Logistic模型的详细介绍
Posted
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Logistic模型的详细介绍相关的知识,希望对你有一定的参考价值。
参考技术A与多重线性回归的比较
logistic回归(Logistic regression) 与多重线性回归实际上有很多相同之处,最大的区别就在于他们的因变量不同,其他的基本都差不多,正是因为如此,这两种回归可以归于同一个家族,即广义线性模型(generalized linear model)。这一家族中的模型形式基本上都差不多,不同的就是因变量不同,如果是连续的,就是多重线性回归,如果是二项分布,就是logistic回归,如果是poisson分布,就是poisson回归,如果是负二项分布,就是负二项回归,等等。只要注意区分它们的因变量就可以了。
logistic回归的因变量可以是二分非线性差分方程类的,也可以是多分类的,但是二分类的更为常用,也更加容易解释。所以实际中最为常用的就是二分类的logistic回归。
logistic回归模型
一、模型简介
线性回归默认因变量为连续变量,而实际分析中,有时候会遇到因变量为分类变量的情况,例如阴性阳性、性别、血型等。此时如果还使用前面介绍的线性回归模型进行拟合的话,会出现问题,以二分类变量为例,因变量只能取0或1,但是拟合出的结果却无法保证只有这两个值。
那么使用概率的概念来进行拟合是否可以呢?答案也是否定的,因为
1.因变量的概率和自变量之间的关系不是线性的,通常呈S型曲线,并且这种曲线是无法通过曲线直线化进行处理的。
2.概率的取值应该在0-1之间,但是线性拟合的结果范围是整个实数集,并不能保证一定在0-1之间。
基于以上问题,我们需要找出其他解决思路,那就是logit变换(逻辑变换),我们将某种结果出现的概率和不出现的概率之比称为优势比P/(1-P),将优势比作为因变量,并且取其对数,这就是逻辑变换,通过逻辑变换使之与自变量之间呈线性关系,从而解决了上述问题1。同时也使得因变量的取值范围覆盖了整个实数集,也解决了上述问题2,我们将经过逻辑变换的线性模型称为logistic回归模型(逻辑回归模型),可以看出,逻辑回归也是一种线性回归模型,属于广义线性回归模型的范畴。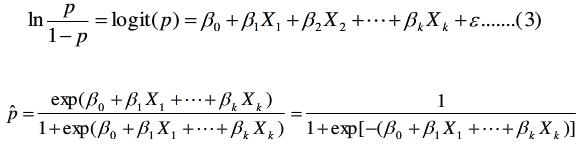
线性回归是根据回归方程预测某个结果的具体值,而逻辑回归则是根据回归方程预测预测某个结果出现的概率。
对因变量进行变换的方法很多,并不只有逻辑变换一种,只是逻辑变换应用最广,对于一些特殊情况,还需具体问题具体分析,不能一味的使用逻辑变换。
根据因变量的取值不同,逻辑回归可以分为:
1.二分类逻辑回归
2.有序多分类逻辑回归
3.无序多分类逻辑回归
4.配对逻辑回归
二、模型估计方法
逻辑回归不能使用普通最小二乘估计,而使用极大似然估计,也可以使用迭代重加权最小二乘法IRLS(Iteratively Reweighted Least Squares)
使用极大似然估计的好处是,这是一种概率论在参数估计中的应用,正好和我们对因变量的概率预测相符合。
极大似然估计也是一种迭代算法,先确定一个似然函数,然后求出能使这一似然函数最大时的参数估计。它基于这样的思想:如果某些参数能使这个样本出现的概率最大,那就不用再去选择其他参数,干脆就把这个参数作为估计的真实值。
三、优势比odds
前面讲过,某种结果出现的概率和不出现(注意顺序,是出现/不出现)的概率之比称为优势比,简称OR。也称为比值比或发生比,两个OR进行比较时,结果和对应的概率比较结果一致,因此,OR是否大于1可以看出两种情况下发生的概率大小的比较。
四、逻辑回归系数的意义
1.常数项
表示自变量全部取0时,某事件发生和不发生概率之比(Y=1和Y=0)的对数值,在不同的研究中,常数项的具体含义不同,在函数图中,常数项只影响图像的水平位置,为正时,函数左移;为负时,函数右移,在大多数情况下,逻辑回归的常数项没有太大意义。
2.回归系数
回归系数决定函数走向,正回归系数使事件发生的概率随x增大而增大,负回归系数使事件的概率随x增大而减小。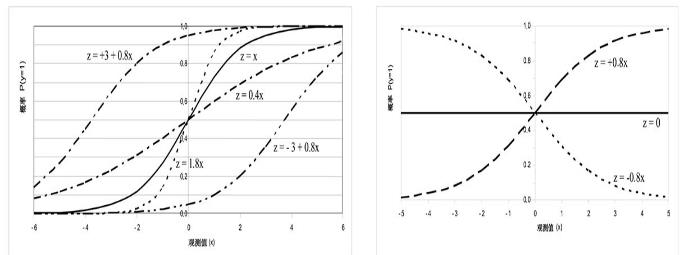
自变量增加一个单位,使某事件发生的优势比增加ebj倍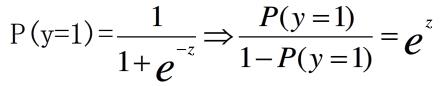
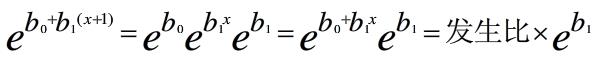
因此,优势比也可以看做是变量对发生概率的影响程度。
五、模型的检验
1.Wald检验
Wald检验用于判断一个变量是否应该包含在模型中,在变量筛选时使用,通过比较β值来进行。当回归系数很大时,会导致Wald统计量变得很小,增加第二类错误的概率,因此当回归系数很大时,应该用似然比检验来代替Wald检验,并且Wald检验也没有考虑共线性的影响。
2.似然比检验(Likelihood Ratio Test)
似然比检验用来判断模型在总体上是否显著,也可在变量筛选时使用,也可以作为判断拟合优度的标准。
该方法通过比较包含于不包含某些自变量的两个模型的对数似然函数之差进行。先拟合不包含自变量x的逻辑模型并求对数似然值,再拟合包含自变量x的逻辑模型并求对数似然值,计算统计量
该统计量近似服从自由度为自变量个数的卡方分布
在对模型总体进行检验时,假设
H0:所有回归系数都等于0(等价于不包含任何变量)
H1:所有回归系数不全为0(等价于包含相应变量)
在筛选变量时,假设
H0:待检测变量的回归系数都等于0(等价于不包含待检测变量)
H1:待检测变量的回归系数都不等于0(等价于包含待检测变量)
3.比分检验
也称为拉格朗日乘子检验,常用来做变量筛选,也近似服从卡方分布
以上三种方法是渐近等价的,在大样本情况下,都渐近服从卡方分布,并且都是基于极大似然原理。三种检验似然比检验最为可靠,其次为比分检验,最后为Wald检验。
4.伪决定系数
“伪”表示与线性回归模型中的决定系数相区别,但是含义并无不同,逻辑回归中的决定系数并不会像线性模型中的回归系数那么大,通常大于0.5就可认为拟合度良好。
常用的两个伪决定系数为
(1)Cox&Snell R2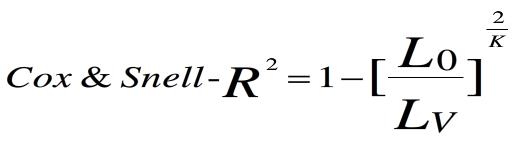
L0;零模型的似然,也就是模型只包含常数项时的似然
Lv:当前模型的似然,也就是包含自变量的模型的似然
K:样本容量
(2)Negelkerke R2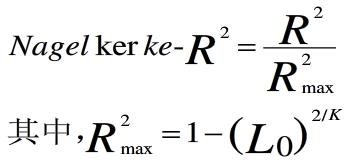
5.Akaike信息准则(AIC)
赤池信息准则是衡量拟合优度的常用标准,公式如下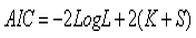
其中K为模型中自变量的数目,S为反应变量类别总数减1,对于逻辑回归有S=2-1=1。-2LogL的值域为0-∞,其值越小说明拟合越好。当模型中的参数数量越大时,似然值也就越大,-2LogL就变小。因此,将2(K+S)加到AIC公式中以抵销参数数量产生的影响。在其它条件不变的情况下,较小的AIC值表示拟合模型较好。
6.Schwarz准则(SC)
公式为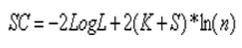
其中ln(n)是观测数量的自然对数。这一指标只能用于比较对同一数据所设的不同模型。在其它条件相同时,一个模型的AIC或SC值越小说明模型拟合越好。
7.Hosmer-Lemeshow检验
与一般的拟合优度检验不同,Hosmer-Lemeshow检验通常把数据分成10组,然后对每一组计算Pearson卡方,自由度则为组数减2,但是要注意该检验主要是检验预测值和观测值是否一致,越一致说明拟合越好,因此零假设为:预测值和观测值是否一致,而零假设不能拒绝的基础是P>α,所以一般来说P越大的话模型的拟合度较好,也可以直接看卡方值,也是越大拟合越好。
以上是关于Logistic模型的详细介绍的主要内容,如果未能解决你的问题,请参考以下文章