各领域公开数据集简介及下载使用方式
Posted 夏小悠
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了各领域公开数据集简介及下载使用方式相关的知识,希望对你有一定的参考价值。
文章目录
本篇博客主要介绍各领域常用的数据集及下载使用方式。
1. ImageNet

ImageNet是深度学习视觉方面最经典的一个数据集,由斯坦福大学教授李飞飞为了解决机器学习中过拟合和泛化的问题而牵头构建的数据集。该数据集从2007年开始手机建立,直到2009年作为论文的形式在CVPR 2009上面发布。
ImageNet Large-Scale Visual Recognition Challenge(ILSVRC)就是基于ImageNet数据集举行的比赛,从2010年开始举行,每年一届,直至2017年最后一届结束,在此期间诞生了AlexNet(2012)、VGG(2014)、GoogLeNet(2014)、ResNet(2015)等经典的深度学习网络模型。我们常说的ImageNet一般是ILSVRC2012的这个子集。
ILSVRC2012数据集拥有1000个分类,每个分类约有1000张图片,其中训练集约为120万(1281167),验证集5万,测试集10万(没有标签)。
适用任务:图像分类、检测、定位。
训练集:ILSVRC2012_img_train.tar中包含120多万张自然图像,大概有150G,其中含有1000个类别的压缩包,分别对应1000个类别,每个压缩包解压之后都可以得到对应的类别照片。
验证集:ILSVRC2012_img_val.tar中含有50000张图片,解压之后是直接是图像,并没有按照类别区分开。因此需要处理成同训练集相同的格式,即验证集也要生成1000个文件夹,将相应的图片移动到所属的类别(文件夹)中。
图片格式都是
.JPEG
可以直接执行valprep.sh脚本来处理验证集,使其文件目录格式同训练集保持一致。
.
├── train
│ │
│ ├── n01440764
│ │ └── *.JPEG
│ ├── n01443537
│ │
│ ├── ...
│ │
│ └── n15075141
└── val
│
├── n01440764
│ └── *.JPEG
├── n01443537
│
├── ...
│
└── n15075141
2. ADE20k

3. PASCAL VOC
适用任务:Object Classification 、Object Detection、Object Segmentation、Human Layout、Action Classification
数据类别:person, bird, cat, cow, dog, horse, sheep, aeroplane, bicycle, boat, bus, car, motorbike, train, bottle, chair, dining table, potted plant, sofa, tv/monitor,共20类
数据量:VOC2007(Train/validation/test):9963张图片, 24640个标注的对象;VOC2012(Train/validation):11530张图片, 27450个标注的对象,6929个注释的分割对象
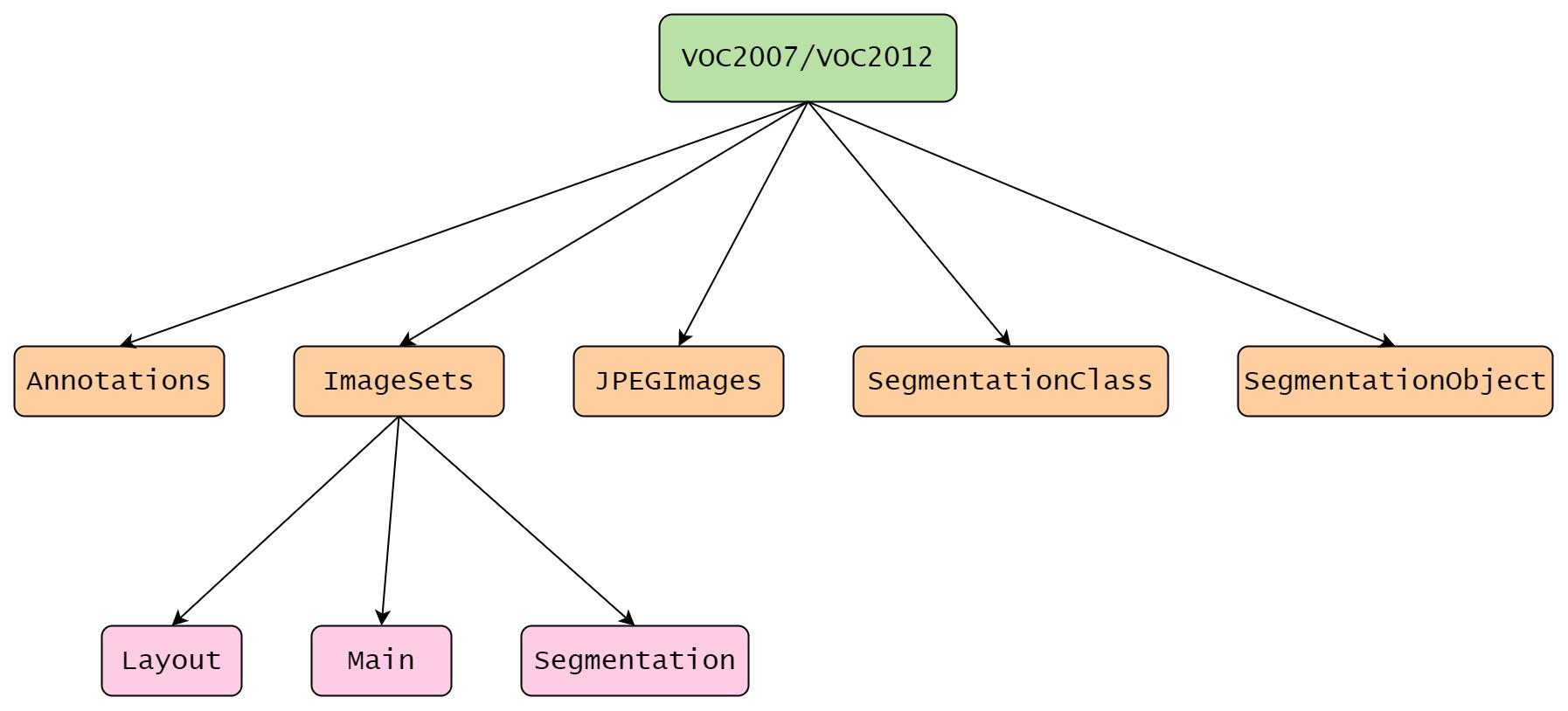
Annotations .xml标签文件,标记了图片大小及所含物体的类别、位置等信息,文件名与图片名一一对应
ImageSets 包含三个子文件夹 Layout、Main、Segmentation,各个子文件夹存放的是适用于各种任务的.txt文件,内容是图片的文件名
JPEGImages 所有的图片文件,.jpg格式
SegmentationClass 存放按照 class 分割的图片
SegmentationObject 存放按照 object 分割的图片
使用
from torchvision import dataset
4. KITTI
KITTI数据集是目前自动驾驶领域最重要的测试集之一,可以用于立体图像(stereo),光流(optical flow),视觉测距(visual odometry),3D物体检测(3D object detection)和3D跟踪(3D tracking)任务的评估。数据采集平台配备了两台高分辨率彩色摄像机和两台灰度摄像机,地面的实况信息由Velodyne激光雷达和GPS定位系统提供。数据集中包含在市区、乡村和高速公路等场景采集的真实图像数据,每张图像中最多可以看到15辆车和30个行人。

在代码中涉及到坐标轴的转换,因此需要对数据采集平台上个传感器做一个简要的介绍:
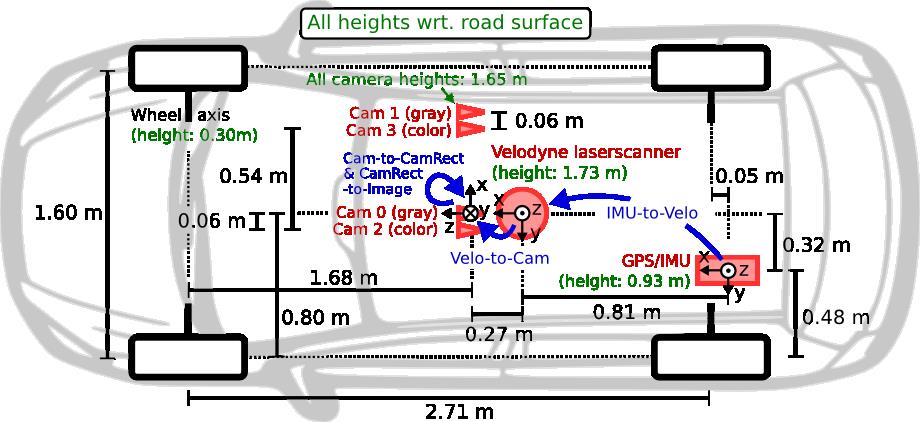
| 传感器 | 名称 | 高度信息 | 坐标系 |
|---|---|---|---|
| 彩色摄像机 | Cam 2 & Cam 3 | 1.65m |  |
| 灰度摄像机 | Cam 0 & Cam 1 | 1.65m | |
| 激光雷达 | Velodyne | 1.73m | 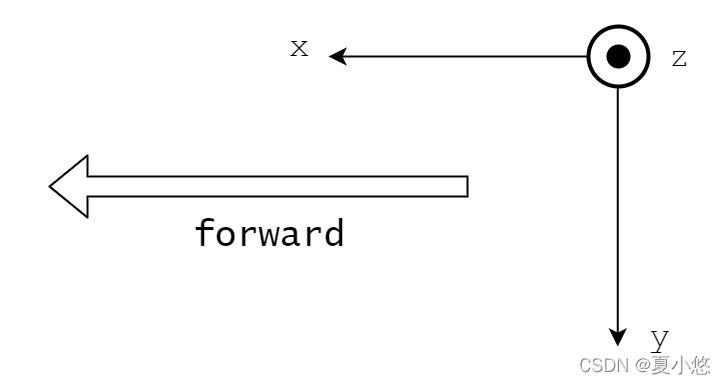 |
| GPS | GPS/IMU | 0.93m | |
由于AVOD论文中只涉及到了object任务,因此只对object下的数据集进行简要介绍:
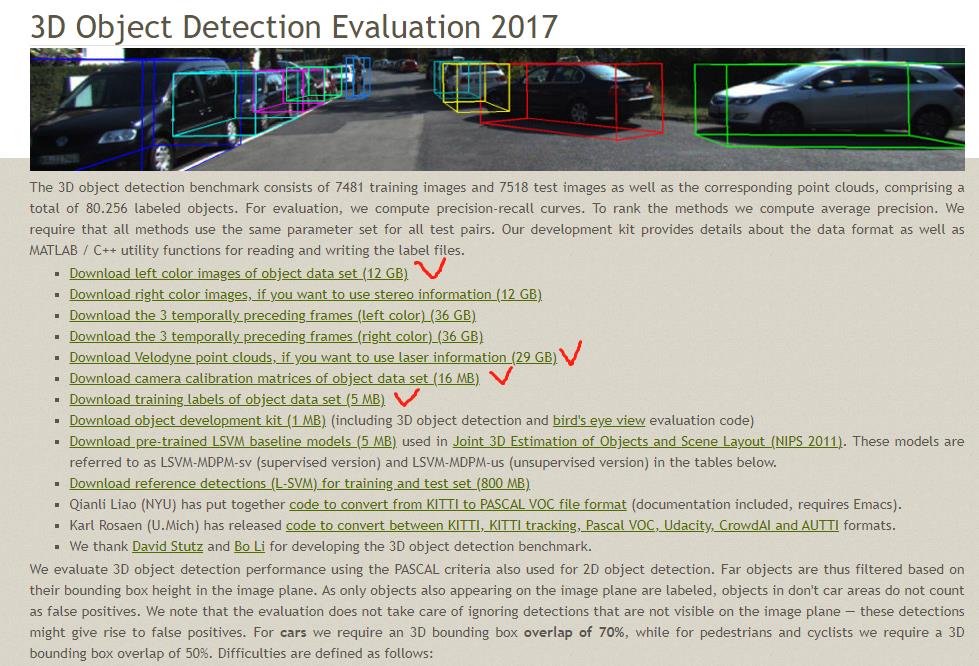
3D目标检测基准由7481张训练图像和7518张测试图像以及相应的点云数据组成,共包含80.256个标记对象。
解压后的数据集如下:
calib 文件夹包含相机、雷达、GPS/IMU等传感器的矫正数据,具体如下:
# 000274.txt
P0: 7.215377000000e+02 0.000000000000e+00 6.095593000000e+02 0.000000000000e+00 0.000000000000e+00 7.215377000000e+02 1.728540000000e+02 0.000000000000e+00 0.000000000000e+00 0.000000000000e+00 1.000000000000e+00 0.000000000000e+00
P1: 7.215377000000e+02 0.000000000000e+00 6.095593000000e+02 -3.875744000000e+02 0.000000000000e+00 7.215377000000e+02 1.728540000000e+02 0.000000000000e+00 0.000000000000e+00 0.000000000000e+00 1.000000000000e+00 0.000000000000e+00
P2: 7.215377000000e+02 0.000000000000e+00 6.095593000000e+02 4.485728000000e+01 0.000000000000e+00 7.215377000000e+02 1.728540000000e+02 2.163791000000e-01 0.000000000000e+00 0.000000000000e+00 1.000000000000e+00 2.745884000000e-03
P3: 7.215377000000e+02 0.000000000000e+00 6.095593000000e+02 -3.395242000000e+02 0.000000000000e+00 7.215377000000e+02 1.728540000000e+02 2.199936000000e+00 0.000000000000e+00 0.000000000000e+00 1.000000000000e+00 2.729905000000e-03
R0_rect: 9.999239000000e-01 9.837760000000e-03 -7.445048000000e-03 -9.869795000000e-03 9.999421000000e-01 -4.278459000000e-03 7.402527000000e-03 4.351614000000e-03 9.999631000000e-01
Tr_velo_to_cam: 7.533745000000e-03 -9.999714000000e-01 -6.166020000000e-04 -4.069766000000e-03 1.480249000000e-02 7.280733000000e-04 -9.998902000000e-01 -7.631618000000e-02 9.998621000000e-01 7.523790000000e-03 1.480755000000e-02 -2.717806000000e-01
Tr_imu_to_velo: 9.999976000000e-01 7.553071000000e-04 -2.035826000000e-03 -8.086759000000e-01 -7.854027000000e-04 9.998898000000e-01 -1.482298000000e-02 3.195559000000e-01 2.024406000000e-03 1.482454000000e-02 9.998881000000e-01 -7.997231000000e-01
文件中每一行表示一个参数矩阵,具体如下:
| 参数矩阵 | shape | 解释 | 备注 |
|---|---|---|---|
P0~P3 | 3x4 | 矫正后的相机投影矩阵, 其中0,1表示灰度摄像机,2,3表示彩色摄像机 | |
R0_rect | 3x3 | 矫正后的相机旋转矩阵 | 在实际计算时,需要将该矩阵扩展为4x4的矩阵,pad值为0 |
Tr_velo_to_cam | 3x4 | 雷达到相机的旋转平移矩阵 | 在实际计算时,需要将该矩阵扩展为4x4的矩阵,pad值为[0,0,0,1] |
Tr_imu_to_velo | 3x4 | GPS/IMU到相机的旋转平移矩阵 | 在实际计算时,需要将该矩阵扩展为4x4的矩阵,pad值为[0,0,0,1] |
# 比如将激光雷达坐标系中的点投影到左侧的彩色摄像机(P2)坐标系中,则计算公式为:
y = P2 ∗ R0_rect ∗ Tr_velo_to_cam ∗ x
image_2 文件夹包含的是.png格式的彩色图片(左侧彩色摄像头拍摄),具体如下:
image_2
label_2
planes
velodyne
4. flowers102
flowers102数据集官网下载
5. Pets37
Pets37数据集官网下载,该数据集可用于图像分类和图像分割,其中数据集数量为7390。
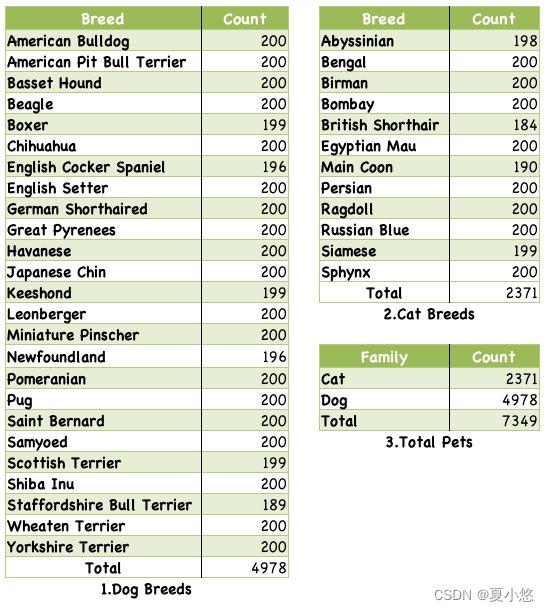
数据集包含两个压缩文件:
原图:https://www.robots.ox.ac.uk/~vgg/data/pets/data/images.tar.gz
标签:https://www.robots.ox.ac.uk/~vgg/data/pets/data/annotations.tar.gz
images.tar.gz这个压缩包,该文件解压后得到一个images目录,这个目录比较简单,里面直接放的是用类名和序号命名好的图片文件,每个图片是对应的宠物照片:
.
├── samoyed_7.jpg
├── ......
└── samoyed_81.jpg
annotations.tar.gz文件解压后的目录里面包含以下内容,目录中的README文件将每个目录和文件做了比较详细的介绍,可以通过README来查看每个目录文件的说明:
.
├── README
├── list.txt
├── test.txt
├── trainval.txt
├── trimaps
│ ├── Abyssinian_1.png
│ ├── Abyssinian_10.png
│ ├── ......
│ └── yorkshire_terrier_99.png
└── xmls
├── Abyssinian_1.xml
├── Abyssinian_10.xml
├── ......
└── yorkshire_terrier_190.xml
# 对于图像分类,label 在 xmls 目录下
# 对于图像分割,label 在 trimaps 目录下

6. CASIA-WebFace
CASIA-WebFace数据集官网链接已失效,可前往百度的AI Studio进行下载。
CASIA-WebFace数据集包含10575 个人的494414 张图像,压缩包约4G。
7. LFW(人脸比对数据集)
LFW数据集官网下载
LFW数据集是一个人脸比对数据,该数据集由13233张全世界知名人士互联网自然场景不同朝向、表情和光照环境人脸图片组成,共有5749人,其中有1680人有2张或2张以上人脸图片。每张人脸图片都有其唯一的姓名ID和序号加以区分。
LFW数据集主要测试人脸识别的准确率,该数据库从中随机选择了6000对人脸组成了人脸辨识图片对,其中3000对属于同一个人2张人脸照片,3000对属于不同的人每人1张人脸照片。测试过程LFW给出一对照片,询问测试中的系统两张照片是不是同一个人,系统给出yes或no的答案。通过6000对人脸测试结果的系统答案与真实答案的比值可以得到人脸识别准确率。目前已经成为了评估人脸识别算法性能的一个重要指标。
持续更新中…
以上是关于各领域公开数据集简介及下载使用方式的主要内容,如果未能解决你的问题,请参考以下文章
最大的英文手写数据集——IAM- ondb 简介下载读取使用分割及深度学习实战
最大的英文手写数据集——IAM- ondb 简介下载读取使用分割及深度学习实战