大数据技术使用java实现MapReduce对文件进行切分,分类汇总
Posted liangzai2048
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了大数据技术使用java实现MapReduce对文件进行切分,分类汇总相关的知识,希望对你有一定的参考价值。
Java使用MapReduce切分文件
比如有海量的文本文件,如订单,页面点击事件的记录,量特别大,很难搞定。
那么我们该怎样解决海量数据的计算?
1、获取总行数
2、计算每个文件中存多少数据
3、split切分文件
4、reduce将文件进行汇总
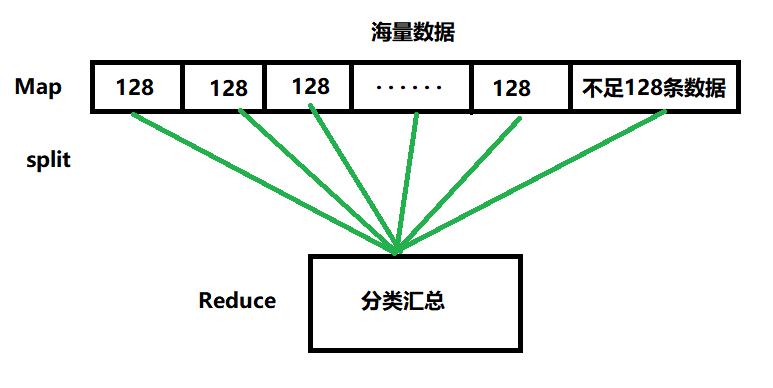
例如这里有百万条数据,单个文件操作太麻烦,所以我们需要进行切分
在切分文件的过程中会出现文件不能整个切分的情况,可能有剩下的数据并没有被读取到,所以我们每个切分128条数据,不足128条再保留到一个文件中
创建MapTask
import java.io.*;
import java.util.HashMap;
import java.util.Map;
import java.util.Set;
public class MapTask extends Thread
//用来接收具体的哪一个文件
private File file;
private int flag;
public MapTask(File file, int flag)
this.file = file;
this.flag = flag;
@Override
public void run()
try
BufferedReader br = new BufferedReader(new FileReader(file));
String line;
HashMap<String, Integer> map = new HashMap<String, Integer>();
while ((line = br.readLine()) != null)
/**
* 统计班级人数HashMap存储
*/
String clazz = line.split(",")[4];
if (!map.containsKey(clazz))
map.put(clazz, 1);
else
map.put(clazz, map.get(clazz) + 1);
br.close();
BufferedWriter bw = new BufferedWriter(
new FileWriter("F:\\\\IDEADEMO\\\\shujiabigdata\\\\part\\\\part---" + flag));
Set<Map.Entry<String, Integer>> entries = map.entrySet();
for (Map.Entry<String, Integer> entry : entries)
String key = entry.getKey();
Integer value = entry.getValue();
bw.write(key + ":" + value);
bw.newLine();
bw.flush();
bw.close();
catch (Exception e)
e.printStackTrace();
创建Map
import java.io.File;
import java.util.concurrent.ExecutorService;
import java.util.concurrent.Executors;
public class Map
public static void main(String[] args)
long start = System.currentTimeMillis();
// 多线程连接池(线程池)
ExecutorService executorService = Executors.newFixedThreadPool(8);
// 获取文件列表
File file = new File("F:\\\\IDEADEMO\\\\shujiabigdata\\\\split");
File[] files = file.listFiles();
//创建多线程对象
int flag = 0;
for (File f : files)
//为每一个文件启动一个线程
MapTask mapTask = new MapTask(f, flag);
executorService.submit(mapTask);
flag++;
executorService.shutdown();
long end = System.currentTimeMillis();
System.out.println(end-start);
创建ClazzSum
import java.io.BufferedReader;
import java.io.FileReader;
import java.util.HashMap;
public class ClazzSum
public static void main(String[] args) throws Exception
long start = System.currentTimeMillis();
BufferedReader br = new BufferedReader(
new FileReader("F:\\\\IDEADEMO\\\\shujiabigdata\\\\data\\\\bigstudents.txt"));
String line;
HashMap<String, Integer> map = new HashMap<String, Integer>();
while ((line = br.readLine()) != null)
String clazz = line.split(",")[4];
if (!map.containsKey(clazz))
map.put(clazz, 1);
else
map.put(clazz, map.get(clazz) + 1);
System.out.println(map);
long end = System.currentTimeMillis();
System.out.println(end-start);
创建split128
import java.io.BufferedReader;
import java.io.BufferedWriter;
import java.io.FileReader;
import java.io.FileWriter;
import java.util.ArrayList;
public class Split128
public static void main(String[] args) throws Exception
BufferedReader br = new BufferedReader(
new FileReader("F:\\\\IDEADEMO\\\\shujiabigdata\\\\data\\\\students.txt"));
//用作标记文件,也作为文件名称
int index = 0;
BufferedWriter bw = new BufferedWriter(
new FileWriter("F:\\\\IDEADEMO\\\\shujiabigdata\\\\split01\\\\split---" + index));
ArrayList<String> list = new ArrayList<String>();
String line;
//用作累计读取了多少行数据
int flag = 0;
int row = 0;
while ((line = br.readLine()) != null)
list.add(line);
flag++;
// flag = 140
if (flag == 140) // 一个文件读写完成,生成新的文件
row = 0 + 128 * index;
for (int i = row; i <= row + 127; i++)
bw.write(list.get(i));
bw.newLine();
bw.flush();
bw.close();
/**
* 生成新的文件
* 计数清零
*/
index++;
flag = 12;
bw = new BufferedWriter(
new FileWriter("F:\\\\IDEADEMO\\\\shujiabigdata\\\\split01\\\\split---" + index));
//文件读取剩余128*1.1范围之内
for (int i = list.size() - flag; i < list.size(); i++)
bw.write(list.get(i));
bw.newLine();
bw.flush();
bw.close();
创建Reduce
import java.io.BufferedReader;
import java.io.File;
import java.io.FileReader;
import java.util.HashMap;
public class Reduce
public static void main(String[] args) throws Exception
long start = System.currentTimeMillis();
HashMap<String, Integer> map = new HashMap<String, Integer>();
File file = new File("F:\\\\IDEADEMO\\\\shujiabigdata\\\\part");
File[] files = file.listFiles();
for (File f : files)
BufferedReader br = new BufferedReader(new FileReader(f));
String line;
while ((line = br.readLine()) != null)
String clazz = line.split(":")[0];
int sum = Integer.valueOf(line.split(":")[1]);
if (!map.containsKey(clazz))
map.put(clazz, sum);
else
map.put(clazz, map.get(clazz) + sum);
long end = System.currentTimeMillis();
System.out.println(end-start);
System.out.println(map);
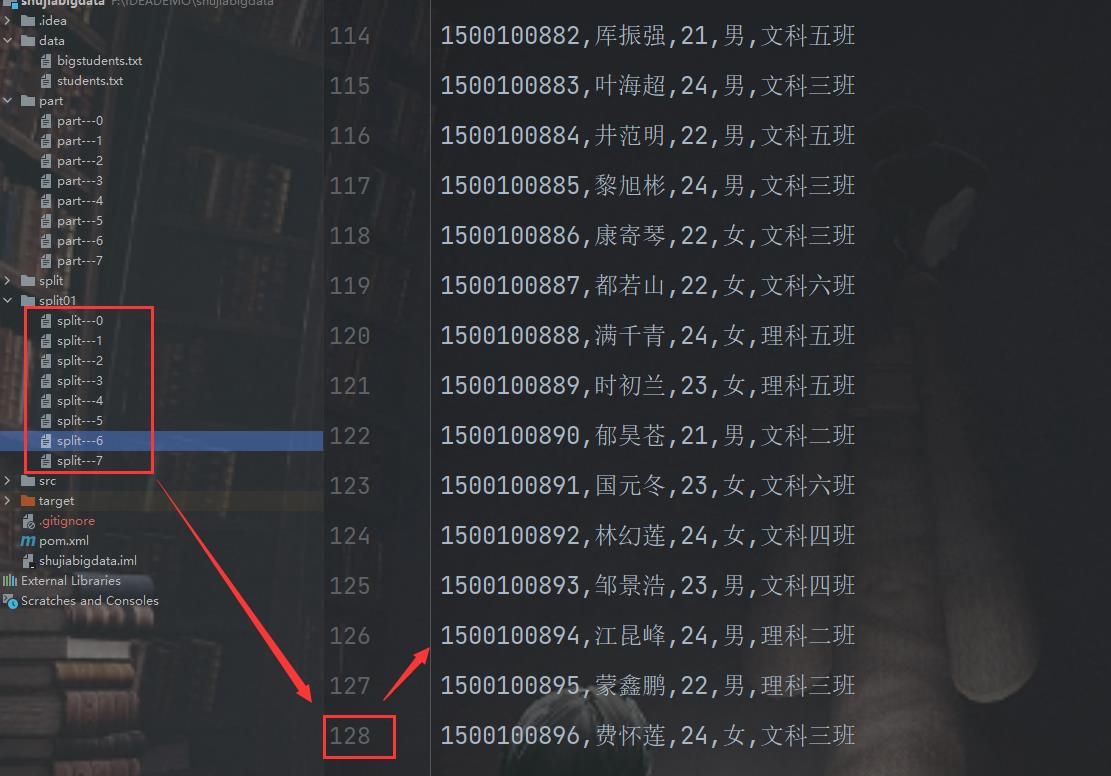
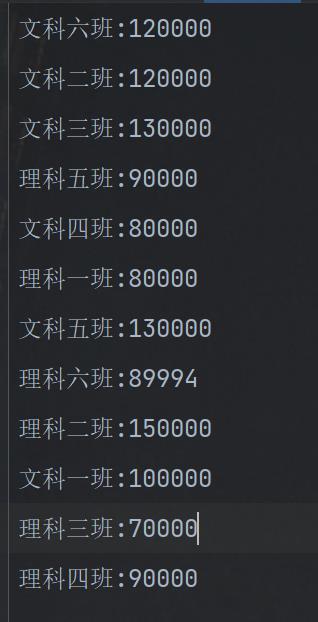
最后将文件切分了8份,这里采用了线程池,建立线程连接,多个线程同时启动,比单一文件采用多线程效率更高更好使。
以上是关于大数据技术使用java实现MapReduce对文件进行切分,分类汇总的主要内容,如果未能解决你的问题,请参考以下文章