大数据技术之Hive
Posted DK_521
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了大数据技术之Hive相关的知识,希望对你有一定的参考价值。
第1章Hive基本概念
1.1 Hive
1.1.1 Hive的产生背景
在那一年的大数据开源社区,我们有了HDFS来存储海量数据、MapReduce来对海量数据进行分布式并行计算、Yarn来实现资源管理和作业调度。但是面对海量数据和负责的业务逻辑,开发人员要编写MR来对数据进行统计分析难度极大、效率较低,并且对开发者的Java功底也有要求。所以Facebook公司在处理自己的海量数据时开发了hive这个数仓工具。Hive可以帮助开发人员来做完成这些苦活(将SQL语句转化为MapReduce在yarn上跑),如此开发人员就可以更加专注于业务需求了。
1.1.2 hive简介
Hive:由Facebook开源用于解决海量结构化日志的数据统计工具。
Hive是基于Hadoop的一个数据仓库工具,将结构化的数据文件映射为一张表,并提供类SQL(HQL)查询功能。
1.1.3 Hive本质:将HQL(hiveSQL)转化成MapReduce程序
(1)Hive处理的数据存储在HDFS
(2)Hive分析数据底层的实现是MapReduce
(3)执行程序运行在Yarn上
(4)结构化文件如何映射成一张表的?借助存储在元数据数据库中的元数据来解析结构化文件
1.2 Hive架构原理

1.2.1 Hive架构介绍
1)用户接口:Client | CLI(command-line interface)、 JDBC/ODBC(jdbc访问hive)、 | |
2)元数据:Metastore | 元数据包括: 表名、表所属的数据库(默认是default)、表的拥有者、列/分区字段、表的类型(是否是外部表)、表的数据所在目录等; 默认存储在自带的derby数据库中,推荐使用mysql存储Metastore | |
3)Hadoop | 使用HDFS进行存储,使用MapReduce进行计算。 | |
4)驱动器:Driver | ·解析器(SQL Parser): | 将SQL字符串转换成抽象语法树AST, 这一步一般都用第三方工具库完成,比如antlr;对AST进行语法分析,比如表是否存在、字段是否存在、SQL语义是否有误。 |
·编译器(Physical Plan): | 将AST编译生成逻辑执行计划。 | |
·优化器(Query Optimizer): | 对逻辑执行计划进行优化。 | |
·执行器(Execution): | 把逻辑执行计划转换成可以运行的物理计划。对于Hive来说,就是MR/Spark。 | |
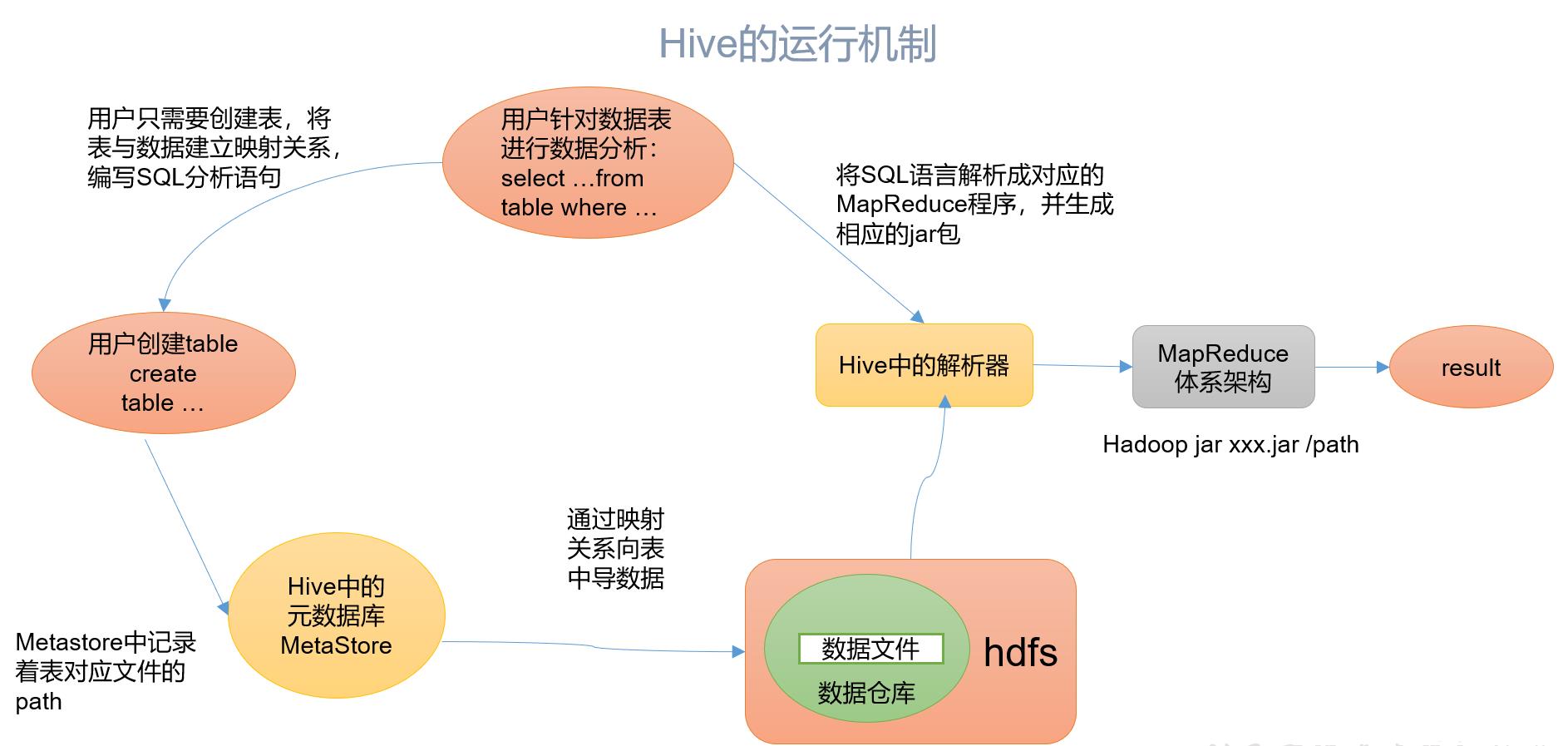
1.2.2 Hive的运行机制
hive通过给用户提供的一系列交互接口,接收到的用户的指令(SQl),使用自己的Driver,结合元数据(MetaStore),将这些指令翻译成MapReduce,提交到Hadoop中执行,最后,将执行返回的结果输出到用户交互接口中。
1.3 Hive和数据库比较
| Hive | mysql |
语言 | 类sql | sql |
数据规模 | 大数据pb及以上 | 数据量小一般百万左右到达单表极限 |
数据插入 | 能增加insert,不能update,delete | 能insert,update,delete |
数据存储 | Hdfs | 拥有自己的存储空间 |
计算引擎 | Mapreduce/spark/tez | 自己的引擎innodb |
综上所述,Hive压根就不是数据库,hive除了语言类似意外,存储和计算都是使用Hadoop来完成的。而Mysql则是使用自己的,拥有自己的体系。
1.4 Hive的优缺点
优点 | 缺点 | |
1. 提供了类SQl语法操作接口,具备快速开发的能力(简单、易上手) | 1. Hive的HQL表达能力有限 | 1)Hive自动生成MapReduce作业,通常情况下不够智能化 |
2. 避免了去写MapReduce,减少开发者的学习成本 | 2)数据挖掘方面不擅长(多个子查询),由于MapReduce数据处理流程的限制,效率更高的算法却无法实现 | |
3. Hive优势在于处理大数据,在处理小数据时没有优势,因为Hive的执行延迟较高。 | 2. Hive的效率比较低 | 1)Hive的执行延迟比较高,因为Hive常用于数据分析,对实时性要求不高的场合 |
2)Hive调优比较困难,粒度较粗 | ||
4. Hive支持用户自定义函数,用户可以根据自己的需求来实现自己的函数 | 3. Hive不支持实时查询和行级别更新 | hive分析的数据是存储在HDFS上的,而HDFS仅支持追加写,所以在hive中不能update和delete,只能select和insert。 |
第2章Hive安装
后续更新
2.3 Hive元数据的三种部署方式
2.3.1 元数据库之Derby
1.内嵌模式示意图:

2.Derby数据库:
Derby数据库是Java编写的内存数据库,在内嵌模式中与应用程序共享一个JVM,应用程序负责启动和停止。
Hive默认使用的元数据库为derby并且部署方式是内嵌式,在开启Hive之后就会独占元数据库,且不与其他客户端共享数据,如果想多窗口操作就会报错,操作比较局限。为此Hive支持采用MySQL作为元数据库,就可以支持多窗口操作。
2.3.2 元数据库之Mysql
1. 直连模式示意图:
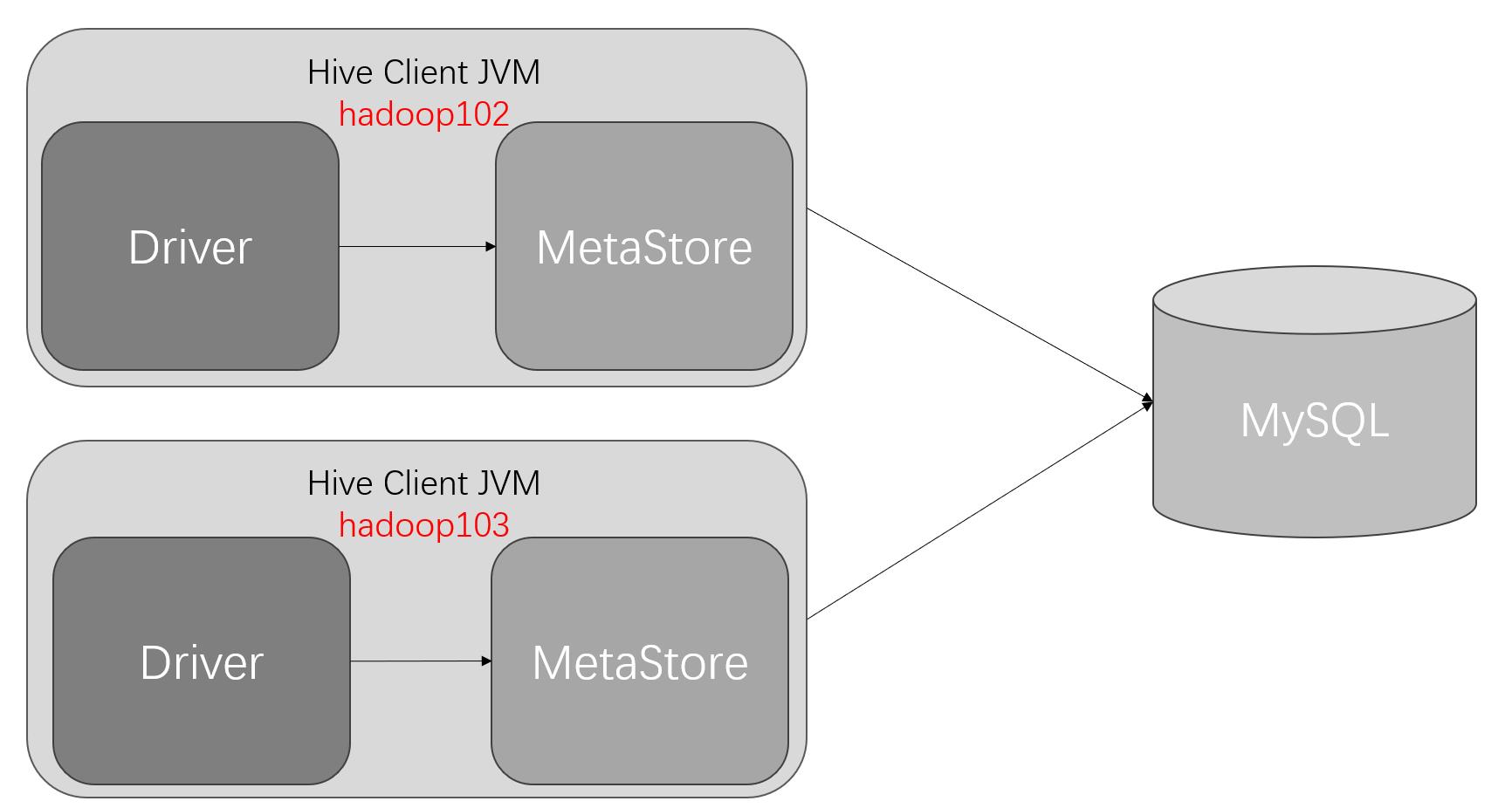
直连模式问题:
在公司生产环境中,网络环境会非常复杂,mysql的所在环境可能存在网络隔离,无法直接访问;另外,mysql的root账户和密码在此模式下会存在泄露风险,存在数据安全隐患。
2.3.3 元数据之MetaStore Server
1.元数据服务模式示意图
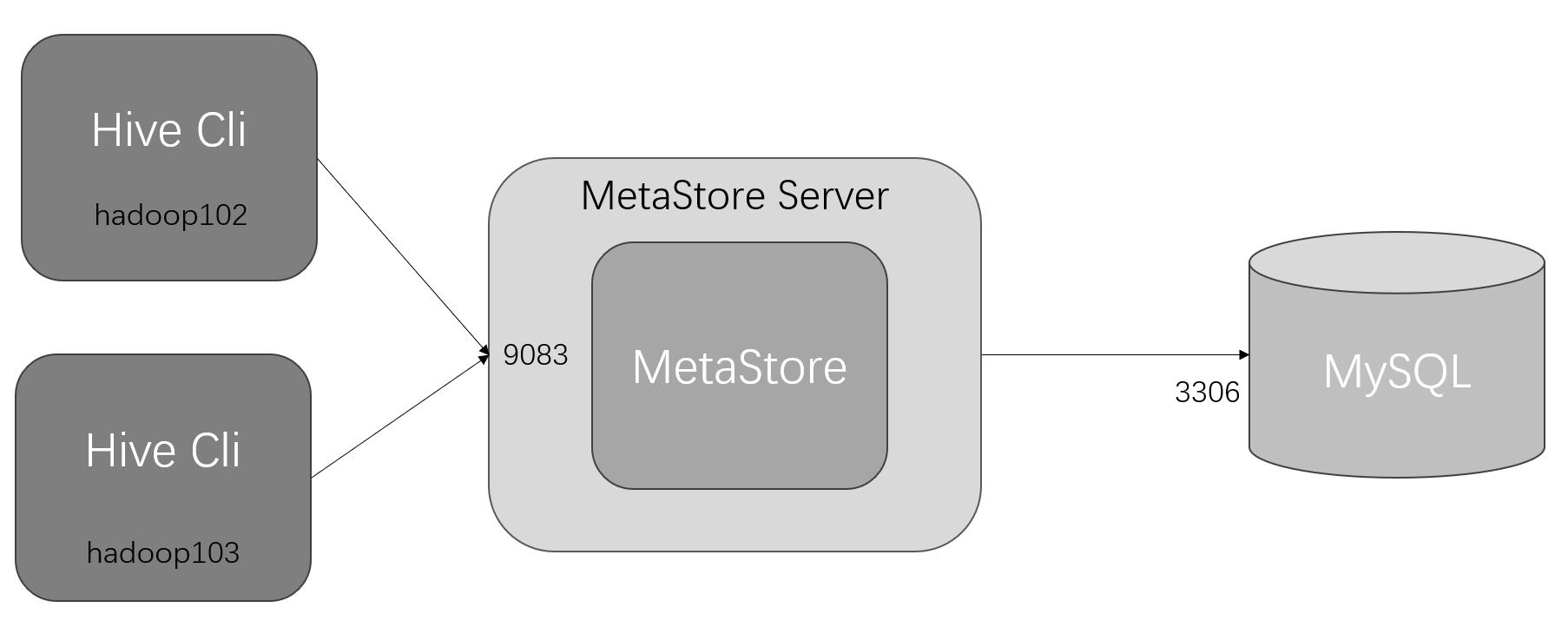
2.元数据服务模式
在服务器端启动MetaStore服务,客户端利用Thrift协议通过MetaStore服务访问元数据库。
元数据服务的访问方式更适合在生产环境中部署使用,相比内嵌式,该方式更加的灵活。(跨网络跨语言跨平台)。
2.4 hive的两种访问方式
2.4.1 命令行的方式
内嵌模式
Mysql的直连模式
元数据服务模式
1. 在前面的操作中,我们都是通过cli的方式访问hive的。
2. 我们可以切身的体会到,通过cli的方式访问hive的不足,如:cli太过笨重,需要hive的jar支持。
2.4.2 HiveServer2模式

2. JDBC方式访问Hive
JDBC方式,本质上是将hive包装为服务发布出去,开发者使用JDBC的方式连接到服务,从而操作hive。减少了对hive环境的依赖.
2.5编写启动metastore和hiveserver2脚本
//TODO
2.6 Hive常用交互命令
[atguigu@hadoop102 hive]$ bin/hive -help
usage: hive
-d,--define <key=value> Variable subsitution to apply to hive commands. e.g. -d A=B or --define A=B
应用于hive命令的变量替换。如:-d A=B 或者 –-define A=B
--database <databasename> Specify the database to use
指定要使用的数据库
-e <quoted-query-string> SQL from command line
命令行中的SQL语句
-f <filename> SQL from files
文件中的SQL语句
-H,--help Print help information
打印帮助信息
--hiveconf <property=value> Use value for given property
设置属性值
--hivevar <key=value> Variable subsitution to apply to hive commands. e.g. --hivevar A=B
应用于hive命令的变量替换,如:--hivevar A=B
-i <filename> Initialization SQL file
初始化SQL文件
-S,--silent Silent mode in interactive shell
交互式Shell中的静默模式
-v,--verbose Verbose mode (echo executed SQL to the console)
详细模式(将执行的SQl回显到控制台)2.6.2 命令中参数-e的使用
使用-e参数,可以不进入hive的交互窗口执行sql语句
[atguigu@hadoop102 hive]$ bin/hive -e "select * from test2;"
……
Logging initialized using configuration in jar:file:/opt/module/hive/lib/hive-common-3.1.2.jar!/hive-log4j2.properties Async: true
Hive Session ID = 8f19d950-9936-4543-8b32-501dd61fa395
OK
1002
Time taken: 1.918 seconds, Fetched: 1 row(s)2.6.3 命令中参数-f的使用
使用-f参数,可以不进入hive交互窗口,执行脚本中sql语句
1)在/opt/module/hive/下创建datas目录并在datas目录下创建hivef.sql文件
[atguigu@hadoop102 hive]$ mkdir /opt/module/hive/datas
[atguigu@hadoop102 hive]$ touch /opt/module/hive/datas/hive-f.sql
2)文件中写入正确的sql语句
[atguigu@hadoop102 datas]$ vim /opt/module/hive/datas/hive-f.sql
select * from test2;
3)执行文件中的sql语句
[atguigu@hadoop102 hive]$ bin/hive -f /opt/module/hive/datas/hivef.sql
4)我们还可以通过执行文件中的sql语句,将结果写入指定文件中
[atguigu@hadoop102 hive]$ bin/hive -f /opt/module/hive/datas/hivef.sql > /opt/module/datas/hive_result.txt 2.7 Hive常见属性配置
2.7.1 Hive运行日志信息配置
1.Hive的log默认存放路径:/tmp/atguigu/hive.log(当前用户名下)
2.修改hive的log存放路径:到/opt/module/hive/logs
① 修改conf目录下hive-log4j2.properties.template文件名称为hive-log4j2.properties
[atguigu@hadoop102hive]$ mv conf/hive-log4j2.properties.template conf/hive-log4j2.properties② 在hive-log4j.properties文件中修改log存放位置
[atguigu@hadoop102hive]$ vim conf/hive-log4j2.properties
property.hive.log.dir=/opt/module/hive/logs3)再次启动hive,观察目录/opt/module/hive/logs下是否产生日志
2.7.2 Hive启动JVM堆内存配置
1.问题:
新版Hive启动时,默认申请的JVM堆内存大小为256M,内存太小,导致若后期开启本地模式,执行相对复杂的SQL经常会报错:java.lang.OutOfMemoryError: Java heap space
2.解决:修改HADOOP_HEAPSIZE参数的值
1)修改/opt/module/hive/conf/下的hive-env.sh.template
[atguigu@hadoop102hive]$ mvconf/hive-env.sh.template conf/hive-env.sh
[atguigu@hadoop102hive]$ vim conf/hive-env.sh
……
exportHADOOP_HEAPSIZE=10242.7.3 hive窗口打印默认库和表头
1.问题:在hive命令行交互窗口中,切换数据库后,不会提示当前所在数据库是哪个,并且在列出的查询结果中也不会带有列名的信息,使用中多有不便。
2.配置:可以修改hive.cli.print.header和hive.cli.print.current.db两个参数的值,打印出当前库头。
编辑hive-site.xml添加如下两个配置:
<property>
<name>hive.cli.print.header</name>
<value>true</value>
</property>
<property>
<name>hive.cli.print.current.db</name>
<value>true</value>
</property>2.7.4 参数配置方式
set 命令使用:查看当前所有的配置信息
hive>set;2.配置参数的三种方式:
配置文件方式 | 命令行参数方式 | 参数声明方式 |
①默认的配置文件:hive-default.xml ②自定义的配置文件:hive-site.xml ③Hive同时也会读入Hadoop配置,Hive的配置会覆盖Hadoop的配置。 ④配置文件中设置的参数值对本机内启动的所有hive进程都有效。 注意:用户自定义配置会覆盖默认配置 | ① 启动hive时,可以在命令行添加 --hiveconf param = value来设定参数 ② 测试: 通过命令行参数方式,配置hive不打印当前数据库名 [atguigu@hadoop102 hive]$ bin/hive --hiveconf hive.cli.print.current.db = false 注意:命令行参数方式仅仅对本次hive启动有效 | ①在进入hive命令行交互窗口后,可使用set命令设置参数 ② 测试: 通过set命令,设置打印当前数据库 hive> set hive.cli.print.current.db = false 注意:仅在当前连接中设置后起作用,若本次中断后重启,参数设置则将按照配置文件中的值重置。 |
3.三种配置方式的优先级
上述三种设定方式的优先级依次递增。即配置文件<命令行参数<参数声明。
注意:某些系统级的参数,例如log4j相关的设定,必须用前两种方式设定,因为那些参数的读取在会话建立以前已经完成了。
第3章Hive数据类型
3.1 基本数据类型
Hive数据类型 | Java数据类型 | 长度 | 例子 |
TINYINT | byte | 1byte有符号整数 | 20 |
SMALINT | short | 2byte有符号整数 | 20 |
INT | int | 4byte有符号整数 | 20 |
BIGINT | long | 8byte有符号整数 | 20 |
BOOLEAN | boolean | 布尔类型,true或者false | TRUE FALSE |
FLOAT | float | 单精度浮点数 | 3.14159 |
DOUBLE | double | 双精度浮点数 | 3.14159 |
STRING | string | 字符系列。可以指定字符集。 可以使用单引号或者双引号。 | ‘now is the time’ “for all good men” |
TIMESTAMP |
| 时间类型 |
|
BINARY |
| 字节数组 |
|
对于Hive的String类型相当于数据库的varchar类型,该类型是一个可变的字符串,不过它不能声明其中最多能存储多少个字符,理论上它可以存储2GB的字符数。
3.2 集合数据类型
数据类型 | 描述 | 语法示例 |
STRUCT | 和c语言中的struct类似,都可以通过“点”符号访问元素内容。 例如: 如果某个列的数据类型是STRUCTfirst STRING, last STRING,那么第1个元素可以通过字段.first来引用。 | struct() 例如: struct<street:string, city:string> |
MAP | MAP是一组键-值对元组集合,使用数组表示法可以访问数据。 例如: 如果某个列的数据类型是MAP,其中键->值对是 ‘first’->’John’和’last’->’Doe’,那么可以通过字段名[‘last’]获取最后一个元素 | map() 例如: map<string, int> |
ARRAY | 数组是一组具有相同类型和名称的变量的集合。 这些变量称为数组的元素,每个数组元素都有一个编号,编号从零开始。 例如: 数组值为[‘John’, ‘Doe’],那么第2个元素可以通过数组名[1]进行引用。 | Array() 例如:array<string> |
Hive有三种复杂数据类型ARRAY、MAP 和 STRUCT。ARRAY和MAP与Java中的Array和Map类似,而STRUCT与C语言中的Struct类似,它封装了一个命名字段集合,复杂数据类型允许任意层次的嵌套。
3.3类型转换
1)Hive的基本数据类型是可以进行隐式转换的,类似于Java的类型转换
例如:某表达式使用INT类型,TINYINT会自动转换为INT类型,
但是Hive不会进行反向转化
例如,某表达式使用TINYINT类型,INT不会自动转换为TINYINT类型,它会返回错误,除非使用CAST操作。
2)隐式类型转换规则如下:
任何整数类型都可以隐式地转换为一个范围更广的类型,如INT可以转换成BIGINT。
所有整数类型、FLOAT和STRING类型都可以隐式地转换成DOUBLE。
TINYINT、SMALLINT、INT都可以转换为FLOAT。
BOOLEAN类型不可以转换为任何其它的类型。
3)可以使用CAST操作显示进行数据类型转换
例如:CAST('1' AS INT)将把字符串'1' 转换成整数1;
如果强制类型转换失败,如执行CAST('X' AS INT),表达式返回空值 NULL。
第4章DDL数据定义
4.1创建数据库
创建数据库语法:
CREATE DATABASE [IF NOTEXISTS] database_name
[COMMENT database_comment]
[LOCATION hdfs_path]
[WITH DBPROPERTIES(property_name=property_value, ...)];
-- 1)创建一个数据库,数据库在HDFS上的默认存储路径是/user/hive/warehouse/*.db。
hive (default)> create database bigdata;
-- 2)避免要创建的数据库已经存在错误,增加if not exists判断。(标准写法)
hive (default)> create database bigdata;
FAILED: Execution Error, return code 1 from org.apache.hadoop.hive.ql.exec.DDLTask. Database db_hive already exists
hive (default)> create database if not exists bigdata;
--3)创建一个数据库,指定数据库在HDFS上存放的位置
hive (default)> create database bigdata2 location '/bigdata2.db';4.2 查询数据库
4.2.1 显示数据库
-- 1)显示数据库
hive(default)> show databases;
-- 2)过滤显示查询的数据库
hive(default)> show databases like 'bigdata*';
OK
bigdata
bigdata24.2.2 查看数据库详情
-- 1)显示数据库信息
hive(default)> desc database bigdata;
bigdata hdfs://hadoop102:9000/user/hive/warehouse/bigdata.db atguigu USER
-- 2)显示数据库详细信息,extended
hive(default)> desc database extended bigdata;
bigdata hdfs://hadoop102:9000/user/hive/warehouse/bigdata.db atguigu USER
-- 3)创建数据库bigdata3,并设置其createtime属性
hive(default)> create database bigdata3 with dbproperties('createtime'='20211022');
-- 4)再次查询
hive(default)> desc database bigdata3
OK
bigdata3 hdfs://hadoop102:8020/user/hive/warehouse/bigdata3.db atguigu USER
hive(default)> desc database extended bigdata3
OK
bigdata3 hdfs://hadoop102:8020/user/hive/warehouse/bigdata3.db atguigu USER createtime=202110224.2.3 切换当前数据库
hive (default)> use bigdata;4.3 修改数据库
用户可以使用ALTER DATABASE命令为某个数据库的DBPROPERTIES设置键-值对属性值,来描述这个数据库的属性信息。数据库其他的元数据信息都是不可以修改的,包括数据库名和数据库所在的目录位置。
hive (default)> alter database bigdata set dbproperties('createtime'='20211022');
-- 在hive中查看修改结果
hive(default)> desc database extended bigdata;
db_name comment location owner_name owner_type parameters
bigdata hdfs://hadoop102:8020/user/hive/warehouse/bigdata.db atguigu USER createtime=202110224.4 删除数据库
1)删除空数据库
hive(default)>drop database bigdata2;2)如果删除的数据库不存在,最好采用 if exists判断数据库是否存在
hive(default)> drop database bigdata10;
FAILED: SemanticException [Error10072]: Database does not exist: bigdata10
hive(default)>drop database if exists bigdata2;3)如果数据库不为空,可以采用cascade命令,强制删除
hive(default)> drop database bigdata;
FAILED: Execution Error, returncode 1 from org.apache.hadoop.hive.ql.exec.DDLTask.InvalidOperationException(message:Database bigdata is not empty. One or moretables exist.)
hive(default)> drop database bigdatacascade;4.5 创建表
1)建表语法
CREATE [EXTERNAL] TABLE [IF NOT EXISTS] table_name
[(col_name data_type [COMMENT col_comment], ...)]
[COMMENT table_comment]
[PARTITIONED BY (col_name data_type [COMMENTcol_comment], ...)]
[CLUSTERED BY (col_name, col_name, ...)
[SORTED BY (col_name [ASC|DESC], ...)] INTO num_bucketsBUCKETS]
[ROW FORMAT row_format]
[STORED AS file_format]
[LOCATION hdfs_path]
[TBLPROPERTIES (property_name=property_value, ...)]
[AS select_statement]
[LIKES existing_table_or_view_name]2)字段解释说明
CREATE TABLE | 创建一个指定名字的表。如果相同名字的表已经存在,则抛出异常;用户可以用 IF NOT EXISTS 选项来忽略这个异常 | ||
EXTERNAL |
在建表的同时可以指定一个指向实际数据的路径(LOCATION)
内部表的元数据和数据会被一起删除, 外部表只删除元数据,不删除数据。 | ||
COMMENT | 为表和列添加注释。 | ||
PARTITIONED BY | 创建分区表 | ||
CLUSTERED BY | 创建分桶表 | ||
SORTED BY | 不常用,对桶中的一个或多个列另外排序 | ||
ROW FROMAT | ROW FORMAT DELIMITED [FIELDS TERMINATED BY char] [COLLECTION ITEMS TERMINATED BY char] [MAP KEYS TERMINATED BY char] [LINES TERMINATED BY char] | SERDE serde_name [WITH SERDEPROPERTIES (property_name=property_value, property_name=property_value, ...)]
| Fields 指定字段之间的分隔符 Collection 用于指定集合中元素间的分隔符 Map 用于指定map集合中键值对间的分隔符 Lines 用于指定每行记录间的分隔符 SerDe是Serialize/Deserialize的简称 用户在建表时可以自定义SerDe或使用自带的SerDe 若未指定Row Format,则用自带的SerDe | |
STORE AS | 指定存储文件类型 常用的文件存储类型: SEQUENCEFILE(二进制序列文件)、TEXTFILE(文本)、RCFILE(列式存储格式文件) 如:store as textfile、store as sequencefile | ||
LOCATION | 指定表在HDFS上的存储位置 | ||
AS | 后跟查询语句,根据查询语句结果创建表 | ||
LIKE | 允许用户复制现有的表结构,但是不复制数据 | ||
4.5.1 管理表(内部表)
1)理论
默认创建的表都是所谓的管理表,有时也被称为内部表。
管理表,Hive会控制着元数据和真实数据的生命周期。
Hive默认会将这些表的数据存储在hive.metastore.warehouse.dir定义目录的子目录下。
当我们删除一个管理表时,Hive也会删除这个表中数据。
管理表不适合和其他工具共享数据。
4.5.2 外部表
1.理论
因为表是外部表,所以Hive并非认为其完全拥有这份数据。
删除该表并不会删除掉这份数据,不过描述表的元数据信息会被删除掉。
2.管理表和外部表的使用场景
每天将收集到的网站日志定期流入HDFS文本文件。
在外部表(原始日志表)的基础上做大量的统计分析,用到的中间表、结果表使用内部表存储,数据通过SELECT+INSERT进入内部表。外部表多用于存储原始数据,为多个部门、小组所使用,采用外部表共易共享数据。
4.5.3 管理表与外部表的互相转换
(1)查询表的类型
hive(default)> desc formatted student2;
Table Type: MANAGED_TABLE(2)修改内部表student2为外部表
hive(default)> alter table student2 set tblproperties('EXTERNAL'='TRUE');(3)查询表的类型
hive(default)> desc formatted student2;
Table Type: EXTERNAL_TABLE(4)修改外部表student2为内部表
hive(default)> alter table student2 set tblproperties('EXTERNAL'='FALSE');(5)查询表的类型
hive(default)> desc formatted student2;
Table Type: MANAGED_TABLE注意:('EXTERNAL'='TRUE')和('EXTERNAL'='FALSE')为固定写法,区分大小写!
4.6 修改表
4.6.1 重命名表
1.语法
ALTER TABLE table_name RENAME TO new_table_name
-- e.g.,
alter table student3大数据技术之 Hive (小白入门)
Hive 基本概念
什么是 Hive
hive 简介
Hive:由 Facebook 开源用于解决海量结构化日志的数据统计工具。
Hive: 是基于 Hadoop 的一个数据仓库工具,可以将结构化的数据文件映射为一张表,并提供类 SQL 查询功能。
Hive 安装
1)下载hive Hive 官网地址:http://hive.apache.org/
2) 把 apache-hive-3.1.2-bin.tar.gz 上传到 linux 的/opt/software 目录下
3)解压 apache-hive-3.1.2-bin.tar.gz 到/opt/module/目录下面
tar -zxvf /opt/software/apache-hive-3.1.2-bin.tar.gz -C /opt/module/
4)修改 apache-hive-3.1.2-bin.tar.gz 的名称为 hive
mv /opt/module/apache-hive-3.1.2-bin /opt/module/hive
5)修改/etc/profile.d/my_env.sh,添加环境变量
#HIVE_HOME
export HIVE_HOME=/opt/module/hive
export PATH=$PATH:$HIVE_HOME/bin
6)解决日志 Jar 包冲突
mv $HIVE_HOME/lib/log4j-slf4j-impl-
2.10.0.jar $HIVE_HOME/lib/log4j-slf4j-impl-2.10.0.bak
7)初始化元数据库
进入hive 安装目录 bin/schematool -dbType derby -initSchema
启动并使用 Hive
1)启动 Hive
bin/hive
2)使用 Hive
show databases;
show tables;
create table test(id int);
insert into test values(1);
select * from test;
MySQL 安装
1)检查当前系统是否安装过 MySQL
rpm -qa|grep mariadb
//如果存在通过如下命令卸载
sudo rpm -e --nodeps mariadb-libs
2)将 MySQL 安装包拷贝到/opt/software 目录下 解压 MySQL 安装包
tar -xf mysql-5.7.28-1.el7.x86_64.rpmbundle.tar
3)在安装目录下执行 rpm 安装
sudo rpm -ivh mysql-community-common-5.7.28-1.el7.x86_64.rpm
sudo rpm -ivh mysql-community-libs-5.7.28-1.el7.x86_64.rpm
sudo rpm -ivh mysql-community-libs-compat-5.7.28-1.el7.x86_64.rpm
sudo rpm -ivh mysql-community-client-5.7.28-1.el7.x86_64.rpm
sudo rpm -ivh mysql-community-server-5.7.28-1.el7.x86_64.rpm
注意:按照顺序依次执行
如果 Linux 是最小化安装的,在安装 mysql-community-server-5.7.28-1.el7.x86_64.rpm 时
可能会出现如下错误
警告:mysql-community-server-5.7.28-1.el7.x86_64.rpm: 头 V3 DSA/SHA1
Signature, 密钥 ID 5072e1f5: NOKEY
错误:依赖检测失败:
libaio.so.1()(64bit) 被 mysql-community-server-5.7.28-1.el7.x86_64
需要
libaio.so.1(LIBAIO_0.1)(64bit) 被 mysql-community-server-5.7.28-
1.el7.x86_64 需要
libaio.so.1(LIBAIO_0.4)(64bit) 被 mysql-community-server-5.7.28-
1.el7.x86_64 需要
通过 yum 安装缺少的依赖,然后重新安装 mysql-community-server-5.7.28-1.el7.x86_64 即 可
4)删除/etc/my.cnf 文件中 datadir 指向的目录下的所有内容
5)初始化数据库
sudo mysqld --initialize --user=mysql
6)查看临时生成的 root 用户的密码
sudo cat /var/log/mysqld.log
7)启动 MySQL 服务
sudo systemctl start mysqld
8)登录 MySQL 数据库
mysql -uroot -p
9)必须先修改 root 用户的密码,否则执行其他的操作会报错
set password = password("新密码");
10)修改 mysql 库下的 user 表中的 root 用户允许任意 ip 连接
update mysql.user set host='%' where user='root';
flush privileges; //刷新
Hive 元数据配置到 MySQL
1)拷贝驱动,将 MySQL 的 JDBC 驱动拷贝到 Hive 的 lib 目录下
cp /opt/software/mysql-connector-java-
5.1.37.jar $HIVE_HOME/lib
2)配置 Metastore 到 MySQL,在$HIVE_HOME/conf 目录下新建 hive-site.xml 文件
<?xml version="1.0"?>
<?xml-stylesheet type="text/xsl" href="configuration.xsl"?>
<configuration>
<!-- jdbc 连接的 URL -->
<property>
<name>javax.jdo.option.ConnectionURL</name>
<value>jdbc:mysql://hadoop102:3306/metastore?useSSL=false</value>
</property>
<!-- jdbc 连接的 Driver-->
<property>
<name>javax.jdo.option.ConnectionDriverName</name>
<value>com.mysql.jdbc.Driver</value>
</property>
<!-- jdbc 连接的 username-->
<property>
<name>javax.jdo.option.ConnectionUserName</name>
<value>root</value>
</property>
<!-- jdbc 连接的 password -->
<property>
<name>javax.jdo.option.ConnectionPassword</name>
<value>000000</value>
</property>
<!-- Hive 元数据存储版本的验证 -->
<property>
<name>hive.metastore.schema.verification</name>
<value>false</value>
</property>
<!--元数据存储授权-->
<property>
<name>hive.metastore.event.db.notification.api.auth</name>
<value>false</value>
</property>
<!-- Hive 默认在 HDFS 的工作目录 -->
<property>
<name>hive.metastore.warehouse.dir</name>
<value>/user/hive/warehouse</value>
</property>
</configuration>
3)登陆 MySQL,新建 Hive 元数据库
create database metastore;
4) 初始化 Hive 元数据库
schematool -initSchema -dbType mysql -verbose
使用元数据服务的方式访问 Hive
1)在 hive-site.xml 文件中添加如下配置信息
<!-- 指定存储元数据要连接的地址 -->
<property>
<name>hive.metastore.uris</name>
<value>thrift://hadoop102:9083</value>
</property>
Hive 常用交互命令
usage: hive
-d,--define <key=value> Variable subsitution to apply to hive
commands. e.g. -d A=B or --define A=B
--database <databasename> Specify the database to use
-e <quoted-query-string> SQL from command line
-f <filename> SQL from files
-H,--help Print help information
--hiveconf <property=value> Use value for given property
--hivevar <key=value> Variable subsitution to apply to hive
commands. e.g. --hivevar A=B
-i <filename> Initialization SQL file
-S,--silent Silent mode in interactive shell
-v,--verbose Verbose mode (echo executed SQL to the
console)
以上是关于大数据技术之Hive的主要内容,如果未能解决你的问题,请参考以下文章