MongoDB基础以及一些聚合操作
Posted 圆圆的球
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了MongoDB基础以及一些聚合操作相关的知识,希望对你有一定的参考价值。
MongoDB基础以及一些聚合操作
--洱涷zZ
前情提要
1.学习MongoDB的几大难点
- MongoDB是一种非关系型数据库,从mysql转变到Mongo需要摒弃传统的关系型数据库理念,不然很有可能会用一种错误的方式去使用和设计
- MongoDB基于JSON数据库模型,其鼓励使用更多的文档嵌套方式来减少多表关联的设计,从而达到易用,高性能的目的,但是这种反范式的文档模型设计,目前没有完整的理论支持,即:即使想系统的学习,也没有太好的书籍和材料供参考
- MongoDB通过分片来进行横向扩展,分片的设计和调优相对复杂,主要是要考虑其本身的一些技术实现和底层原理,以及数据均衡带来的性能影响,这方面需要深度学习
2.学习MongoDB的目的
- 理解MongoDB的意义,了解使用它的场景和价值
- 什么是文档模式设计,以及其数据安全、事务…
- 掌握进阶的架构设计方法以及实践的案例,比如:两地三中心,数据中台…
MongoDB的特色
| MongoDB | RDBMS(传统的关系型数据库) | |
|---|---|---|
| 数据模型 | json文档模型 | 关系模型 |
| 数据库类别 | OLTP | OLTP |
| CRUD操作 | MQL/SQL(非主流) | SQL |
| 高可用 | 复制集(默认高可用部署) | 集群模式 |
| 横向扩展能力 | 通过原生分片完善支持(特色) | 主从复制,集群和分片 |
| 索引支持 | 以B树为基础的全文索引、地理位置索引… | B树,B+树,hash索引… |
| 开发难度 | 易 | 复杂 |
| 数据容量 | 没有理论上限 | 千万、亿 |
注:OLTP(用来做前端交互式应用,也称为面向交易的处理过程,其基本特征是前台接收的用 户数据可以立即传送到计算中心进行处理,并在很短的时间内给出处理结果,是对用户操 作快速响应的方式之一)
OLAP(用来做后端离线批处理的分析型场景,对OLTP数据库中的数据进行再加工,从这 些海量的业务数据中提取出对企业决策分析有用的信息)
MongoDB的一些基础操作以及引伸的一些问题
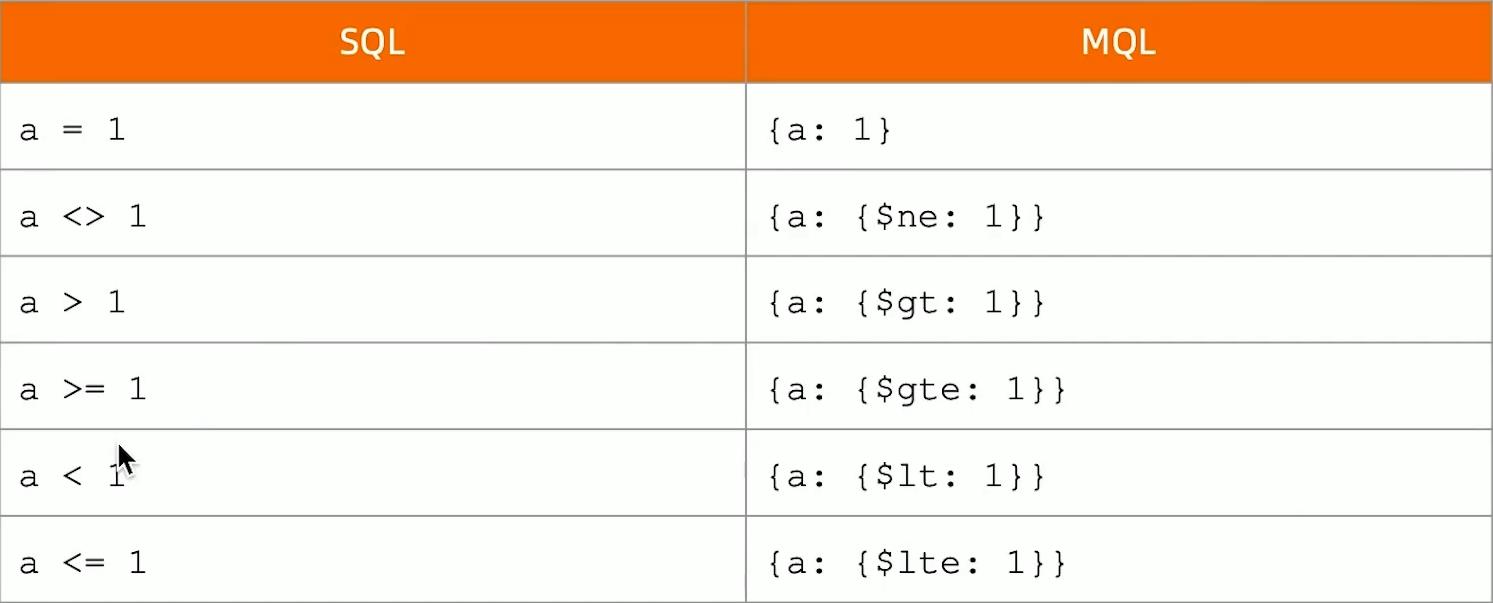
1. MQL和SQL的条件查询对照表

2. 关于MongoDB基础增删改
-
创建
创建数据库 use user; 创建集合 db.createCollection("phone"); 创建固定集合 db.createCollection("company", capped: true, autoIndexId: true, size: 6142800, max: 10000 ); -
展示
展示所有的数据库 show dbs; 展示所有的集合 show collections; -
插入数据
插入一条数据 db.userDetail.insertOne( title: 'MongoDB', description: 'MongoDB 是一个 Nosql 数据库', by: 'xiaochen', url: 'www.baidu.com', tags: ['mongodb', 'database', 'NoSQL'], likes: 100 ) 一次插入多条数据 db.userDetail.insertMany([ title: 'MongoDB1', description: 'MongoDB 是一个 Nosql 数据库', by: 'xiaochen', url: 'www.baidu.com', tags: ['mongodb', 'database', 'NoSQL'], likes: 100 , title: 'MongoDB2', description: 'MongoDB 是一个 Nosql 数据库', by: 'xiaochen', url: 'www.baidu.com', tags: ['mongodb', 'database', 'NoSQL'], likes: 100 , title: 'MongoDB3', description: 'MongoDB 是一个 Nosql 数据库', by: 'xiaochen', url: 'www.baidu.com', tags: ['mongodb', 'database', 'NoSQL'], likes: 100 ]) 将集合定义为变量,并且插入 data = title: 'MongoDB', description: 'MongoDB 是一个 Nosql 数据库', by: 'xiaochen', url: 'http://www.baidu.cn', tags: ['mongodb', 'database', 'NoSQL'], likes: 100 ; db.user.insertOne(data) -
删除
删除数据库 db.dropDatabase(); 删除集合 db.collection.drop(); db.user.remove(a: 1)//删除a=1的记录 db.user.remove(a: $lt: 5)//删除a小于1的记录 db.user.remove()//删除所有记录 -
更新
update操作的执行格式 db.<集合>.update(<查询字段>,<更新字段>) db.fruit.updateone(name:"apple",$set:from:"china") 会给这条数据增加一个from:china的属性注:使用updateOne表示条件无论匹配到多少条数据,只会更新第一条,updateMany是匹配多少,更新多少
注:updateOne/updateMany方法要求更新条件部分必须具有以下之一,否则将报错
- $set / $unset
- $push / $pushAll / $pop (增加一个对象到数组底部、增加多个对象到数组底部、从数组底部删除一个对象)
- $pull / $pullAll(如果匹配指定的值,从数组中删除相应的对象、如果匹配到任意的值,从数据中删除相应的对象)
- $addToSet(如果不存在则增加一个值到数组)
3. 关于MongoDB的查操作
-
MongoDB的通用查操作
db.getCollection("user").find(); db.movies.find("year": 1975)//单条件查询 db.movies.find("year": 1975, "title": "Batman")//多条件and查询 db.movies.find($and: ["year": 1975, "title": "Batman"])//and的另外一种形式 db.movies.find($or: ["year": 1975, "title": "Batman"])//多条件or查询 db.movies.find("title": /^B/)//按照正则表达式去找 -
关于查操作,find返回的是游标
那么什么是游标呢?
通俗的说,游标不是查询结果,而是查询返回的资源或接口,通过此接口可逐条读取,可以理解为java里的iterator,数据库使用游标返回find查询结果,客户端对游标的实现通常能对最终结果进行有效的控制。可限制结果的数量,略过部分结果,根据任意方向任意键的组合对结果进行各种排序,或是执行其他一些更🐂的操作。
当调用find()时,shell并不立即查询数据库,而是等待真正开始要求获取结果的时候才发送查询,这样在执行之前给查询额外的选项。几乎所有游标对象的方法都返回游标本身,这样可按任意顺序组成方法链。
在服务端,游标消耗内存和其他资源,游标遍历尽结果后,或客户端发来消息要求终止,数据库将会释放这些资源。释放的资源可被数据库换做他用以保证尽快释放游标。
# 声明游标 var cursor = db.bar.find();要想从shell中创建一个游标,首先要对集合填充文档然后对其查询,并将结果分配给一个局部变量。
# 判断游标是否取到尽头 cursor.hasNext() # 获取游标的下一个单元 cursor.next()要迭代结果可使用游标的next(),也可使用hasNext()来查看是否有结果。
游标的迭代:
var cursor = db.foo.find(); while(cursor.hasNext()) //do stuff var next = cursor.next();游标类实现了迭代器接口,可在 foreach 循环中使用。游标中有一个迭代函数,允许自定义回调函数来逐个处理每个单元。
var cursor = db.foo.find(); cursor.forEach(function(item) var name = item.name; )游标在分页中的应用:
# 查到10000行跳过100页后取10行 var cursor = db.foo.find().skip(10000).limit(10); cursor.forEach(function(item) printjson(item); )游标的销毁
- 客户端发来信息让其销毁
- 游标迭代完毕
- 默认游标超过10分钟自动清除
导致游标终止随后被清理的情况
首先,当游标完成匹配结果的迭代时,它会清除自身。另外,当游标在客户端已不在作用域内了,驱动会向服务器发送专门的消息,让其销毁。最后,即时用户也没有迭代完所有结果,游标也还在作用域中,10分钟不适用,数据库游标也会自动销毁。这种超时销毁的行为是我们希望的,极少有应用程序希望用户耗费时间等待结果。然而,的确有些适用希望游标持续的时间长一些,这种情况下多数驱动实现了一个叫做immortal()或类似机制,来告知数据库不要让游标超时。若关闭游标的超时时间,则一定要在迭代完结果后将其关闭,否则会一直在数据库中消耗服务器资源。
-
find支持使用"field.sub_field"的形式查询子文档
db.fruit.insertOne(name: "apple", from: country: "China", province: "XiAn") db.fruit.find("from.country": "china") -
在数组中搜索子对象的多个字段时,如果使用
$elemMatch,它表示必须是同一个子对象满足多个条件db.getCollection('movies').find("filming_locations": $elemMarch: "city": "Rome", "country": "USA") -
通过Mongo的投影机制可以获取文档中的某几个字段:
_id代表不返回db.movies.find("category":"action","_id":0,title:1)//代表返回title不返回id
MongoDB聚合框架
1. 什么是MongoDB的聚合框架
MongoDB聚合框架(Aggregation Framework)是一个计算框架,它可以作用在一个或几个集合上然后对集合中的数据进行一系列的运算并将这些数据转化为期望的形式。
从效果上来说,它比较像SQL查询中的GROUP BY、LEFT OUTER JOIN、AS等等
2. 管道(pipeLine)和步骤(stage)
整个聚合运算过程称之为管道,可以理解为我们java中的stream流式操作,它是由多个步骤组成,每个管道的执行流程如下:
- 接受一系列文档(原始数据)
- 每个步骤对这些文档进行一系列运算
- 结果文档输出给下一个步骤

3. 聚合运算的基本格式
pipeline = [$stage1, $stage2... $stageN]
db.<COLLECTION>.aggregate(
pipeline,
options
)
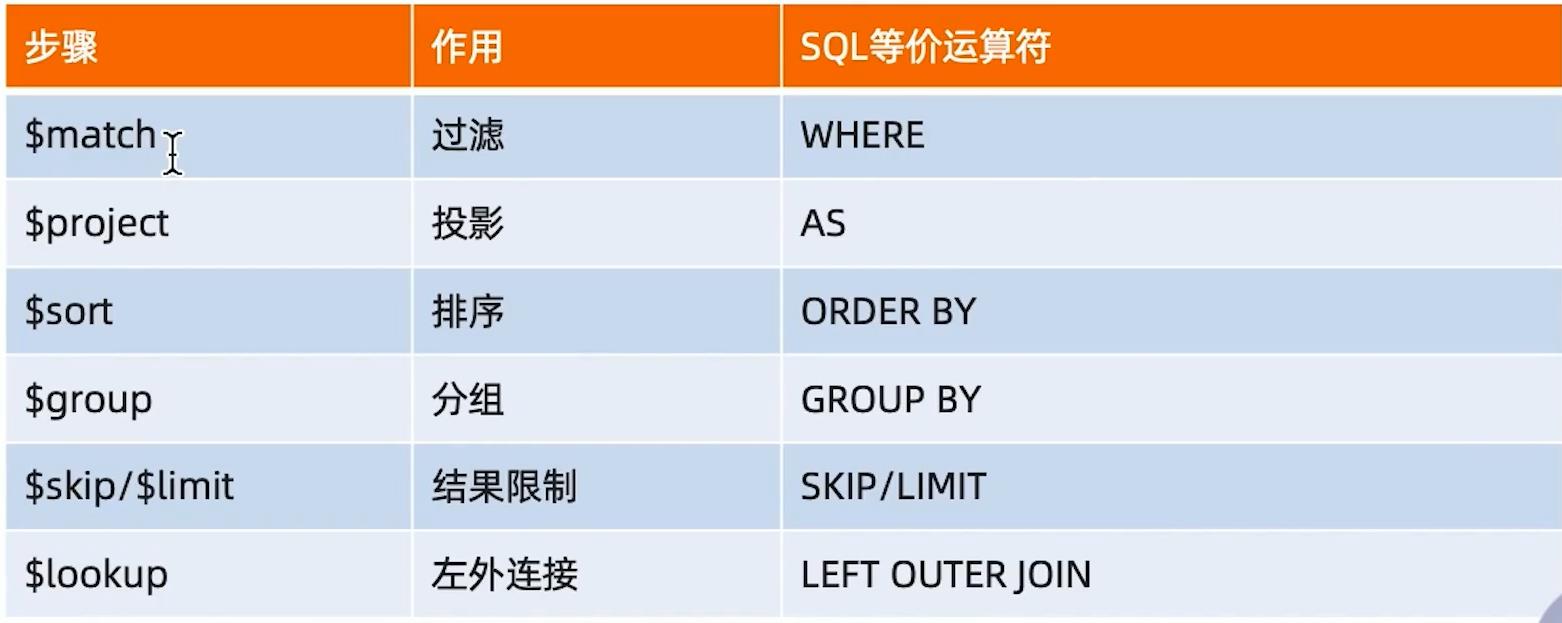
4. 常见步骤

5. 聚合运算的一些例子
举一些SQL的常见栗子然后与相应的MQL进行对比:
-
查找第100到第120个员工的姓和名
select first_name AS '名' last_name AS '姓' from users where gender = '男' skip 100 limit 20 其对应的MQL为: db.users.aggregate([ $match: gender:'男', $skip:100, $limit:20, $project: '名':'$first_name', '姓':'$last_name' ]) -
在人数小于10的部门里查找性别为女的员工的所属部门以及汇总
select department,count() as emp_qty from users where gender = '女' group by department having count(*) < 10 其对应的MQL为: db.users.aggregate([ $match:gender:'女', $group: _id:'$department', emp_qty:$sum:1 , $match:emp_qty:$lt:10 ]) -
MQL的特有步骤
$unwind:将数组打平db.students.findOne() name:'张三', score:[ subject:'语文',score:184, subject:'数学',score:194, subject:'外语',score:104 ] db.students.aggregate([$unwind:'$score']) 结果: name:'张三',score:subject:'语文',score:184 name:'张三',score:subject:'数学',score:194 name:'张三',score:subject:'外语',score:104
以上是关于MongoDB基础以及一些聚合操作的主要内容,如果未能解决你的问题,请参考以下文章