HashMap的初始容量和加载因子
Posted
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了HashMap的初始容量和加载因子相关的知识,希望对你有一定的参考价值。
参考技术A 原文地址: https://xeblog.cn/articles/26通过查看 HashMap 的源码可以得知其默认的初始容量为 16 ,默认的加载因子为 0.75 。
一般情况下都是通过这三种构造方法来初始化 HashMap 的。通过默认的无参构造方法初始化后 HashMap 的容量就是默认的16,加载因子也是默认的0.75;通过带参数的构造方法可以初始化一个自定义容量和加载因子的 HashMap 。通常情况下,加载因子使用默认的0.75就好。
HashMap 的容量要求必须是2的N次幂,这样可以提高散列的均匀性,降低 Hash 冲突的风险。但是容量可以通过构造方法传入的,如果我传入一个非2次幂的数进去呢?比如3?传进去也不会干嘛呀,又不报错。。。哈哈哈哈。
是的,不会报错的,那是因为 HashMap 自己将这个数转成了一个最接近它的2次幂的数。这个转换的方法是 tableSizeFor(int cap) 。
这个方法会将传入的数转换成一个2次幂的数,比如传入的是3,则返回的是4;传入12,则返回的是16。
加载因子和 HashMap 的扩容机制有着非常重要的联系,它可以决定在什么时候才进行扩容。 HashMap 是通过一个阀值来确定是否扩容,当容量超过这个阀值的时候就会进行扩容,而加载因子正是参与计算阀值的一个重要属性,阀值的计算公式是 容量 * 加载因子 。如果通过默认构造方法创建 HashMap ,则阀值为 16 * 0.75 = 12 ,就是说当 HashMap 的容量超过12的时候就会进行扩容。
这是 HashMap 的 putVal(...) 方法的一个片段, put(...) 方法其实就是调用的这个方法, size 是当前 HashMap 的元素个数,当元素个数+1后超过了阀值就会调用 resize() 方法进行扩容。
加载因子在一般情况下都最好不要去更改它,默认的0.75是一个非常科学的值,它是经过大量实践得出来的一个经验值。当加载因子设置的比较小的时候,阀值就会相应的变小,扩容次数就会变多,这就会导致 HashMap 的容量使用不充分,还没添加几个值进去就开始进行了扩容,浪费内存,扩容效率还很低;当加载因子设置的又比较大的时候呢,结果又很相反,阀值变大了,扩容次数少了,容量使用率又提高了,看上去是很不错,实际上还是有问题,因为容量使用的越多, Hash 冲突的概率就会越大。所以,选择一个合适的加载因子是非常重要的。
通过默认构造方法创建一个 HashMap ,并循环添加13个值
当添加第1个值后,容量为16,加载因子为0.75,阀值为12
当添加完第13个值后,执行了扩容操作,容量变为了32,加载因子不变,阀值变为了24
创建一个初始容量为12(非2次幂数)的 HashMap ,并添加1个值
创建一个初始容量为2的 HashMap ,并添加2个值
当添加完第1个值后,容量为2,加载因子为0.75,阀值为1
当添加完第2个值后,执行了扩容操作,容量变为4,加载因子为0.75,阀值为3
创建一个初始容量为2、加载因子为1的 HashMap ,并添加2个值
当添加完第1个值后,容量为2,加载因子为1,阀值为2
当添加完第2个值后,并没有执行扩容操作,容量、加载因子、阀值均没有变化
HashMap与ConcurrentHashMap
HashMap
(1)初始化方法
HashMap的实现方式是:数组+链表 的形式。
在HashMap中有两个参数会影响HashMap的性能:初始容量/加载因子
初始容量:Hash表中桶的数量
加载因子:是Hash表在自动增加之前可以达到多满的一个尺度。
通过计算key的hash值和数组长度值进行取模确定该key在数组中的索引。
//初始容量,默认16
static final int DEFAULT_INITIAL_CAPACITY = 1 << 4;
//加载因子,默认0.75
static final float DEFAULT_LOAD_FACTOR = 0.75f;
这两个参数的作用是:当Hash表中的条目数量超过了加载因子与当前容量的乘积,将会调用resize()进行扩容,将容量翻倍。
这两个参数在初始化HashMap的时候可以进行设置:可以单独指定初始容量,也可以同时设置
(3)HashMap的线程不安全原因一:死循环
原因在于HashMap在多线程情况下,执行resize()进行扩容时容易造成死循环。
扩容思路为它要创建一个大小为原来两倍的数组,保证新的容量仍为2的N次方,从而保证上述寻址方式仍然适用。扩容后将原来的数组从新插入到新的数组中。这个过程称为reHash。
【单线程下的reHash】 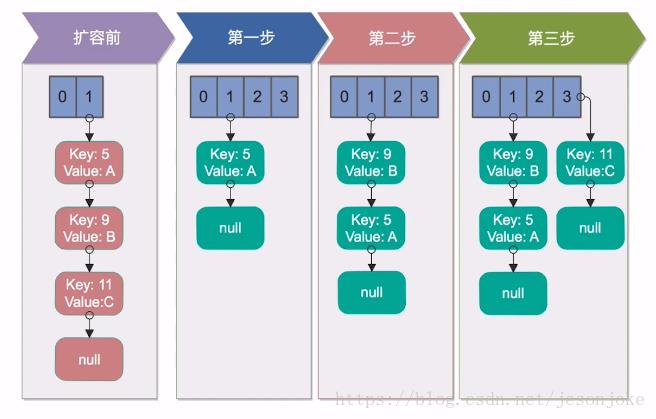
- 扩容前:我们的HashMap初始容量为2,加载因子为1,需要向其中存入3个key,分别为5、9、11,放入第三个元素11的时候就涉及到了扩容。
- 第一步:先创建一个二倍大小的数组,接下来把原来数组中的元素reHash到新的数组中,5插入新的数组,没有问题。
- 第二步:将9插入到新的数组中,经过Hash计算,插入到5的后面。
- 第三步:将11经过Hash插入到index为3的数组节点中。
单线程reHash完全没有问题。
【多线程下的reHash】

我们假设有两个线程同时需要执行resize操作,我们原来的桶数量为2,记录数为3,需要resize桶到4,原来的记录分别为:[3,A],[7,B],[5,C],在原来的map里面,我们发现这三个entry都落到了第二个桶里面。
假设线程thread1执行到了transfer方法的Entry next = e.next这一句,然后时间片用完了,此时的e = [3,A], next = [7,B]。线程thread2被调度执行并且顺利完成了resize操作,需要注意的是,此时的[7,B]的next为[3,A]。此时线程thread1重新被调度运行,此时的thread1持有的引用是已经被thread2 resize之后的结果。线程thread1首先将[3,A]迁移到新的数组上,然后再处理[7,B],而[7,B]被链接到了[3,A]的后面,处理完[7,B]之后,就需要处理[7,B]的next了啊,而通过thread2的resize之后,[7,B]的next变为了[3,A],此时,[3,A]和[7,B]形成了环形链表,在get的时候,如果get的key的桶索引和[3,A]和[7,B]一样,那么就会陷入死循环。
(4)HashMap的线程不安全原因二:fail-fast
如果在使用迭代器的过程中有其他线程修改了map,那么将抛出ConcurrentModificationException,这就是所谓fail-fast。
在每一次对HashMap进行修改的时候,都会变动类中的modCount域,即modCount变量的值。
ConcurrentHashMap
(1)结构 [Java7与Java8不同]
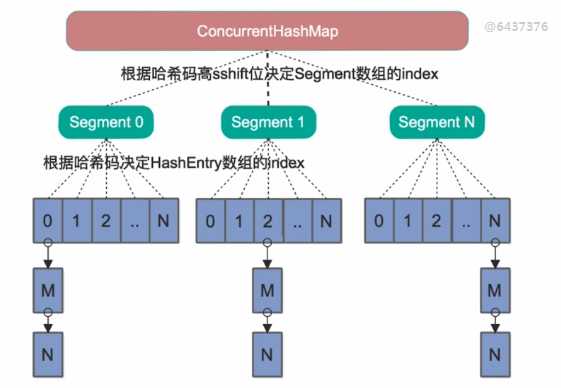
- Java7里面的ConcurrentHashMap的底层结构仍然是数组和链表,与HashMap不同的是ConcurrentHashMap的最外层不是一个大的数组,而是一个Segment数组。每个Segment包含一个与HashMap结构差不多的链表数组。
- 当我们读取某个Key的时候它先取出key的Hash值,并将Hash值得高sshift位与Segment的个数取模,决定key属于哪个Segment。接着像HashMap一样操作Segment。
- 为了保证不同的Hash值保存到不同的Segment中,ConcurrentHashMap对Hash值也做了专门的优化。
-
Segment继承自J.U.C里的ReetrantLock,所以可以很方便的对Segment进行上锁。即分段锁。理论上最大并发数是和segment的个数是想等的。
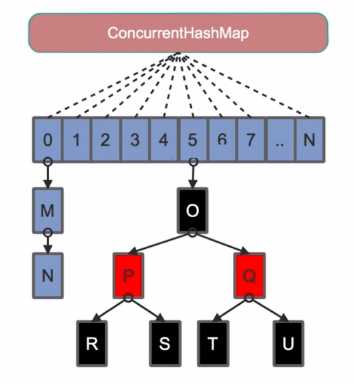
-
Java8为了进一步提高并发性,废弃了Java7中ConcurrentHashMap中分段锁的方案,并且不使用Segment,转为使用大的数组。同时为了提高Hash碰撞下的寻址做了性能优化。
- Java8在列表的长度超过了一定的值(默认8)时,将链表转为红黑树实现。寻址的复杂度从O(n)转换为Olog(n)。java8也是通过计算key的hash值和数组长度值进行取模确定该key在数组中的索引。但是java8引入红黑树,即使hash冲突比较高,寻址效率也会是比较高的。
对比
- HashMap非线程安全、ConcurrentHashMap线程安全
- HashMap允许Key与Value为空,ConcurrentHashMap不允许
- HashMap不允许通过迭代器遍历的同时修改,ConcurrentHashMap允许。并且更新可见
以上是关于HashMap的初始容量和加载因子的主要内容,如果未能解决你的问题,请参考以下文章
在元素的装载数量明确的时候HashMap的大小应该如何选择。