MapReduce案例
Posted 摸鱼的老山羊
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了MapReduce案例相关的知识,希望对你有一定的参考价值。
美国新冠疫情COVID-19数据统计
统计美国各州病例数量
需求分析
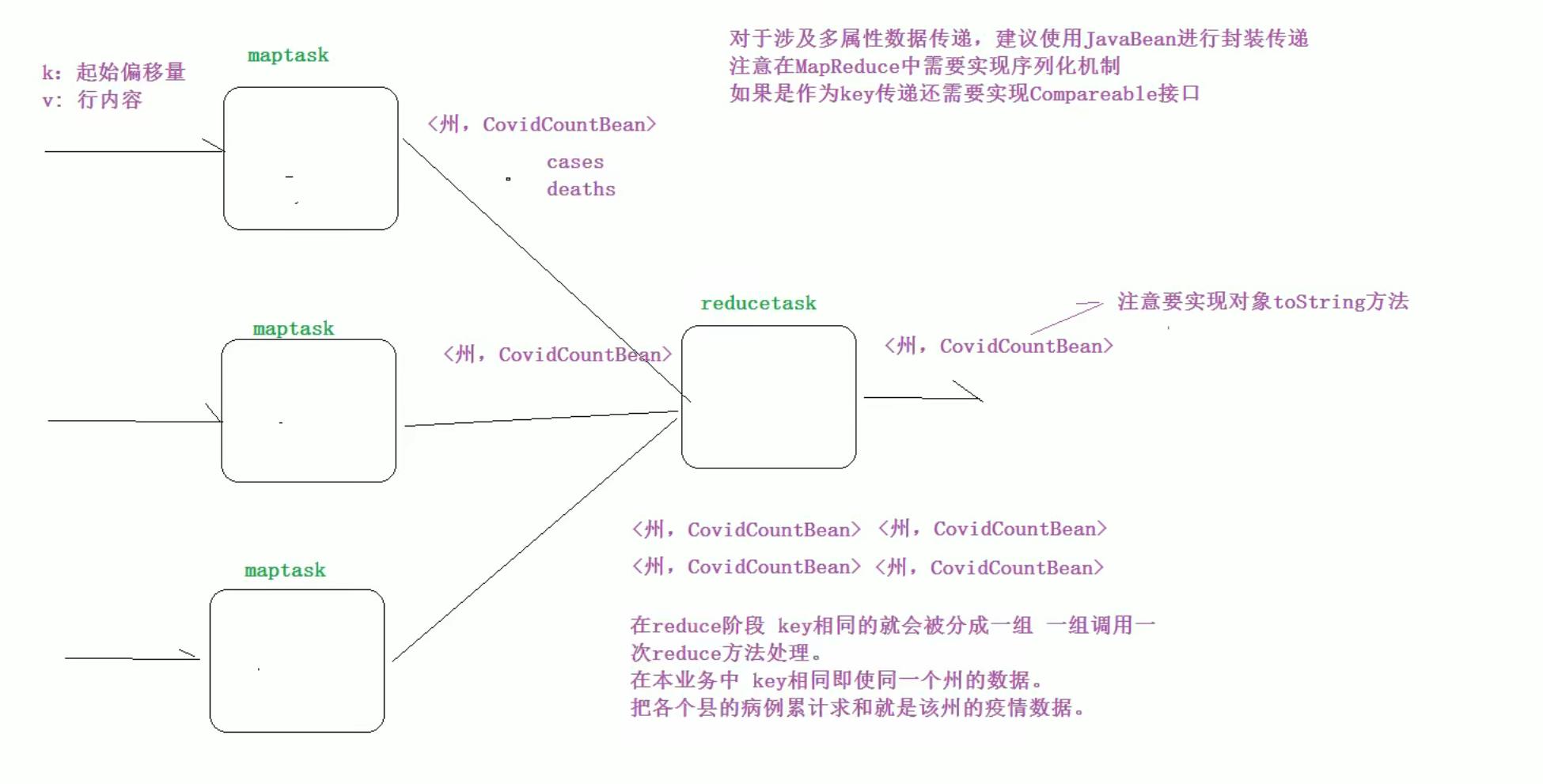
- 1、自定义对象CovidCountBean,用于封装每个县的确诊病例数和死亡病例数。
- 2、注意自定义对象需要实现Hadoop的序列化机制。
- 3、以州作为map阶段输出的key,以CovidCountBean作为value,这样属于同一个州的数据就会变成一组进行reduce处理,进行累加即可得出每个州累计确诊病例。
画图分析
代码实现
CovidCountBean
import org.apache.hadoop.io.Writable;
import java.io.DataInput;
import java.io.DataOutput;
import java.io.IOException;
public class CovidCountBean implements Writable
private long cases; //确诊病例数
private long deaths; //死亡病例数
public CovidCountBean()
public CovidCountBean(long cases, long deaths)
this.cases = cases;
this.deaths = deaths;
public long getCases()
return cases;
public long getDeaths()
return deaths;
public void set(long cases, long deaths)
this.cases = cases;
this.deaths = deaths;
@Override
public String toString()
return cases+"\\t"+deaths;
/**
* 序列化方法,控制哪一些字段可以序列化出去
* @param dataOutput
* @throws IOException
*/
@Override
public void write(DataOutput dataOutput) throws IOException
dataOutput.writeLong(cases);
dataOutput.writeLong(deaths);
/**
* 反序列化方法 注意反序列的读取顺序,和序列化的写入顺序是一样的
* @param dataInput
* @throws IOException
*/
@Override
public void readFields(DataInput dataInput) throws IOException
this.cases = dataInput.readLong();
this.deaths = dataInput.readLong();
CovidSumMapper
import cn.hwq.mapreduce.covid.bean.CovidCountBean;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Mapper;
import java.io.IOException;
public class CovidSumMapper extends Mapper<LongWritable, Text, Text, CovidCountBean>
Text outKey = new Text();
CovidCountBean outValue = new CovidCountBean();
@Override
protected void map(LongWritable key, Text value, Mapper<LongWritable, Text, Text, CovidCountBean>.Context context) throws IOException, InterruptedException
//读取一行数据 进行切割
String[] fields = value.toString().split(",");
//提取数据 州 确诊病例 死亡病例
outKey.set(fields[2]);
// outValue.set(Long.parseLong(fields[4]),Long.parseLong(fields[5])); 这里这样写可能出现下标越界,因为某些数据有缺失 如果还这样访问就会出现异常 需要考虑到特殊情况
outValue.set(Long.parseLong(fields[fields.length - 2]),Long.parseLong(fields[fields.length - 1]));
//输出结果
context.write(outKey,outValue);//<州,CovidCountBean>
CovidSumReducer
import cn.hwq.mapreduce.covid.bean.CovidCountBean;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Reducer;
import java.io.IOException;
public class CovidSumReducer extends Reducer<Text, CovidCountBean, Text, CovidCountBean>
CovidCountBean outValue = new CovidCountBean();
@Override
protected void reduce(Text key, Iterable<CovidCountBean> values, Reducer<Text, CovidCountBean, Text, CovidCountBean>.Context context) throws IOException, InterruptedException
//统计变量
long cases = 0; //确诊病例
long deaths = 0; //死亡病例
//遍历该州各个县的数据,并累加
for (CovidCountBean value : values)
cases += value.getCases();
deaths += value.getDeaths();
outValue.set(cases, deaths);
context.write(key,outValue);
CovidSumDriver
import cn.hwq.mapreduce.covid.bean.CovidCountBean;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
/**
* @description: 美国各县新冠疫情汇总统计 客户端驱动类
*/
public class CovidSumDriver
public static void main(String[] args) throws Exception
//配置文件对象
Configuration conf = new Configuration();
// 创建作业实例
Job job = Job.getInstance(conf, CovidSumDriver.class.getSimpleName());
// 设置作业驱动类
job.setJarByClass(CovidSumDriver.class);
// 设置作业mapper reducer类
job.setMapperClass(CovidSumMapper.class);
job.setReducerClass(CovidSumReducer.class);
// 设置作业mapper阶段输出key value数据类型
job.setMapOutputKeyClass(Text.class);
job.setMapOutputValueClass(CovidCountBean.class);
//设置作业reducer阶段输出key value数据类型 也就是程序最终输出数据类型
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(CovidCountBean.class);
// 配置作业的输入数据路径
FileInputFormat.addInputPath(job, new Path(args[0]));
// 配置作业的输出数据路径
FileOutputFormat.setOutputPath(job, new Path(args[1]));
//判断输出路径是否存在 如果存在删除
FileSystem fs = FileSystem.get(conf);
if(fs.exists(new Path(args[1])))
fs.delete(new Path(args[1]),true);
// 提交作业并等待执行完成
boolean resultFlag = job.waitForCompletion(true);
//程序退出
System.exit(resultFlag ? 0 :1);
结果示例
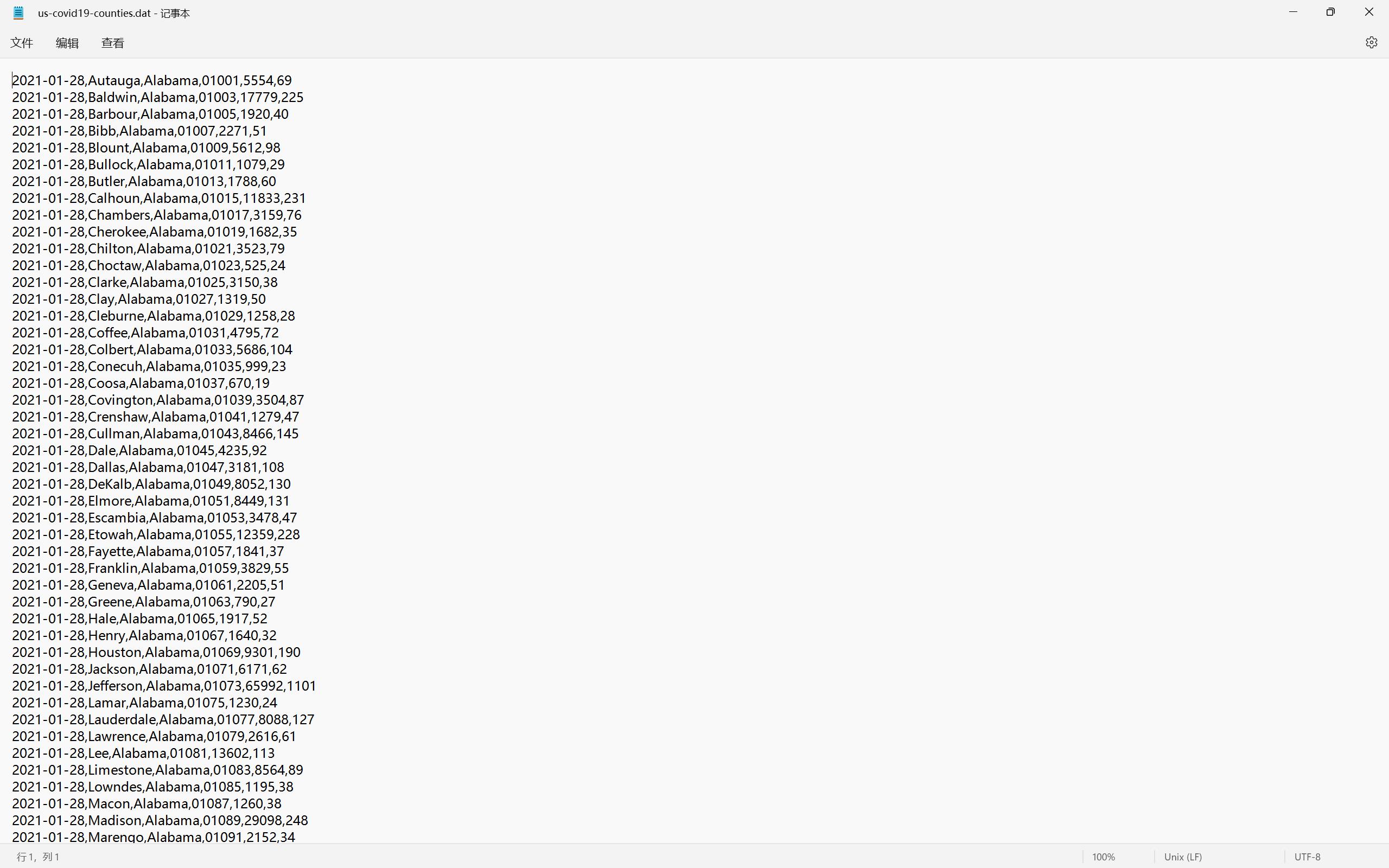
输入文件
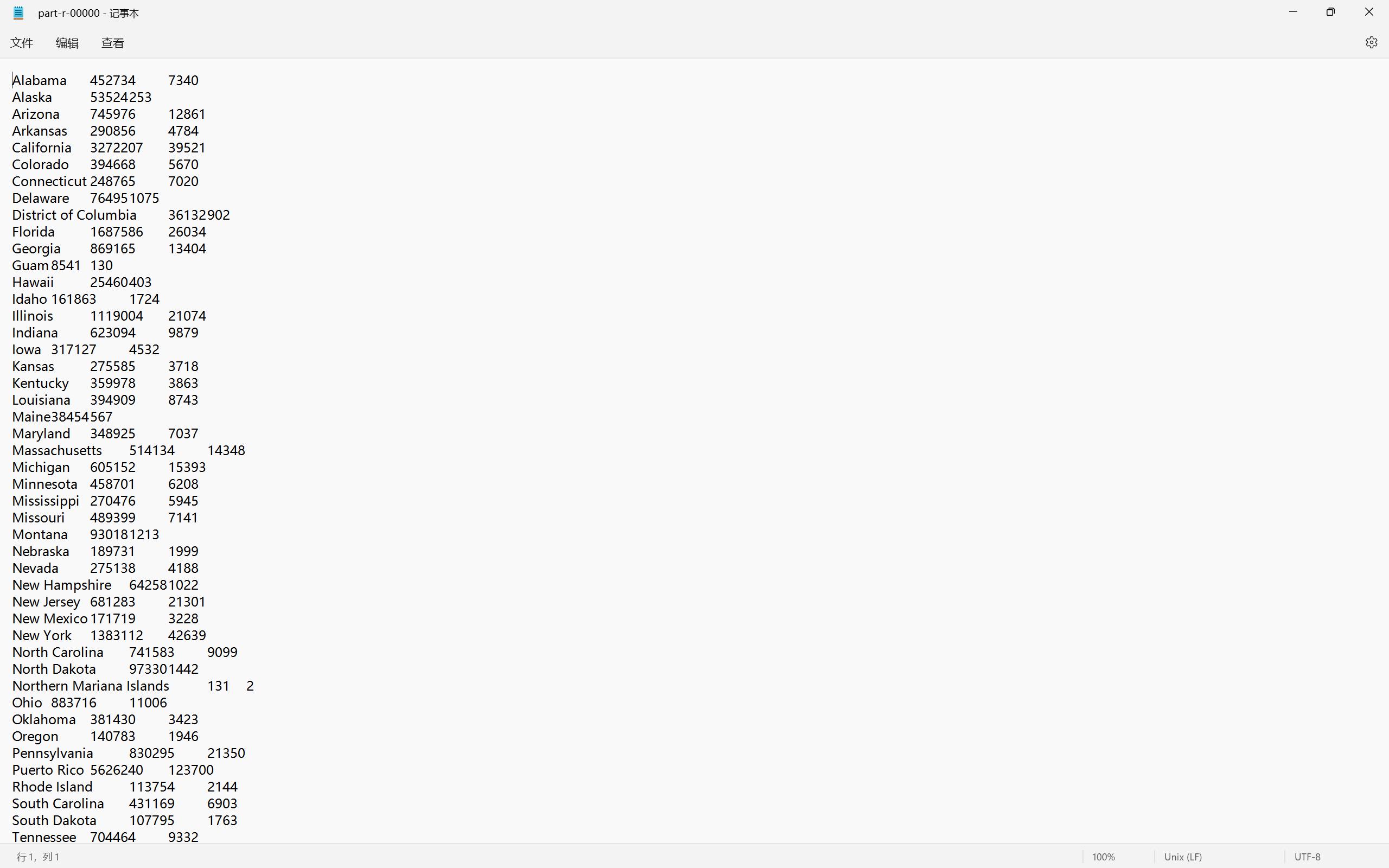
输出文件part-r-00000
- 统计了美国每个州的确诊病例和死亡病例
以上是关于MapReduce案例的主要内容,如果未能解决你的问题,请参考以下文章