算法LRUCache示例 (LeetCode146)
Posted Kant101
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了算法LRUCache示例 (LeetCode146)相关的知识,希望对你有一定的参考价值。
链接
JAVA
方法1
- 采用HashMap存储键值对;
- 采用LinkedHashSet存储键的使用情况,因为LinkedHashSet是按插入顺序来存储值的,当容量到顶时,直接删除第一个值即可。
class LRUCache
private LinkedHashSet<Integer> lru;
private HashMap<Integer, Integer> cache;
private int capacity;
public LRUCache(int capacity)
cache = new HashMap<>(capacity);
lru = new LinkedHashSet<>();
this.capacity = capacity;
public int get(int key)
if (!cache.containsKey(key))
return -1;
lru.remove(key);
lru.add(key);
return cache.get(key);
public void put(int key, int value)
if (cache.containsKey(key))
cache.put(key, value);
lru.remove(key);
lru.add(key);
else
cache.put(key, value);
lru.add(key);
if (cache.size() > capacity)
int removeKey = -1;
for (Integer firstKey : lru)
removeKey = firstKey;
break;
lru.remove(removeKey);
cache.remove(removeKey);

方法2
重写 LinkedHashMap 的 **removeEldestEntry()** 方法,使得当达到LRUCache缓存的容量上限时,删除掉最老的元素,也就是最近最少使用的元素。
从LinkedHashMap的源码中看到,当在构造LinkedHashMap时设置了accessOrder 参数为true后,调用get() 或 getOrDefault() 方法后,都会调用如下的 afterNodeAccess() 方法,将最近访问过的结点放发到最后。

从LinkedHashMap的源码中看到,每次调用 put 方法后都会调用如下的 afterNodeInsertion() 方法,当 removeEldestEntry() 方法返回 true 时,就会删除 eldest 的结点。
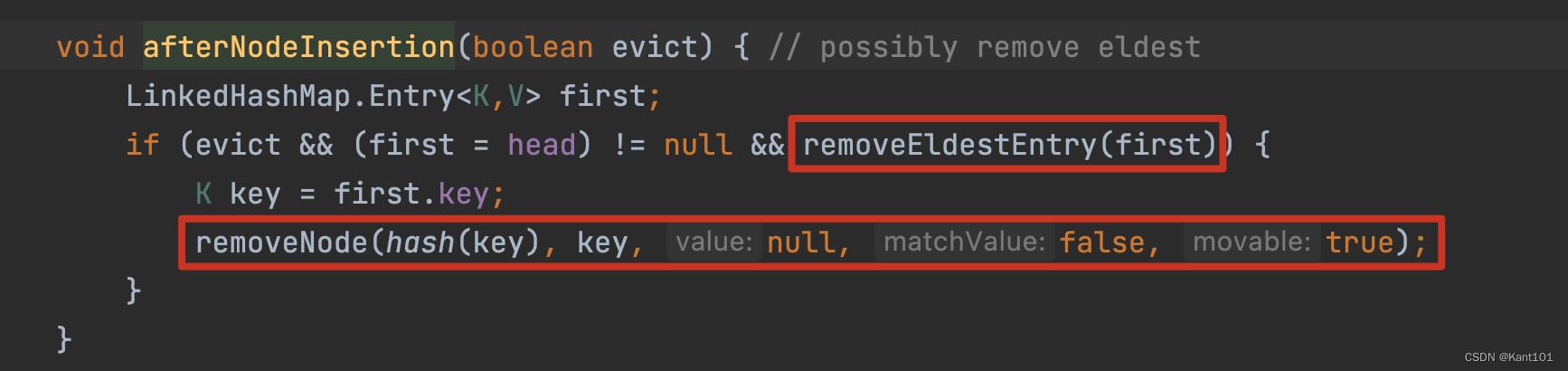
因此到我们重写 removeEldestEntry() 方法,使得容量大于LRUCache的capacity时删除掉最老的那个元素,也就实现了删除最近最少使用的目的,实现了LRUCache。
class LRUCache
private final int capacity;
private final LinkedHashMap<Integer, Integer> map;
public LRUCache(int capacity)
this.capacity = capacity;
/*
Override the `removeEldestEntry` of LinkedHashmap.
first param : capacity at the time the hash table is created
second param: default load factor: measure of how full the hash table is allowed
https://stackoverflow.com/questions/10901752/what-is-the-significance-of-load-factor-in-hashmap
third param: accessOrder – the ordering mode - true for access-order, false for insertion-order
*/
map = new LinkedHashMap<Integer, Integer>(capacity, 0.75f, true)
@Override
protected boolean removeEldestEntry(Map.Entry eldest)
return size() > capacity;
;
public int get(int key)
return map.getOrDefault(key, -1);
public void put(int key, int value)
map.put(key, value);
虽然跟方法一的原理差不多,但是不得不说JAVA库函数的效率要高得多。
C++
class LRUCache
private:
int cap;
list<pair<int, int>> l;
unordered_map<int, list<pair<int, int>>::iterator> m;
public:
LRUCache(int capacity)
this->cap = capacity;
int get(int key)
auto it = m.find(key);
if (it == m.end()) return -1;
l.splice(l.begin(), l, it->second);
return it->second->second;
void put(int key, int value)
auto it = m.find(key);
if (it != m.end()) l.erase(it->second);
l.push_front(make_pair(key, value));
m[key] = l.begin();
if (m.size() > cap)
int k = l.rbegin()->first;
l.pop_back();
m.erase(k);
;

OJ中C++偶尔会超时。
参考文献
[1] https://leetcode.com/problems/lru-cache/discuss/2425126/Java-solution-using-LinkedHashmap-(very-short-code).
[2] https://leetcode.com/problems/lru-cache/discuss/2425119/Java-Solutionor-Using-LinkedHashMap-and-HashMap-without-using-removeEldestEntry()-of-LinkedHashMap.
以上是关于算法LRUCache示例 (LeetCode146)的主要内容,如果未能解决你的问题,请参考以下文章