MySql窗口函数
Posted
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了MySql窗口函数相关的知识,希望对你有一定的参考价值。
参考技术Amysql从8.0开始支持窗口函数。也就是分析函数
序号函数:ROW_NUMBER()、RANK()、DENSE_RANK()
分布函数:PERCENT_RANK()、CUME_DIST()
前后函数:LAG()、LEAD()
头尾函数:FIRST_VALUE()、LAST_VALUE()
其它函数:NTH_VALUE()、NTILE()
例子:
首先有一个表字段:id score(分数)user_id
1.序号函数:ROW_NUMBER()、RANK()、DENSE_RANK()
用途:显示分区中的当前行号,对查询结果进行排序.
ROW_NUMBER():顺序排序——1、2、3 RANK():并列排序,跳过重复序号——1、1、3 DENSE_RANK():并列排序,不跳过重复序号——1、1、2
执行sql:
2.分布函数:PERCENT_RANK()、CUME_DIST()
用途:每行按照公式(rank-1) / (rows-1)进行计算。其中,rank为RANK()函数产生的序号,rows为当前窗口的记录总行数
3.前后函数:LAG()、LEAD()
LAG和LEAD分析函数可以在同一次查询中取出同一字段的前N行的数据(LAG)和后N行的数据(LEAD)作为独立的列
在实际应用当中,若要用到取今天和昨天的某字段差值时,LAG和LEAD函数的应用就显得尤为重要。当然,这种操作可以用表的自连接实现,但是LAG和LEAD与LEFT JOIN、RIGHT JOIN等自连接相比,效率更高,SQL更简洁。下面我就对这两个函数做一个简单的介绍。
函数语法如下:
lag(exp_str,offset,defval) OVER(PARTITION BY …ORDER BY …)
lead(exp_str,offset,defval) OVER(PARTITION BY …ORDER BY …)
参数说明:
exp_str是字段名
offset是偏移量,即是上1个或上N个的值,假设当前行在表中排在第10行,则offset 为3,则表示我们所要找的数据行就是表中的第7行(即10-3=7)。
defval默认值,当两个函数取上N/下N个值,当在表中从当前行位置向前数N行已经超出了表的范围时,LAG()函数将defval这个参数值作为函数的返回值,若没有指定默认值,则返回NULL,那么在数学运算中,总要给一个默认值才不会出错。
执行sql:
以第一行为例:4.0上一条记录(lag)是没有的,所有有赋予默认值0,4.0的下一条记录(lead)还是4.0,可以通过偏移量调整上下N条记录
注意:这里是序号的上一条或下一条
4.头尾函数:FIRST_VALUE(expr)、LAST_VALUE(expr)
用途:返回第一个(FIRST_VALUE(expr))或最后一个(LAST_VALUE(expr))expr的值
执行sql:
FIRST_VALUE()的结果容易理解,直接在结果的所有行记录中输出同一个满足条件的首个记录;
LAST_VALUE()默认统计范围是 rows between unbounded preceding and current row,也就是取当前行数据与当前行之前的数据的比较。
那么如果我们直接在每行数据中显示最后的那个数据,需在order by 条件的后面加上语句: rows between unbounded preceding and unbounded following , 也就是前面无界和后面无界之间的行比较。
加上语句,执行sql:
结果:
简单理解就是,取最大的还是最小的结合ORDER BY使用,或者取第一个还是或者最后一个
参考: https://baijiahao.baidu.com/s?id=1728966619393719484&wfr=spider&for=pc
Mysql窗口函数
窗口函数
MySQL从8.0版本开始支持窗口函数,其中,窗口可以理解为数据的集合。窗口函数也就是在符合某种条件或者某些条件的记录集合中执行的函数,窗口函数会在每条记录上执行。窗口函数可以分为静态窗口函数和动态窗口函数,其中,静态窗口函数的窗口大小是固定的,不会因为记录的不同而不同;动态窗口函数的窗口大小会随着记录的不同而变化。
窗口函数总体上可以分为序号函数、分布函数、前后函数、首尾函数和其他函数,如表11-5所示。
表11-5 MySQL窗口函数分类
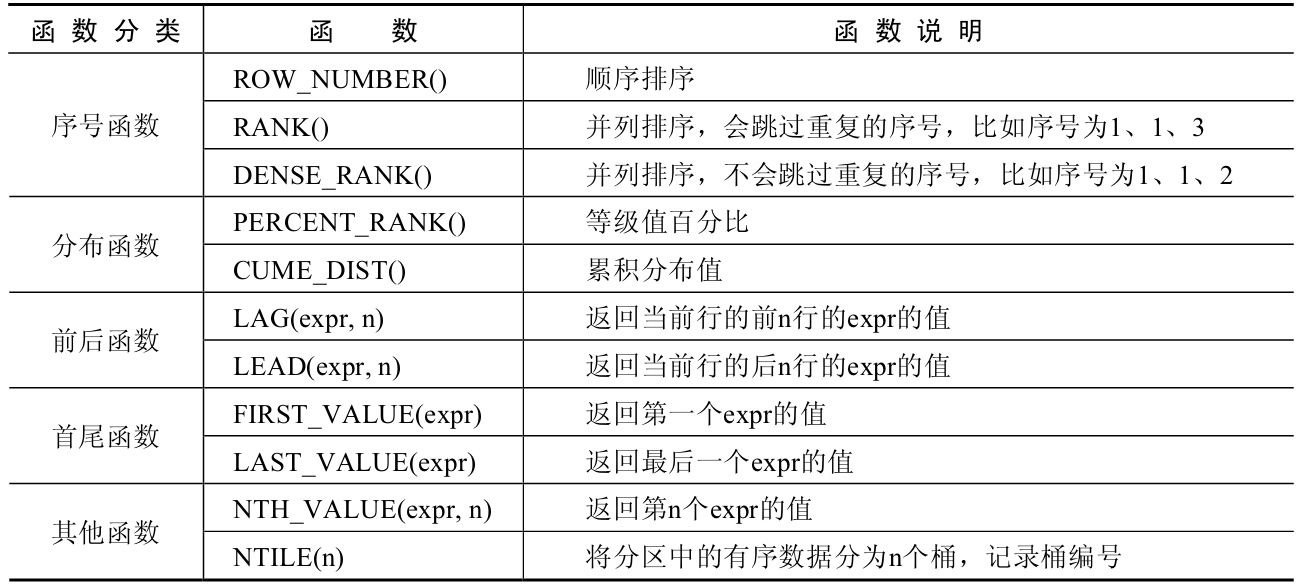
窗口函数的基本用法格式如下:
函数名 ([expr]) over子句
over关键字指定函数窗口的范围,如果省略后面括号中的内容,则窗口会包含满足WHERE条件的所有记录,窗口函数会基于所有满足WHERE条件的记录进行计算。如果over关键字后面的括号不为空,则可以使用如下语法设置窗口。
·window_name:为窗口设置一个别名,用来标识窗口。
·PARTITION BY子句:指定窗口函数按照哪些字段进行分组。分组后,窗口函数可以在每个分组中分别执行。
·ORDER BY子句:指定窗口函数按照哪些字段进行排序。执行排序操作使窗口函数按照排序后的数据记录的顺序进行编号。
·FRAME子句:为分区中的某个子集定义规则,可以用来作为滑动窗口使用。
以第8章中创建的t_goods数据表为例,向t_goods数据表中插入数据。
mysql> INSERT INTO t_goods (t_category_id, t_category, t_name, t_price, t_stock, t_upper_time) VALUES
-> (1, '女装/女士精品', 'T恤', 39.90, 1000, '2020-11-10 00:00:00'),
-> (1, '女装/女士精品', '连衣裙', 79.90, 2500, '2020-11-10 00:00:00'),
-> (1, '女装/女士精品', '卫衣', 89.90, 1500, '2020-11-10 00:00:00'),
-> (1, '女装/女士精品', '牛仔裤', 89.90, 3500, '2020-11-10 00:00:00'),
-> (1, '女装/女士精品', '百褶裙', 29.90, 500, '2020-11-10 00:00:00'),
-> (1, '女装/女士精品', '呢绒外套', 399.90, 1200, '2020-11-10 00:00:00'),
-> (2, '户外运动', '自行车', 399.90, 1000, '2020-11-10 00:00:00'),
-> (2, '户外运动', '山地自行车', 1399.90, 2500, '2020-11-10 00:00:00'),
-> (2, '户外运动', '登山杖', 59.90, 1500, '2020-11-10 00:00:00'),
-> (2, '户外运动', '骑行装备', 399.90, 3500, '2020-11-10 00:00:00'),
-> (2, '户外运动', '运动外套', 799.90, 500, '2020-11-10 00:00:00'),
-> (2, '户外运动', '滑板', 499.90, 1200, '2020-11-10 00:00:00');
Query OK, 12 rows affected (0.01 sec)
Records: 12 Duplicates: 0 Warnings: 0
下面针对t_goods表中的数据来验证每个窗口函数的功能。
序号函数
1.ROW_NUMBER()函数
ROW_NUMBER()函数能够对数据中的序号进行顺序显示。
例如,查询t_goods数据表中每个商品分类下价格最高的3种商品信息。
mysql> SELECT * FROM
-> (
-> SELECT
-> ROW_NUMBER() OVER(PARTITION BY t_category_id ORDER BY t_price DESC) AS row_num,
-> id, t_category_id, t_category, t_name, t_price, t_stock
-> FROM t_goods) t
-> WHERE row_num <= 3;
+---------+----+---------------+---------------------+-----------------+---------+---------+
| row_num | id | t_category_id | t_category | t_name | t_price | t_stock |
+---------+----+---------------+---------------------+-----------------+---------+---------+
| 1 | 6 | 1 | 女装/女士精品 | 呢绒外套 | 399.90 | 1200 |
| 2 | 3 | 1 | 女装/女士精品 | 卫衣 | 89.90 | 1500 |
| 3 | 4 | 1 | 女装/女士精品 | 牛仔裤 | 89.90 | 3500 |
| 1 | 8 | 2 | 户外运动 | 山地自行车 | 1399.90 | 2500 |
| 2 | 11 | 2 | 户外运动 | 运动外套 | 799.90 | 500 |
| 3 | 12 | 2 | 户外运动 | 滑板 | 499.90 | 1200 |
+---------+----+---------------+---------------------+-----------------+---------+---------+
6 rows in set (0.00 sec)
在名称为“女装/女士精品”的商品类别中,有两款商品的价格为89.90元,分别是卫衣和牛仔裤。两款商品的序号都应该为2,而不是一个为2,另一个为3。此时,可以使用RANK()函数和DENSE_RANK()函数解决。
2.RANK()函数
使用RANK()函数能够对序号进行并列排序,并且会跳过重复的序号,比如序号为1、1、3。
例如,使用RANK()函数获取t_goods数据表中类别为“女装/女士精品”的价格最高的4款商品信息。
mysql> SELECT * FROM
-> (
-> SELECT
-> RANK() OVER(PARTITION BY t_category_id ORDER BY t_price DESC) AS row_num,
-> id, t_category_id, t_category, t_name, t_price, t_stock
-> FROM t_goods) t
-> WHERE t_category_id = 1 AND row_num <= 4;
+---------+----+---------------+---------------------+--------------+---------+---------+
| row_num | id | t_category_id | t_category | t_name | t_price | t_stock |
+---------+----+---------------+---------------------+--------------+---------+---------+
| 1 | 6 | 1 | 女装/女士精品 | 呢绒外套 | 399.90 | 1200 |
| 2 | 3 | 1 | 女装/女士精品 | 卫衣 | 89.90 | 1500 |
| 2 | 4 | 1 | 女装/女士精品 | 牛仔裤 | 89.90 | 3500 |
| 4 | 2 | 1 | 女装/女士精品 | 连衣裙 | 79.90 | 2500 |
+---------+----+---------------+---------------------+--------------+---------+---------+
4 rows in set (0.00 sec)
可以看到,使用RANK()函数得出的序号为1、2、2、4,相同价格的商品序号相同,后面的商品序号是不连续的,跳过了重复的序号。
3.DENSE_RANK()函数
DENSE_RANK()函数对序号进行并列排序,并且不会跳过重复的序号,比如序号为1、1、2。
例如,使用DENSE_RANK()函数获取t_goods数据表中类别为“女装/女士精品”的价格最高的4款商品信息。
mysql> SELECT * FROM
-> (
-> SELECT
-> DENSE_RANK() OVER(PARTITION BY t_category_id ORDER BY t_price DESC) AS row_num,
-> id, t_category_id, t_category, t_name, t_price, t_stock
-> FROM t_goods) t
-> WHERE t_category_id = 1 AND row_num <= 3;
+---------+----+---------------+---------------------+--------------+---------+---------+
| row_num | id | t_category_id | t_category | t_name | t_price | t_stock |
+---------+----+---------------+---------------------+--------------+---------+---------+
| 1 | 6 | 1 | 女装/女士精品 | 呢绒外套 | 399.90 | 1200 |
| 2 | 3 | 1 | 女装/女士精品 | 卫衣 | 89.90 | 1500 |
| 2 | 4 | 1 | 女装/女士精品 | 牛仔裤 | 89.90 | 3500 |
| 3 | 2 | 1 | 女装/女士精品 | 连衣裙 | 79.90 | 2500 |
+---------+----+---------------+---------------------+--------------+---------+---------+
4 rows in set (0.00 sec)
可以看到,使用DENSE_RANK()函数得出的行号为1、2、2、3,相同价格的商品序号相同,后面的商品序号是连续的,并且没有跳过重复的序号。
2 分布函数
1.PERCENT_RANK()函数
PERCENT_RANK()函数是等级值百分比函数。按照如下方式进行计算。
(rank - 1) / (rows - 1)
其中,rank的值为使用RANK()函数产生的序号,rows的值为当前窗口的总记录数。
例如,计算t_goods数据表中名称为“女装/女士精品”的类别下的商品的PERCENT_RANK值。
mysql> SELECT
-> RANK() OVER w AS r,
-> PERCENT_RANK() OVER w AS pr,
-> id, t_category_id, t_category, t_name, t_price, t_stock
-> FROM t_goods
-> WHERE t_category_id = 1
-> WINDOW w AS (PARTITION BY t_category_id ORDER BY t_price DESC);
+---+-----+----+---------------+---------------------+--------------+---------+---------+
| r | pr | id | t_category_id | t_category | t_name | t_price | t_stock |
+---+-----+----+---------------+---------------------+--------------+---------+---------+
| 1 | 0 | 6 | 1 | 女装/女士精品 | 呢绒外套 | 399.90 | 1200 |
| 2 | 0.2 | 3 | 1 | 女装/女士精品 | 卫衣 | 89.90 | 1500 |
| 2 | 0.2 | 4 | 1 | 女装/女士精品 | 牛仔裤 | 89.90 | 3500 |
| 4 | 0.6 | 2 | 1 | 女装/女士精品 | 连衣裙 | 79.90 | 2500 |
| 5 | 0.8 | 1 | 1 | 女装/女士精品 | T恤 | 39.90 | 1000 |
| 6 | 1 | 5 | 1 | 女装/女士精品 | 百褶裙 | 29.90 | 500 |
+---+-----+----+---------------+---------------------+--------------+---------+---------+
6 rows in set (0.00 sec)
2.CUME_DIST()函数
CUME_DIST()函数主要用于查询小于或等于某个值的比例。
例如,查询t_goods数据表中小于或等于当前价格的比例。
mysql> SELECT
-> CUME_DIST() OVER(PARTITION BY t_category_id ORDER BY t_price DESC) AS cd,
-> id, t_category, t_name, t_price
-> FROM t_goods;
+---------------------+----+---------------------+-----------------+---------+
| cd | id | t_category | t_name | t_price |
+---------------------+----+---------------------+-----------------+---------+
| 0.16666666666666666 | 6 | 女装/女士精品 | 呢绒外套 | 399.90 |
| 0.5 | 3 | 女装/女士精品 | 卫衣 | 89.90 |
| 0.5 | 4 | 女装/女士精品 | 牛仔裤 | 89.90 |
| 0.6666666666666666 | 2 | 女装/女士精品 | 连衣裙 | 79.90 |
| 0.8333333333333334 | 1 | 女装/女士精品 | T恤 | 39.90 |
| 1 | 5 | 女装/女士精品 | 百褶裙 | 29.90 |
| 0.16666666666666666 | 8 | 户外运动 | 山地自行车 | 1399.90 |
| 0.3333333333333333 | 11 | 户外运动 | 运动外套 | 799.90 |
| 0.5 | 12 | 户外运动 | 滑板 | 499.90 |
| 0.8333333333333334 | 7 | 户外运动 | 自行车 | 399.90 |
| 0.8333333333333334 | 10 | 户外运动 | 骑行装备 | 399.90 |
| 1 | 9 | 户外运动 | 登山杖 | 59.90 |
+---------------------+----+---------------------+-----------------+---------+
12 rows in set (0.01 sec)
前后函数
1.LAG(expr,n)函数
LAG(expr,n)函数返回当前行的前n行的expr的值。
例如,查询t_goods数据表中前一个商品价格与当前商品价格的差值。
mysql> SELECT id, t_category, t_name, t_price, pre_price,
-> t_price - pre_price AS diff_price
-> FROM (
-> SELECT id, t_category, t_name, t_price,
-> LAG(t_price,1) OVER w AS pre_price
-> FROM t_goods
-> WINDOW w AS (PARTITION BY t_category_id ORDER BY t_price)) t;
+----+---------------------+-----------------+---------+-----------+------------+
| id | t_category | t_name | t_price | pre_price | diff_price |
+----+---------------------+-----------------+---------+-----------+------------+
| 5 | 女装/女士精品 | 百褶裙 | 29.90 | NULL | NULL |
| 1 | 女装/女士精品 | T恤 | 39.90 | 29.90 | 10.00 |
| 2 | 女装/女士精品 | 连衣裙 | 79.90 | 39.90 | 40.00 |
| 3 | 女装/女士精品 | 卫衣 | 89.90 | 79.90 | 10.00 |
| 4 | 女装/女士精品 | 牛仔裤 | 89.90 | 89.90 | 0.00 |
| 6 | 女装/女士精品 | 呢绒外套 | 399.90 | 89.90 | 310.00 |
| 9 | 户外运动 | 登山杖 | 59.90 | NULL | NULL |
| 7 | 户外运动 | 自行车 | 399.90 | 59.90 | 340.00 |
| 10 | 户外运动 | 骑行装备 | 399.90 | 399.90 | 0.00 |
| 12 | 户外运动 | 滑板 | 499.90 | 399.90 | 100.00 |
| 11 | 户外运动 | 运动外套 | 799.90 | 499.90 | 300.00 |
| 8 | 户外运动 | 山地自行车 | 1399.90 | 799.90 | 600.00 |
+----+---------------------+-----------------+---------+-----------+------------+
12 rows in set (0.00 sec)
2.LEAD(expr,n)函数
LEAD(expr,n)函数返回当前行的后n行的expr的值。
例如,查询t_goods数据表中后一个商品价格与当前商品价格的差值。
mysql> SELECT id, t_category, t_name, behind_price, t_price,
-> behind_price - t_price AS diff_price
-> FROM(
-> SELECT id, t_category, t_name, t_price,
-> LEAD(t_price, 1) OVER w AS behind_price
-> FROM t_goods
-> WINDOW w AS (PARTITION BY t_category_id ORDER BY t_price)) t;
+----+---------------------+-----------------+--------------+---------+------------+
| id | t_category | t_name | behind_price | t_price | diff_price |
+----+---------------------+-----------------+--------------+---------+------------+
| 5 | 女装/女士精品 | 百褶裙 | 39.90 | 29.90 | 10.00 |
| 1 | 女装/女士精品 | T恤 | 79.90 | 39.90 | 40.00 |
| 2 | 女装/女士精品 | 连衣裙 | 89.90 | 79.90 | 10.00 |
| 3 | 女装/女士精品 | 卫衣 | 89.90 | 89.90 | 0.00 |
| 4 | 女装/女士精品 | 牛仔裤 | 399.90 | 89.90 | 310.00 |
| 6 | 女装/女士精品 | 呢绒外套 | NULL | 399.90 | NULL |
| 9 | 户外运动 | 登山杖 | 399.90 | 59.90 | 340.00 |
| 7 | 户外运动 | 自行车 | 399.90 | 399.90 | 0.00 |
| 10 | 户外运动 | 骑行装备 | 499.90 | 399.90 | 100.00 |
| 12 | 户外运动 | 滑板 | 799.90 | 499.90 | 300.00 |
| 11 | 户外运动 | 运动外套 | 1399.90 | 799.90 | 600.00 |
| 8 | 户外运动 | 山地自行车 | NULL | 1399.90 | NULL |
+----+---------------------+-----------------+--------------+---------+------------+
12 rows in set (0.00 sec)
首尾函数
1.FIRST_VALUE(expr)函数
FIRST_VALUE(expr)函数返回第一个expr的值。
例如,按照价格排序,查询第1个商品的价格信息。
mysql> SELECT id, t_category, t_name, t_price, t_stock,
-> FIRST_VALUE(t_price) OVER w AS first_price
-> FROM t_goods
-> WINDOW w AS (PARTITION BY t_category_id ORDER BY t_price);
+----+---------------------+-----------------+---------+---------+-------------+
| id | t_category | t_name | t_price | t_stock | first_price |
+----+---------------------+-----------------+---------+---------+-------------+
| 5 | 女装/女士精品 | 百褶裙 | 29.90 | 500 | 29.90 |
| 1 | 女装/女士精品 | T恤 | 39.90 | 1000 | 29.90 |
| 2 | 女装/女士精品 | 连衣裙 | 79.90 | 2500 | 29.90 |
| 3 | 女装/女士精品 | 卫衣 | 89.90 | 1500 | 29.90 |
| 4 | 女装/女士精品 | 牛仔裤 | 89.90 | 3500 | 29.90 |
| 6 | 女装/女士精品 | 呢绒外套 | 399.90 | 1200 | 29.90 |
| 9 | 户外运动 | 登山杖 | 59.90 | 1500 | 59.90 |
| 7 | 户外运动 | 自行车 | 399.90 | 1000 | 59.90 |
| 10 | 户外运动 | 骑行装备 | 399.90 | 3500 | 59.90 |
| 12 | 户外运动 | 滑板 | 499.90 | 1200 | 59.90 |
| 11 | 户外运动 | 运动外套 | 799.90 | 500 | 59.90 |
| 8 | 户外运动 | 山地自行车 | 1399.90 | 2500 | 59.90 |
+----+---------------------+-----------------+---------+---------+-------------+
12 rows in set (0.00 sec)
2.LAST_VALUE(expr)函数
LAST_VALUE(expr)函数返回最后一个expr的值。
例如,按照价格排序,查询最后一个商品的价格信息。
mysql> SELECT id, t_category, t_name, t_price, t_stock,
-> LAST_VALUE(t_price) OVER w AS last_price
-> FROM t_goods
-> WINDOW w AS (PARTITION BY t_category_id ORDER BY t_price);
+----+---------------------+-----------------+---------+---------+------------+
| id | t_category | t_name | t_price | t_stock | last_price |
+----+---------------------+-----------------+---------+---------+------------+
| 5 | 女装/女士精品 | 百褶裙 | 29.90 | 500 | 29.90 |
| 1 | 女装/女士精品 | T恤 | 39.90 | 1000 | 39.90 |
| 2 | 女装/女士精品 | 连衣裙 | 79.90 | 2500 | 79.90 |
| 3 | 女装/女士精品 | 卫衣 | 89.90 | 1500 | 89.90 |
| 4 | 女装/女士精品 | 牛仔裤 | 89.90 | 3500 | 89.90 |
| 6 | 女装/女士精品 | 呢绒外套 | 399.90 | 1200 | 399.90 |
| 9 | 户外运动 | 登山杖 | 59.90 | 1500 | 59.90 |
| 7 | 户外运动 | 自行车 | 399.90 | 1000 | 399.90 |
| 10 | 户外运动 | 骑行装备 | 399.90 | 3500 | 399.90 |
| 12 | 户外运动 | 滑板 | 499.90 | 1200 | 499.90 |
| 11 | 户外运动 | 运动外套 | 799.90 | 500 | 799.90 |
| 8 | 户外运动 | 山地自行车 | 1399.90 | 2500 | 1399.90 |
+----+---------------------+-----------------+---------+---------+------------+
12 rows in set (0.00 sec)
其他函数
1.NTH_VALUE(expr,n)函数
NTH_VALUE(expr,n)函数返回第n个expr的值。
例如,查询t_goods数据表中排名第3和第4的价格信息。
mysql> SELECT id, t_category, t_name, t_price,
-> NTH_VALUE(t_price,2) OVER w AS second_price,
-> NTH_VALUE(t_price,3) OVER w AS third_price
-> FROM t_goods
-> WINDOW w AS (PARTITION BY t_category_id ORDER BY t_price);
+----+---------------------+-----------------+---------+--------------+-------------+
| id | t_category | t_name | t_price | second_price | third_price |
+----+---------------------+-----------------+---------+--------------+-------------+
| 5 | 女装/女士精品 | 百褶裙 | 29.90 | NULL | NULL |
| 1 | 女装/女士精品 | T恤 | 39.90 | 39.90 | NULL |
| 2 | 女装/女士精品 | 连衣裙 | 79.90 | 39.90 | 79.90 |
| 3 | 女装/女士精品 | 卫衣 | 89.90 | 39.90 | 79.90 |
| 4 | 女装/女士精品 | 牛仔裤 | 89.90 | 39.90 | 79.90 |
| 6 | 女装/女士精品 | 呢绒外套 | 399.90 | 39.90 | 79.90 |
| 9 | 户外运动 | 登山杖 | 59.90 | NULL | NULL |
| 7 | 户外运动 | 自行车 | 399.90 | 399.90 | 399.90 |
| 10 | 户外运动 | 骑行装备 | 399.90 | 399.90 | 399.90 |
| 12 | 户外运动 | 滑板 | 499.90 | 399.90 | 399.90 |
| 11 | 户外运动 | 运动外套 | 799.90 | 399.90 | 399.90 |
| 8 | 户外运动 | 山地自行车 | 1399.90 | 399.90 | 399.90 |
+----+---------------------+-----------------+---------+--------------+-------------+
12 rows in set (0.00 sec)
2.NTILE(n)函数
NTILE(n)函数将分区中的有序数据分为n个桶,记录桶编号。
例如,将t_goods表中的商品按照价格分为3组。
mysql> SELECT
-> NTILE(3) OVER w AS nt,
-> id, t_category, t_name, t_price
-> FROM t_goods
-> WINDOW w AS (PARTITION BY t_category_id ORDER BY t_price);
+------+----+---------------------+-----------------+---------+
| nt | id | t_category | t_name | t_price |
+------+----+---------------------+-----------------+---------+
| 1 | 5 | 女装/女士精品 | 百褶裙 | 29.90 |
| 1 | 1 | 女装/女士精品 | T恤 | 39.90 |
| 2 | 2 | 女装/女士精品 | 连衣裙 | 79.90 |
| 2 | 3 | 女装/女士精品 | 卫衣 | 89.90 |
| 3 | 4 | 女装/女士精品 | 牛仔裤 | 89.90 |
| 3 | 6 | 女装/女士精品 | 呢绒外套 | 399.90 |
| 1 | 9 | 户外运动 | 登山杖 | 59.90 |
| 1 | 7 | 户外运动 | 自行车 | 399.90 |
| 2 | 10 | 户外运动 | 骑行装备 | 399.90 |
| 2 | 12 | 户外运动 | 滑板 | 499.90 |
| 3 | 11 | 户外运动 | 运动外套 | 799.90 |
| 3 | 8 | 户外运动 | 山地自行车 | 1399.90 |
+------+----+---------------------+-----------------+---------+
12 rows in set (0.00 sec)
以上是关于MySql窗口函数的主要内容,如果未能解决你的问题,请参考以下文章