LeetCode 146. LRU 缓存
Posted 英雄哪里出来
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了LeetCode 146. LRU 缓存相关的知识,希望对你有一定的参考价值。

文章目录
一、题目
1、题目描述
请你设计并实现一个满足
LRU(最近最少使用) 缓存 约束的数据结构。实现LRUCache类:
LRUCache(int capacity)以 正整数作为容量capacity初始化LRU缓存;
int get(int key)如果关键字 k e y key key 存在于缓存中,则返回关键字的值,否则返回-1。
void put(int key, int value)如果关键字key已经存在,则变更其数据值value;如果不存在,则向缓存中插入该组key-value。如果插入操作导致关键字数量超过capacity,则应该逐出最久未使用的关键字。
函数get和put必须以 O ( 1 ) O(1) O(1) 的平均时间复杂度运行。
样例输入:["LRUCache", "put", "put", "get", "put", "get", "put", "get", "get", "get"] [[2], [1, 1], [2, 2], [1], [3, 3], [2], [4, 4], [1], [3], [4]]
样例输出:[null, null, null, 1, null, -1, null, -1, 3, 4]
2、基础框架
- C语言 版本给出的基础框架代码如下:
typedef struct
LRUCache;
LRUCache* lRUCacheCreate(int capacity)
int lRUCacheGet(LRUCache* obj, int key)
void lRUCachePut(LRUCache* obj, int key, int value)
void lRUCacheFree(LRUCache* obj)

3、原题链接
LeetCode 146. LRU 缓存
面试题 16.25. LRU 缓存
剑指 Offer II 031. 最近最少使用缓存
二、解题报告
1、思路分析
(
1
)
(1)
(1) 对于这种设计题,我们首先要想清楚每个步骤的时间复杂度要求,如果数据给定的操作是常数级别,那么这个操作可以采用
O
(
n
)
O(n)
O(n) 的算法;否则就要往
O
(
1
)
O(1)
O(1) 或者
O
(
l
o
g
n
)
O(logn)
O(logn) 去考虑。
(
2
)
(2)
(2) 对于创建操作lRUCacheCreate,只有一次操作,所以
O
(
n
)
O(n)
O(n) 一般是没有什么问题的。
(
3
)
(3)
(3) 对于获取操作lRUCacheGet,如果要求
O
(
1
)
O(1)
O(1),只有 数组 或者 哈希表 (大概率就是哈希表了)。
(
4
)
(4)
(4) 对于插入操作lRUCachePut,如果要求
O
(
1
)
O(1)
O(1),数组放进最后一个元素的操作是
O
(
1
)
O(1)
O(1) 的,链表放进第一个元素的操作是
O
(
1
)
O(1)
O(1) 的。
(
5
)
(5)
(5) 如果插入操作导致关键字数量超过 capacity,则应该逐出最久未使用的关键字。表明 插入 和 删除 操作是操作的一个表的头和尾。要求头和尾都能够进行插入删除的,是队列。但是,在执行插入操作的时候,如果一个数被插入,势必会改变它的 “最久未使用” 属性,想要快速改变位置,就只能用链表,然后又涉及到头和尾,所以必须是 双向链表 (所以,它不是一个队列)。
(
6
)
(6)
(6) 所以这个题,需要用到的数据结构就是 双向链表 + 哈希表。
2、时间复杂度
O ( n ) O(n) O(n)。
3、代码详解
1)定义
定义一个双向链表的结点BiNode,包含值val、前驱结点prev、后继结点next。
再定义一个LRUCache,包含双向链表的结点哈希表hash、双向链表的头尾指针head和tail、对于双向链表当前有多少个结点size、双向链表总共能够存放多少个结点capacity。
struct BiNode
int key;
int val;
struct BiNode *prev;
struct BiNode *next;
;
typedef struct
struct BiNode *hash[100001];
struct BiNode *head;
struct BiNode *tail;
int size;
int capacity;
LRUCache;
2)初始化
初始化就是把定义的结构赋初值。
obj->capacity表示这个LRU缓存的最大结点个数;
obj->size表示这个LRU缓存的当前结点个数;
obj->head表示这个LRU缓存的双向链表的头结点;
obj->tail表示这个LRU缓存的双向链表的尾结点;
obj->hash表示这个LRU缓存的值到双向链表的结点的映射;
LRUCache* lRUCacheCreate(int capacity)
LRUCache* obj = (LRUCache *)malloc( sizeof(LRUCache) );
obj->capacity = capacity;
obj->size = 0;
obj->head = obj->tail = NULL;
memset(obj->hash, NULL, sizeof(obj->hash));
return obj;
3)值的插入
void put(int key, int value)如果关键字 key已经存在,则变更其数据值 value;如果不存在,则向缓存中插入该组 key-value。如果插入操作导致关键字数量超过 capacity,则应该 逐出 最久未使用的关键字。
我们需要抽象出双向链表的插入操作、删除操作。先来看插入操作。
对于我们需要实现的双向链表来说,插入操作一定是在头结点插入的,因为在执行插入的当下,它一定是一个 “最近使用” 的结点。它的优先级是最高的。
void BiNodeAdd(struct BiNode **head, struct BiNode **tail, struct BiNode *node)
if(*head == NULL)
*head = *tail = node;
else
node->prev = NULL;
node->next = *head;
(*head)->prev = node;
*head = node;
对于我们需要实现的双向链表来说,删除操作可以是任意结点,因为不一定是被元素个数达到上限以后淘汰出去的,也有可能是之前存在结点,调整了位置。那么对于双向链表的删除操作,我们需要考虑目前有 0个结点、1个结点、以及被删除的结点是头结点、是尾结点、以及中间结点。
void BiNodeDel(struct BiNode **head, struct BiNode **tail, struct BiNode *node)
if(*head == NULL)
return ;
else if( *head == *tail )
*head = *tail = NULL;
else
if(*head == node)
*head = node->next;
(*head)->prev = NULL;
else if(*tail == node)
*tail = node->prev;
(*tail)->next = NULL;
else
node->prev->next = node->next;
node->next->prev = node->prev;
node->prev = node->next = NULL;
如何把值塞入这个LRU缓存中呢?如果从哈希表里面找不到这个结点,则执行双向链表的插入操作、更新哈希表、更新size;如果能够找到,则更新val、删除原结点、插入新结点。
最后,需要判断链表的长度是否超过了capacity,如果超过了,移除双向链表的尾结点,并且修改size属性、清理内存。
void lRUCachePut(LRUCache* obj, int key, int value)
struct BiNode *bnode = obj->hash[key];
if(bnode == NULL)
bnode = (struct BiNode *) malloc( sizeof(struct BiNode) );
bnode->key = key;
bnode->val = value;
bnode->prev = bnode->next = NULL;
BiNodeAdd(&obj->head, &obj->tail, bnode);
obj->hash[key] = bnode;
obj->size ++;
else
bnode->val = value;
BiNodeDel(&obj->head, &obj->tail, bnode);
BiNodeAdd(&obj->head, &obj->tail, bnode);
if(obj->size > obj->capacity)
bnode = obj->tail;
BiNodeDel(&obj->head, &obj->tail, bnode);
obj->hash[bnode->key] = NULL;
obj->size --;
free(bnode);
4)值的获取
int get(int key)如果关键字 key存在于缓存中,则返回关键字的值,否则返回 -1。首先,通过哈希表进行查找,如果哈希表里面没有元素,直接返回 -1即可,如果有元素,我们需要执行一次put操作。
为什么要执行一次put操作?原因是因为它改变了 “最近最久未使用” 这个属性,所以相当于它变成了 “最近使用” 的元素。
int lRUCacheGet(LRUCache* obj, int key)
struct BiNode *bn = obj->hash[key];
if(bn == NULL)
return -1;
lRUCachePut(obj, bn->key, bn->val);
return bn->val;
三、本题小知识
对于复杂的问题,要善于拆分每个子问题,对不同的子问题,采用不同的数据结构,并且进行整合梳理,最终确定采用哪种数据结构。

四、加群须知
相信看我文章的大多数都是「 大学生 」,能上大学的都是「 精英 」,那么我们自然要「 精益求精 」,如果你还是「 大一 」,那么太好了,你拥有大把时间,当然你可以选择「 刷剧 」,然而,「 学好算法 」,三年后的你自然「 不能同日而语 」。
那么这里,我整理了「 几十个基础算法 」 的分类,点击开启:
如果链接被屏蔽,或者有权限问题,可以私聊作者解决。

大致题集一览:

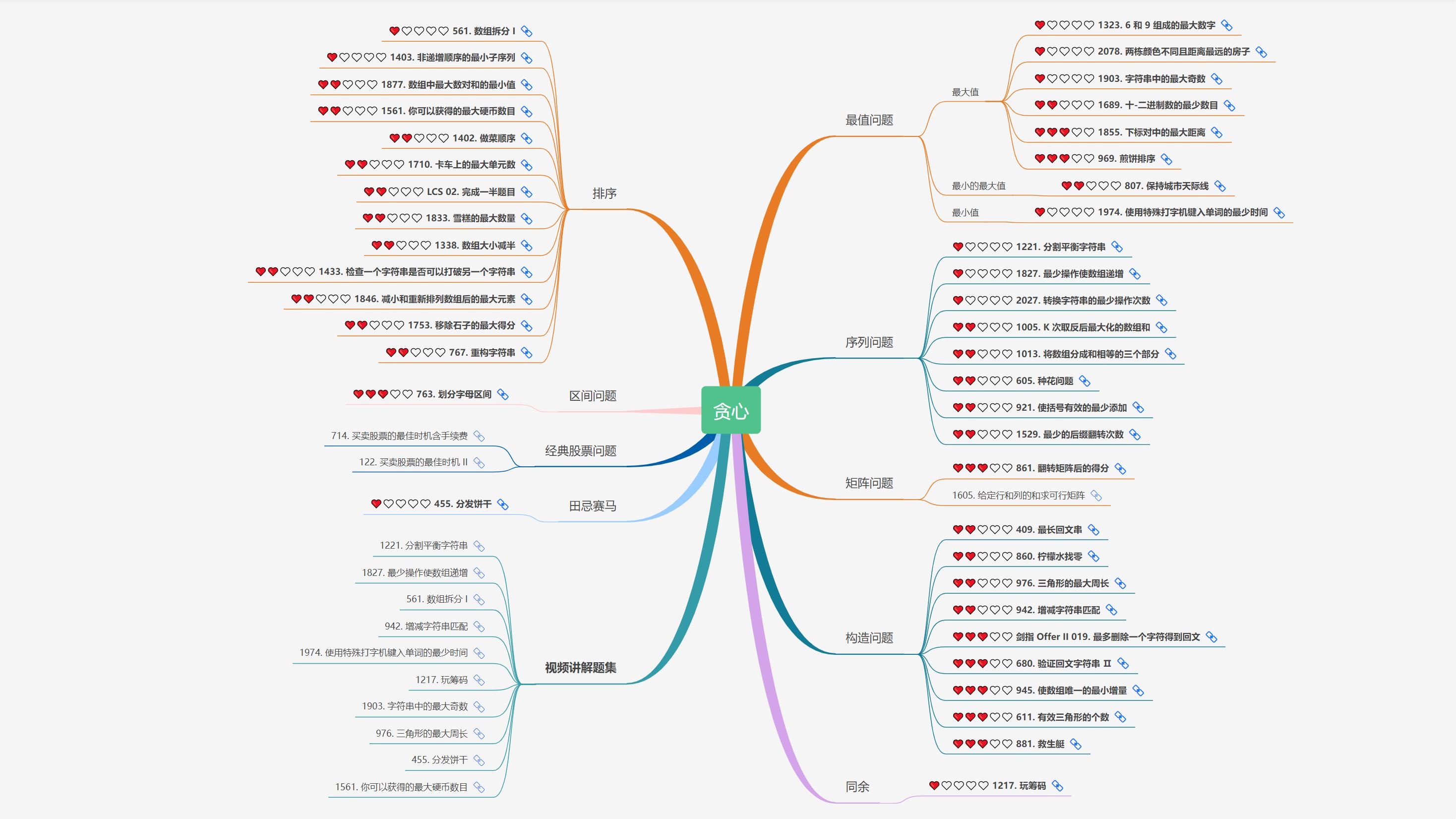
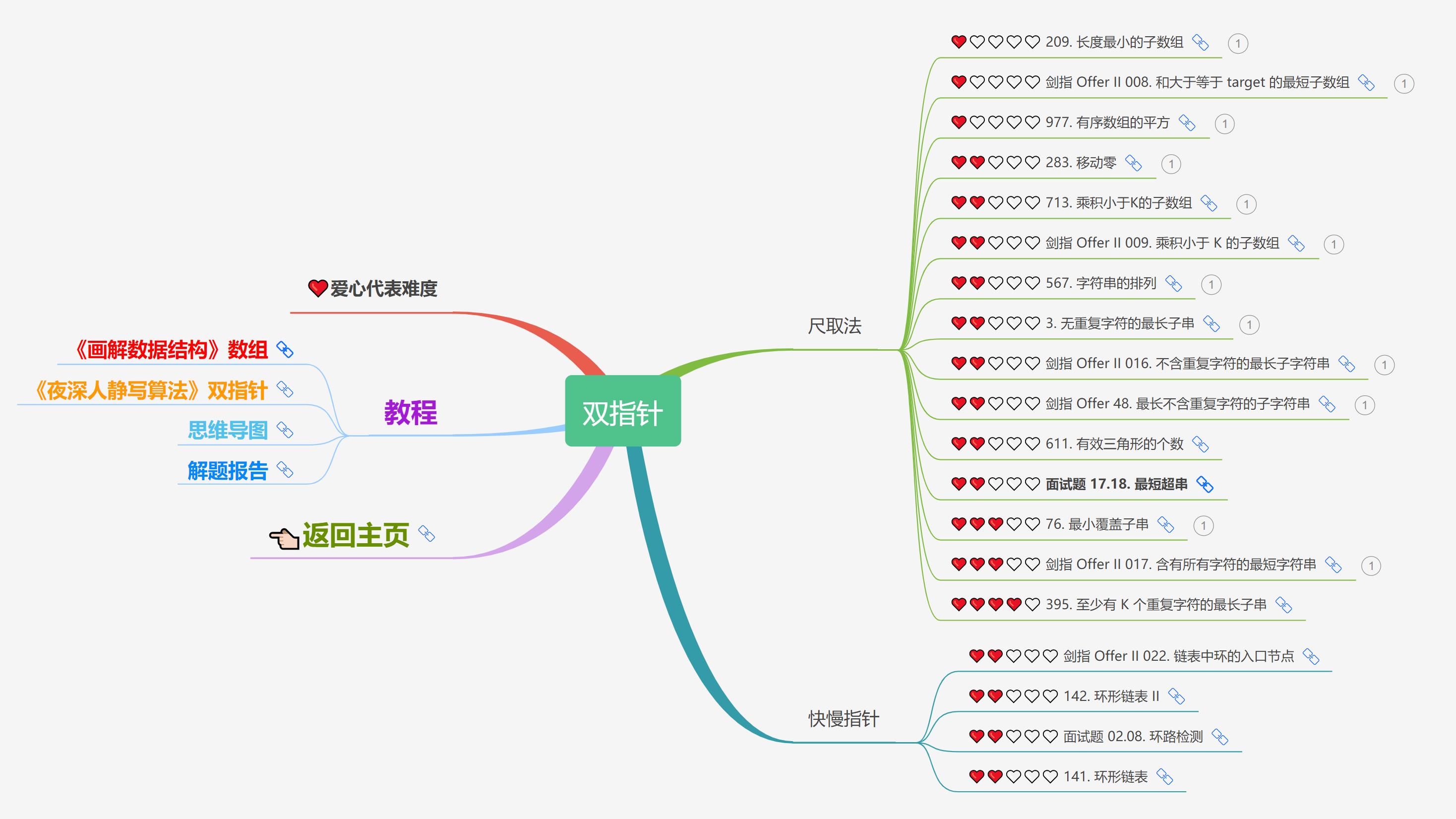

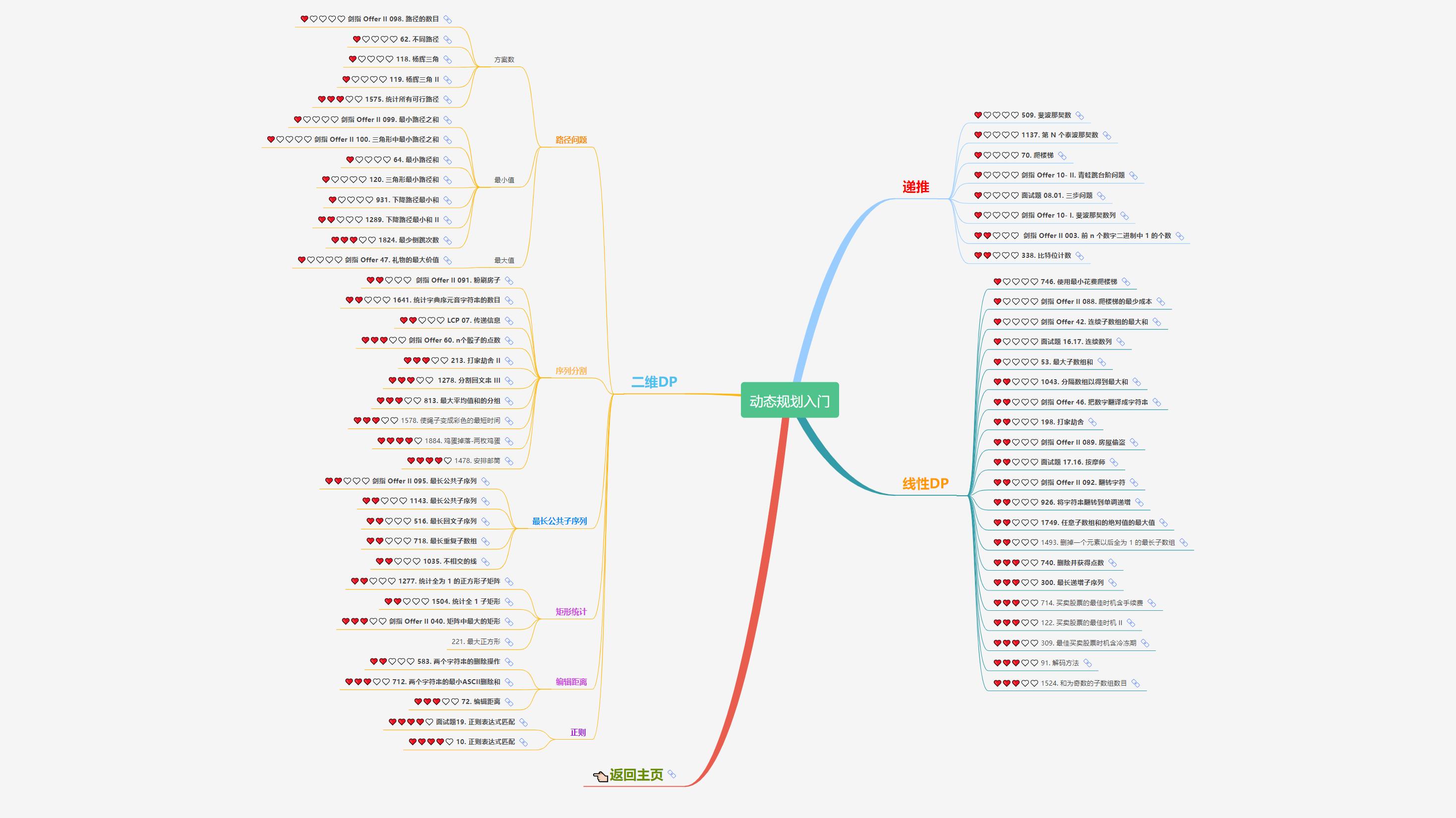
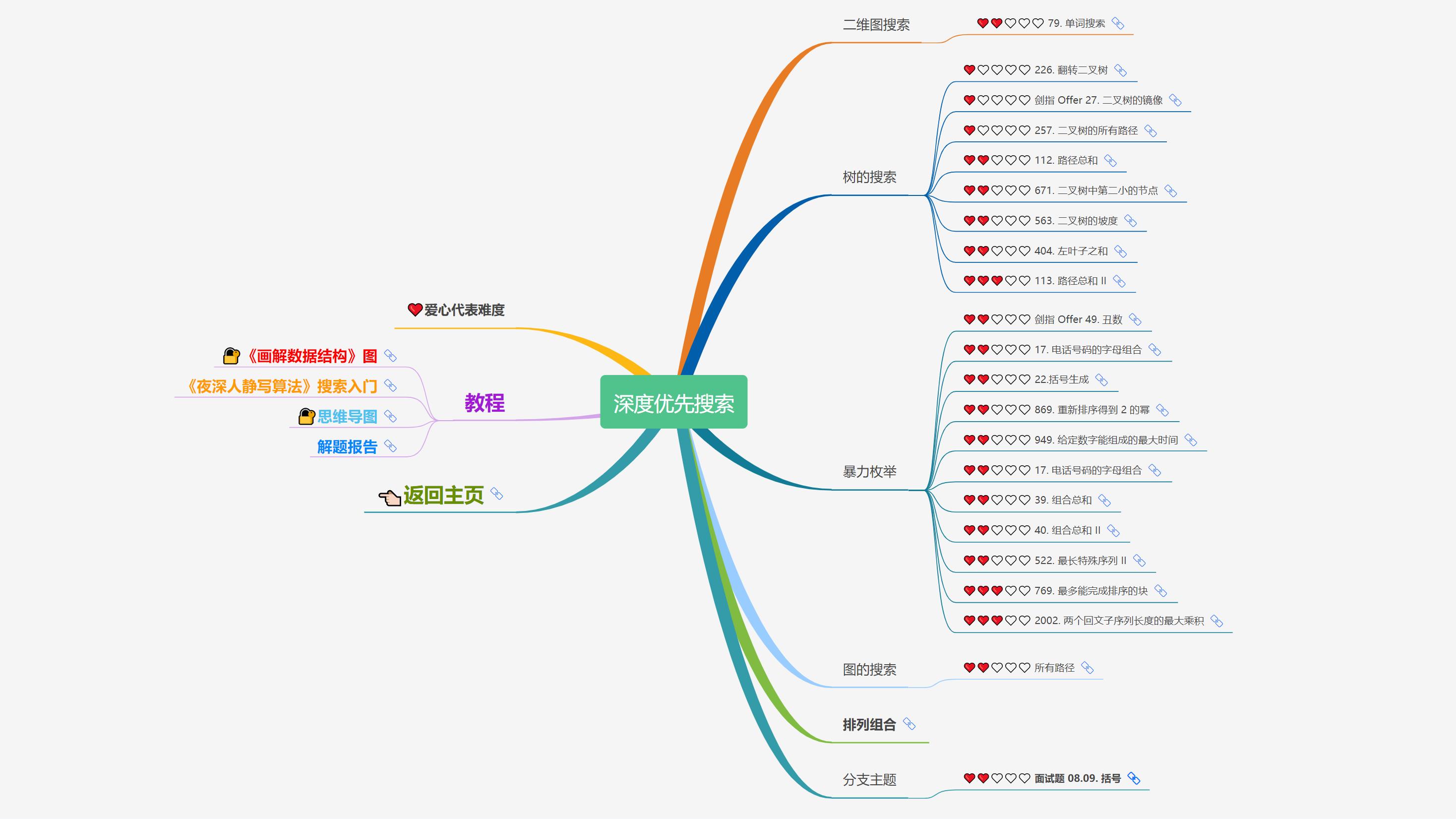






为了让这件事情变得有趣,以及「 照顾初学者 」,目前题目只开放最简单的算法 「 枚举系列 」 (包括:线性枚举、双指针、前缀和、二分枚举、三分枚举),当有 一半成员刷完 「 枚举系列 」 的所有题以后,会开放下个章节,等这套题全部刷完,你还在群里,那么你就会成为「 夜深人静写算法 」专家团 的一员。
不要小看这个专家团,三年之后,你将会是别人 望尘莫及 的存在。如果要加入,可以联系我,考虑到大家都是学生, 没有「 主要经济来源 」,在你成为神的路上,「 不会索取任何 」。
🔥联系作者,或者扫作者主页二维码加群,加入刷题行列吧🔥
🔥让天下没有难学的算法🔥
C语言免费动漫教程,和我一起打卡! 🌞《光天化日学C语言》🌞
让你养成九天持续刷题的习惯 🔥《九日集训》🔥
入门级C语言真题汇总 🧡《C语言入门100例》🧡
组团学习,抱团生长 🌌《算法零基础100讲》🌌
几张动图学会一种数据结构 🌳《画解数据结构》🌳
竞赛选手金典图文教程 💜《夜深人静写算法》💜
以上是关于LeetCode 146. LRU 缓存的主要内容,如果未能解决你的问题,请参考以下文章
[JavaScript 刷题] 链表 - LRU 缓存, leetcode 146