中文纠错Pycorrector是如何收获2000 Star的?
Posted 狮子座明仔
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了中文纠错Pycorrector是如何收获2000 Star的?相关的知识,希望对你有一定的参考价值。
(导语)
计算机行业发展至今,“开源”已逐渐成为技术茁壮成长最肥沃的土壤。而在中国,企业开源热闹非常,个人开源也方兴未艾。尽管个人开源困难重重,还是有一些开发者仍然在努力做着这样“吃力不讨好”的事情。
今天的“开发者说”文章,就来自这样一位个人开发者。他做的文本纠错开源工具pycorrector,当前在GitHub上star数2165,fork数565。pycorrector主要用于音似、形似错字纠正,可用于输入法、OCR、ASR的文本错误纠正,兼容Kenlm语言模型纠错,和深度模型纠错,包括:Seq2Seq,Bert,MacBert,Electra,Ernie。
欢迎大家Star支持:https://github.com/shibing624/pycorrector
下面就来看下这样的千星项目是怎样打造出来的吧!
开源初心
为什么要做 Pycorrector?
做中文纠错项目之前,我做了做大量的背景调研,避免重复造轮子。
- deep-text-corrector优点:英文的语法纠错项目,深度模型,支持自定义训练;缺点:不支持中文纠错,4年未更新;
- correction优点:统计语言模型kenlm,解释性强;缺点:code跑不起来,C++开发且注释少,4年未更新;
- Cn_Speck_Checker优点:参考英文拼写纠错spell-correct实现,ngram的简单拼音纠错,针对医学数据,统计词频和共现信息,可自训练;缺点:仅限于单词纠错,无深度模型,repo5年未更新;
- chinese_correct_wsd优点:京东客服机器人语料做的中文纠错;缺点:code跑不起来,仅限于同音纠错,6年未更新;
- 中文纠错领域有NLPCC、CGED中文语法纠错比赛,比赛优异队伍有产出对应的方法paper,但无对应的开源实现代码。
基于以上调研,我做了文本纠错pycorrector项目。

做成什么样?
我们选择做一个面向开源,解耦业务数据,对新老模型兼容并包,将学术界SOTA模型应用于工业应用。
由此,新项目需要满足以下四点:
- 扩展性强,支持开发者自定义训练;
- 中文、英文的文本纠错任务兼顾;
- 统计模型、深度模型均有;
- 有可衡量评估标准,使用NLPCC、CGED中文语法纠错比赛数据测评。
文本纠错的两种解决方案,规则方法和深度方法。
- 规则方法:基于语言模型的ngram统计,依据正确字词搭配的出现概率高于错误的假设,识别错误字词搭配,结合语言模型计算句子困惑度PPL,判定最优纠正词。
- 模型方法:基于预训练模型,结合多种深度方法Seq2Seq, transformer, BERT, MacBERT, ELECTRA, ERNIE通过端到端识别文本错误并纠正。
项目的质量标准
既然已经决定开源,项目的质量要求即是以开源的标准来要求。
- 技术公开:公开给所有人的并不只是功能和文档,而是全部代码,这样的质量要求和做一个内部项目是不同的。我们认同马丁福勒这位代码沟通大师的理念,任务代码是给人看的,不是仅仅给机器编译用的。
- 逻辑清晰:维护一个有缺陷但是代码清晰的项目,远比维护一个代码混乱但暂时未发现缺陷的项目要更加受欢迎。
- 充分测试:测试用例的覆盖率,我们要求测试覆盖率尽量达到80%以上,如此才可以放心的重构和完善新功能。结合Travis-CI在线持续集成服务,自动化执行单元测试,就可以保证项目的充分测试了。单元测试不仅能保证代码的可靠程度,同时在写测试过程中你会发现你代码设计得不好的地方,我一直使用的一个评判标准就是:编写单元测试的难度与代码质量成反比。测试方法:单元测试 + 功能测试
- 效果复现:最佳效果可复现,不能允许有谁都不敢碰的黑箱存在。
开源的目的
回馈开源社区
每个开发者都或多或少的使用过开源产品,在使用开源的同时尽量的反馈社区,让开源成为良性循环。
吸取社区精华
使用的人越多,看代码的人越多,项目的bug和风险就会越小。社区开发人员的贡献促进pycorrector项目成长。比如:
- 我们项目中的MacBERT模型,模型代码和测试效果由社区开发同学贡献的;
- ERNIE模型是百度paddle同学建议下引入的;
- GitHub上的ISSUES大多数问题也是社区人员帮忙答复解决的;
- 微信沟通交流群也是社区人员自发组织成立的。
发现问题的途径越多就越有利于项目的健康发展。而且社区人员确实反馈了一些关键问题,贡献了关键代码,这些代码也为项目的最终效果做出了贡献。
提升公司和个人技术品牌
开源之后收到越来越多的人询问组里是否还招人,也更多收到了讨论技术问题的邮件和微信消息。这些影响都是潜移默化的,会渐渐的让公司和个人的技术影响力提升。对于不发出技术声音的互联网公司,可能会越来越难招募到优秀的开发者。
经验分享
关注文档:良好的文档是项目的“门面”
文档是项目的“门面”,优秀的文档更吸引开发者。 文档要有,代码不能代替文档。文档要清晰,使用者是通过文档来了解并使用项目的。通读代码的使用者毕竟是少数,我们无法要求使用者通读代码。但文档绝不是越多越好,一定要适中,信息量爆炸不利于信息的吸收消化和检索。如果你的项目不限于国内使用,那最好提供两个版本,或者起码提供英文版本的文档。
文档的要求:
- 亮点突出:对于算法模型,模型结构以图表示,创新点重点突出,模型特征、优势交代清楚;
- 效果明显:简化预测代码,需要高级封装,直接输出模型识别结果,动态图、图片展示效果更好;
- 结构清晰:类似于八股文,写清项目简介、特征、安装方法、使用方法、评估效果、后续规划、参考文献等。
详细的文档结构:
- 项目简介及动机
- features & 适用人群
- 运行的平台或软硬件要求
- 重要依赖
- 如何安装与测试
- 使用示例
- 贡献指南
- License
- 鸣谢
技术难度:开源项目一般难度会大于业务项目
对齐学术界SOTA模型,产出最佳应用效果。
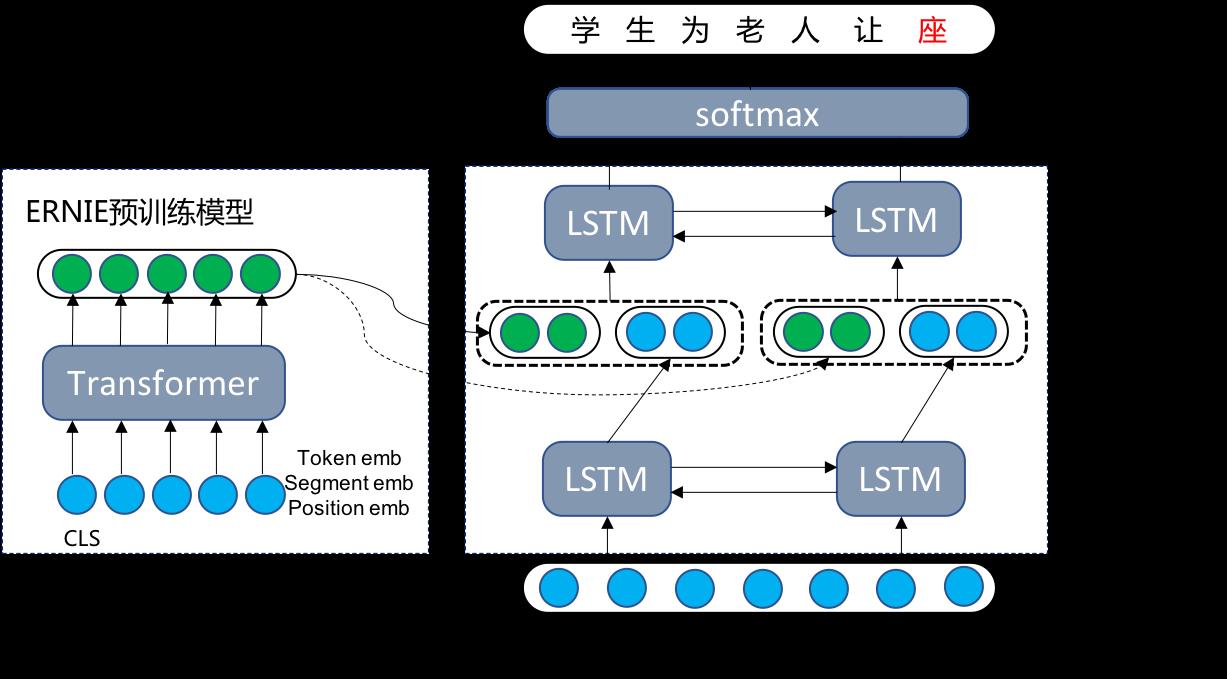
过去一年,百度提出的ERNIE通过持续学习海量数据中的知识在中英文十六个自然语言理解任务上取得领先效果,并在去年12月登顶权威评测榜单GLUE榜首。

我们的项目使用ERNIE预训练语言模型,分别调研基于Fill-Mask和Bi-LSTM模型的文本纠错效果,结果是Fill-Mask模型效果更优,项目文档如下图所示。
开源项目一般难度会大于业务项目。
这里以transformers和 detectron2(https://github.com/facebookresearch/detectron2)举例。两个项目的难度展现在不同的地方,transformers属于为NLP领域提供最先进模型的应用框架,该项目汇聚100+人类语言,超过32+类NLP任务的预训练模型,可以高效让研究人员快速呈现最先进模型的应用效果。detectron2属于CV领域目标检测方向的识别工具,着力于在目标检测及图像分割上深耕模型创新,融合不同基模型达到目标检测的最优效果。以上两个项目都有较高借鉴意义。
代码逻辑:代码需精雕细琢,逻辑整体设计严谨
举个例子,pycorrector核心代码开发只花了两周左右,而花了两个月打磨。主要包括整体流程梳理、模块拆分规划、代码可读性重塑、封装粒度缩小、深度模型调研等。开源项目是否可持续发展的关键点即在于此,这是对一个项目负责的态度。
开源版本的管理
GitHub的repo版本管理具有先天优势,基于GIT,可以灵活运用branchs,tags管理源码。我建议在代码版本管理之外,对于工具类项目上传到pip或者conda中,方便release版本管理。
版本:
- 主版本号:当你做了不兼容的 API 修改,
- 次版本号:当你做了向下兼容的功能性新增,
- 修订号:当你做了向下兼容的问题修正。
沟通运营
- 交流群:建立一个微信群或者QQ群,或者使用Slack、Gitter等开源协同工具,用于轻便和愉快的沟通,也便于头脑风暴。群中最好有一个活跃的组员是项目主导人员,及时沟通和反馈项目情况。
- issue:使用GitHub的issue或者邮件,适用于开发者,低频打扰。
如何让更多开发者参与贡献?
针对于这样的问题,为了可以让更多的人参与项目贡献,我们考虑把任务分级,分为简单型、长期型、讨论型、缺陷型和技术难点型。
- 简单型:例如介绍页面由中文翻译为多国语言,这样的任务可以让有兴趣的社区人员参与开发,并无太多门槛。
- 长期型:属于核心任务,最好由资深的开发人员或者项目的主导人员完成,比如:系统接口设计,核心模块开发,项目长期规划等。
- 讨论型:一般会在微信群,QQ群,wiki,issue等平台讨论,比如roadmap先做哪些,某个具体任务的取舍等,最终会转化为其他的任务类型,当然,一般不会转化为简单型。
- 缺陷型:属于快速响应的任务,在下个升级版本就会发布。
- 难点型:遇到技术难题,需要做调研,调研明白之后才决定如何做,有这方面技术经验的社区人员可以提供更多的帮助。
参与开源从迈出第一步开始
很多开发者想要参与开源,但不知道如何开始,这里我建议大家从小做起。从小做起指的是从“小贡献”和“小项目”开始做。
完成一些bug修复,实现一些小的功能可以让你收获成就感和圈子中小有名气,更重要的是了解项目的底层代码实现逻辑,这能使你提交的补丁更容易获得批准。
- 从小做起
- 参与那些你使用过的开源软件
- 做你喜欢的事
- 观察项目的社区动态
- 建立自己的项目
总的来看,本片文章结合pycorrector的项目经历介绍了开源项目从0到1的过程,希望通过以上的分享,吸引更多感兴趣的同行一起加入到开源的大家庭,共同推进技术的进步。
以上是关于中文纠错Pycorrector是如何收获2000 Star的?的主要内容,如果未能解决你的问题,请参考以下文章
中文纠错Pycorrector是如何收获2000 Star的?