计算该列除NULL之外的不重复数量。注意 count(distinct col1, col2) 如果其中一列全为NULL,那么即使另一列有不同的值,也返回为0。
当某一列的值全是NULL时,count(col)的返回结果为0,但sum(col)的返回结果为NULL,因此使用sum()时需注意NPE问题。正例:可以使用如下方式来避免sum的NPE问题:SELECT IFNULL(SUM(column), 0) FROM table;
对于数据库中表记录的查询和变更,只要涉及多个表,都需要在列名前加表的别名(或表名)进行限定。说明:对多表进行查询记录、更新记录、删除记录时,如果对操作列没有限定表的别名(或表名),并且操作列在多个表中存在时,就会抛异常。正例:select t1.name from table_first as t1 , table_second as t2 where t1.id=t2.id;反例:在飞猪某业务中,由于多表关联查询语句没有加表的别名(或表名)的限制,正常运行两年后,最近在某个表中增加一个同名字段,在预发布环境做数据库变更后,线上查询语句出现出1052异常:Column 'name' in field list is ambiguous,导致票务交易下跌。
在代码中写分页查询逻辑时,若count为0应直接返回,避免执行后面的分页语句。
不得使用外键与级联,一切外键概念必须在应用层解决。说明:(概念解释)学生表中的student_id是主键,那么成绩表中的student_id则为外键。如果更新学生表中的student_id,同时触发成绩表中的student_id更新,则为级联更新。外键与级联更新适用于单机低并发,不适合分布式、高并发集群;级联更新是强阻塞,存在数据库更新风暴的风险;外键影响数据库的插入速度。
禁止使用存储过程,存储过程难以调试和扩展,更没有移植性。
IDB数据订正(特别是删除或修改记录操作)时,要先select,避免出现误删除,确认无误才能提交执行。
SQL语句中表的别名前加as,并且以t1、t2、t3、...的顺序依次命名。说明:1)别名可以是表的简称,或者依据表在SQL语句中出现的顺序,以t1、t2、t3的方式命名。2)别名前加as使别名更容易识别。正例:select t1.name from table_first as t1, table_second as t2 where t1.id=t2.id;
in操作能避免则避免,若实在避免不了,需要仔细评估in后边的集合元素数量,控制在1000个之内。
因国际化需要,所有的字符存储与表示,均采用utf8字符集,那么字符计数方法注意:说明:SELECT LENGTH("阿里巴巴");返回为12SELECT CHARACTER_LENGTH("阿里巴巴");返回为4如果需要存储表情,那么选择utf8mb4来进行存储,注意它与utf8编码的区别。
▐ ORM规约
在表查询中,一律不要使用 * 作为查询的字段列表,需要哪些字段必须明确写明。说明:1)增加查询分析器解析成本。2)增减字段容易与resultMap配置不一致。3)多余字段增加网络消耗,尤其是 text 类型的字段。
POJO类的布尔属性不能加is,而数据库字段必须加is_,要求在resultMap中进行字段与属性之间的映射。说明:参见定义POJO类以及数据库字段定义规定,在sql.xml增加映射,是必须的。
不要用resultClass当返回参数,即使所有类属性名与数据库字段一一对应,也需要定义;反过来,每一个表也必然有一个与之对应。说明:配置映射关系,使字段与DO类解耦,方便维护。
sql.xml配置中参数注意:#,#param# 不要使用$ 此种方式容易出现SQL注入。
iBATIS自带的queryForList(String statementName,int start,int size)不推荐使用。说明:其实现方式是在数据库取到statementName对应的SQL语句的所有记录,再通过subList取start,size的子集合,线上因为这个原因曾经出现过OOM。正例:在sqlmap.xml中引入 #start#, #size#
Map<String, Object> map = new HashMap<>(16); map.put("start", start); map.put("size", size);不允许直接拿HashMap与HashTable作为查询结果集的输出。反例:某同学为避免写一个xxx,直接使用HashTable来接收数据库返回结果,结果出现日常是把bigint转成Long值,而线上由于数据库版本不一样,解析成BigInteger,导致线上问题。
更新数据表记录时,必须同时更新记录对应的gmt_modified字段值为当前时间。
▐ 注释规约
注释的双斜线与注释内容之间有且仅有一个空格。正例:
// 这是示例注释,请注意在双斜线之后有一个空格 String commentString = new String();类、类属性、类方法的注释必须使用javadoc规范,使用/**内容*/格式,不得使用//xxx方式。说明:在IDE编辑窗口中,javadoc方式会提示相关注释,生成javadoc可以正确输出相应注释;在IDE中,工程调用方法时,不进入方法即可悬浮提示方法、参数、返回值的意义,提高阅读效率。
所有的抽象方法(包括接口中的方法)必须要用javadoc注释、除了返回值、参数、异常说明外,还必须指出该方法做什么事情,实现什么功能。说明:对子类的实现要求,或者调用注意事项,请一并说明。
所有的类都必须添加创建者信息和创建日期。说明:在设置模板时,注意IDEA的@author为$USER,而eclipse的@author为$user,大小写有区别,而日期的设置统一为yyyy/MM/dd的格式。
正例:
/**
@author wangchen(一律用花名)
@date 2016/10/31 (yyyy/MM/dd)
*/
方法内部单行注释,在被注释语句上方另起一行,使用//注释。方法内部多行注释使用/ /注释,注意与代码对齐。
所有的枚举类型字段必须要有注释,说明每个数据项的用途。
代码修改的同时,注释也要进行相应的修改,尤其是参数、返回值、异常、核心逻辑等的修改。说明:代码与注释更新不同步,就像路网与导航软件更新不同步一样,如果导航软件严重滞后,就失去了导航的意义。
在类中,删除未使用的任何字段和方法;在方法中,删除未使用的任何参数声明与内部变量。
对于注释的要求:第一、能够准确反映设计思想和代码逻辑;第二、能够描述业务含义,使别的程序员能够迅速了解到代码背后的信息。完全没有注释的大段代码对于阅读者形同天书,注释是给自己看的,即使隔很长时间,也能清晰理解当时的思路;注释也是给继任者看的,使其能够快速接替自己的工作。
接口文档规约
公共统一:统一返回的response格式,比如使用CommonResult,统一返回的错误码
联调地址:测试环境地址,预发环境地址,生产环境地址;
接口规约:接口名称,接口路径,请求方式,请求入参(名称,类型,是否空,字段描述),请求入参样例,返回参数(名称,类型,字段描述),返回参数样例;
开发测试联调流程:日常环境 -> 预发环境 -> 生产环境,数据库同步环境:日常dev -> 预发 -> 生产
开发规约执行方法论
以上开发规约是基于《阿里巴巴 Java 开发手册》整理的特殊化需求,虽然《手册》是阿里巴巴集团技术团队的集体智慧结晶和经验总结, 经历了多次大规模一线实战的检验及不断完善,系统化地整理成册。当然,规范只能提供参考,我们还需要工具来帮忙我们实现了实时检测。
▐ 团队间项目的代码复查
在项目上线之前,在前端团队联调之后,在测试团队测试主体流程通过后,可以展开团队间相互code review,这个过程时间控制在半天左右。比如当前项目由主coder开发,可以由其他项目成员review,反过来同理。这种方法相对消耗时间成本,当然也有接下来这种方式。
▐ 使用插件工具复查
目前,Alibaba Java Code Guidelines 插件实现了开发手册中的的 53 条规则,大部分基于 PMD 实现,其中有 4 条规则基于 IDEA 实现,并且基于 IDEA Inspection 实现了实时检测功能。部分规则实现了 Quick Fix 功能。目前,插件检测有两种模式:实时检测、手动触发。
IDEA 插件地址:https://plugins.jetbrains.com/plugin/10046-alibaba-java-coding-guidelines
插件检查结果说明:
Blocker 、Critical 、Major 错误等级说明
Blocker: 即系统无法执行、崩溃或严重资源不足、应用模块无法启动或异常退出、无法测试、造成系统不稳定。
严重花屏
内存泄漏
用户数据丢失或破坏
系统崩溃/死机/冻结
模块无法启动或异常退出
严重的数值计算错误
功能设计与需求严重不符
其它导致无法测试的错误, 如服务器500错误
Critical:即影响系统功能或操作,主要功能存在严重缺陷,但不会影响到系统稳定性。
功能未实现
功能错误
系统刷新错误
数据通讯错误
轻微的数值计算错误
影响功能及界面的错误字或拼写错误
安全性问题
Major:即界面、性能缺陷、兼容性。
操作界面错误(包括数据窗口内列名定义、含义是否一致)
边界条件下错误
提示信息错误(包括未给出信息、信息提示错误等)
长时间操作无进度提示
系统未优化(性能问题)
光标跳转设置不好,鼠标(光标)定位错误
兼容性问题
Minor/Trivial:即易用性及建议性问题。
界面格式等不规范
辅助说明描述不清楚
操作时未给用户提示
可输入区域和只读区域没有明显的区分标志
个别不影响产品理解的错别字
文字排列不整齐等一些小问题
总结:Blocker > Critical > Major > Minor > Trivial
Blocker,Critical是必须要修改的,Major根据具体建议情况参考处理,Minor和Trivial可以根据建议情况修补或者不修补。
▐ 常见插件一览
快捷键提示工具:Key promoter X
Key Promoter X 是一个快捷键提示插件,如果鼠标操作是能够用快捷键替代,Key Promoter X 会提示可以用什么快捷键替代。详细使用文档,参考:https://plugins.jetbrains.com/plugin/9792-key-promoter-x
代码注解插件:Lombok
lombok 的使用,参考 :https://projectlombok.org/。我们需要在代码中引入二方库,然后安装 lombok 插件即可。
代码生成工具:CodeMaker
开发过程中,经常手工编写重复代码。现在,可以通过 CodeMaker 来定义 Velocity 模版来支持自定义代码模板来生成代码。目前,CodeMaker 自带两个模板。Model:根据当前类生成一个与其拥有类似属性的类,用于自动生成持久类对应的领域类。Converter:该模板需要两个类作为输入的上下文,用于自动生成领域类与持久类的转化类。详细使用文档,参考:https://github.com/x-hansong/CodeMaker
单元测试测试生成工具:JUnitGenerator
单元测试是必不可少的!我们可以使用 JUnitGenerator 插件来自动创建了单元测试。我们可以使用提供的 velocity 模板定制单元测试输出代码。如果在已经存在单元测试的地方创建了单元测试,则会提示用户进行覆盖或合并操作。合并操作允许用户有选择地创建目标文件内容。详细使用文档,参考:https://plugins.jetbrains.com/plugin/3064-junitgenerator-v2-0
Mybatis 工具:Free Mybatis plugin
现在,MyBatis 框架已占领半壁江山。因此,围绕着 MyBatis 的插件和工具越来越多。Free Mybatis plugin 非常方便进行 Mapper 接口和 XML 文件之间跳转。详细使用文档,参考:
https://plugins.jetbrains.com/plugin/8321-free-mybatis-plugin。此外,收费版的还有 Mybatis plugin。
Maven辅助神器:Maven Helper
如果 Maven 引入的 jar 包有冲突,可以使用 Maven Helper 插件来帮助分析。详细使用文档,参考:https://plugins.jetbrains.com/plugin/7179-maven-helper
JSON转领域对象工具:GsonFormat
在开发过程中,我们可能会遇到 json 格式的字符串转换成实体类参数的场景,这个插件可以根据 JSONObject 格式的字符串,自动生成实体类参数。详细使用文档,参考:https://github.com/zzz40500/GsonFormat
领域对象转JSON工具:POJO to JSON
为了测试需要,我们需要将简单 Java 领域对象转成 JSON 字符串方便用 postman 或者 curl 模拟数据。详细使用文档,参考:https://plugins.jetbrains.com/plugin/9686-pojo-to-json
时序图生成工具:SequenceDiagram
有的时候,我们需要梳理业务逻辑或者阅读源码。从中,我们需要了解整个调用链路,反向生成 UML 的时序图是强需求。其中,SequenceDiagram 插件是一个非常棒的插件。详细使用文档,参考:https://plugins.jetbrains.com/plugin/8286-sequencediagram
字符串工具:String Manipulation
String Manipulation 插件提供了非常丰富字符串工具,例如命名替换( (camelCase, kebab-lowercase, KEBAB-UPPERCASE, snakecase, SCREAMINGSNAKE_CASE, dot.case, words lowercase, Words Capitalized, PascalCase)等。详细使用文档,参考:https://plugins.jetbrains.com/plugin/2162-string-manipulation
代码作色工具:Rainbow Brackets
Rainbow Brackets 插件可以实现配对括号相同颜色,并且实现选中区域代码高亮的功能。详细使用文档,参考:https://plugins.jetbrains.com/plugin/10080-rainbow-brackets
日志工具:Grep Console
参考:https://plugins.jetbrains.com/plugin/7125-grep-console
不同级别日志通过颜色区分,一路了然。
Redis可视化:Iedis
参考:https://plugins.jetbrains.com/plugin/9228-iedis 使用参考:https://codesmagic.com/iedis/userguide/getting-started 可方便的执行增删查改及使用命令行进行操作。
中英文翻译工具:Translation
最骚的操作是什么?帆哥在群里分享了一套「半中文编程」:说到了变量命名,先用中文写好,然后用 Translation 插件的 translate and replace 一键替换为英文,这样效率高而且准确。详细使用文档,参考:https://plugins.jetbrains.com/plugin/8579-translation
▐ 代码Review表格追踪
应用 | 具体业务 | 开发人 | Review人 | Review结果/建议 | Review日期 |
the-matrix | 价格段洞察 | 开发人 | 组长 | 省略 | 省略 |
团队介绍
新品平台,打造新品全链路数智化引擎,致力于构建新品全链路的数字化工具和智能化驱动品牌创新的技术体系,围绕新品从市场研究、到产品研发、再到上市打爆的全生命周期,基于全域数据洞察,联动产业生态,通过全链路的数据驱动、用户共创和生态协同,帮助商家全面提升新品全链路效率和新品成功率,带动规模优质新供给的创造和孵化,打造新品一站式孵化中心。
✿ 拓展阅读


作者|望沉
编辑|橙子君
出品|阿里巴巴新零售淘系技术


以上是关于开发规约的意义与细则的主要内容,如果未能解决你的问题,请参考以下文章