Spark Streaming源码解读之Receiver在Driver详解
Posted snail_gesture
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Spark Streaming源码解读之Receiver在Driver详解相关的知识,希望对你有一定的参考价值。
一:Receiver启动的方式设想
1. Spark Streaming通过Receiver持续不断的从外部数据源接收数据,并把数据汇报给Driver端,由此每个Batch Durations就可以根据汇报的数据生成不同的Job。
2. Receiver属于Spark Streaming应用程序启动阶段,那么我们找Receiver在哪里启动就应该去找Spark Streaming的启动。
3. Receivers和InputDStreams是一一对应的,默认情况下一般只有一个Receiver.
如何启动Receiver?
1. 从Spark Core的角度来看,Receiver的启动Spark Core并不知道,就相当于Linux的内核之上所有的都是应用程序,因此Receiver是通过Job的方式启动的。
2. 一般情况下,只有一个Receiver,但是可以创建不同的数据来源的InputDStream.
final private[streaming] class DStreamGraph extends Serializable with Logging
private val inputStreams = new ArrayBuffer[InputDStream[_]]()
private val outputStreams = new ArrayBuffer[DStream[_]]()
3. 启动Receiver的时候,启动一个Job,这个Job里面有RDD的transformations操作和action的操作,这个Job只有一个partition.这个partition的特殊是里面只有一个成员,这个成员就是启动的Receiver.
4. 这样做的问题:
a) 如果有多个InputDStream,那就要启动多个Receiver,每个Receiver也就相当于分片partition,那我们启动Receiver的时候理想的情况下是在不同的机器上启动Receiver,但是Spark Core的角度来看就是应用程序,感觉不到Receiver的特殊性,所以就会按照正常的Job启动的方式来处理,极有可能在一个Executor上启动多个Receiver.这样的话就可能导致负载不均衡。
b) 有可能启动Receiver失败,只要集群存在Receiver就不应该失败。
c) 运行过程中,就默认的而言如果是一个partition的话,那启动的时候就是一个Task,但是此Task也很可能失败,因此以Task启动的Receiver也会挂掉。
由此,可以得出,对于Receiver失败的话,后果是非常严重的,那么Spark Streaming如何防止这些事的呢,下面就寻找Receiver的创建。
这里先给出答案,后面源码会详细分析:
a) Spark使用一个Job启动一个Receiver.最大程度的保证了负载均衡。
b) Spark Streaming指定每个Receiver运行在那些Executor上。
c) 如果Receiver启动失败,此时并不是Job失败,在内部会重新启动Receiver.
- 在StreamingContext的start方法被调用的时候,JobScheduler的start方法会被调用。
/**
* Start the execution of the streams.
*
* @throws IllegalStateException if the StreamingContext is already stopped.
*/
def start(): Unit = synchronized
state match
case INITIALIZED =>
startSite.set(DStream.getCreationSite())
StreamingContext.ACTIVATION_LOCK.synchronized
StreamingContext.assertNoOtherContextIsActive()
try
validate()
// Start the streaming scheduler in a new thread, so that thread local properties
// like call sites and job groups can be reset without affecting those of the
// current thread.
ThreadUtils.runInNewThread("streaming-start")
sparkContext.setCallSite(startSite.get)
sparkContext.clearJobGroup()
sparkContext.setLocalProperty(SparkContext.SPARK_JOB_INTERRUPT_ON_CANCEL, "false")
//启动子线程,一方面为了本地初始化工作,另外一方面是不要阻塞主线程。
scheduler.start()
state = StreamingContextState.ACTIVE
catch
case NonFatal(e) =>
logError("Error starting the context, marking it as stopped", e)
scheduler.stop(false)
state = StreamingContextState.STOPPED
throw e
StreamingContext.setActiveContext(this)
shutdownHookRef = ShutdownHookManager.addShutdownHook(
StreamingContext.SHUTDOWN_HOOK_PRIORITY)(stopOnShutdown)
// Registering Streaming Metrics at the start of the StreamingContext
assert(env.metricsSystem != null)
env.metricsSystem.registerSource(streamingSource)
uiTab.foreach(_.attach())
logInfo("StreamingContext started")
case ACTIVE =>
logWarning("StreamingContext has already been started")
case STOPPED =>
throw new IllegalStateException("StreamingContext has already been stopped")
2. 而在JobScheduler的start方法中ReceiverTracker的start方法被调用,Receiver就启动了。
def start(): Unit = synchronized
if (eventLoop != null) return // scheduler has already been started
logDebug("Starting JobScheduler")
eventLoop = new EventLoop[JobSchedulerEvent]("JobScheduler")
override protected def onReceive(event: JobSchedulerEvent): Unit = processEvent(event)
override protected def onError(e: Throwable): Unit = reportError("Error in job scheduler", e)
eventLoop.start()
// attach rate controllers of input streams to receive batch completion updates
for
inputDStream <- ssc.graph.getInputStreams
rateController <- inputDStream.rateController
ssc.addStreamingListener(rateController)
listenerBus.start(ssc.sparkContext)
receiverTracker = new ReceiverTracker(ssc)
inputInfoTracker = new InputInfoTracker(ssc)
//启动receiverTracker
receiverTracker.start()
jobGenerator.start()
logInfo("Started JobScheduler")
3. ReceiverTracker的start方法启动RPC消息通信体,为啥呢?因为receiverTracker会监控整个集群中的Receiver,Receiver转过来要向ReceiverTrackerEndpoint汇报自己的状态,接收的数据,包括生命周期等信息
/** Start the endpoint and receiver execution thread. */
def start(): Unit = synchronized
if (isTrackerStarted)
throw new SparkException("ReceiverTracker already started")
//Receiver的启动是依据输入数据流的。
if (!receiverInputStreams.isEmpty)
endpoint = ssc.env.rpcEnv.setupEndpoint(
"ReceiverTracker", new ReceiverTrackerEndpoint(ssc.env.rpcEnv))
if (!skipReceiverLaunch) launchReceivers()
logInfo("ReceiverTracker started")
trackerState = Started
4. 基于ReceiverInputDStream(是在Driver端)来获得具体的Receivers实例,然后再把他们分不到Worker节点上。一个ReceiverInputDStream只产生一个Receiver
/**
* Get the receivers from the ReceiverInputDStreams, distributes them to the
* worker nodes as a parallel collection, and runs them.
*/
private def launchReceivers(): Unit =
val receivers = receiverInputStreams.map(nis =>
//一个数据输入来源(receiverInputDStream)只产生一个Receiver
val rcvr = nis.getReceiver()
rcvr.setReceiverId(nis.id)
rcvr
)
runDummySparkJob()
logInfo("Starting " + receivers.length + " receivers")
//此时的endpoint就是上面代码中在ReceiverTracker的start方法中构造的ReceiverTrackerEndpoint
endpoint.send(StartAllReceivers(receivers))
5. 其中runDummySparkJob()为了确保所有节点活着,而且避免所有的receivers集中在一个节点上。
/**
* Run the dummy Spark job to ensure that all slaves have registered. This avoids all the
* receivers to be scheduled on the same node.
*
* TODO Should poll the executor number and wait for executors according to
* "spark.scheduler.minRegisteredResourcesRatio" and
* "spark.scheduler.maxRegisteredResourcesWaitingTime" rather than running a dummy job.
*/
private def runDummySparkJob(): Unit =
if (!ssc.sparkContext.isLocal)
ssc.sparkContext.makeRDD(1 to 50, 50).map(x => (x, 1)).reduceByKey(_ + _, 20).collect()
assert(getExecutors.nonEmpty)
- ReceiverInputDStream中的getReceiver()方法获得receiver对象然后将它发送到worker节点上实例化receiver,然后去接收数据。
此方法必须要在子类中实现。
/**
* Gets the receiver object that will be sent to the worker nodes
* to receive data. This method needs to defined by any specific implementation
* of a ReceiverInputDStream.
*/
def getReceiver(): Receiver[T] //返回的是Receiver对象
7. 根据继承关系,这里看一下SocketInputDStream中的getReceiver方法。
def getReceiver(): Receiver[T] =
new SocketReceiver(host, port, bytesToObjects, storageLevel)
启动后台线程,调用receive方法。
private[streaming]
class SocketReceiver[T: ClassTag](
host: String,
port: Int,
bytesToObjects: InputStream => Iterator[T],
storageLevel: StorageLevel
) extends Receiver[T](storageLevel) with Logging
def onStart()
// Start the thread that receives data over a connection
new Thread("Socket Receiver")
setDaemon(true)
override def run() receive()
.start()
启动socket开始接收数据。
/** Create a socket connection and receive data until receiver is stopped */
def receive()
var socket: Socket = null
try
logInfo("Connecting to " + host + ":" + port)
socket = new Socket(host, port)
logInfo("Connected to " + host + ":" + port)
val iterator = bytesToObjects(socket.getInputStream())
while(!isStopped && iterator.hasNext)
store(iterator.next)
if (!isStopped())
restart("Socket data stream had no more data")
else
logInfo("Stopped receiving")
catch
case e: java.net.ConnectException =>
restart("Error connecting to " + host + ":" + port, e)
case NonFatal(e) =>
logWarning("Error receiving data", e)
restart("Error receiving data", e)
finally
if (socket != null)
socket.close()
logInfo("Closed socket to " + host + ":" + port)
8. ReceiverTrackerEndpoint源码如下:
/** RpcEndpoint to receive messages from the receivers. */
private class ReceiverTrackerEndpoint(override val rpcEnv: RpcEnv) extends ThreadSafeRpcEndpoint
// TODO Remove this thread pool after https://github.com/apache/spark/issues/7385 is merged
private val submitJobThreadPool = ExecutionContext.fromExecutorService(
ThreadUtils.newDaemonCachedThreadPool("submit-job-thread-pool"))
private val walBatchingThreadPool = ExecutionContext.fromExecutorService(
ThreadUtils.newDaemonCachedThreadPool("wal-batching-thread-pool"))
@volatile private var active: Boolean = true
override def receive: PartialFunction[Any, Unit] =
// Local messages
case StartAllReceivers(receivers) =>
val scheduledLocations =
// schedulingPolicy调度策略
//receivers就是要启动的receiver
//getExecutors获得集群中的Executors的列表
// scheduleReceivers就可以确定receiver可以运行在哪些Executor上
schedulingPolicy.scheduleReceivers(receivers, getExecutors)
for (receiver <- receivers)
// scheduledLocations根据receiver的Id就找到了当前那些Executors可以运行Receiver
val executors = scheduledLocations(receiver.streamId)
updateReceiverScheduledExecutors(receiver.streamId, executors)
receiverPreferredLocations(receiver.streamId) = receiver.preferredLocation
//上述代码之后要启动的Receiver确定了,具体Receiver运行在哪些Executors上也确定了。
//循环receivers,每次将一个receiver传入过去。
startReceiver(receiver, executors)
//用于接收RestartReceiver消息,从新启动Receiver.
case RestartReceiver(receiver) =>
// Old scheduled executors minus the ones that are not active any more
//如果Receiver失败的话,从可选列表中减去。
val oldScheduledExecutors =
//刚在调度为Receiver分配给哪个Executor的时候会有一些列可选的Executor列表
getStoredScheduledExecutors(receiver.streamId)
//从新获取Executors
val scheduledLocations = if (oldScheduledExecutors.nonEmpty)
// Try global scheduling again
oldScheduledExecutors
else
//如果可选的Executor使用完了,则会重新执行rescheduleReceiver重新获取Executor.
val oldReceiverInfo = receiverTrackingInfos(receiver.streamId)
// Clear "scheduledLocations" to indicate we are going to do local scheduling
val newReceiverInfo = oldReceiverInfo.copy(
state = ReceiverState.INACTIVE, scheduledLocations = None)
receiverTrackingInfos(receiver.streamId) = newReceiverInfo
schedulingPolicy.rescheduleReceiver(
receiver.streamId,
receiver.preferredLocation,
receiverTrackingInfos,
getExecutors)
// Assume there is one receiver restarting at one time, so we don't need to update
// receiverTrackingInfos
//重复调用startReceiver
startReceiver(receiver, scheduledLocations)
case c: CleanupOldBlocks =>
receiverTrackingInfos.values.flatMap(_.endpoint).foreach(_.send(c))
case UpdateReceiverRateLimit(streamUID, newRate) =>
for (info <- receiverTrackingInfos.get(streamUID); eP <- info.endpoint)
eP.send(UpdateRateLimit(newRate))
// Remote messages
case ReportError(streamId, message, error) =>
reportError(streamId, message, error)
9. 从注释中可以看到,Spark Streaming指定receiver在那些Executors运行,而不是基于Spark Core中的Task来指定。
Spark使用submit Job的方式启动Receiver,而在应用程序执行的时候会有很多Receiver,这个时候是启动一个Receiver呢,还是把所有的Receiver通过这一个Job启动?
在ReceiverTracker的receive方法中startReceiver方法第一个参数就是receiver,从实现的可以看出for循环不断取出receiver,然后调用startReceiver。由此就可以得出一个Job只启动一个Receiver.
如果Receiver启动失败,此时并不会认为是作业失败,会重新发消息给ReceiverTrackerEndpoint重新启动Receiver,这样也就确保了Receivers一定会被启动,这样就不会像Task启动Receiver的话如果失败受重试次数的影响。
/**
* Start a receiver along with its scheduled executors
*/
private def startReceiver(
receiver: Receiver[_],
// scheduledLocations指定的是在具体的那台物理机器上执行。
scheduledLocations: Seq[TaskLocation]): Unit =
//判断下Receiver的状态是否正常。
def shouldStartReceiver: Boolean =
// It's okay to start when trackerState is Initialized or Started
!(isTrackerStopping || isTrackerStopped)
val receiverId = receiver.streamId
//如果不需要启动Receiver则会调用onReceiverJobFinish()
if (!shouldStartReceiver)
onReceiverJobFinish(receiverId)
return
val checkpointDirOption = Option(ssc.checkpointDir)
val serializableHadoopConf =
new SerializableConfiguration(ssc.sparkContext.hadoopConfiguration)
//startReceiverFunc封装了在worker上启动receiver的动作。
// Function to start the receiver on the worker node
val startReceiverFunc: Iterator[Receiver[_]] => Unit =
(iterator: Iterator[Receiver[_]]) =>
if (!iterator.hasNext)
throw new SparkException(
"Could not start receiver as object not found.")
if (TaskContext.get().attemptNumber() == 0)
val receiver = iterator.next()
assert(iterator.hasNext == false)
// ReceiverSupervisorImpl是Receiver的监控器,同时负责数据的写等操作。
val supervisor = new ReceiverSupervisorImpl(
receiver, SparkEnv.get, serializableHadoopConf.value, checkpointDirOption)
supervisor.start()
supervisor.awaitTermination()
else
//如果你想重新启动receiver的话,你需要重新完成上面的调度,从新schedule,而不是Task重试。
// It's restarted by TaskScheduler, but we want to reschedule it again. So exit it.
// Create the RDD using the scheduledLocations to run the receiver in a Spark job
val receiverRDD: RDD[Receiver[_]] =
if (scheduledLocations.isEmpty)
ssc.sc.makeRDD(Seq(receiver), 1)
else
val preferredLocations = scheduledLocations.map(_.toString).distinct
ssc.sc.makeRDD(Seq(receiver -> preferredLocations))
//receiverId可以看出,receiver只有一个
receiverRDD.setName(s"Receiver $receiverId")
ssc.sparkContext.setJobDescription(s"Streaming job running receiver $receiverId")
ssc.sparkContext.setCallSite(Option(ssc.getStartSite()).getOrElse(Utils.getCallSite()))
//每个Receiver的启动都会触发一个Job,而不是一个作业的Task去启动所有的Receiver.
//应用程序一般会有很多Receiver,
//调用SparkContext的submitJob,为了启动Receiver,启动了Spark一个作业.
val future = ssc.sparkContext.submitJob[Receiver[_], Unit, Unit](
receiverRDD, startReceiverFunc, Seq(0), (_, _) => Unit, ())
// We will keep restarting the receiver job until ReceiverTracker is stopped
future.onComplete
case Success(_) =>
// shouldStartReceiver默认是true
if (!shouldStartReceiver)
onReceiverJobFinish(receiverId)
else
logInfo(s"Restarting Receiver $receiverId")
self.send(RestartReceiver(receiver))
case Failure(e) =>
if (!shouldStartReceiver)
onReceiverJobFinish(receiverId)
else
logError("Receiver has been stopped. Try to restart it.", e)
logInfo(s"Restarting Receiver $receiverId")
//RestartReceiver
self.send(RestartReceiver(receiver))
//使用线程池的方式提交Job,这样的好处是可以并发的启动Receiver。
(submitJobThreadPool)
logInfo(s"Receiver $receiver.streamId started")
10. 当Receiver启动失败的话,就会调用ReceiverTrackEndpoint重新启动一个Spark Job去启动Receiver.
/**
* This message will trigger ReceiverTrackerEndpoint to restart a Spark job for the receiver.
*/
private[streaming] case class RestartReceiver(receiver: Receiver[_])
extends ReceiverTrackerLocalMessage
11. 当Receiver关闭的话,并不需要重新启动Spark Job.
/**
* Call when a receiver is terminated. It means we won't restart its Spark job.
*/
private def onReceiverJobFinish(receiverId: Int): Unit =
receiverJobExitLatch.countDown()
//使用foreach将receiver从receiverTrackingInfo中去掉。
receiverTrackingInfos.remove(receiverId).foreach receiverTrackingInfo =>
if (receiverTrackingInfo.state == ReceiverState.ACTIVE)
logWarning(s"Receiver $receiverId exited but didn't deregister")
12. Supervisor.start(),在子类ReceiverSupervisorImpl中并没有start方法,因此调用的是父类ReceiverSupervisor的start方法。
/** Start the supervisor */
def start()
onStart() //具体实现是子类实现的。
startReceiver()
Onstart方法源码如下:
/**
* Called when supervisor is started.
* Note that this must be called before the receiver.onStart() is called to ensure
* things like [[BlockGenerator]]s are started before the receiver starts sending data.
*/
protected def onStart()
其具体实现是在子类的ReceiverSupervivorImpl的onstart方法
override protected def onStart()
registeredBlockGenerators.foreach _.start()
此时的start方法调用的是BlockGenerator的start方法。
/** Start block generating and pushing threads. */
def start(): Unit = synchronized
if (state == Initialized)
state = Active
blockIntervalTimer.start()
blockPushingThread.start()
logInfo("Started BlockGenerator")
else
throw new SparkException(
s"Cannot start BlockGenerator as its not in the Initialized state [state = $state]")
Receiver启动全生命周期总流程图如下:
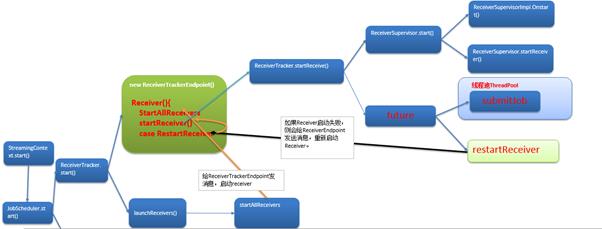
以上是关于Spark Streaming源码解读之Receiver在Driver详解的主要内容,如果未能解决你的问题,请参考以下文章
Spark发行版笔记13:Spark Streaming源码解读之Driver容错安全性
(版本定制)第14课:Spark Streaming源码解读之State管理之updateStateByKey和mapWithState解密
Spark Streaming源码解读之Executor容错安全性
Spark 定制版:008~Spark Streaming源码解读之RDD生成全生命周期彻底研究和思考