邻接表边节点是啥
Posted
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了邻接表边节点是啥相关的知识,希望对你有一定的参考价值。
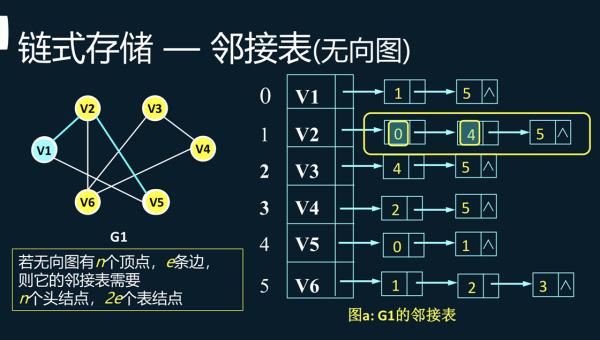
邻接表边节点是 n个顶点的无向图最多有n(n-1)/2条边,邻接表中1条边被存储了2次,因此最多有n(n-1)个结点。
邻接表是图的一种最主要存储结构,用来描述图上的每一个点。对图的每个顶点建立一个容器(n个顶点建立n个容器),第i个容器中的结点包含顶点Vi的所有邻接顶点。实际上我们常用的邻接矩阵就是一种未离散化每个点的边集的邻接表。
在有向图中,描述每个点向别的节点连的边(点a->点b这种情况);在无向图中,描述每个点所有的边(点a-点b这种情况)。
扩展资料:
先用边集表存图,然后每条边a,b得优先以std::min(a,b)为第一关键字再按std::max(a,b)为第二关键字排序,再按照修正后的存图方法存图即可。具体代码见nocow上骑马修栅栏那题lgeecn发的题解和代码。
如果使用list存图可以先存图再用list.sort()函数进行排序,不过似乎效率会差一些,毕竟相对于vector,list常数太大了,达到6倍以上。
存图真心不简单,因为真正用的时候你可能会遇到各种问题,但是你可以加以思考,进行容器搭配使用,即可解决。
参考技术A n个顶点的无向图最多有n(n-1)/2条边邻接表中1条边被存储了2次,因此最多有n(n-1)个结点追问能说说边结点概念吗
多杈树的邻接矩阵实现--插入删除前序遍历
分支任意的树构造的方法主要有两种,邻接矩阵和兄弟链表。邻接矩阵主要用于输入的范围很小的情况,因为矩阵反应的是对应情况,比如树的每一个节点都给与对应顺序的编号的话,如果有100个输入,就需要一个100*100的数组来存储联接关系。
链表的形式一般用于输入量很大的情况,可以很方便的适应。(需要仔细体会一下区别)
邻接矩阵的使用方法:
邻接矩阵的行数代表父节点ID,每一行用来存储其各子节点ID。比如 0 节点下面添加了一个子节点1的话,就需要在数组的第0行的第Tree(邻接数组名)[0]的位置上写入1.这里涉及到下面的小技巧中的每一行的第0位的使用。
邻接矩阵的使用小技巧:
邻接矩阵的每一行的第0位放当前父亲节点的子节点的数量,这样在遍历的时候可以很方便的控制循环。而且在插入新的节点的时候第0位里面的数字就是当前要放入数据的数组的下标(这里的方法很像之前学过的计数排序,把计数值从前一位累加到后一位,这样对应位置里面放的数值就是当前数据应该放在输出数组中的位置。计数排序一会可以再写一个随笔记录一下)。
用法举例:
Tree[fatherID][0]++;//这里是放的当前父亲节点的子节点的数量
Tree[fatherID][Tree[fatherID][0]] = childID;//把当前要插入的子节点放在它应该对应的数组位置上
如果单单是插入的话只需要一个邻接矩阵存储父节点对应的子节点的关系就可以了。但是如果要删除的话,我们往往只是给定当前要删除的节点的标号。这样的话我们没办法找到他的父节点(除非从root节点开始遍历我们刚才生成的邻接数组),这时候我们又需要一个数组来记录子对于父的连接关系(这里就有点像双向链表了,双向链表要实现的也是类似的功能,如果要删除当前节点,只要通过node->pre找到他的父亲节点,然后通过指针操作,把父亲节点的->next指向下一个node,把下一个node的->pre指向前面一个node即可)。于是我们创建一个Father[]数组来存储每一个节点的父亲节点标号。因为所有的节点肯定只有一个父亲(可以有多个孩子,但是只可能有一个父亲,这里仔细体会一下)。
int FatherID[MAX_ID];//存放每一个节点的父节点
我们在插入的时候要把fatherID放到FatherID数组的对应位置上,这样只要知道子节点和FatherID[]数组就可以知道当前的子节点的父亲节点是谁。
对应代码:
void insertNode(int fatherID,int childID){ Tree[fatherID][0]++; Tree[fatherID][Tree[fatherID][0]] = childID; FatherID[childID] = fatherID; }
所以在删除的时候我们要做的就是通过子节点和FatherID[childID] 找到他的父亲节点,然后维护自己创建的数据结构。这里面只有两个数据结构,1.FatherID[childID] 2.int Tree[MAX_ID][MAX_ID]; 因为我们只是通过FatherID数组来找父亲节点,所以嗯。。(纠结了一下)也可以把FatherID对应子节点位置的数组置零,主要是要更改Tree数组的值,
1.要更改Tree[fatherID][0]的值,子节点少了一个。需要把子节点的数目减1
2.要更改Tree[fatherID][Tree[fatherID][0]]的值,子节点已经删去了。需要把对应位置的对应关系删去,即把Tree[fatherID][Tree[fatherID][0]]清零
for(int i=1;i<MAX_ID;i++){ if(Tree[fatherId][i]==Id){ Tree[fatherId][i]=0; Tree[fatherId][0]--;
return; } }
好了进行到最后一个步骤,需要前序遍历生成的树。
刚开始我总是想着要用FatherID这个数组,因为这个数组初始化的时候把对应位置初始化成了自己,这样在向上遍历的时候只要遍历到了自己的话就证明他是根节点。可以作为递归的出口(这里也不是想的很明白。。。汗-_-||等有时间再比较一下数组构建的二叉树的前序,然后更新一下)
但是用当前节点子节点的个数作为递归变量会更好一点(有点像那道给出前序和中序求后序遍历的题目一样,每一次递归的传入量就是当前的前序和中序,用长度来控制传入的前序和中序的字符串,根据每一次的前序提供的根再做下一次的划分,直到当前中序的长度为1,证明不能向下分割了,就是递归的出口)
所以我先把根打印出来,然后对于替换当前的父节点位置,和父节点下面的子节点的个数,如果子节点的个数为零的时候就return。
void preorder(int fatherID,int n){//父亲节点有几个根节点 if(n==0){return;} for(int i=1;i<n+1;i++){ printf("%d ",Tree[fatherID][i]);//root preorder(Tree[fatherID][i],count(Tree,Tree[fatherID][i]));//从前到后面遍历每一个节点 } }
哦,count函数就是为了计算当前的节点下面有几个子节点:利用了Tree[][]数组。(这里面特别骚气的循环是和金老师学的。这样可以少定义一个ret遍历,而且可以少一步传值的过程)
int count(int data[MAX_ID][MAX_ID],int fatherID){ int i=1; for(;data[fatherID][i]!=0;i++){ ; } return i-1; }
最终的代码:
#include <stdio.h> #define MAX_ID 20 int Tree[MAX_ID][MAX_ID];//存放对应关系 int FatherID[MAX_ID];//存放每一个节点的父节点 void insertNode(int fatherID,int childID){ Tree[fatherID][0]++; Tree[fatherID][Tree[fatherID][0]] = childID; FatherID[childID] = fatherID; } void delNode(int Id){ int fatherId = FatherID[Id]; FatherID[Id] = 0; for(int i=1;i<MAX_ID;i++){ if(Tree[fatherId][i]==Id){ Tree[fatherId][i]=0; Tree[fatherId][0]--; return; } } } //计算当前父亲节点有几个子节点 int count(int data[MAX_ID][MAX_ID],int fatherID){ int i=1; for(;data[fatherID][i]!=0;i++){ ; } return i-1; } void preorder(int fatherID,int n){//父亲节点有几个根节点 if(n==0){return;} for(int i=1;i<n+1;i++){ printf("%d ",Tree[fatherID][i]);//root preorder(Tree[fatherID][i],count(Tree,Tree[fatherID][i]));//从前到后面遍历每一个节点 } } void init(){ for(int i=0;i<MAX_ID;i++){ for(int j=0;j<MAX_ID;j++){ Tree[i][j] = 0; } } for(int i=0;i<MAX_ID;i++){ FatherID[i] = i;//指向它自己 } } int main(){ insertNode(0,1); insertNode(0,2); insertNode(0,3); insertNode(0,4); insertNode(1,5); insertNode(1,7); insertNode(2,8); insertNode(3,9); insertNode(4,10); insertNode(4,11); insertNode(11,12); insertNode(10,13); delNode(12); delNode(13); int num = count(Tree,0); printf("0 "); preorder(0,num); return 0; }
递归的过程还是不是那么的清晰,要再好好想想。
以上是关于邻接表边节点是啥的主要内容,如果未能解决你的问题,请参考以下文章
每个邻接链表中的边结点都是按照序号从大到小的顺序链接而成是啥意思?
数据结构问题 在邻接表中啥是表节点?啥是表头节点?啥是头节点?