如何使用Spark Streaming读取HBase的数据并写入到HDFS
Posted Hadoop实操
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了如何使用Spark Streaming读取HBase的数据并写入到HDFS相关的知识,希望对你有一定的参考价值。
温馨提示:要看高清无码套图,请使用手机打开并单击图片放大查看。
Fayson的github:https://github.com/fayson/cdhproject
提示:代码块部分可以左右滑动查看噢
1.文档编写目的
Spark Streaming是在2013年被添加到Apache Spark中的,作为核心Spark API的扩展它允许用户实时地处理来自于Kafka、Flume等多种源的实时数据。这种对不同数据的统一处理能力就是Spark Streaming会被大家迅速采用的关键原因之一。
Spark Streaming能够按照batch size(如1秒)将输入数据分成一段段的离散数据流(Discretized Stream,即DStream),这些流具有与RDD一致的核心数据抽象,能够与MLlib和Spark SQL等Spark组件无缝集成。本篇文章主要介绍如何使用Spark Streaming读取HBase数据并将数据写入HDFS,数据流图如下:
类图如下:
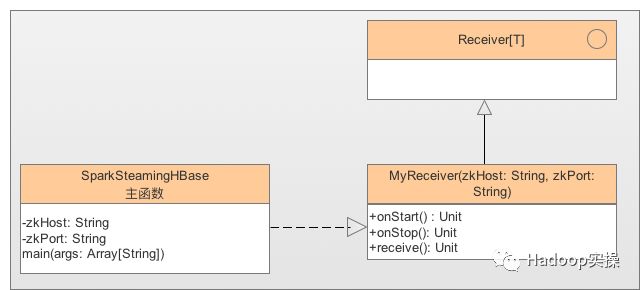
SparkStreamingHBase:初始化SparkContext及SteamingContext,通过ssc.receiverStream(new MyReceiver(zkHost, zkPort))获取DStream后调用saveAsTextFiles方法将数据写入HDFS。
MyReceiver:自定义Receiver通过私有方法receive()方法读取HBase数据并调用store(b.toString())将数据写入DStream。
内容概述
1.测试环境准备
2.创建Maven工程
3.示例代码
4.编译测试
测试环境
1.CentOS6.5
2.CM和CDH版本为5.13.1
3.Spark1.6.0
4.Scala2.10.5
2.测试环境
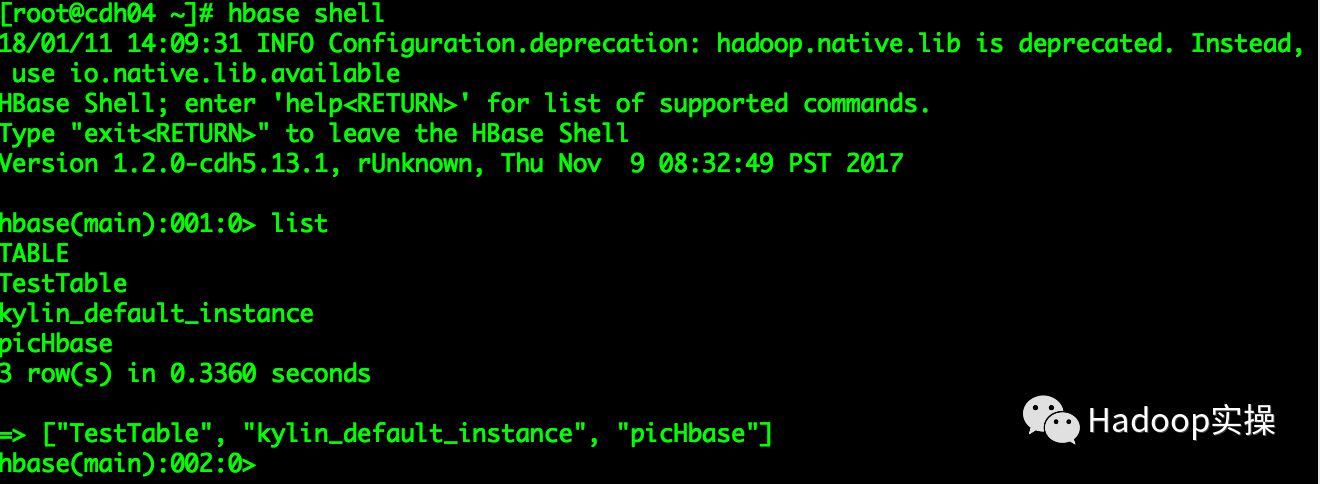
1.HBase表
create 'picHbase', {NAME => 'picinfo'}
(可向右拖动)
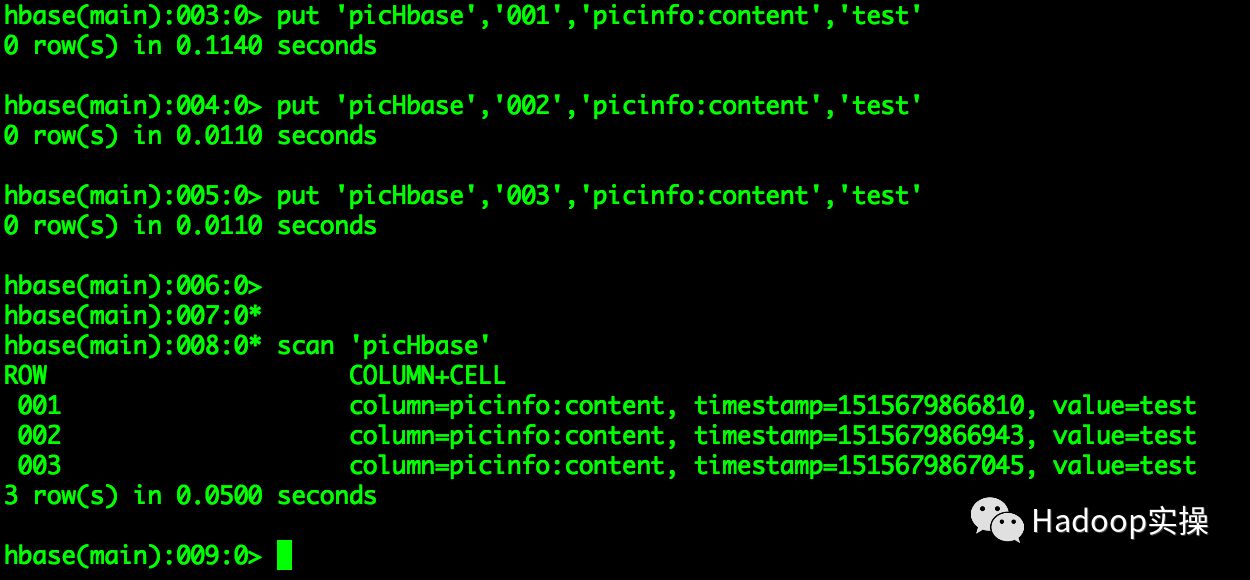
2.向表中插入测试数据
put 'picHbase','001','picinfo:content','test'
put 'picHbase','002','picinfo:content','test'
put 'picHbase','003','picinfo:content','test'
(可向右拖动)
3.创建SparkStreaming工程
1.使用Intellij工具创建一个Maven工程,pom.xml文件如下
<dependency>
<groupId>org.apache.hbase</groupId>
<artifactId>hbase-client</artifactId>
<version>1.2.0-cdh5.13.1</version>
</dependency>
<dependency>
<groupId>org.apache.hbase</groupId>
<artifactId>hbase-server</artifactId>
<version>1.2.0-cdh5.13.1</version>
</dependency>
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-streaming_2.10</artifactId>
<version>1.6.0</version>
</dependency>
<dependency>
<groupId>org.scala-lang</groupId>
<artifactId>scala-library</artifactId>
<version>2.10.5</version>
</dependency>
(可向右拖动)
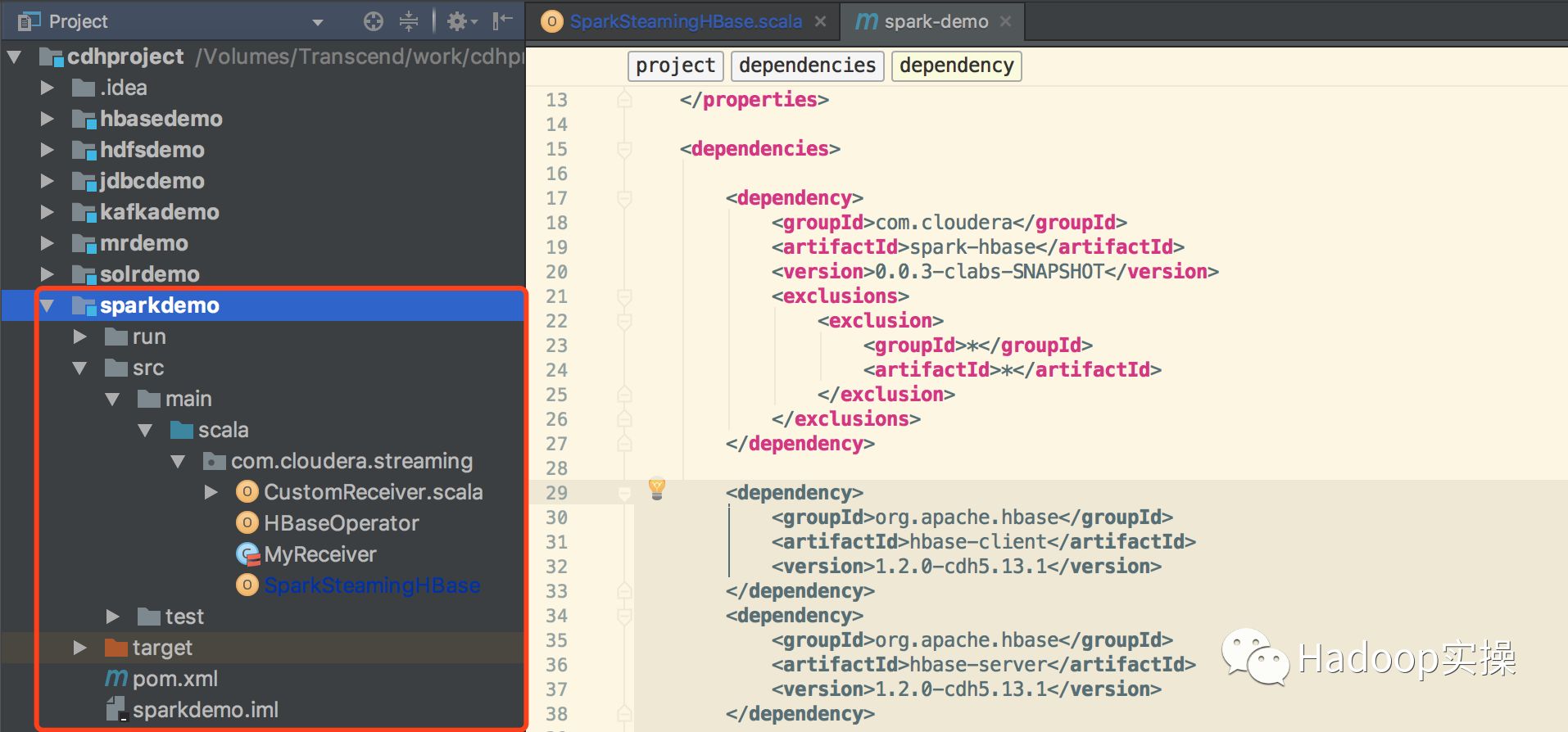
2.Maven工程目录结构
4.编写SparkStreaming程序
1.由于没有读取HBase的Stream接口,需要一个自定义的Receiver用于查询HBase数据类
MyReceiver类需要继承Spark的Receiver类
/**
* package: com.cloudera.streaming
* describe: 自定义Receiver类用于提供SparkStreaming的DataStream数据源
* creat_user: Fayson
* email: htechinfo@163.com
* creat_date: 2018/1/9
* creat_time: 上午12:21
* 公众号:Hadoop实操
*/
class MyReceiver(zkHost: String, zkPort: String) extends Receiver[String](StorageLevel.MEMORY_AND_DISK_2) with Logging {
override def onStart(): Unit = {
receive()
}
override def onStop(): Unit = {
}
private def receive(): Unit = {
val conf = HBaseConfiguration.create()
conf.set("hbase.zookeeper.quorum", zkHost)
conf.set("hbase.zookeeper.property.clientPort", zkPort)
val connection = ConnectionFactory.createConnection(conf);
val admin = connection.getAdmin;
val tableName = "picHbase"
val table = new HTable(conf, tableName)
val scan = new Scan()
scan.setCaching(1)
val rs = table.getScanner(scan)
val iterator = rs.iterator()
while(iterator.hasNext) {
val result = iterator.next();
val b = new StringBuilder
b.append(Bytes.toString(result.getRow))
b.append(",")
val cells = result.listCells()
val it = cells.iterator()
while (it.hasNext) {
val kv = it.next()
b.append(Bytes.toString(kv.getValue))
b.append(",")
b.append(kv.getTimestamp)
}
store(b.toString())
}
restart("Trying to connect again")
table.close()
connection.close()
}
}
(可向右拖动)
2.编写SparkStreaming入口类
package com.cloudera.streaming
import org.apache.spark.{SparkConf, SparkContext}
import org.apache.spark.streaming.{Seconds, StreamingContext}
/**
* package: com.cloudera.streaming
* describe: SparkStreaming读取HBase表数据并将数据写入HDFS
* creat_user: Fayson
* email: htechinfo@163.com
* creat_date: 2018/1/9
* creat_time: 上午12:09
* 公众号:Hadoop实操
*/
object SparkSteamingHBase {
val zkHost = "ip-172-31-5-190.fayson.com";
val zkPort = "2181"
def main(args: Array[String]): Unit = {
val sparkConf = new SparkConf().setAppName("SparkSteamingTest")
sparkConf.set("spark.streaming.receiverRestartDelay", "5000"); //设置Receiver启动频率,每5s启动一次
val sc = new SparkContext(sparkConf)
sc.setLogLevel("WARN")
val ssc = new StreamingContext(sc, Seconds(10)) //设置Spark时间窗口,每10s处理一次
val rddStream = ssc.receiverStream(new MyReceiver(zkHost, zkPort))
rddStream.saveAsTextFiles("/sparkdemo/test", "001")
ssc.start()
ssc.awaitTermination()
}
}
(可向右拖动)
3.在命令行使用mvn命令编译Spark工程
mvn clean scala:compile package
(可向右拖动)
5 提交作业测试
1.将编译好的jar包上传至集群中有Spark Gateway角色的任意节点

2.在命令行运行如下命令向集群提交作业
spark-submit --class com.cloudera.streaming.SparkSteamingHBase
--master yarn-client --num-executors 2 --driver-memory 1g
--driver-cores 1 --executor-memory 1g --executor-cores 1
spark-demo-1.0-SNAPSHOT.jar
(可向右拖动)
运行如下截图:

3.插入HDFS的/sparkdemo目录下生成的数据文件

查看目录下数据文件内容:
6.总结
示例中我们自定义了SparkStreaming的Receiver来查询HBase表中的数据,我们可以根据自己数据源的不同来自定义适合自己源的Receiver。
这里需要注意一点我们在提交Spark作业时指定了多个executor,这样我们的Receiver会分布在多个executor执行,同样的逻辑会导致重复获取相同的HBase数据。
可以通过spark.streaming.receiverRestartDelay=5000参数来设置Receiver的执行频率,单位ms(即每5s启动一次Receiver)
https://github.com/fayson/cdhproject/tree/master/sparkdemo/src/main/scala/com/cloudera/streaming
提示:代码块部分可以左右滑动查看噢
为天地立心,为生民立命,为往圣继绝学,为万世开太平。
温馨提示:要看高清无码套图,请使用手机打开并单击图片放大查看。
推荐关注Hadoop实操,第一时间,分享更多Hadoop干货,欢迎转发和分享。
以上是关于如何使用Spark Streaming读取HBase的数据并写入到HDFS的主要内容,如果未能解决你的问题,请参考以下文章
如何使用Spark Structured Streaming连续监视目录
如何将 Spark Streaming DStream 制作为 SQL 表
通过 Apache Spark Streaming 从 RabbitMq 读取消息