菜鸡读论文Recognizing Spontaneous Micro-Expression Using a Three-Stream Convolutional Neural Network
Posted 猫头丁
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了菜鸡读论文Recognizing Spontaneous Micro-Expression Using a Three-Stream Convolutional Neural Network相关的知识,希望对你有一定的参考价值。
Recognizing Spontaneous Micro-Expression Using a Three-Stream Convolutional Neural Network
大家好呀!
又到了一周一次的《菜鸡读论文》时间啦!先来个酷炫小叮当作为我们的开场,代表我们菜鸡不屈不挠,坚持不懈,不撞南墙心不死,不跳黄河不回头的无畏精神。谁说,菜鸡没有春天,谁说菜鸡看不懂论文!如果说我们看不懂,那一定是论文不够简单!没错!作为菜鸡,我们要反其道而行之,成为读论文界的一股清流。

哈哈,开玩笑哈哈,下一秒,端正态度!昨天我正在和往常一样,开始准备自己今天要讲的两篇论文(没错!笔者现在已经开始了极限看论文的状态,非前一天不看论文)但是没想到!室友竟然在下午三四点就开始和男朋友连麦,谁懂啊!一整个emo住了!心情复杂!
言归正传,让我们来看看今天要读的论文

在本文中,我们提出了一个三流的卷积神经网络(TSCNN)通过学习ME视频的三个关键帧中的ME识别特征来识别MEs。我们设计了一个动态时间流、静态空间流和局部空间流 的模块,分别尝试学习和整合ME视频中的时间和整个面部区域和面部局部区域线索,达到最终识别MEs的目的。此外, 为了使TSCNN在不使用顶点帧的索引值的情况下识别TSCNN,我们设计了一种可靠的顶点帧检测算法。
首先让我们先看一下网络架构,有一个大体的了解,接下来将分别基于顶点帧检测算法和三个不同的输入流进行介绍。
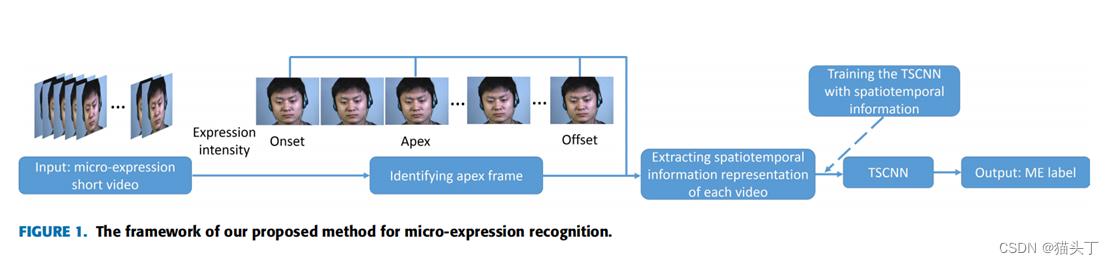
IDENTIFYING APEX FRAME(识别顶点帧)
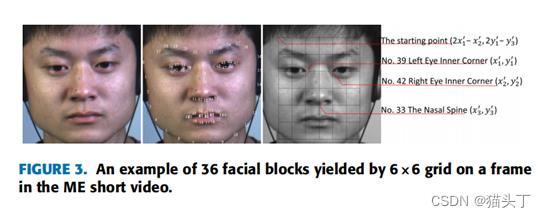
如上图所示,为了消除头部姿势的影响,首先对齐面部区域。使用 an ensemble of regression trees回归树集合(ERT)定位68个面部地标
接下里选取两个内眼角坐标(x1,y1)、(x2,y2)计算旋转矩阵R,公式如下:

面部对齐之后,基于两个内眼角和鼻脊点将面部区域划分为6*6也就是36个块,参照上上图FIGURE3。
对于输入视频的每一帧,我们计算了每帧所对应的36个块中使用P=8和R=3的UP-LBP直方图。这样,每个帧将会对应36个10维的向量。
定义,第i帧和第j帧之间的特征差FD值为:
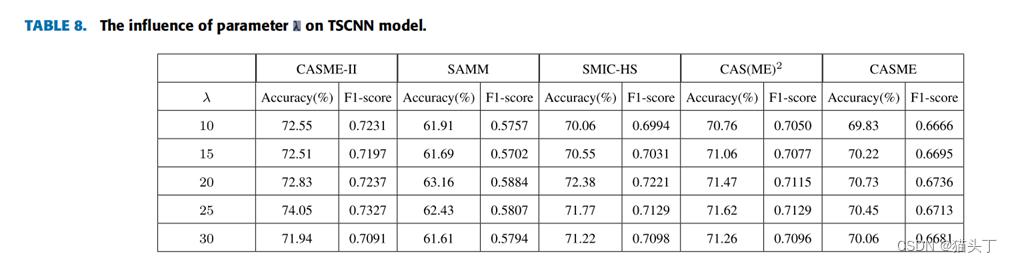
(注意,这里有一个参数λ,作者在实验部分对这个参数的不同取值进行了试验,等会儿可以看到结果)
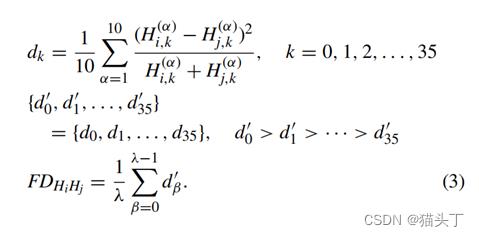
其中,Hi,k和Hj,k的i和j代表第i和第j帧,k代表对帧分块后的第k块的UP-LBP直方图。计算起始帧和偏移帧的平均直方图,与之特征差最大的即为顶点帧。如下图所示:
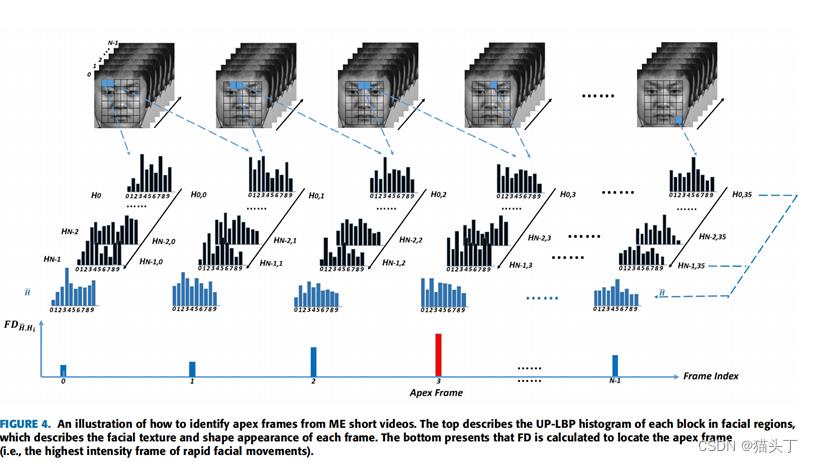
弱弱的说,个人感觉这个图不是那么直观,0~N-1代表的是一个视频序列中的N帧,下面是每个块对应的UP-LBP直方图。
三个不同的输入流
在本文中,我们提出的时空特征包括static-spatial(空间静态)、local-spatial(局部空间)和temporal components(时间成分)
1、STATIC-SPATIAL
将顶点帧中整个人脸的灰度图像作为TSCNN中静态空间识别流的输入,它被裁剪到4848像素、最后,静态空间从面部提取的特征通过全连接层与TSCNN网络其他两个识别流中的另外两个特征向量融合在一起。
2、LOCAL-SPATIAL
使用多种大小的空间网格nn|22,33,44将顶点帧的灰度图像划分为几个面部块,然后叠加得到一个面部块序列作为TSCNN中局部空间流CNN的输入。每个块的大小为4848像素。(作者在实验部分对不同的划分进行了测试,3*3划分的效果最好)
3、TEMPORAL COMPONENTS
起始帧、顶点帧、偏移帧中间的光流,下面我们来具体看一下:
如下图所示,Fonset、Fapex和Foffset分别表示ME视频中的起始帧、顶点帧和偏移帧。通过公式可以得到两组光流场(Fonset和Fapex之间、Fapex和Foffset之间,水平方向和垂直方向)。
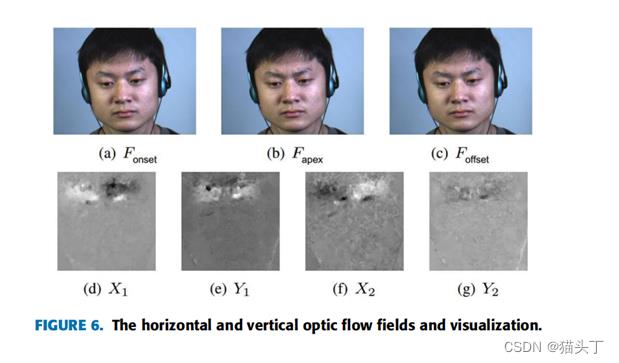

这两组光流场可以完全代表微表情运动从开始到峰值,然后从峰值到终止的过程。
到这里,我们已经看完了三个都不同的输入流都是什么了,让我们看一看整个网络的架构图,来对三个输入有更好的理解。
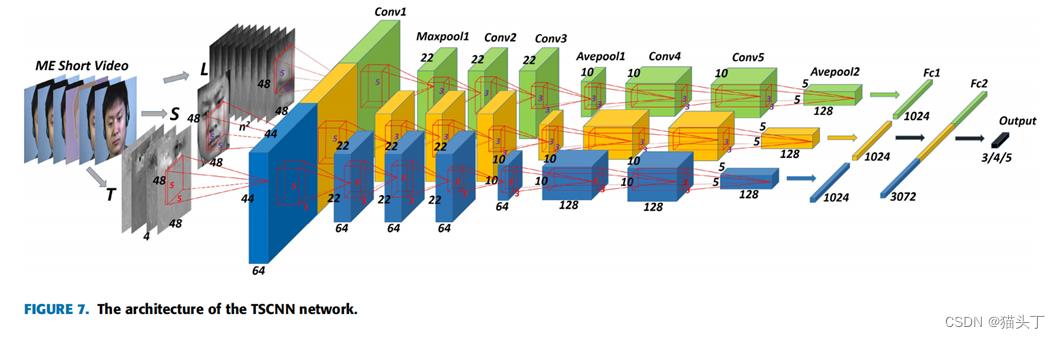 这三个不同的输入分别用三个不同的符号带代表,如图所示,T代表的就是两组光流场大小都是4848,S代表的顶点帧,也是缩放到4848,L代表的是被分割成nn块的顶点帧,每个块的大小都是4848,作者还给出了整个网络的详细参数,让我们一起看一下:
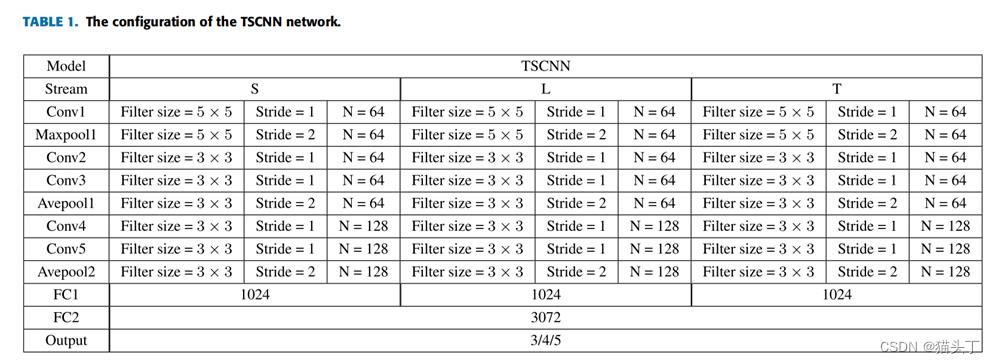
这三个不同的输入分别用三个不同的符号带代表,如图所示,T代表的就是两组光流场大小都是4848,S代表的顶点帧,也是缩放到4848,L代表的是被分割成nn块的顶点帧,每个块的大小都是4848,作者还给出了整个网络的详细参数,让我们一起看一下:
接下来,就是实验部分,因为图太多了,就不全放上来了,大家可以自己去论文上的该部分去看。
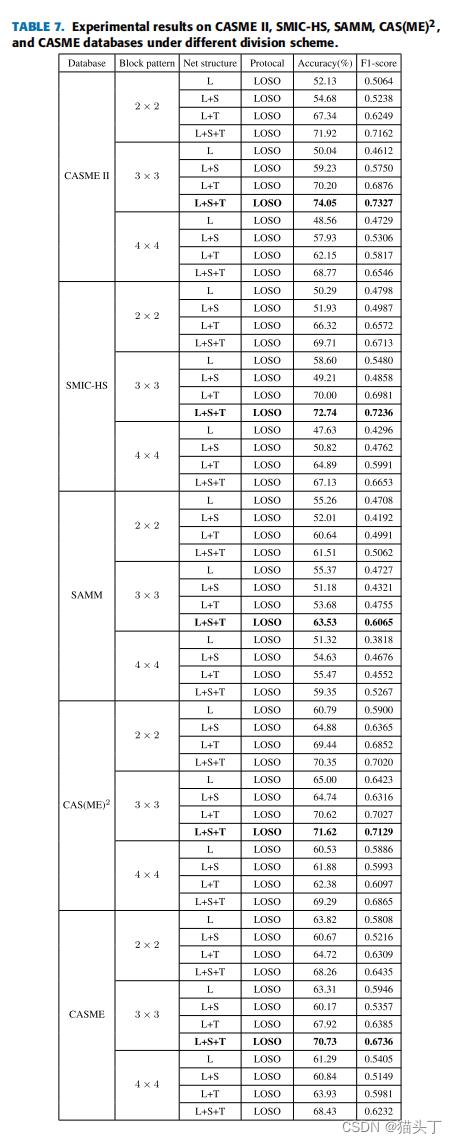
这个是不同块大小切割方式和L、S、T三个模块的使用与否对实验结果的影响。
这个是不同λ的取值,对实验结果的影响
以上是关于菜鸡读论文Recognizing Spontaneous Micro-Expression Using a Three-Stream Convolutional Neural Network的主要内容,如果未能解决你的问题,请参考以下文章
菜鸡读论文Dive into Ambiguity: Latent Distribution Mining and Pairwise Uncertainty Estimation for Facia
菜鸡读论文Face2Exp: Combating Data Biases for Facial Expression Recognition
菜鸡读论文Face2Exp: Combating Data Biases for Facial Expression Recognition
菜鸡读论文AU-assisted Graph Attention Convolutional Network for Micro-Expression Recognition
菜鸡读论文Margin-Mix: Semi-Supervised Learning for Face Expression Recognition
菜鸡读论文Margin-Mix: Semi-Supervised Learning for Face Expression Recognition