Towards Emotional Support Dialog Systems论文笔记
Posted 程序员小小何
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Towards Emotional Support Dialog Systems论文笔记相关的知识,希望对你有一定的参考价值。
文章目录
一,基调
标题翻译过来是“面向情感支持对话系统”,黄民烈等,ACL 2021。情感支持应该指的是心理疾病患者(或者程度更弱一些内心不开心的用户)向心理医生(或者程度更弱一些擅于聊天的开导者,本文指机器)寻求帮助、开导和治疗的过程。整个论文有点儿像心理学领域的一篇文章,不太像计算机领域,重点聚焦在面向情感支持的对话数据集的构建上,所以本笔记写法简单记录文章聚焦的问题和数据集的一些统计情况,更多省略方法和计算上的一些操作。整个论文在数据集的构建过程上工作量大,因水平限制记不出数据集构造牵扯的逻辑。
二,情感支持框架
(一)情感支持和共情的区别
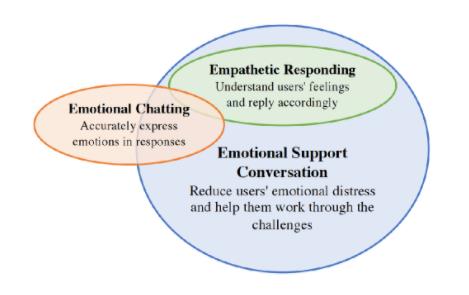
情感支持包括情感聊天的一部分和共情回复生成的元素。
- 情感支持更大更宽,旨在减少用户的情绪困扰,并帮助他们克服这些挑战。
- 共情是了解用户的感受,并相应地回复。
- 情绪聊天机器人在回复中准确地表达情绪。
(二)情感支持的三个阶段
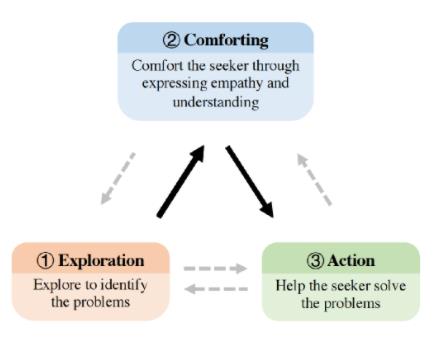
情感支持更大更宽,是一个由浅入深的过程。旨在减少用户的情绪困扰,并帮助他们克服这些挑战。作者引用2009年应该是心理学的一篇论文中的帮助技能理论编了一套如上图所示的情感支持框架( Helping skills: Facilitating, exploration, insight, and action. American Psychological Association. )。
情感支持框架它包括三个阶段,过程通常遵循以下顺序:1探索→2安慰→3动作(如上图黑色箭头所示),但也可以根据需要适应个人对话(由虚线灰色箭头表示)。
1,探索以识别用户(seeker)的问题
2,通过表达同理心和理解力来安慰用户
2009年的原论文第二阶段指洞察力(insight,帮助求助者进入自我理解的新深度),而不是comforting。作者解释,洞察力通常需要重新解释用户的行为和感受,这对于没有足够的支持经验的支持者来说是既困难又有风险的,于是把洞察力改为安慰,通过同理心和理解来提供支持。(个人理解,洞察力可能因解释而需要一些因果的判断,或许计算机不太好实现,另外心理医生专业知识本身足够复杂等原因)
3,帮助用户解决问题
(三)情感支持的范例

上图是我们一个情感支持的范例。左边是用户(seeker),右边是机器(supporter)。注意右边三个小人图标分别对应着情感支持的三个阶段,探索、安慰、动作。虚线方框中的红色粗体文本也突出显示了ESC(Emotional Support Conversation)框架的三个阶段。机器(supporter)使用的支持策略(技能)标记在话语前的括号中。支持策略具体内容见下一小节。
(四)情感支持中的八大策略
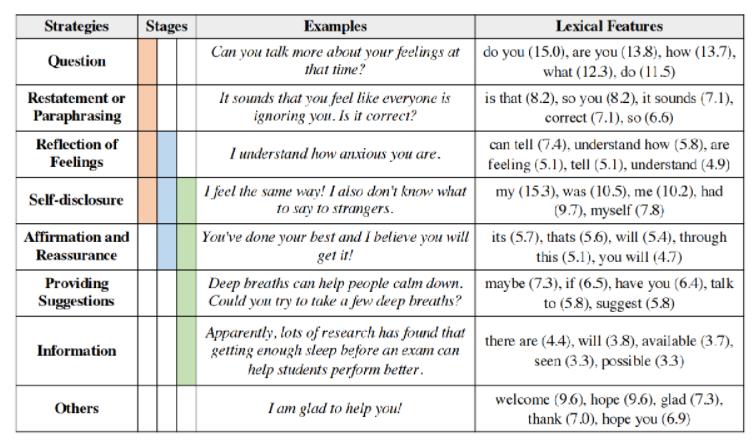
上表列了情感支持中的八大策略,指的是supporter在提供支持的过程中可以使用的沟通技巧,由浅入深被分为八大类别。表格stages一列的颜色分别对应三大阶段:(淡橙)探索→(淡蓝)安慰→(淡绿)动作。
-
探索阶段含有提问、重新陈述或组织、情感反射、自我暴露四个策略方法
-
安慰阶段含有情感反射、自我暴露、确认和保证三个策略方法
-
动作阶段含有自我暴露、确认和保证、提供建议、信息四个策略方法
表格中列了每种策略的具体例子,并列了词汇的特征top 5排序,特征选的unigrams或者bigrams。打分方法使用z-scored log odds ratios(我没用过不知计算方法,列名称在此)。
三,情感支持数据集
下面重点介绍数据集相关内容
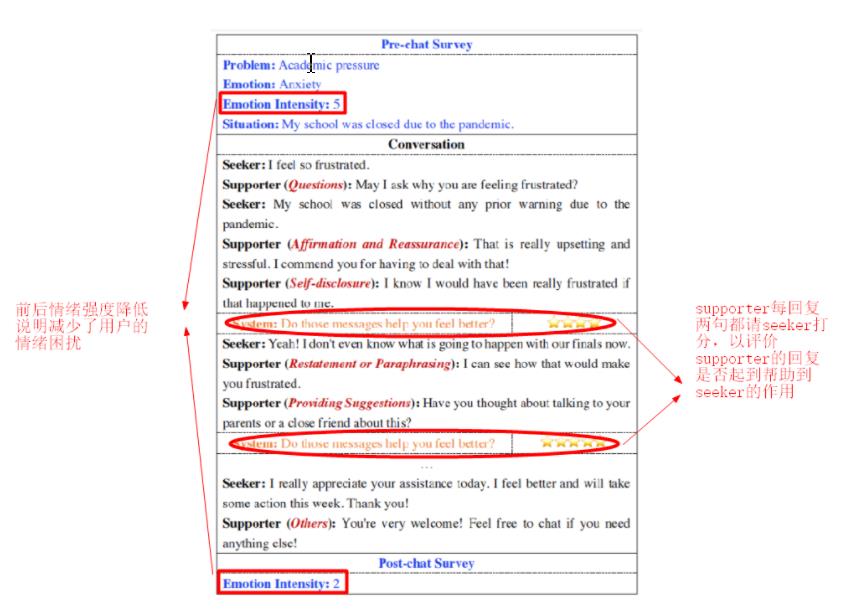
情感支持旨在减少用户的情绪困扰,并帮助他们克服这些挑战,为达此目的作者等人设计一套对话过程中的标记方法,如上图所示。标记完之后,使用下表的筛选数据集的指标来对对话数据集进行筛选,符合下表指标的对话才会被保留下来。
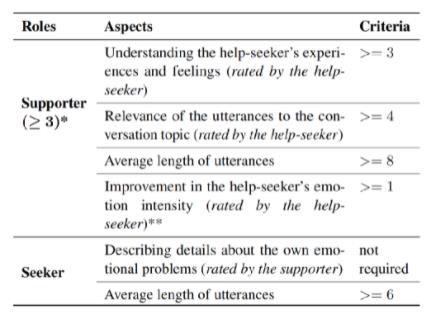
经过筛选,2472个对话最后保留1053个。
下表展示数据集的统计信息
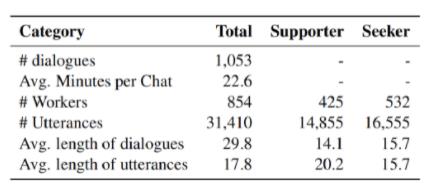
由表中可以看出,这套数据集共1053个对话,对话平均长度29.8(约含有15个turns),每个句子17.8个单词。
从主题、情感类别、八大策略类别等几个维度进行统计的信息如下表:
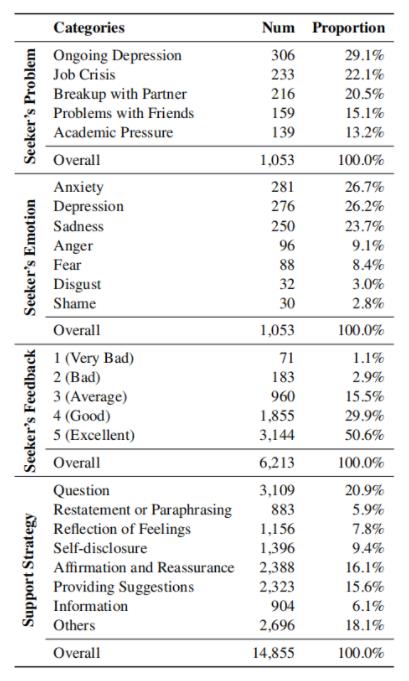
最后想介绍的是对话从开始到结束过程中,八大策略类别的分布图,如下图所示:
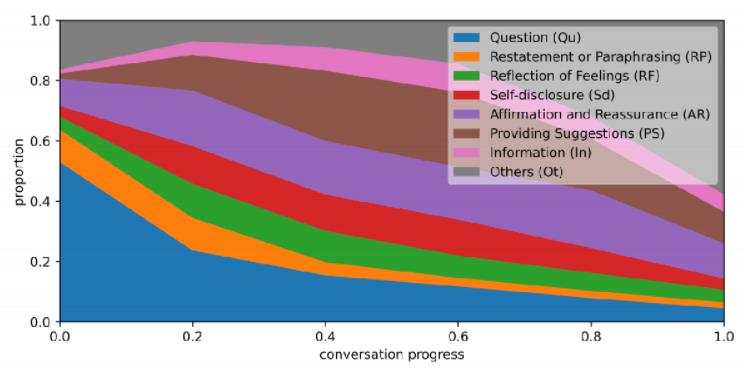
横坐标指每个对话被平均分成5份时涉及的6个点,纵坐标指在每个点上各个策略的句子占比是多少。
四,方法、实验和结果
本节略写实验方法及结果。
(一)方法
方法在dialogGPT和BlenderBot两个预训练模型方法的基础上进行小改动进行。具体指在机器生成response之前,先生成相应的策略(八大策略中的一个),之后再生成相应策略下的response。具体描述见如下原文:

(二)结果
结果见下表:
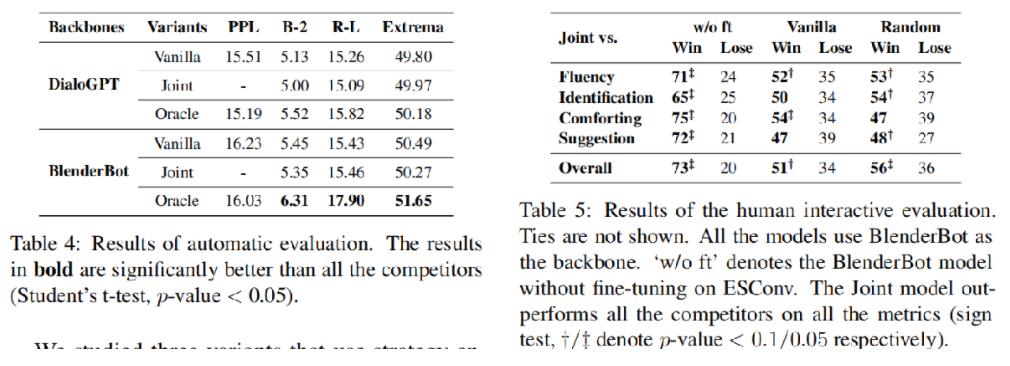
左表机器评价指标,右表人工评价。
(三)案例分析
案例分析是作者想给我们看到的案例,如下图所示:
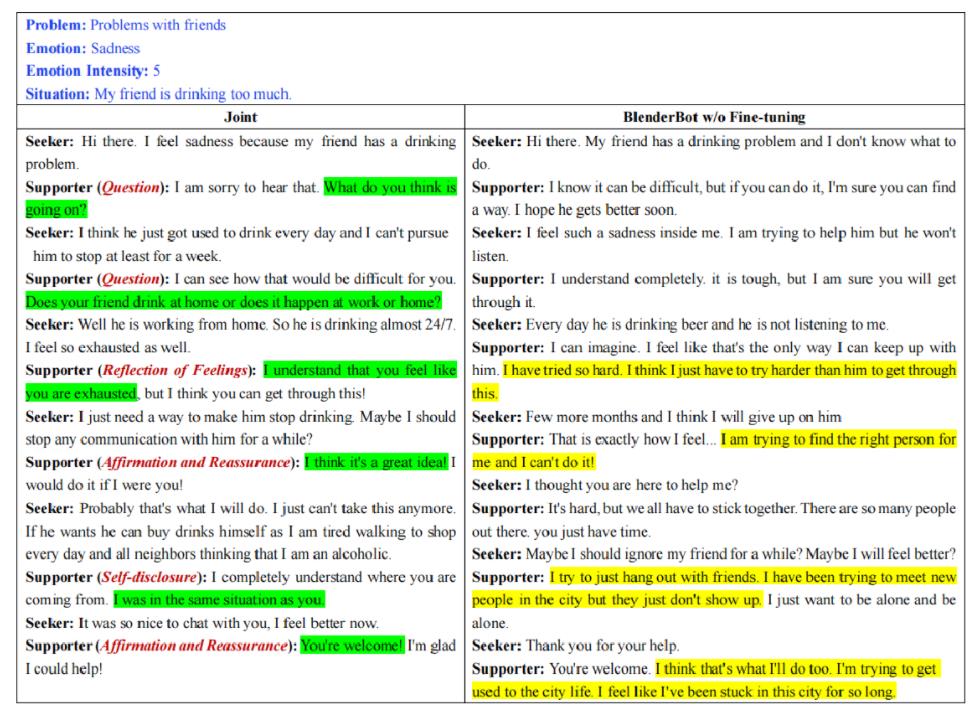
表格分左右两边,左边指联合预测策略和文本的模型,右边指没经过微调的预训练模型BlenderBot。
-
红色文本:由模型预测的策略
-
绿色背景:与所用策略相对应的话语
-
黄色背景:BlenderBot模型谈论自己而不是以用户为中心的话语
左侧体现了红色文本和绿色文本相互对应的情况,右侧黄色文本说明预训练模型可能会生成话题无关的回复。
五,总结与展望
这部分引用之前跑的coling 2020 EmpDG的代码结果
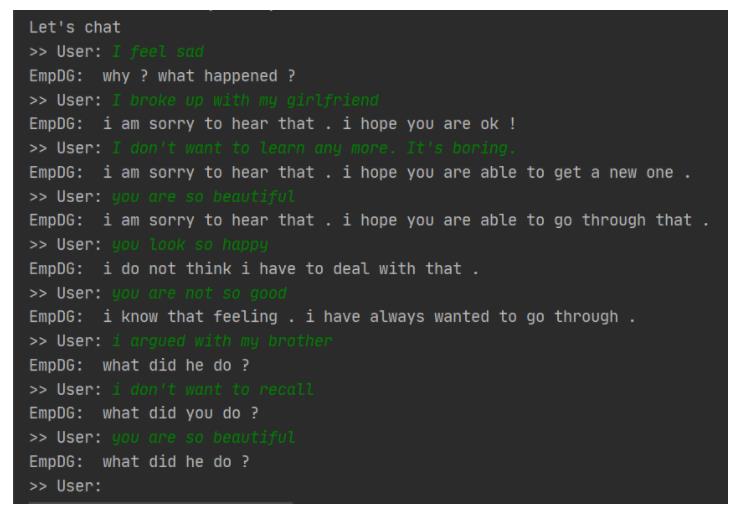
从结果上看,对话机器人在初步具备共情能力的同时,还存在通用回复和不合逻辑的回复等问题。
笼统的说,共情对话机器人的效果主要受限于语料和不够强大的模型,因而造成很多通用回复和不合逻辑的回复,也能笼统的提一些比较大而宽泛的点:
- 在模型上,探索共情语句本身具有的特质,将共情语句进行分类,并搭建更合适的模型来刻画共情语句的天然本质。
- 在语料上,可以使用EMNLP 2021 A Large-Scale Dataset for Empathetic Response Generation出发,电影字幕中存在的大量对话语料库,其中已经筛选出更多具有共情色彩的语料,在更大的语料上训练出更优秀的共情对话机器人,约100万个对话,感觉偏工程,没想好下面怎么接续这个
- 现在无论模型研究和语料研究都集中在英语语言上,这对中文语境的人们是巨大的损失,开展中文共情语料和模型研究,为中文共情对话机器人开拓出一片天地
- 调研开放域领域的对话研究进展,以期能在解决通用回复和不合逻辑的回复上获得更好的方法,并应用在共情对话机器人上
- 当共情对话机器人趋于成熟,人类会倾向于沉迷和机器人聊天,产生的伦理问题也值得我们关注和注意
至于情感支持机器人或许更复杂。如果训练出的chatbot完全不能使用,这个题目是不是就不做了?如果要做,应该怎么做?
(图片几乎都从原论文中剪切出来)
以上是关于Towards Emotional Support Dialog Systems论文笔记的主要内容,如果未能解决你的问题,请参考以下文章
Towards Emotional Support Dialog Systems论文笔记
Towards Facilitating Empathic Conversations in Online Mental Health Support 论文阅读笔记
Towards Facilitating Empathic Conversations in Online Mental Health Support 论文阅读笔记
Towards Facilitating Empathic Conversations in Online Mental Health Support 论文阅读笔记
Towards Facilitating Empathic Conversations in Online Mental Health Support 论文阅读笔记