[DNA-Seq] bam相关
Posted
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了[DNA-Seq] bam相关相关的知识,希望对你有一定的参考价值。
参考技术A SAM Flag值说明
picard Flag值查询
soft clip and hard clip
需要知道clipping alignment 和split alignment代表什么
关于嵌合体(Chimeric alignment), top显示为soft-clipping,others为hard-clipping, hard-clipping 的出现可以避免信息冗余
0X4 (4) 序列未比对上
0X400 (1024) PCR or optical duplicate
0X100 (256) secondary alignment (除去这个则是唯一比对)
mismatch判断:
XM:i:(\\d+) 即错配碱基数
或者看MD信息:MD:Z:7C22C5^ACCCT46
这篇文章写的非常的清楚duplication的原因 碱基矿工:二代测序的四种Read重复是如何产生的? ,图片也是从里面抠的,按我的理解,简单来说如下:
1、 PCR duplication: 文库构建完成后,经过加A尾,加接头之后,进行PCR扩增导致的;
2、 Cluster duplicates,长Cluster的时候长到旁边去了;
3、 Optical duplicates,捕获荧光出现衍射现象,一个点变成了两个点;
4、 Sister duplicates, 文库的两条互补链同时与flowcell上的引物结合,形成各自的cluster
Total effective bases (Mb) :比对上参考基因组Genome 碱基数之和
Effective sequences on target (Mb) : 比对上Bed区域 碱基数之和
Capture specificity by reads (%) :捕获效率(比对上Expanding BED区域的reads数 / 比对上参考基因组的Reads数)
Mapping rate on genome (%) :比对率(比对上参考基因组的Reads数/Bam文件总Reads数) *** 感觉这里不是很准,因为有的chimeric比对上两次,显示了两次***
Unique Hit Rate (%) :唯一比对率,即比对上参考基因组的唯一比对reads数(-F 256)/ 比对上参考基因组的reads数
Duplicate rate on genome (%) : dup 的reads数(0x400) /比对上参考基因组的Reads数
Mismatch rate in target region (%) :比对上Expanding BED区域的Mismatch的碱基数 / 比对上Bed区域 碱基数之和(即之前的Effective sequences on target)
Average sequencing depth on target :平均测序深度,即比对上Bed区域 碱基数之和/BED 区域总碱基数
Fraction of target covered >= 1x (%) :BED区域depth超过1的碱基数/ BED 区域总碱基数
Fraction of target covered >= 4x (%) : 同上。。。
用法:
参考: samtools idxstats
用法:
使用plot-bamstats的时候遇到的报错:
重新用conda 安装了一遍samtools和gnuplot,安装的gnuplot版本为gnuplot 5.2 patchlevel 7,结果遇到了下面这个报错:
参考: plot-bamstats
参考资料: 肿瘤全外显子测序数据分析流程
命令:
结果里面会有一个Report.pdf,包括所有mapping ratio,Insert size,mean coverage及chromsome stats统计结果,和一些展示图片。
相关结果中包括Target区域和Flank区域的统计,还是很全的,没有作图但是有相关的表格出来,可以自己作图。具体说明推荐看这篇: :bamdst
但是bamdst官网有这么一段,感觉对WGS分析不是太友好:
几款计算测序深度和覆盖度的软件或模块
一直没有把gtf文件导入,发现导入gtf也是要先sort再建index,有个参考资料:
IGV导入注释文件
建立index的时候出现java报错,可以去看看除了igvtools,有没有其他的方法建立index
还有生信100问的参考资料:
生物信息学100个基础问题 —— 第29题 如何使用IGVTools对mapping结果进行可视化?
之前的方案使用到awk,觉得太慢了;又搜索了一下发现samtools fastq 能将bam文件中的序列提取为fastq,但是后续分析有遇到因为pair不正确发生报错,原因可能是由于fq1和fq2没有按序列顺序配对导致,查询了一下解决方法,可以参考这个记录:
如何从BAM文件中提取fastq
但是觉得samtools的方法还是有点慢,继而发现了一款软件seqkit,最终解决方案如下:
-j 线程
-v 反向选择
-f id文件
认识Panda3D引擎bam相关命令
看一下Panda自带命令,其中有bam相关的,来了解一下;
输入一个命令看一下,提示需要输入一个bam文件名;

查一下,查到一个介绍一种bam文件的资料如下,
SAM (Sequence Alignment/Map) 格式是一种通用的比对格式,用来存储reads到参考序列的比对信息。
SAM是sanger制定,是以TAB为分割符的文本格式。主要应用于测序序列mapping到基因组上的结果表示,当然也可以表示任意的多重比对结果。
BAM文件
通过BGZF格式压缩后的SAM文件,一种二进制文件,可以直接理解为对SAM文件的压缩。
BAM文件无法直接用less、cat、head、tail等常规命令打开,可用samtools -view sample.bam命令打开
上面命令需要的bam文件是否是这个?
资料说,
Bam文件的head部分以"@"开头的行,包含有"@HD"、"@SQ"、"@RG"、"@PG" 等。
@HD行表示整个文件信息,VN表示格式版本,SO表示排序信息,支持queryname、coordinate、unknown、unsorted。
@SQ行记录了参考序列的信息,一般三列,分别是@SQ、RNAME、Sequence_length。
@RG记录了样本名,测序平台等信息,内容与bwa生成bam文件时的-R参数后更的内容一致。
用记事本打开一个bam文件,
再用十六进制编辑器打开看看,

Panda的bam-info命令是查看bam文件信息;看一下,
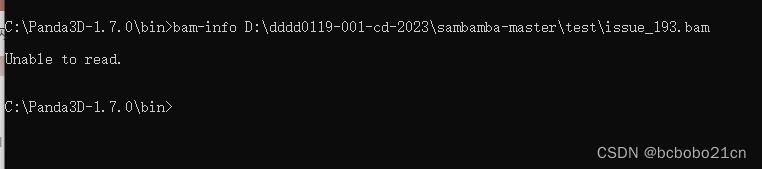
不能读上面的示例bam文件;
Panda还有一个命令是转换egg文件为bam文件,egg是panda自身的模型文件格式,可以和3dmax和maya等相互转换,
egg2bam -ps rel -o bamFileName.bam eggFileName.egg
那么这里的bam也应是一种3d模型文件,并非前面的示例bam文件;
查一下资料,常见3d模型文件格式里面没有bam;
看一下panda手册;
Converting Egg to Bam
Panda’s native egg file format is human-readable. This is convenient, but the files can get very large, and they can a little bit slow to load. To accelerate loading, Panda supports a second native format, bam. These files are smaller and are loaded very rapidly, but they cannot be viewed or edited in a text editor. Also, bam files are specific to the version of Panda they are created with, so they are not a good choice for long-term storage of your models.
转换Egg到Bam
Panda自己的egg文件格式是可读的。这是方便的,但是文件可能比较大,加载会有延迟。为了加速加载,Panda支持第二种格式,bam。
native format,应翻译为自带格式,bam是Panda3d引擎自带的第二种格式,第一种是egg。
bam是panda自带的二种模型文件格式之一;如果egg格式加载慢,可转换为bam格式;
操作一下看一下,
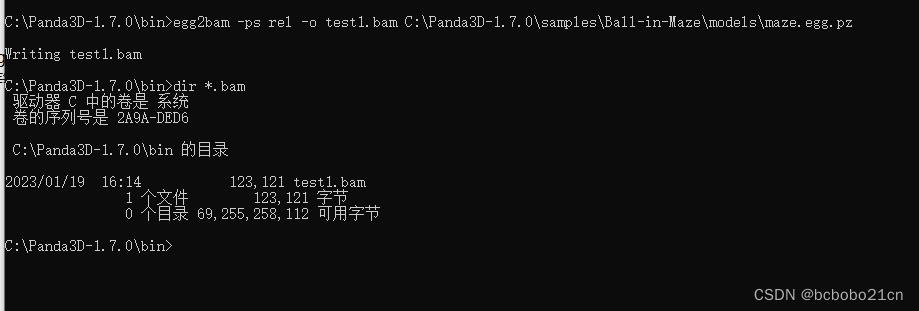
出来一个bam文件;
以上是关于[DNA-Seq] bam相关的主要内容,如果未能解决你的问题,请参考以下文章