Python读取Mysql数据库数据保存至csv文件,以及简单使用Python进行数据分析。(加州房价数据集) Posted 2023-04-06 ChangchenWang
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Python读取Mysql数据库数据保存至csv文件,以及简单使用Python进行数据分析。(加州房价数据集)相关的知识,希望对你有一定的参考价值。
Hello 大家好
本篇内容我想和大家分享一下Python和Mysql数据库的交互 。数据库里面保存着我们所需要的数据,mysql
首先,我们需要知道,Python在和Mysql交互时比较重要的一个包:Pymysql, 有了这个包之后,我们就可以自定义数据连接,然后去拿到我们需要的数据了!上代码:
import pymysql
conn = pymysql.connect(
host = "localhost",
port = 3306,
user = 'root',
password= '你数据库的密码',
database= 'mysql',
charset='utf8'
) 这样呢,我们就定义好了mysql数据库的连接,那么如何测试我们是否连接成功了呢?我们可以从库里面找一张表,然后查询里面的数据并且打印出来。我们首先需要定义一个Cursor游标,这个游标的作用就是运行sql语句,关闭数据库链接等。
import pymysql
conn = pymysql.connect(
host = "localhost",
port = 3306,
user = 'root',
password= '你数据库的密码',
database= 'mysql',
charset='utf8'
)
# 创建游标
cursor = conn.cursor()
# sql语句书写
sql = "select * from test"
# 执行sql
cursor.execute(sql)
# 将sql语句查询到的内容全都保存到data变量中
data = cursor.fetchall()
# 关闭数据库连接
cursor.close()
# 打印查询到的所有内容
print(data) 现在!保存数据库到CSV文件中!首先我们需要导入csv包,这里我们顺便把pandas包也导入进来!pandas包是用来后期读取csv文件的库。(如果还没有安装pandas包的话,可以在命令行中使用pip命令安装:pip3 install pandas, 其他包也可以使用这个命令去进行安装)
import pymysql
import csv
import pandas as pd
conn = pymysql.connect(
host = "localhost",
port = 3306,
user = 'root',
password= '你数据库的密码',
database= 'mysql',
charset='utf8'
)
# 创建游标
cursor = conn.cursor()
# sql语句书写
sql = "select * from test"
# 执行sql
cursor.execute(sql)
# 将sql语句查询到的内容全都保存到data变量中
data = cursor.fetchall()
# 关闭数据库连接
cursor.close()
# 打印查询到的所有内容
print(data)
# 定义一个标题行
header = ('header1', 'header2', 'header3', 'header4', 'header5', 'header6')
with open ("c.csv", "w+", newline = "") as file:
pen = csv.writer(file)
pen.writerow(header)
# 遍历data中的每一行,并且转换为列表格式 (默认 tuple)
for i in data:
a = list(i)
pen.writerow(a) 现在我们已经把数据写入到了csv文件中了,现在我们需要使用pandas包读取csv文件并且打印出来:
import pymysql
import csv
import pandas as pd
conn = pymysql.connect(
host = "localhost",
port = 3306,
user = 'root',
password= '你数据库的密码',
database= 'mysql',
charset='utf8'
)
# 创建游标
cursor = conn.cursor()
# sql语句书写
sql = "select * from test"
# 执行sql
cursor.execute(sql)
# 将sql语句查询到的内容全都保存到data变量中
data = cursor.fetchall()
# 关闭数据库连接
cursor.close()
# 打印查询到的所有内容
print(data)
# 定义一个标题行
header = ('header1', 'header2', 'header3', 'header4', 'header5', 'header6')
with open("c.csv", "w+", newline = "") as file:
pen = csv.writer(file)
pen.writerow(header)
# 遍历data中的每一行,并且转换为列表格式 (默认 tuple)
for i in data:
a = list(i)
pen.writerow(a)
# 因为中文字符编码一般都是使用gbk,打开csv文件的时候增加encoding = "gbk",不然会字符乱码报错
data2 = pd.read_csv("c.csv", encoding = "gbk")
print(data2.head()) 现在我们就完成了从Python读取数据库数据到本地并且打印出来的全过程啦!当然,我们不仅能将数据保存为csv格式,我们也能把数据保存成excel文件,这些都是可以的。
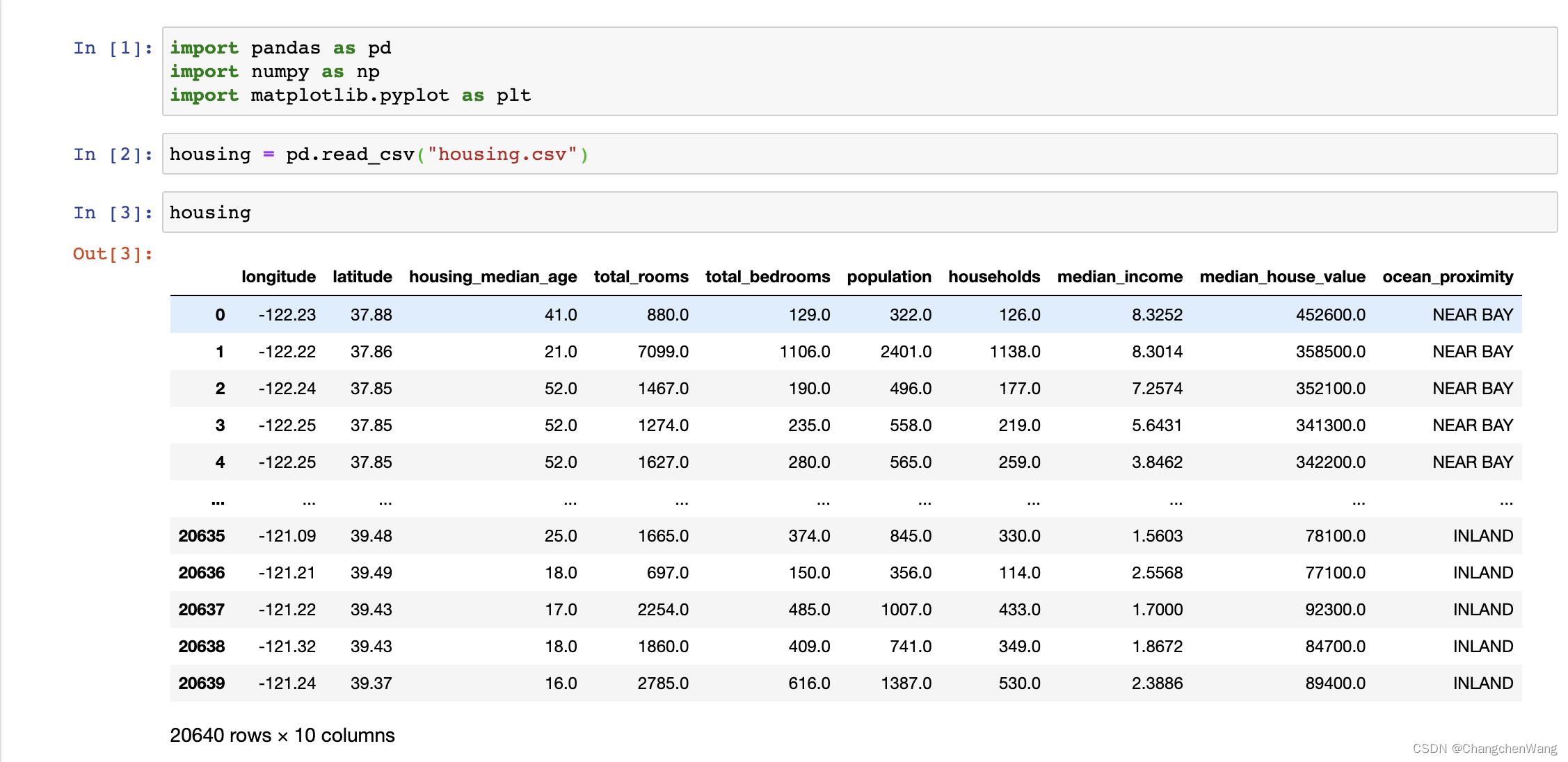
现在我们换一个数据集,我从kaggle官网上面下载了一个数据集,数据集的名称是加州房价预测,链接为:California Housing Data (1990) | Kaggle 。下面我将针对这个数据集使用numpy,pandas,matplotlib对这个数据集进行绘图,大家如果感兴趣的话也可以去官网上下载这个数据集试一下~
我们打开一个新的文件(下面的绘制过程我将使用Jupyter Notebook进行),创建好文件之后我们需要导入需要的三个包,在后面绘图的时候我们还需要导入request库以及map库。导入之后我们就要先读区我们的csv文件,也就是我们的数据集,数据集的名字是housing。
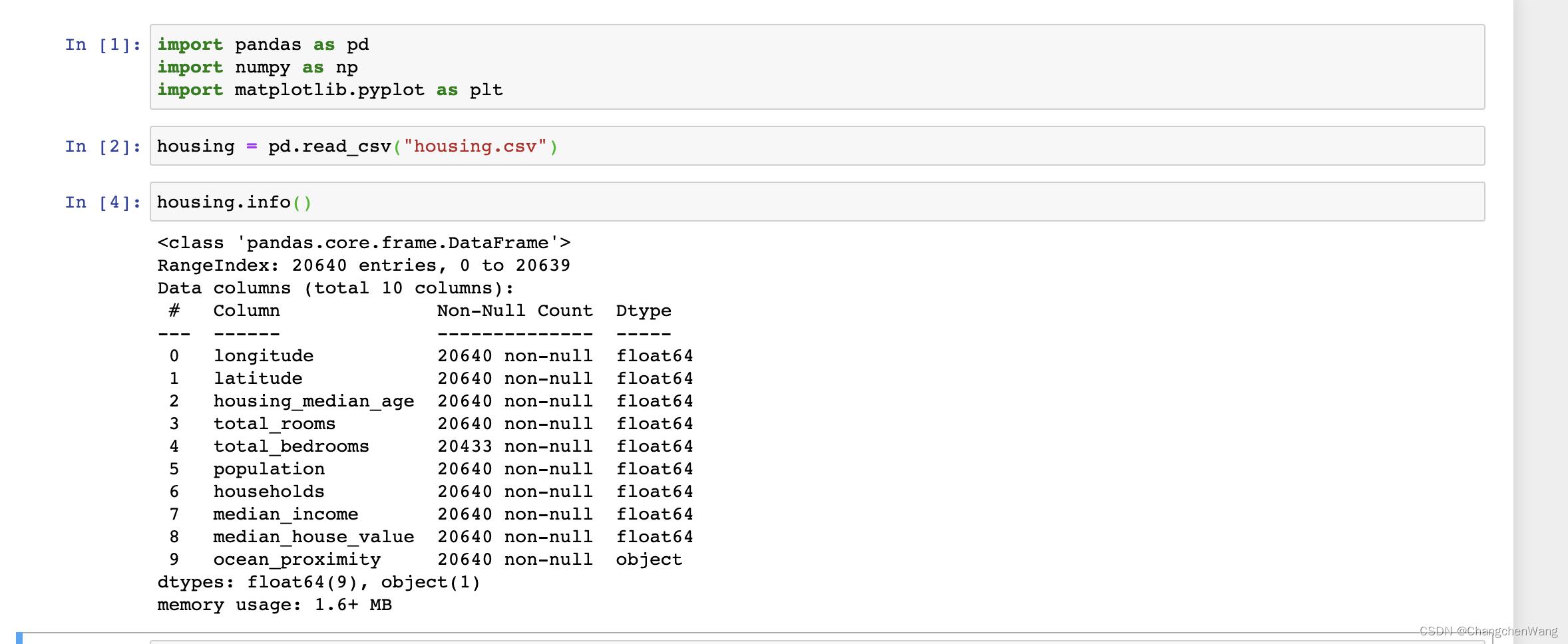
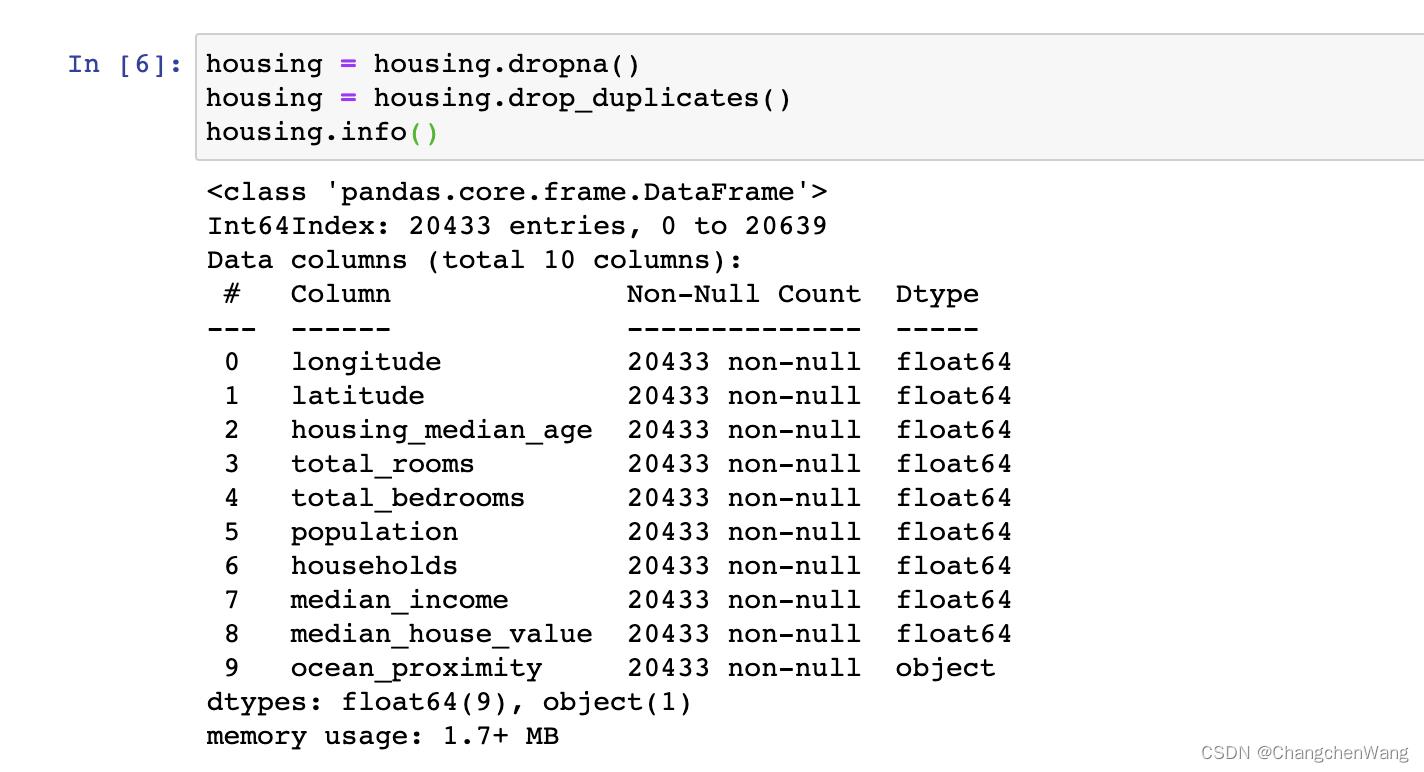
现在我们需要看一下数据集的质量,我们可以通过文件名.info()的方式去进行查看,我们可以很清楚的看到total_bedrooms的数据行数为20433,然而别的特征对应的行数为20640,所以我们可以理解为这一行里面是有空值的,因为我们可以看到non-null的数量为20433,null的数量应该有200多条数据。接下来我们就可以通过数据集.dropna() 以及数据集.drop_duplicates() 去清理我们数据集中的空值还有重复值。
删除完之后(如下图),我们就可以发现现在所有的特征所对应的行数都保持一致了,接下来我们就可以绘图了!
对了,绘图之前,我们可以通过数据集.head()再查看一下我们数据集的质量,如果数据集里面有的特征是含有单位的,我们就需要把数据集里面的单位给去掉,具体去掉的方法我可以先给大家附上一个代码,大家如果有需要的话可以直接使用就好。
代码说明:创建一个numpy类型的空数组,我们可以查看数据集中的哪一个特征值(列)是有单位并且需要我们改动的,我们就将这一列保存到一个变量中,然后循环这个变量。np.array(i[:-2])的-2表示每一个数据的最后两个字符,比如“千米”,“千克”这样的我们就可以通过这样的形式将它忽略到,如果是“平方米的话”,我们就需要遍历我们的数据到-3,也就是倒数第三个位置的地方去将单位忽略掉,然后不断的保存到我们的创建的列表中。最后再将我们替换完成的数据列放入到我们的原数据集housing中,替换原来数据集的特征列就可以了。
datalist = np.array([])
temp = housing["特征名"].values
for i in temp2:
datalist = np.append(datalist,np.array(i[:-2]))
datalist
housing.loc[:,"特征名"] = datalist上面只是如果我们有需要替换的(去掉单位)的情况我们才需要进行的步骤,我们可以接续绘图~
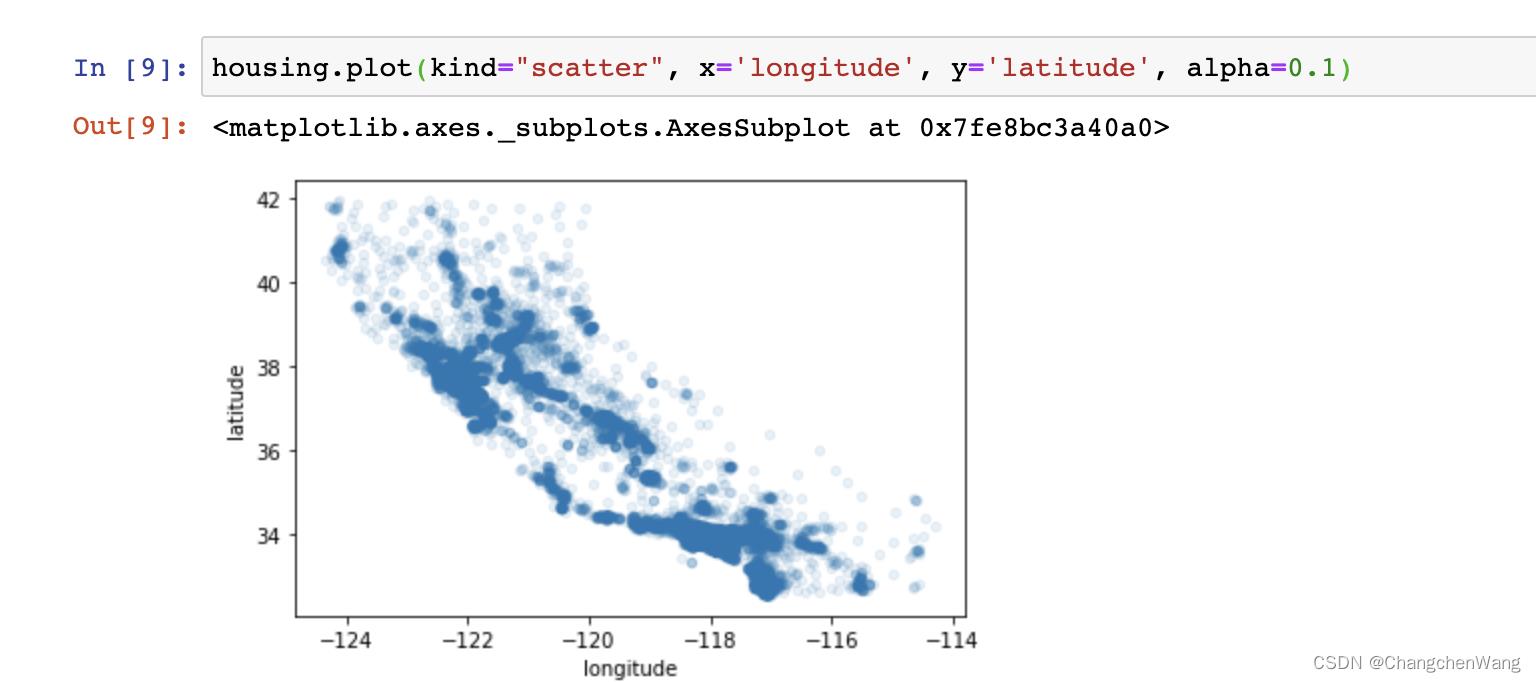
我们使用pyplot中的plot,去将我们数据集中的经纬度在我们的散点图中泼洒出来:
housing.plot(kind="scatter", x='longitude', y='latitude', alpha=0.1)
这样的效果如果不清楚的话,我们可以继续添加一些内容:
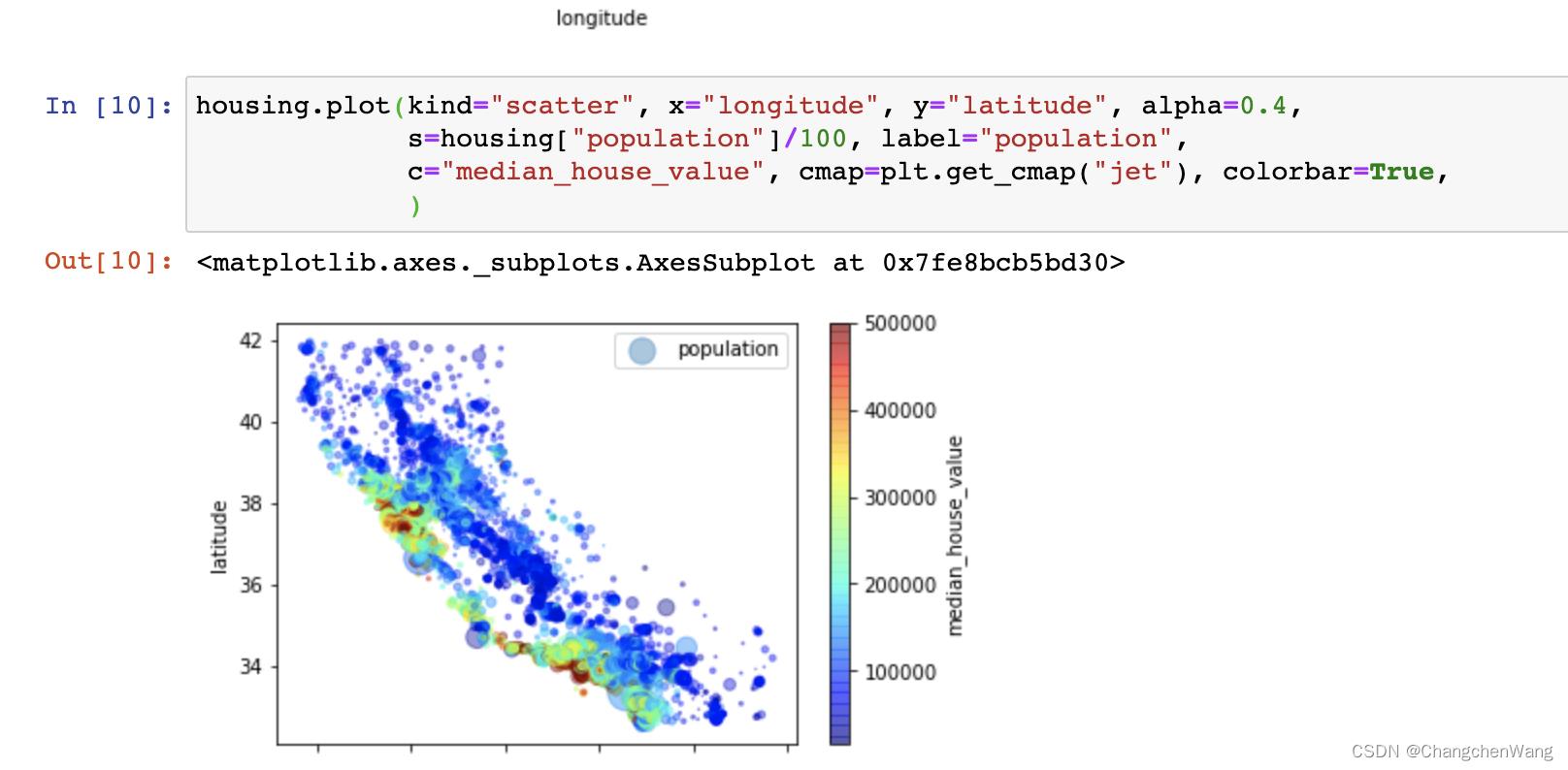
housing.plot(kind="scatter", x="longitude", y="latitude", alpha=0.4,
s=housing["population"]/100, label="population",
c="median_house_value", cmap=plt.get_cmap("jet"), colorbar=True,
)
根据数据分布我们不难发现,颜色越偏暖色代表房价越高,我们可以看到加州的房价比较高的地方是偏向于加州整体的西南部,我们也可以通过添加地图的形式,更清楚的观察到这一点。(此处特别感谢b站up主大扬笔谈录给予的灵感!) 代码如下:
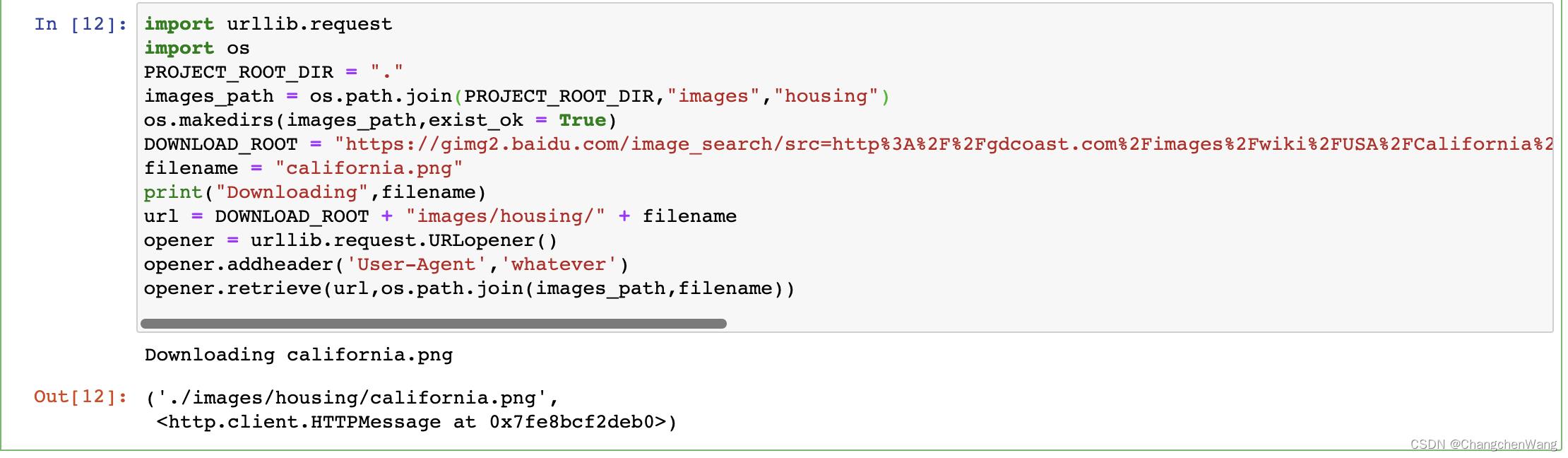
(我们需要导入request包还有os包,包括一会儿引入地图的时候我们也需要去引入map有关的包)
import urllib.request
import os
PROJECT_ROOT_DIR = "."
images_path = os.path.join(PROJECT_ROOT_DIR,"images","housing")
os.makedirs(images_path,exist_ok = True)
DOWNLOAD_ROOT = "https://gimg2.baidu.com/image_search/src=http%3A%2F%2Fgdcoast.com%2Fimages%2Fwiki%2FUSA%2FCalifornia%2Fmaps%2Fcalifornia_cities_map.png&refer=http%3A%2F%2Fgdcoast.com&app=2002&size=f9999,10000&q=a80&n=0&g=0n&fmt=auto?sec=1671804049&t=33441ad8576f0d76e775084ae7e7b370"
filename = "california.png"
print("Downloading",filename)
url = DOWNLOAD_ROOT + "images/housing/" + filename
opener = urllib.request.URLopener()
opener.addheader('User-Agent','whatever')
opener.retrieve(url,os.path.join(images_path,filename))
现在我们就可以看到,california.png图片已经保存到我们的目录下面啦!
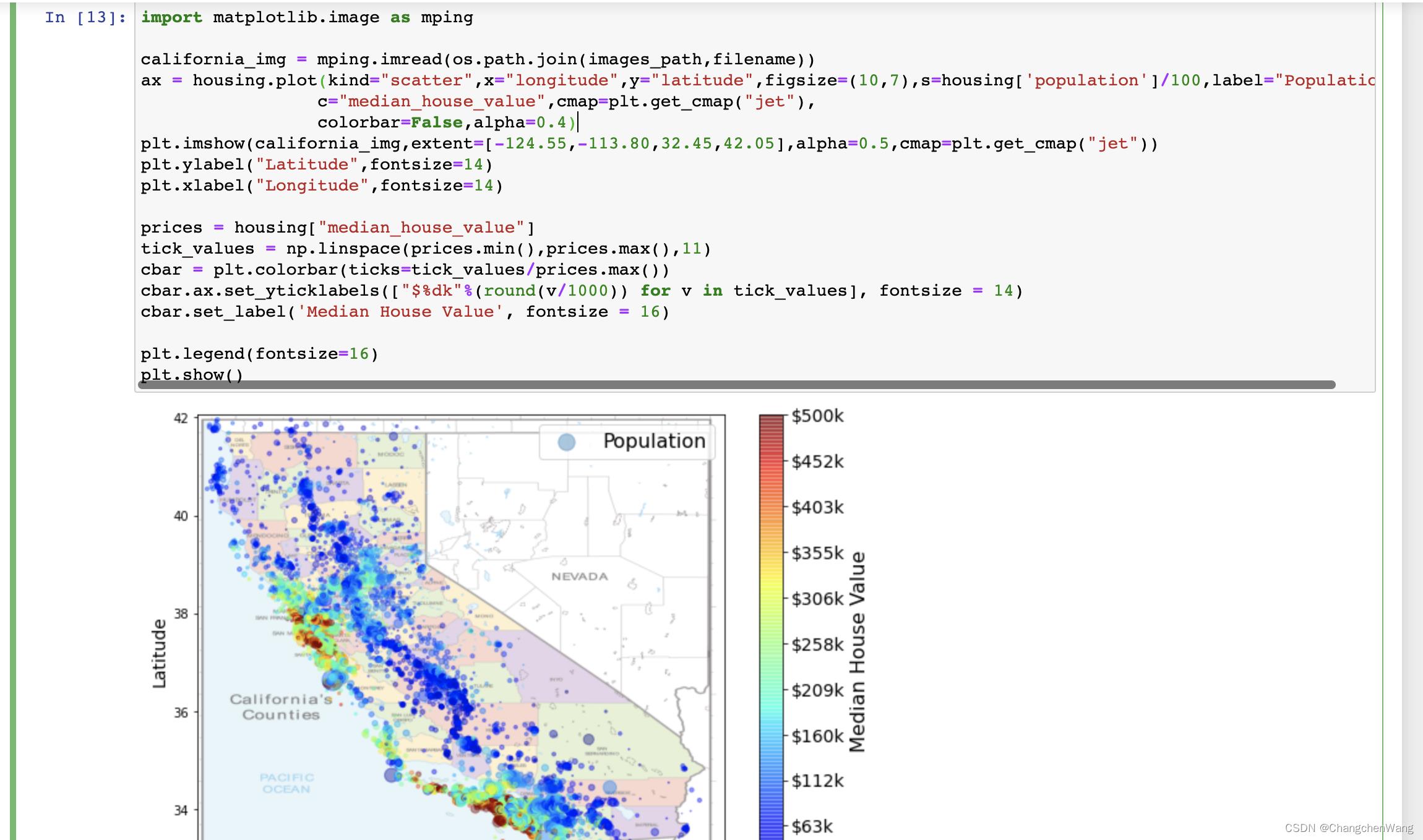
最后,我们就可以在我们原有的散点图的基础上,将我们从网上下载的地图图片读入到我们的画布上,并且调整好尺寸,已经横纵坐标对应的经纬度信息,我们就可以得到如下的效果了:
代码如下:
import matplotlib.image as mping
california_img = mping.imread(os.path.join(images_path,filename))
ax = housing.plot(kind="scatter",x="longitude",y="latitude",figsize=(10,7),s=housing['population']/100,label="Population",
c="median_house_value",cmap=plt.get_cmap("jet"),
colorbar=False,alpha=0.4)
plt.imshow(california_img,extent=[-124.55,-113.80,32.45,42.05],alpha=0.5,cmap=plt.get_cmap("jet"))
plt.ylabel("Latitude",fontsize=14)
plt.xlabel("Longitude",fontsize=14)
prices = housing["median_house_value"]
tick_values = np.linspace(prices.min(),prices.max(),11)
cbar = plt.colorbar(ticks=tick_values/prices.max())
cbar.ax.set_yticklabels(["$%dk"%(round(v/1000)) for v in tick_values], fontsize = 14)
cbar.set_label('Median House Value', fontsize = 16)
plt.legend(fontsize=16)
plt.show()
这样的话就更加清晰的印证了我们的想法,加州房价的西南部的确是整体偏高的,通过地图信息我们也能比较容易的假设出原因,可能就是因为加州的西南部是临海区域,所以整体的房价会偏高。
ok,本篇文章的分享内容就到这里啦,加州房价数据集作为机器学习使用的数据集的确数据质量非常棒,我们在使用的过程中没有花费太多的经历去进行清洗和改动。
本篇内容我主要和大家分享了如果使用Python和我们的数据库进行互联,以及如何将我们的数据保存至本地生成csv文件,后来我又下载了kaggle上面的数据集和大家简单分享了一下数据分析的简易步骤,虽然可能会非常的基础,但是大家如果能在看完我这篇文章之后收获一些东西的话,我会非常开心的!我的分享就到这里啦,非常谢谢大家的观看~我们其他文章见!
Python ddt读取CSV文件数据驱动
import csv
搜索词,响应 以上是关于Python读取Mysql数据库数据保存至csv文件,以及简单使用Python进行数据分析。(加州房价数据集)的主要内容,如果未能解决你的问题,请参考以下文章
Python之csv模块
如何将MYSQL中数据导出到EXCEL表中 python 脚本?
Python ddt读取CSV文件数据驱动
Python读取CSV文件并存储到MySQL
Python使用pandas & pymysql读取MySQL数据到csv文件中
Python使用pandas & pymysql读取MySQL数据到csv文件中