Transformer
Posted -牧野-
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Transformer相关的知识,希望对你有一定的参考价值。
关键词
Dot Product(向量点乘)
向量的点乘是对这两个向量对应位一一相乘之后再求和的操作,点乘的结果是一个标量。
点乘的几何意义是可以用来表征或计算两个向量之间的夹角:

从而有:
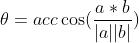
根据以上公式可以根据向量点乘结果推知两个向量之间的相互关系,具体的:
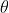 > 0 :两向量方向基本相同,夹角范围[0°,90°],正相关;
> 0 :两向量方向基本相同,夹角范围[0°,90°],正相关;
< 0: 两向量方向基本相反,夹角范围[90°,180°],负相关;
= 0 :两向量正交,夹角90°,完全不相关;
Attention
注意力机制,通过一定方法,给输入的表征序列中的每个元素分配一个权重系数,当前输出(可能是依次输出,每次输出一个结果元素)依据注意力系数,对输入序列中不同元素分配不一样的关注度。
所谓的Attention机制就是要从序列中学习到每个元素对结果的重要程度,然后按重要程度将输入的元素合并。
例如对于下图,输入的X1~X4的每个编码元素,对于输出的Y1、Y2、Y3对应不同的attention系数,按权重系数加权分别生成特征编码C1、C2、C3。
Self-attention
又称为内部注意力(intra-attention),是一种将单个序列中不同位置的元素互相关联起来,再以这种关联关系建立起序列表示(序列表征)的注意力机制。Self-attention是Attention的一种特例。
在Self-attention之前的Attention,重点强调的是输入序列中的各个元素对于输出的重要程度,而Self-attention强调的是当前输入(输出)序列中每一个元素对于本序列中其他元素的重要程度。
Attention Is All You Need论文中采用点乘(Dot Prodect)计算Self-attention注意力系数,所以论文中的Attention又叫Dot-Product Attention。
Self-attention并非本论文首创,论文中的表述是
“the Transformer is the first transduction model relying entirely on sele-attention to compute representations of its input and output without using sequence-aligned RNNs or onvolution”。
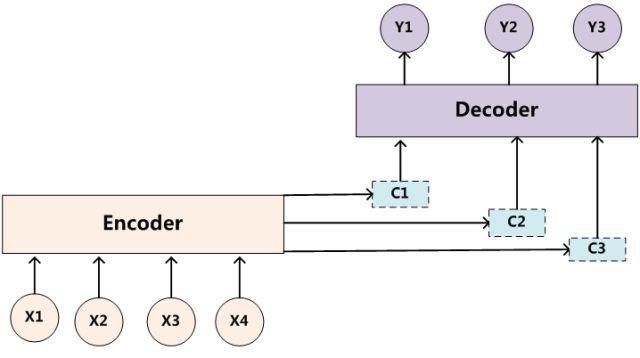
Query、Keys、Values vector(查询、键、值向量)
查询向量、键向量和值向量是输入(经编码)与三个矩阵分别相乘创建出的表征矩阵,三个矩阵是需要网络学习的参数。
查询向量q是用来匹配序列内所有元素的键向量k的,本元素自己的q与所有元素的k分别点乘获得attention权重,之后该attention权重分别叉乘上对应位置的值向量,再求和就得到当前元素的Self-attention结果。该过程见下图:
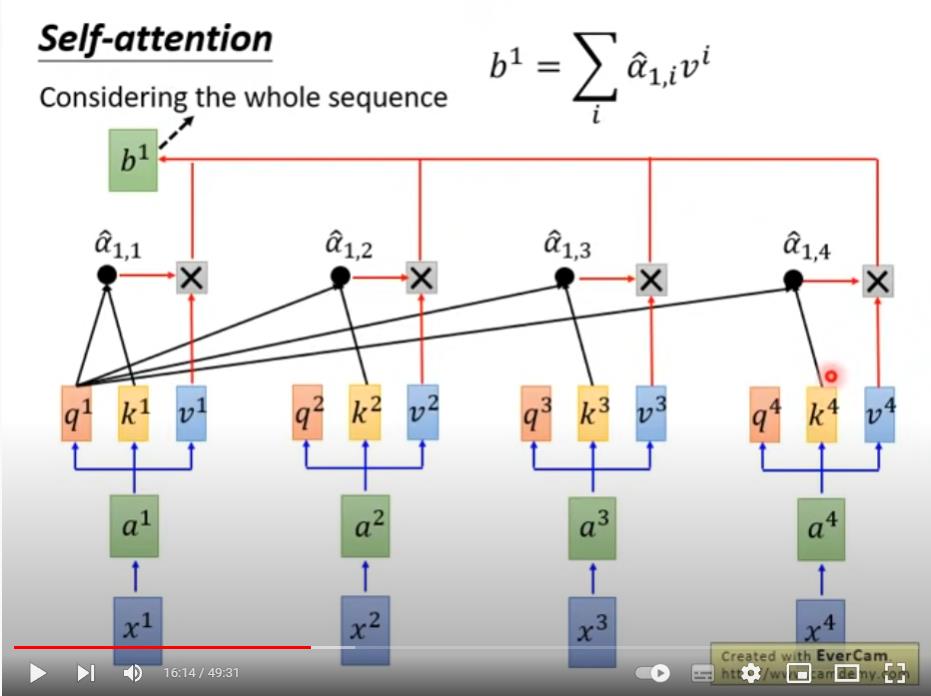
个人理解:q、k和v是输入向量在不同维度或不同空间上的表征特征,q主要是给当前元素自己算attention用的,k主要是给其他元素算attention用的,q和v两者计算出attention系数,而v是当前Self-attention模块“直接相关的”输出。
Transformer
下图是Transformer的结构图,左侧是Encoder部分,右侧是Decoder部分。
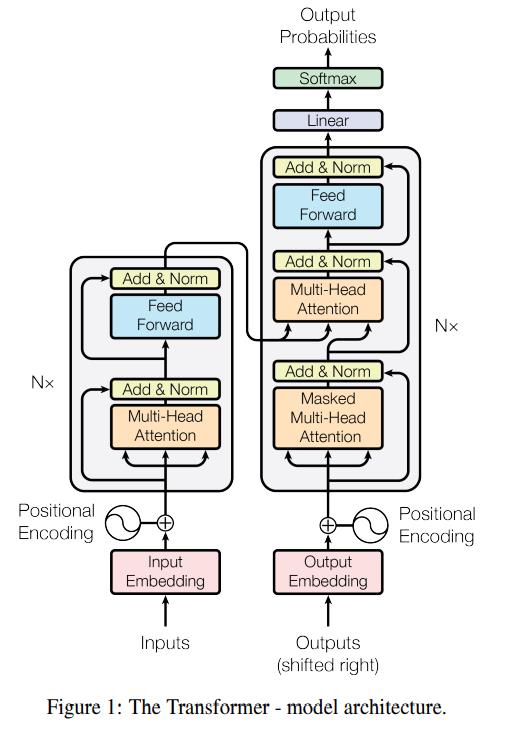
Input Embedding、Output Embedding
Embedding是词嵌入的意思,词嵌入是把输入的词汇序列映射到一个特定空间的多维向量表示上,方便执行其后的计算,这个映射是手动定义的,在一个任务中是固定的。
论文中是把每个单词映射到一个512维的向量上。
Positional Encoding
Attention的优点是可以获取局部与全局的关联信息,但是无法像CNN那样感知空间位置上的信息,即无法记录序列中元素的顺序或位置关系,为了弥补这个缺点,对Attention加入了位置编码(Positional Encoding)。
论文中的位置编码跟经Input Embedding后的向量具有相同的维度,具体操作是位置编码跟词嵌入直接相加。
论文中使用了正弦和余弦函数来做位置编码:
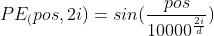
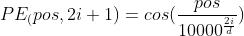
式中 表示单词在整个句子中的位置,如果句子含有10个单词,则
表示单词在整个句子中的位置,如果句子含有10个单词,则 ;
; 表示 词嵌入后的维度,论文中每个单词词嵌入后生成512维的向量,所以
表示 词嵌入后的维度,论文中每个单词词嵌入后生成512维的向量,所以 ;
;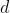 是维度,论文中是512;
是维度,论文中是512;
所以论文中是在偶数和奇数位交替使用正弦和余弦编码,丰富了位置表征所包含的绝对和相对位置信息,这里的位置编码是一种相对位置编码,即在同一个词向量的不同维度上可以有相同的编码,但是如果考虑到所有同一位置上相同维度的编码,则可以唯一确定一个位置点。
简单线性位置编码vs论文中正余弦编码
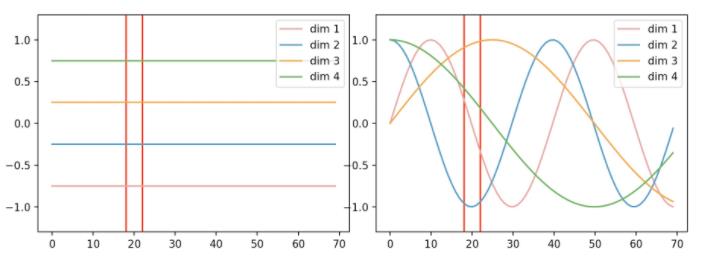
图源 https://www.ylkz.life/deeplearning/p10770524/
上图以长度是4,维度是70的序列举例,横坐标是单个词向量的维度坐标,纵坐标是词向量在句子中的位置。正弦余弦位置编码表征的信息更丰富。
Position Encoding不需过渡研读,包括固定的位置编码和带学习参数的位置编码,以及不同的位置编码方式,实际效果上差异并不大。
Multi-Head Attention

多头注意力通过把Q,K,V线性投影到不同的表示子空间(representation subspaces),提升了Self-attention的表征能力。
多头注意力的四个组件:
- 线性层并拆分成多头
- Self-attention
- 多头注意力concat
- 线性层
多头注意力机制允许模型在不同表征空间有不同的注意力。
input的维度是512,每个Multi-Head attention的维度是64,使用了8个多头,concat之后跟input的维度一致。
Add & Norm
Add是残差模块,直接把输入叠加到输出上。
Norm是Layer Norm,不是Batch Norm。Batch Norm做Norm是在同一个Batch内不同元素(样本)之间相同的维度上执行的,使得不同元素之间同一维度上的数值服从均值为0方差为1的分布,是协调元素与元素之间的分布;Layer Norm是在Batch内不同元素内各个维度上执行的,使得Batch内不同元素内所有维度上的数值服从均值0方差1的分布,是协调本元素内不同维度上的分布。
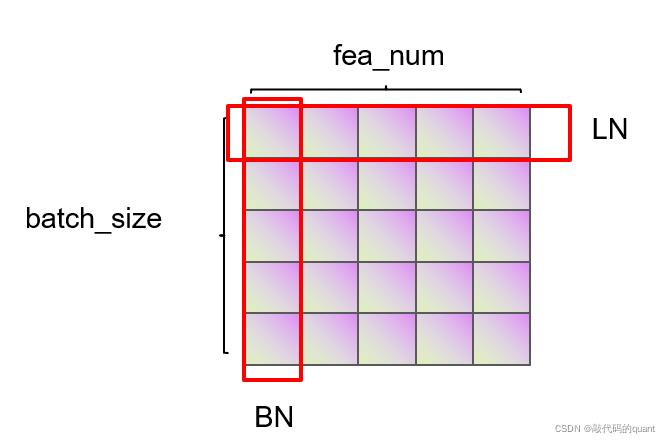
图源【机器学习】LayerNorm & BatchNorm的作用以及区别_敲代码的quant的博客-CSDN博客_layernorm
BN多适用于CV领域,LN多适用于NLP领域。
Feed Forward
每个Multi-Head Attention的输出后都接了一个Feed Forward层(FFN),公式是:
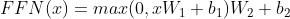
FFN是两个全连接层,是两个线性变换,中间有一个Relu激活。FFN参数不共享。
Masked Multi-Head Attention
Masked的意思是序列中部分元素的attention,因为只能在之前已经产生的output上做attention。
Scaled Dot-product Attention
Dot-product是说attention因子是通过计算两个向量的点积获得的。
论文提到两个最常见获取注意力的函数是additive attention 和 dot-product。
Additive attention使用含有一个隐藏层的前馈神经网络获得,输入是两个向量的Concat,所有相关向量输出之后再做Sigmoid,得到当前向量跟其他所有向量之间的相关度。
Dot-product Attention通过向量点积获得相关度。论文里Self-attention的公式是: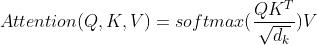
论文中Scaled就是上式中的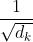 。论文中陈述的是Dot-product Attention与Additive attention理论复杂度相似,但实践中Dot-product attention执行速度更快以及更省内存。之所以加Scaled是因为论文怀疑对于较大的维度,点积的数值会更大,这就导致softmax之后数据集中在一小部分梯度区间,导致训练不稳定,加上Scaled尝试抵消这种影响,使得attention的分布与维度无关。
。论文中陈述的是Dot-product Attention与Additive attention理论复杂度相似,但实践中Dot-product attention执行速度更快以及更省内存。之所以加Scaled是因为论文怀疑对于较大的维度,点积的数值会更大,这就导致softmax之后数据集中在一小部分梯度区间,导致训练不稳定,加上Scaled尝试抵消这种影响,使得attention的分布与维度无关。
参考
Attention Is All You Need
Transformer 李宏毅
BERT大火却不懂Transformer?读这一篇就够了
以上是关于Transformer的主要内容,如果未能解决你的问题,请参考以下文章
[Python人工智能] 三十六.基于Transformer的商品评论情感分析 keras构建多头自注意力(Transformer)模型
[Python人工智能] 三十六.基于Transformer的商品评论情感分析 keras构建多头自注意力(Transformer)模型
轴承RUL预测代码基于TCNTCN和多头注意力(TCN和Transformer的encoder结合)Transformer模型的轴承RUL预测代码(精华)
翻译: 详细图解Transformer多头自注意力机制 Attention Is All You Need