docker安装prometheus和grafana
Posted justry_deng
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了docker安装prometheus和grafana相关的知识,希望对你有一定的参考价值。
docker安装prometheus和grafana
- docker安装prometheus和grafana
概念简述
-
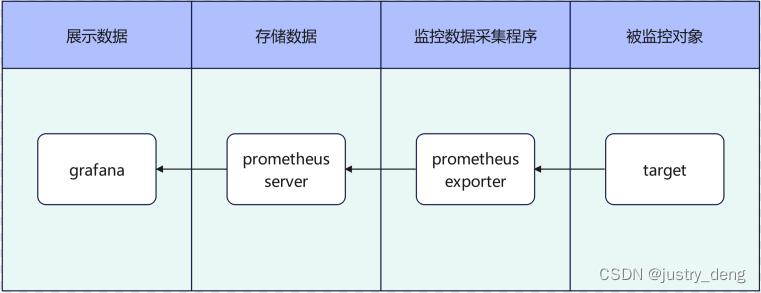
prometheus(普罗米修斯):天生为采集存储监控数据而生的时序数据库。prometheus通过各种Exporter采集到监控数据,然后存储进prometheus中,以供查询展示
-
grafana:一个监控仪表系统。grafana的数据来源可以有很多(如:Prometheus、Graphite、OpenTSDB、InfluxDB、mysql/PostgreSQL、Microsoft SQL Serve等等),其中用得最多的数据源是prometheus
注:prometheus也有自己的UI,不过功能没有grafana强大
安装prometheus
第一步:确保安装有docker
查看docker版本
docker -v

第二步:拉取镜像
# 你也可以直接拉docker pull prom/prometheus, 即拉取最新的镜像docker pull prom/prometheus:lastest
docker pull prom/prometheus:v2.41.0
第三步:准备相关挂载目录及文件
准备目录
# /opt/prometheus/data目录,准备用来挂载放置prometheus的数据
# /opt/prometheus/config目录,准备用来放置prometheus的配置文件
# /opt/prometheus/rules目录,准备用来挂载放置prometheus的规则文件
mkdir -p /opt/prometheus/data,config,rules
# 授权相关文件夹权限
chmod -R 777 /opt/prometheus/data
chmod -R 777 /opt/prometheus/config
chmod -R 777 /opt/prometheus/rules
准备文件
# 配置文件
cat > /opt/prometheus/config/prometheus.yml << \\EOF
global:
# 数据采集间隔
scrape_interval: 45s
# 告警检测间隔
evaluation_interval: 45s
# 告警规则
rule_files:
# 这里匹配指定目录下所有的.rules文件
- /prometheus/rules/*.rules
# 采集配置
scrape_configs:
# 采集项(prometheus)
- job_name: 'prometheus'
static_configs:
# prometheus自带了对自身的exporter监控程序,所以不需额外安装exporter就可配置采集项
- targets: ['localhost:9090']
EOF
# 查看一下配置文件
cat /opt/prometheus/config/prometheus.yml
prometheus配置项说明
- global:全局配置 (如果有内部单独设定,会覆盖这个参数)
- alerting:告警插件定义。这里会设定alertmanager这个报警插件
- rule_files:告警规则。 按照设定参数进行扫描加载,用于自定义报警规则,其报警媒介和route路由由alertmanager插件实现
- scrape_configs:采集配置。配置数据源,包含分组job_name以及具体target。又分为静态配置和服务发现
- remote_write:用于远程存储写配置
- remote_read:用于远程读配置
第四步:启动容器
# 启动prometheus
# config.file:指定容器中,配置文件的位置
# web.enable-lifecycle:启动此项后,当配置文件发生变化后,可通过HTTP API 发送 post 请求到 /-/reload,实现热加载,如:curl -X POST http://47.105.39.189:9090/-/reload
# -v /etc/localtime:/etc/localtime:ro表示让容器使用宿主机的时间, :ro表示只读(注:此方式只针对宿主机和容器的时区文件均为/etc/localtime)
docker run --name prometheus -d \\
-p 9090:9090 \\
-v /etc/localtime:/etc/localtime:ro \\
-v /opt/prometheus/data:/prometheus/data \\
-v /opt/prometheus/config:/prometheus/config \\
-v /opt/prometheus/rules:/prometheus/rules \\
prom/prometheus:v2.41.0 --config.file=/prometheus/config/prometheus.yml --web.enable-lifecycle
第五步:访问测试
访问
ip:9090即可

安装grafana
第一步:确保安装有docker
查看docker版本
docker -v

第二步:拉取镜像
镜像有哪些版本,可以通过查看一个docker镜像有哪些版本查看
# 你也可以直接拉docker pull grafana/grafana, 即拉取最新的镜像docker pull grafana/grafana:lastest
docker pull grafana/grafana:9.3.2
第三步:准备相关挂载目录及文件
准备目录
# /opt/grafana/data目录,准备用来挂载放置grafana的数据
# /opt/grafana/plugins目录,准备用来放置grafana的插件
# /opt/grafana/config目录,准备用来挂载放置grafana的配置文件
mkdir -p /opt/grafana/data,plugins,config
# 授权相关文件夹权限
chmod -R 777 /opt/grafana/data
chmod -R 777 /opt/grafana/plugins
chmod -R 777 /opt/grafana/config
准备配置文件
# 先临时启动一个容器
docker run --name grafana-tmp -d -p 3000:3000 grafana/grafana:9.3.2
# 将容器中默认的配置文件拷贝到宿主机上
docker cp grafana-tmp:/etc/grafana/grafana.ini /opt/grafana/config/grafana.ini
# 移除临时容器
docker stop grafana-tmp
docker rm grafana-tmp
# 修改配置文件(需要的话)
# vim /opt/grafana/config/grafana.ini
第四步:启动容器
# 启动prometheus
# 环境变量GF_SECURITY_ADMIN_PASSWORD:指定admin的密码
# 环境变量GF_INSTALL_PLUGINS:指定启动时需要安装得插件
# grafana-clock-panel代表时间插件
# grafana-simple-json-datasource代表json数据源插件
# grafana-piechart-panel代表饼图插件
docker run -d \\
-p 3000:3000 \\
--name=grafana \\
-v /etc/localtime:/etc/localtime:ro \\
-v /opt/grafana/data:/var/lib/grafana \\
-v /opt/grafana/plugins/:/var/lib/grafana/plugins \\
-v /opt/grafana/config/grafana.ini:/etc/grafana/grafana.ini \\
-e "GF_SECURITY_ADMIN_PASSWORD=admin" \\
-e "GF_INSTALL_PLUGINS=grafana-clock-panel,grafana-simple-json-datasource,grafana-piechart-panel" \\
grafana/grafana:9.3.2
第五步:访问测试
访问
ip:3000即可,使用账密admin/admin进行登录即可

第六步:使用测试
-
添加数据源

选择普罗米修斯作为数据源


-
制作(或导入)仪表盘
grafana官网提供了很多模板,选择你喜欢的样式,直接输入Dashboard Id即可直接导入
这里列出几个本人使用的Dashboard Id
- 12633:Linux主机详情


此时,界面就出来了
提示:这会儿还没有数据,是因为prometheus里面本来就没有数据,后面我们只需要使用相应的exporter往prometheus录入一些监控数据(如:安装node-exporter),这里就会显示出来了

安装exporter监控采集程序,采集数据进prometheus
node-exporter
官方不建议通过Docekr方式部署node-exporter,因为它需要访问主机系统
node-exporter 可以采集机器(物理机、虚拟机、云主机等)的监控指标数据,能够采集到的指标包括 CPU, 内存,磁盘,网络,文件数等信息
-
安装node-exporter
# 下载 wget https://github.com/prometheus/node_exporter/releases/download/v1.1.2/node_exporter-1.1.2.linux-amd64.tar.gz # 解压 tar -xvf node_exporter-1.1.2.linux-amd64.tar.gz cd node_exporter-1.1.2.linux-amd64 # 启动 nohup ./node_exporter --web.listen-address=":9100" & -
访问一下,确保node-exporter已正常启动
或者直接
curl 47.105.39.189:9100进行验证也可
-
在prometheus中配置当前采集项
编辑配置文件
vim /opt/prometheus/config/prometheus.yml增加当前采集项目

-
使得最新的prometheus配置生效
你可以重启prometheus或者使用热加载使新配置生效,这里我们使用热加载的方式
# 前提条件:启动prometheus时,启用了web.enable-lifecycle # 发送post请求到prometheus的/-/reload下触发热加载配置 curl -X POST http://47.105.39.189:9090/-/reload注:若你触发热加载后,过个一会儿还没看到监控的变化, 那么你可以使用
docker logs prometheus容器查看prometheus日志,看到底是否触发了热加载 -
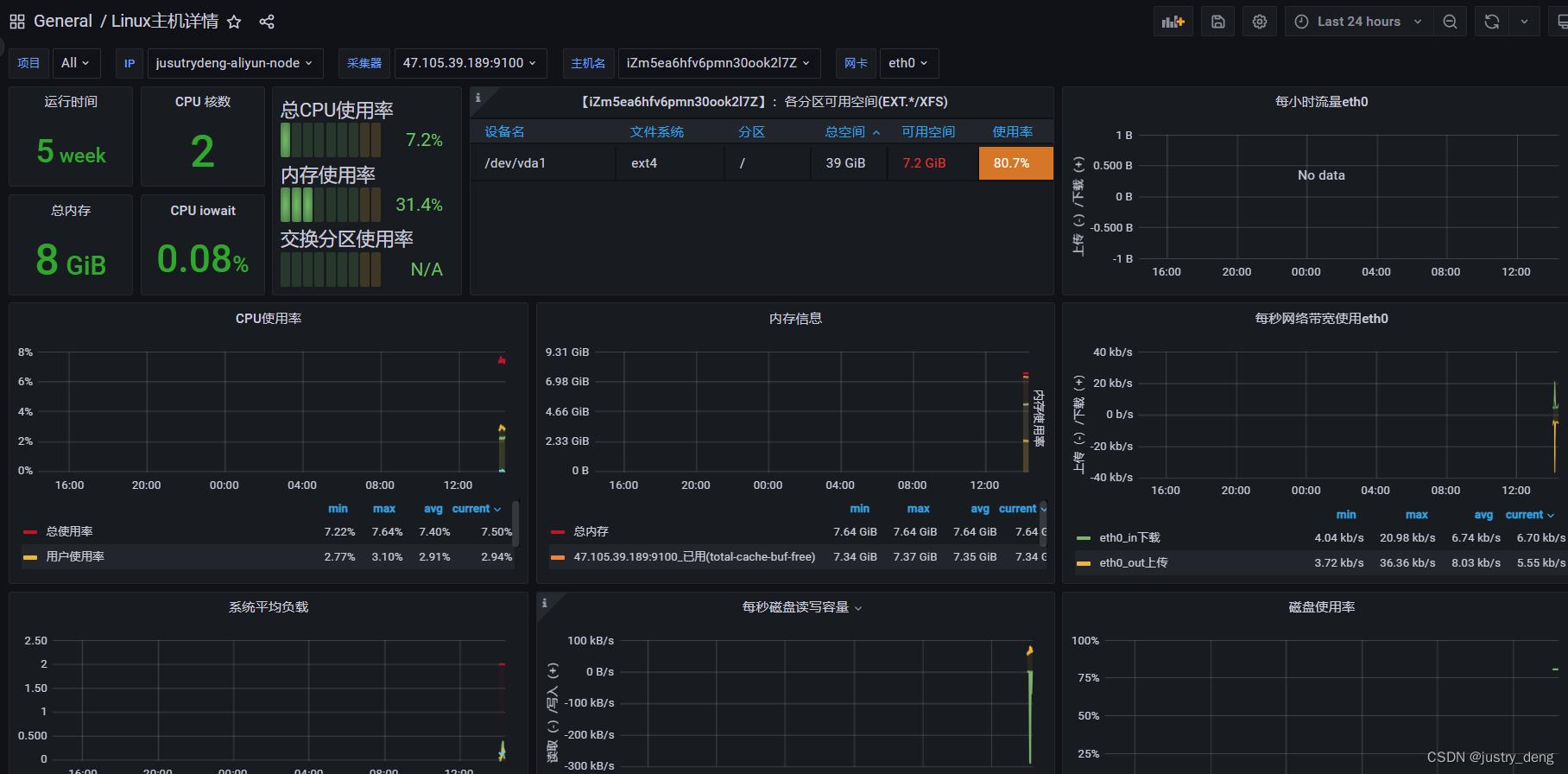
验证一下
此时,我们再在grafana上看监控面板,就会发现有数据了
安装alertmanager,集成进prometheus
安装alertmanager
第一步:确保安装有docker
查看docker版本
docker -v

第二步:拉取镜像
镜像有哪些版本,可以通过查看一个docker镜像有哪些版本查看
# 你也可以直接拉docker pull prom/alertmanager, 即拉取最新的镜像docker pull prom/alertmanager:lastest
docker pull prom/alertmanager:v0.25.0
第三步:准备相关挂载目录及文件
准备目录
# /opt/alertmanager/config目录,准备用来放置alertmanager的配置文件
# /opt/alertmanager/template目录,准备用来挂载放置alertmanager的模板文件
mkdir -p /opt/alertmanager/config,template
# 授权相关文件夹权限
chmod -R 777 /opt/alertmanager/config
chmod -R 777 /opt/alertmanager/template
准备配置文件
# 配置文件
cat > /opt/alertmanager/config/alertmanager.yml << \\EOF
global:
resolve_timeout: 5m
# 发件人
smtp_from: '1612513157@qq.com'
# 邮箱服务器的 POP3/SMTP 主机配置 smtp.qq.com 端口为 465 或 587
smtp_smarthost: 'smtp.qq.com:465'
# 用户名
smtp_auth_username: '1612513157@qq.com'
# 授权码 或 密码
smtp_auth_password: '你的qq授权码'
smtp_require_tls: false
smtp_hello: 'qq.com'
templates:
# 指定预警内容模板
- '/etc/alertmanager/template/email.tmpl'
route:
# 指定通过什么字段进行告警分组(如:alertname=A和alertname=B的将会被分导两个组里面)
group_by: ['alertname']
# 在组内等待所配置的时间,如果同组内,5 秒内出现相同报警,在一个组内出现
group_wait: 5s
# 如果组内内容不变化,合并为一条警报信息,5 分钟后发送
group_interval: 5m
# 发送告警间隔时间 s/m/h,如果指定时间内没有修复,则重新发送告警
repeat_interval: 5m
# 默认的receiver。 如果一个报警没有被任何一个route匹配,则发送给默认的接收器
receiver: 'justrydeng163email'
#子路由(上面所有的route属性都由所有子路由继承,并且可以在每个子路由上进行覆盖)
routes:
# 当触发当前预警的prometheus规则满足:标签alarmClassify的为normal时(标签名、标签值可以自定义,只要和编写的prometheus的rule里面设置的标签呼应上即可),往justrydeng163email发送邮件
- receiver: justrydeng163email
match_re:
alarmClassify: normal
# 当触发当前预警的prometheus规则满足:标签alarmClassify的值为special时(标签名、标签值可以自定义,只要和编写的prometheus的rule里面设置的标签呼应上即可),往justrydengQQemail发送邮件
- receiver: justrydengQQemail
match_re:
alarmClassify: special
receivers:
- name: 'justrydeng163email'
email_configs:
# 如果想发送多个人就以 ',' 做分割
- to: '13548417409@163.com'
send_resolved: true
# 接收邮件的标题
headers: Subject: "alertmanager报警邮件"
- name: 'justrydengQQemail'
email_configs:
# 如果想发送多个人就以 ',' 做分割
- to: '1249823187@qq.com'
send_resolved: true
# 接收邮件的标题
headers: Subject: "alertmanager报警邮件"
inhibit_rules:
- source_match:
severity: 'critical'
target_match:
severity: 'warning'
equal: ['alertname', 'dev', 'instance']
EOF
# 查看一下配置文件
cat /opt/alertmanager/config/alertmanager.yml
准备预警内容模板文件
# 因为我们进行了挂载,所以我们只需编辑宿主机上的模板文件即可
cat > /opt/alertmanager/template/email.tmpl << \\EOF
define "email.html"
<table border="1">
<tr>
<td>报警项</td>
<td>实例</td>
<td>报警阀值</td>
<td>开始时间</td>
<td>告警信息</td>
</tr>
range $i, $alert := .Alerts
<tr>
<td> index $alert.Labels "alertname" </td>
<td> index $alert.Labels "instance" </td>
<td> index $alert.Annotations "value" </td>
<td> $alert.StartsAt </td>
<td> index $alert.Annotations "description" </td>
</tr>
end
</table>
end
EOF
# 查看一下模板文件
cat /opt/alertmanager/template/email.tmpl
提示:模板文件中,占位符取值,取的是prometheus的rules文件中对应的值,你可以先写好prometheus的规则文件后,再来编写模板文件
第四步:启动容器
# 启动alertmanager (启动后docker ps检查一下,确保alertmanager起来了即可)
docker run -d --name=alertmanager \\
-p 9093:9093 \\
-v /etc/localtime:/etc/localtime:ro \\
-v /opt/alertmanager/config/alertmanager.yml:/etc/alertmanager/alertmanager.yml \\
-v /opt/alertmanager/template:/etc/alertmanager/template \\
prom/alertmanager:v0.25.0
第五步:确保alertmanager正常启动
# 查看一下docker容器
docker ps | grep alertmanager
# 再看一下alertmanager的日志
docker logs --tail=50 alertmanager
集成进prometheus
第一步:启用alertmanager
编辑配置文件
vim /opt/prometheus/config/prometheus.yml
启用alertmanager
# 启用alertmanager
alerting:
alertmanagers:
- static_configs:
- targets:
# alertmanager的地址
- 172.31.113.186:9093

第二步:增加prometheus预警规则
提示:prometheus的rules机制,即便不集成alertmanager也是可以用的
# 因为我们启动prometheus时,是挂载了宿主机的/opt/prometheus/rules目录到/prometheus/rules下,且配置了/prometheus/rules目录下所有的.rules文件都会被作为规则文件的
# 所以我们只需要将规则文件创建到宿主机的/opt/prometheus/rules目录下即可
cat > /opt/prometheus/rules/os.rules << \\EOF
groups:
- name: os
rules:
# prometheus是通过对应exporter的metric指标查询接口获取到被监测对象的数据的。当这个接口调用不通(或调用出错时),会认为up == 0,当持续时间满足for时,会发出对应的节点宕机预警
# 实际上,exporter的指标查询接口调不通,也可能是因为超时或者其它什么导致的,并不一定是被监控节点down机了
- alert: instance不可用(宕机或忙)告警
expr: up == 0
for: 1m
labels:
alarmClassify: normal
annotations:
summary: "监控程序 $labels.job 所监控机器不可用"
description: "监控程序 $labels.job (监控程序地址为 $labels.instance ) down机超过1分钟了"
- alert: CPU告警
expr: 100-(avg(irate(node_cpu_seconds_totalmode="idle"[5m])) by(instance)* 100) > 90
for: 5m
labels:
alarmClassify: normal
annotations:
summary: "CPU告警:CPU使用大于90%(目前使用:$value%)"
description: "CPU告警:监控程序$labels.instance所监控机器的CPU使用大于90%(目前使用:$value%). 已经持续5分钟了"
- alert: 内存告警
expr: 100 - ((node_memory_MemAvailable_bytes * 100) / node_memory_MemTotal_bytes) > 90
for: 30m
labels:
alarmClassify: normal
annotations:
summary: "内存告警:内存使用大于80%(目前使用:$value%)"
description: "内存告警:监控程序$labels.instance所监控机器的内存使用大于80%(目前使用:$value%)"
- alert: 磁盘分区使用率报警
expr: 100 - ((node_filesystem_avail_bytesfstype=~"rootfs|xfs",mountpoint=~"/|/etc/hosts" * 100) / node_filesystem_size_bytesfstype=~"rootfs|xfs",mountpoint=~"/|/etc/hosts") > 80
for: 1m
labels:
alarmClassify: normal
annotations:
summary: "磁盘分区告警:$labels.mountpoint 磁盘分区使用大于80%(目前使用:$value%)"
description: "磁盘分区告警:监控程序$labels.instance所监控机器的磁盘分区使用量大于80%(目前使用:$value%). 其它信息:device:$labels.device, mount:$labels.mountpoint "
- alert: 挂载磁盘分区使用率报警
expr: 100 - ((node_filesystem_avail_bytesmountpoint=~"/rootfs/newDisk|/backup" * 100) / node_filesystem_size_bytesmountpoint=~"/rootfs/newDisk|/backup") > 80
for: 1m
labels:
alarmClassify: normal
annotations:
summary: "挂载磁盘分区告警:$labels.mountpoint 挂载磁盘分区使用大于80%(目前使用:$value%)"
description: "挂载磁盘分区告警:监控程序$labels.instance所监控机器的挂载磁盘分区使用量大于80%(目前使用:$value%). 其它信息:device:$labels.device, mount:$labels.mountpoint "
- alert: IO性能
expr: ((irate(node_disk_io_time_seconds_total[30m]))* 100) > 95
for: 1m
labels:
alarmClassify: normal
annotations:
summary: "$labels.mountpoint 流入磁盘IO使用率过高"
description: "监控程序$labels.instance所监控机器的$labels.mountpoint 流入磁盘IO大于95%(目前使用:($value))"
- alert: 网络(入)
expr: ((sum(rate (node_network_receive_bytes_totaldevice!~'tap.*|veth.*|br.*|docker.*|virbr*|lo*'[5m])) by (instance)) / 100) > 10240
for: 5m
labels:
alarmClassify: normal
annotations:
summary: "$labels.mountpoint 流入网络带宽过高"
description: "监控程序$labels.instance所监控机器的 $labels.mountpoint 流入网络带宽持续5分钟高于10M. RX带宽使用率$value"
- alert: 网络(出)
expr: ((sum(rate (node_network_transmit_bytes_totaldevice!~'tap.*|veth.*|br.*|docker.*|virbr*|lo*'[5m])) by (instance)) / 100) > 10240
for: 5m
labels:
alarmClassify: normal
annotations:
summary: "$labels.mountpoint 流出网络带宽过高"
description: "监控程序$labels.instance所监控机器的 $labels.mountpoint 流出网络带宽持续5分钟高于10M. RX带宽使用率$value"
EOF
# 查看一下os.rules规则
cat /opt/prometheus/rules/os.rules
一条告警规则主要由以下几部分组成
alert:告警规则的名称
expr:基于PromQL表达式告警触发条件,用于计算是否有时间序列满足该条件
for:评估等待时间,可选参数。用于表示只有当触发条件持续一段时间后才发送告警。在等待期间新产生告警的状态为pending
labels:自定义标签,允许用户指定要附加到告警上的一组附加标签(注:如果自定义的标签名与prometheus.yml下内置的或配置的标签名一样,则会以这里设置的标签为主)
注:labels下默认有这些标签
alertname:告警规则的名称(即:alert指定的名称)
device:机器设备
fstype:文件系统类型
mountpoint:挂载点
job:采集任务名。(即:当前预警所属采集任务名,假设prometheus.yml如下所示,采集项aliyun-node预警了,那么这里对应的job值为:xxx)
instance:采集对象。(即:当前预警所属采集项地址,假设prometheus.yml如下所示,采集项aliyun-node预警了,那么这里对应的instance值为:47.105.39.189:9100)
global: 。。。省略 alerting: 。。。省略 rule_files: 。。。省略 scrape_configs: # 采集任务 - job_name: 'xxx' static_configs: - targets: ['47.105.39.189:9100'] # 设置采集任务标签 (注:如果预警规则里面设置有同名标签的话,预警时则会覆盖此标签) labels: env: prod name: justrydeng instance: xxx-instance group: 'ds'annotations:用于指定一组附加信息,比如用于描述告警详细信息的文字等,annotations的内容在告警产生时会一同作为参数发送到Alertmanager
占位符
$xxx,用于取值xxx对应的值如:$labels.instance,取当前规则文件下,instance标签的值
如:在annotations中,使用$value取触发当前预警的预警值
检查预警规则文件是否正确
# 进入容器 # docker exec -it 容器id 或 容器名 /bin/sh docker exec -it prometheus /bin/sh # 使用promtool 工具,执行check指令 # promtool check rules 规则文件,后缀名随意都可以 promtool check rules /prometheus/rules/os.rules
第三步:使得最新的prometheus配置生效
因为这里启用了alertmanager,为保险起见,本人这里选择重启prometheus(而不是使用prometheus的热加载)来使生效
# 重启容器prometheus
docker restart prometheus
# 查看日志
docker logs --tail=50 prometheus
第四步:验证预警生效
-
访问prometheus,查看预警规则是否有了

预警状态说明:
- Inactive:未触发预警
- Pending:满足预警规则里面的预警表达式expr了,但是持续时间不满足预警规则里面的for,尚未发送预警信息
- Firing:触发预警且已发送预警信息
-
查看邮箱,发现收到了预警消息

注:因为本人后来优化了上面的rule规则的配置内容,所以这里email里面的截图和上面的配置有点出入
相关资料
- docker安装prometheus+grafana安装详细教程
- AlertManager简介与告警模板
- 本文已被收录进《程序员成长笔记》 ,笔者JustryDeng
以上是关于docker安装prometheus和grafana的主要内容,如果未能解决你的问题,请参考以下文章
Ubuntu Server 18.04.1 Docker使用
是否可以运行 Prometheus 和 Grafana docker 容器但使用安装在主机中的 node-exporter?