六十三Spark-读取数据并写入数据库
Posted 托马斯-酷涛
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了六十三Spark-读取数据并写入数据库相关的知识,希望对你有一定的参考价值。
支持的数据源-JDBC
需求说明:使用Spark流式计算 将数据写入mysql,并读取数据库信息进行打印
文章目录
项目主体架构
pom.xml依赖
<?xml version="1.0" encoding="UTF-8"?> <project xmlns="http://maven.apache.org/POM/4.0.0" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd"> <modelVersion>4.0.0</modelVersion> <groupId>cn.itcast</groupId> <artifactId>SparkDemo</artifactId> <version>1.0-SNAPSHOT</version> <repositories> <repository> <id>aliyun</id> <url>http://maven.aliyun.com/nexus/content/groups/public/</url> </repository> <repository> <id>apache</id> <url>https://repository.apache.org/content/repositories/snapshots/</url> </repository> <repository> <id>cloudera</id> <url>https://repository.cloudera.com/artifactory/cloudera-repos/</url> </repository> </repositories> <properties> <encoding>UTF-8</encoding> <maven.compiler.source>1.8</maven.compiler.source> <maven.compiler.target>1.8</maven.compiler.target> <scala.version>2.12.11</scala.version> <spark.version>3.0.1</spark.version> <hadoop.version>2.7.5</hadoop.version> </properties> <dependencies> <!--依赖Scala语言--> <dependency> <groupId>org.scala-lang</groupId> <artifactId>scala-library</artifactId> <version>$scala.version</version> </dependency> <!--SparkCore依赖--> <dependency> <groupId>org.apache.spark</groupId> <artifactId>spark-core_2.12</artifactId> <version>$spark.version</version> </dependency> <!-- spark-streaming--> <dependency> <groupId>org.apache.spark</groupId> <artifactId>spark-streaming_2.12</artifactId> <version>$spark.version</version> </dependency> <!--spark-streaming+Kafka依赖--> <dependency> <groupId>org.apache.spark</groupId> <artifactId>spark-streaming-kafka-0-10_2.12</artifactId> <version>$spark.version</version> </dependency> <!--SparkSQL依赖--> <dependency> <groupId>org.apache.spark</groupId> <artifactId>spark-sql_2.12</artifactId> <version>$spark.version</version> </dependency> <!--SparkSQL+ Hive依赖--> <dependency> <groupId>org.apache.spark</groupId> <artifactId>spark-hive_2.12</artifactId> <version>$spark.version</version> </dependency> <dependency> <groupId>org.apache.spark</groupId> <artifactId>spark-hive-thriftserver_2.12</artifactId> <version>$spark.version</version> </dependency> <!--StructuredStreaming+Kafka依赖--> <dependency> <groupId>org.apache.spark</groupId> <artifactId>spark-sql-kafka-0-10_2.12</artifactId> <version>$spark.version</version> </dependency> <!-- SparkMlLib机器学习模块,里面有ALS推荐算法--> <dependency> <groupId>org.apache.spark</groupId> <artifactId>spark-mllib_2.12</artifactId> <version>$spark.version</version> </dependency> <dependency> <groupId>org.apache.hadoop</groupId> <artifactId>hadoop-client</artifactId> <version>2.7.5</version> </dependency> <dependency> <groupId>com.hankcs</groupId> <artifactId>hanlp</artifactId> <version>portable-1.7.7</version> </dependency> <dependency> <groupId>mysql</groupId> <artifactId>mysql-connector-java</artifactId> <version>8.0.23</version> </dependency> <dependency> <groupId>redis.clients</groupId> <artifactId>jedis</artifactId> <version>2.9.0</version> </dependency> <dependency> <groupId>com.alibaba</groupId> <artifactId>fastjson</artifactId> <version>1.2.47</version> </dependency> <dependency> <groupId>org.projectlombok</groupId> <artifactId>lombok</artifactId> <version>1.18.2</version> <scope>provided</scope> </dependency> </dependencies> <build> <sourceDirectory>src/main/scala</sourceDirectory> <plugins> <!-- 指定编译java的插件 --> <plugin> <groupId>org.apache.maven.plugins</groupId> <artifactId>maven-compiler-plugin</artifactId> <version>3.5.1</version> </plugin> <!-- 指定编译scala的插件 --> <plugin> <groupId>net.alchim31.maven</groupId> <artifactId>scala-maven-plugin</artifactId> <version>3.2.2</version> <executions> <execution> <goals> <goal>compile</goal> <goal>testCompile</goal> </goals> <configuration> <args> <arg>-dependencyfile</arg> <arg>$project.build.directory/.scala_dependencies</arg> </args> </configuration> </execution> </executions> </plugin> <plugin> <groupId>org.apache.maven.plugins</groupId> <artifactId>maven-surefire-plugin</artifactId> <version>2.18.1</version> <configuration> <useFile>false</useFile> <disableXmlReport>true</disableXmlReport> <includes> <include>**/*Test.*</include> <include>**/*Suite.*</include> </includes> </configuration> </plugin> <plugin> <groupId>org.apache.maven.plugins</groupId> <artifactId>maven-shade-plugin</artifactId> <version>2.3</version> <executions> <execution> <phase>package</phase> <goals> <goal>shade</goal> </goals> <configuration> <filters> <filter> <artifact>*:*</artifact> <excludes> <exclude>META-INF/*.SF</exclude> <exclude>META-INF/*.DSA</exclude> <exclude>META-INF/*.RSA</exclude> </excludes> </filter> </filters> <transformers> <transformer implementation="org.apache.maven.plugins.shade.resource.ManifestResourceTransformer"> <mainClass></mainClass> </transformer> </transformers> </configuration> </execution> </executions> </plugin> </plugins> </build> </project>注:pom依赖在业务实施中是极其重要的一环,相当于配置文件,例如可能需要的 jar 包,可能需要的 Scala 语言版本都在此处进行配置 等等
创建数据库
CREATE TABLE `data` (
`id` int(11) NOT NULL AUTO_INCREMENT,
`name` varchar(255) DEFAULT NULL,
`age` int(11) DEFAULT NULL,
PRIMARY KEY (`id`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8;业务逻辑
1、创建本地环境,并设置日志提示级别
val conf: SparkConf = new SparkConf().setAppName("spark").setMaster("local[*]") val sc: SparkContext = new SparkContext(conf) sc.setLogLevel("WARN")2、加载数据,创建RDD
val dataRDD: RDD[(String, Int)] = sc.makeRDD(List(("tuomasi", 21), ("孙悟空", 19), ("猪八戒", 20)))3、分区迭代
dataRDD.foreachPartition(iter => )4、加载驱动
val conn: Connection = DriverManager.getConnection("jdbc:mysql://localhost:3306/bigdata?characterEncoding=UTF-8", "root", "123456")5、封装SQL语句
val sql: String = "INSERT INTO `data` (`id`, `name`, `age`) VALUES (NULL, ?, ?);" val ps: PreparedStatement = conn.prepareStatement(sql)6、数据处理
iter.foreach(t => //t就表示每一条数据 val name: String = t._1 val age: Int = t._2 ps.setString(1, name) ps.setInt(2, age) ps.addBatch() ) ps.executeBatch()7、关闭连接
if (conn != null) conn.close() if (ps != null) ps.close()8、读取数据库
val getConnection = () => DriverManager.getConnection("jdbc:mysql://localhost:3306/bigdata?characterEncoding=UTF-8", "root", "123456")9、SQL语句上下界设定以及分区数设置
val studentTupleRDD: JdbcRDD[(Int, String, Int)] = new JdbcRDD[(Int, String, Int)]( sc, getConnection, sql, 1, //id为1~20之间的记录进行提取 20, 1, mapRow )10、结果集处理函数
val mapRow: ResultSet => (Int, String, Int) = (r: ResultSet) => val id: Int = r.getInt("id") val name: String = r.getString("name") val age: Int = r.getInt("age") (id, name, age)11、遍历打印数据
studentTupleRDD.foreach(println)
完整代码
package org.example.spark import java.sql.Connection, DriverManager, PreparedStatement, ResultSet import org.apache.spark.rdd.JdbcRDD, RDD import org.apache.spark.SparkConf, SparkContext object RDD_DataSource def main(args: Array[String]): Unit = //TODO 0.env/创建环境 val conf: SparkConf = new SparkConf().setAppName("spark").setMaster("local[*]") val sc: SparkContext = new SparkContext(conf) sc.setLogLevel("WARN") //TODO 1.source/加载数据/创建RDD //RDD[(姓名, 年龄)] val dataRDD: RDD[(String, Int)] = sc.makeRDD(List(("tuomasi", 21), ("孙悟空", 19), ("猪八戒", 20))) //TODO 2.transformation //TODO 3.sink/输出 //需求:将数据写入到MySQL,再从MySQL读出来 dataRDD.foreachPartition(iter => //加载驱动 val conn: Connection = DriverManager.getConnection("jdbc:mysql://localhost:3306/bigdata?characterEncoding=UTF-8", "root", "123456") val sql: String = "INSERT INTO `data` (`id`, `name`, `age`) VALUES (NULL, ?, ?);" val ps: PreparedStatement = conn.prepareStatement(sql) iter.foreach(t => //t就表示每一条数据 val name: String = t._1 val age: Int = t._2 ps.setString(1, name) ps.setInt(2, age) ps.addBatch() //ps.executeUpdate() ) ps.executeBatch() //关闭连接 if (conn != null) conn.close() if (ps != null) ps.close() ) // //从MySQL读取 val getConnection = () => DriverManager.getConnection("jdbc:mysql://localhost:3306/bigdata?characterEncoding=UTF-8", "root", "123456") val sql: String = "select id,name,age from data where id >= ? and id <= ?" val mapRow: ResultSet => (Int, String, Int) = (r: ResultSet) => val id: Int = r.getInt("id") val name: String = r.getString("name") val age: Int = r.getInt("age") (id, name, age) val studentTupleRDD: JdbcRDD[(Int, String, Int)] = new JdbcRDD[(Int, String, Int)]( sc, getConnection, sql, 1, 20, 1, mapRow ) studentTupleRDD.foreach(println)
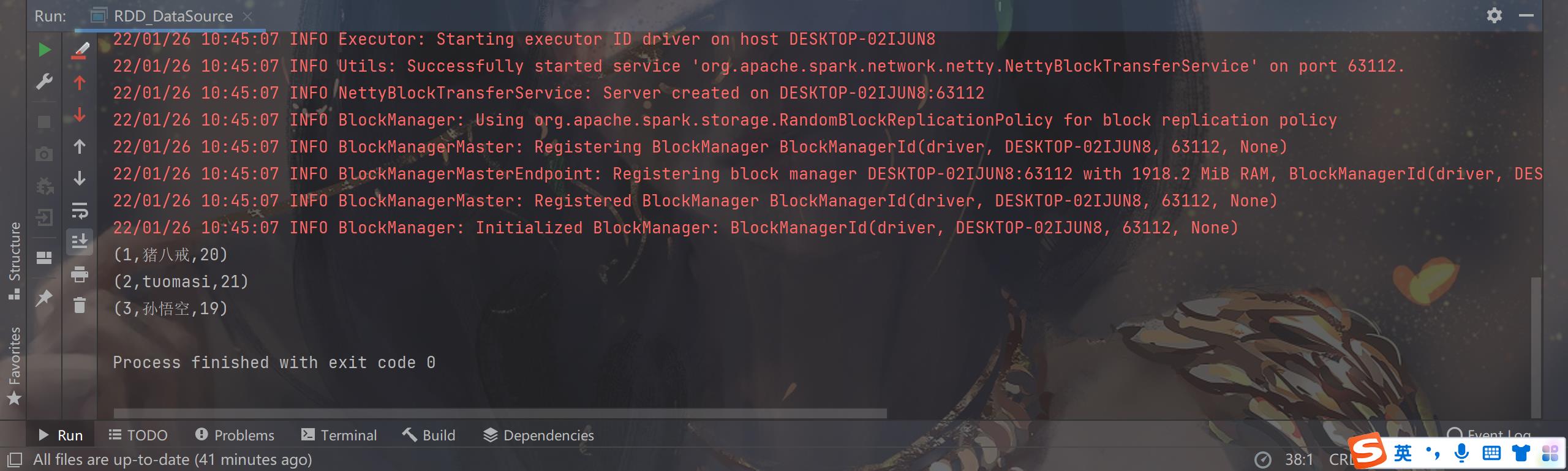
程序运行
控制台打印
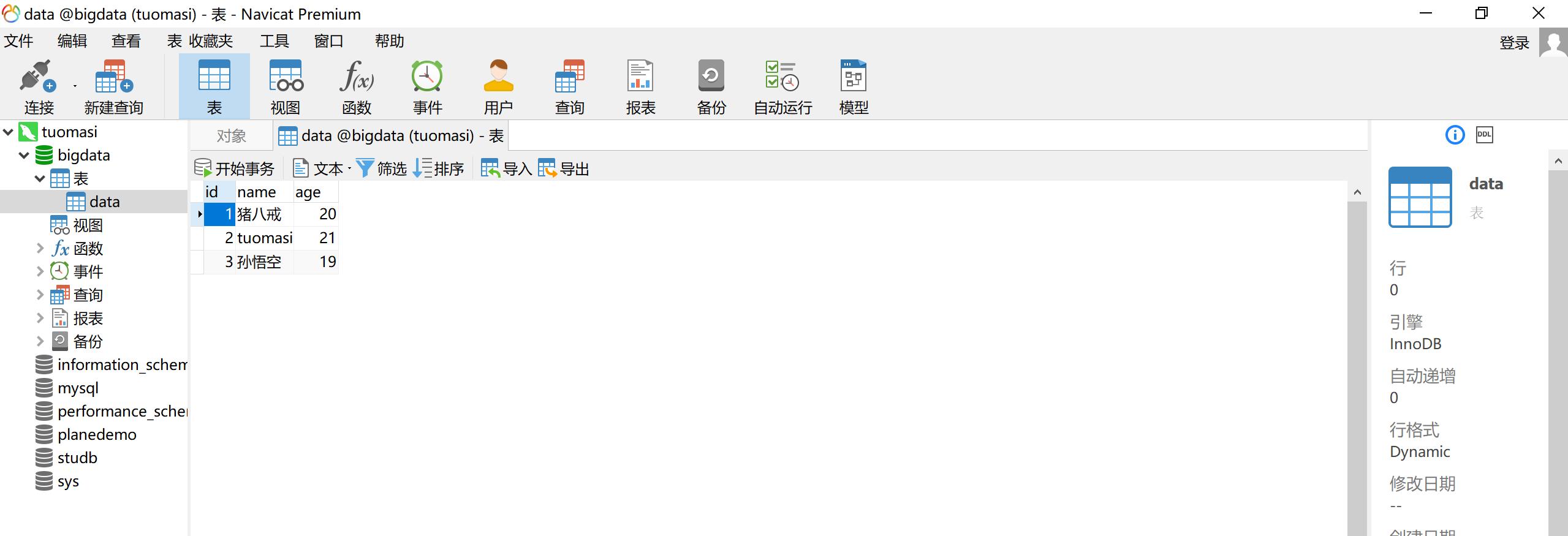
数据库查看
注:此为实验案例,在真实的场景中往往数据都是数以万计级别或者更多,优秀的代码往往体现在数据量极大的场景下,调优不失为一种升职加薪的必备技能
项目总结
总结:在代码编写过程中,难免出现知识匮乏,在遇到问题时,养成多看源码的好习惯,在以后的开发书写过程中会有事半功倍的效果,当然日志,及其 debug 的作用在开发中也不容小觑。
以上是关于六十三Spark-读取数据并写入数据库的主要内容,如果未能解决你的问题,请参考以下文章
如何使用Spark Streaming读取HBase的数据并写入到HDFS
将 Spark 数据集转换为 JSON 并写入 Kafka Producer