增强学习Reinforcement Learning经典算法梳理2:蒙特卡洛方法
Posted songrotek
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了增强学习Reinforcement Learning经典算法梳理2:蒙特卡洛方法相关的知识,希望对你有一定的参考价值。
1 前言
在上一篇文章中,我们介绍了基于Bellman方程而得到的Policy Iteration和Value Iteration两种基本的算法,但是这两种算法实际上很难直接应用,原因在于依然是偏于理想化的两个算法,需要知道状态转移概率,也需要遍历所有的状态。对于遍历状态这个事,我们当然可以不用做到完全遍历,而只需要尽可能的通过探索来遍及各种状态即可。而对于状态转移概率,也就是依赖于模型Model,这是比较困难的事情。
什么是状态转移?就比如一颗子弹,如果我知道它的运动速度,运动的当前位置,空气阻力等等,我就可以用牛顿运动定律来描述它的运动,进而知道子弹下一个时刻会大概在哪个位置出现。那么这个基于牛顿运动定律来描述其运动就是一个模型Model,我们也就可以知道其状态(空间位置,速度)的变化概率。
那么基本上所以的增强学习问题都需要有一定的模型的先验知识,至少根据先验知识我们可以来确定需要多少输入可以导致多少输出。比如说玩Atari这个游戏,如果输入只有屏幕的一半,那么我们知道不管算法多么好,也无法训练出来。因为输入被限制了,而且即使是人类也是做不到的。但是以此同时,人类是无需精确的知道具体的模型应该是怎样的,人类可以完全根据观察来推算出相应的结果。
所以,对于增强学习的问题,或者说对于任意的决策与控制问题。输入输出是由基本的模型或者说先验知识决定的,而具体的模型则可以不用考虑。所以,为了更好的求解增强学习问题,我们更关注Model Free的做法。简单的讲就是如果完全不知道状态转移概率(就像人类一样),我们该如何求得最优的策略呢?
本文介绍蒙特卡洛方法。
2 蒙特卡洛方法
蒙特卡洛方法只面向具有阶段episode的问题。比如玩一局游戏,下一盘棋,是有步骤,会结束的。而有些问题则不一定有结束,比如开赛车,可以无限的开下去,或者说需要特别特别久才能结束。能不能结束是一个关键。因为只要能结束,那么每一步的reward都是可以确定的,也就是可以因此来计算value。比如说下棋,最后赢了就是赢了,输了就是输了。而对于结束不了的问题,我们只能对于value进行估计。
那么蒙特卡洛方法只关心这种能够较快结束的问题。蒙特卡洛的思想很简单,就是反复测试求平均。如果大家知道在地上投球计算圆周率的事情就比较好理解了。不清楚的童鞋可以网上找找看。那么如何用在增强学习上呢?
既然每一次的episode都可以到结束,那么意味着根据:

每一步的reward都知道,也就意味着每一步的return
Gt
都可以计算出来。这就好了。我们反复做测试,这样很多状态会被遍历到,而且不止一次,那么每次就可以把在状态下的return求和取平均。
当episode无限大时,得到的数据也就接近于真实的数据。
蒙特卡洛方法就是使用统计学的方法来取代Bellman方法的计算方法。

上面的算法叫first-visit MC。也就是每一次的episode中state只使用第一次到达的t来计算return。
另一种方法就是every-visit,就是每一次的episode中state只要访问到就计算return求平均。
所以可以看到蒙特卡洛方法是极其简单的。但是缺点也是很明显的,需要尽可能多的反复测试,而且需要到每一次测试结束后才来计算,需要耗费大量时间。但是,大家知道吗?AlphaGo就是使用蒙特卡洛的思想。不是蒙特卡洛树搜索,而是说在增强学习中使用蒙特卡洛方法的思想。AlphaGo每次也是到下棋结束,而且只使用最后的输赢作为return。所以这也是非常神奇的事,只使用最后的输赢结果,竟然能够优化每一步的走法。
3 使用蒙特卡洛方法来控制
上面说的蒙特卡洛方法只是能够对当前的policy进行评估。那么大家记得上一个blog说的policy iteration方法吗?我们可以在policy iteration中使用蒙特卡洛方法进行评估,然后使用greedy policy更新。
那么依然是有两种做法。一种就是在一个policy下测试多次,评估完全,然后更新policy,然后再做很多测试。另一种就是不完全评估,每次测试一次完就评估,评估完就更新:
第一种做法:

第二种做法:
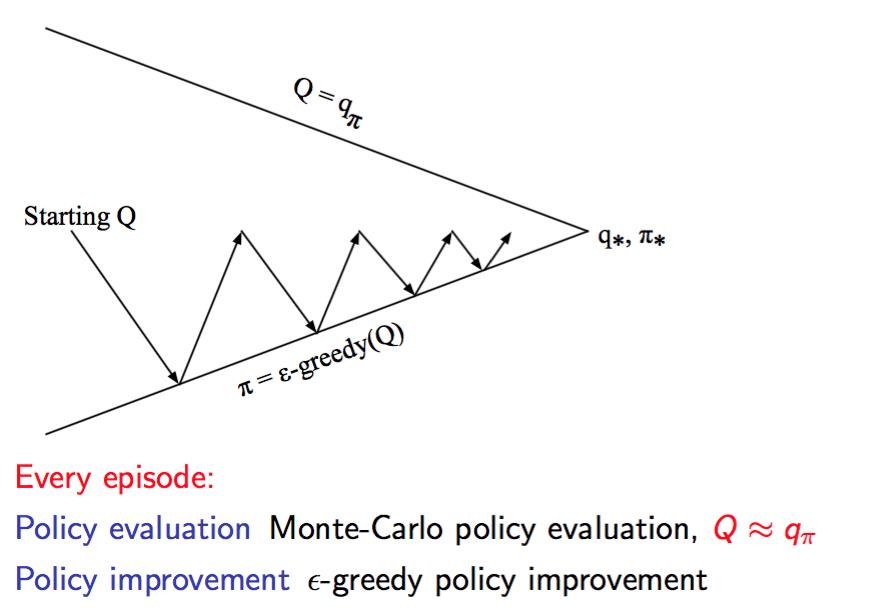
两种做法都能够收敛,那么显然第二种做法的速度更快。
那么再改进一点,就是改变greedy policy中
ϵ
的值,使得不断变小趋于0,这个时候最后得到的policy就是完全的最优policy了。
这个算法就叫做GLIE Monte-Carlo Control:

其他变种:
Monte Carlo with Exploring Starts,使用
Q(s,a)
,然后使用上面说的第二种做法,一次episode就更新一次policy,而且policy直接使用Q值。

policy的更新使用了
ϵ−greedy
,目的就是能够更好的探索整个状态空间。

4 Off Policy Learning
那么上面的方法一直是基于当前的policy,为了探索状态空间,采用一个次优的策略
ϵ−greedy
policy来探索。那么是不是可以更直接的使用两个policy。一个policy用来探索空间,也就是behavior policy,另一个policy就是为了达到最优policy,叫做target policy。那么这种方法就叫做off policy learning。On-policy的方法比较简单,off-policy 方法需要更多的概念和标记,比较不好理解,而且,由于behaviour policy和target policy不相关,这种方法比较不容易收敛。但是off-policy更强大,更通用,实际上的on-policy方法就是off-policy方法的一个子集。比如,就可以使用off-policy从人类专家或者传统的控制算法来学习一个增强学习模型。

关键是要找到两个policy之间的权重关系,从而更新Q值。
关于off-policy learning的部分,之后结合TD方法再做分析。
小结
本次blog分析了一下蒙特卡洛方法。这种基于统计学的方法算法简单,但是更多的只能用于虚拟环境能进行无限测试的情况。并且state 状态比较有限,离散的最好。基于这个方法,比如简单的五子棋(棋盘最好小一点),就可以用这个方法来玩玩了。
接下来的blog讲分析TD方法。
声明:
本文的图片截取自:
1 Reinforcement Learning: An Introduction
2 Reinforcement Learning Course by David Silver
以上是关于增强学习Reinforcement Learning经典算法梳理2:蒙特卡洛方法的主要内容,如果未能解决你的问题,请参考以下文章
增强学习Reinforcement Learning经典算法梳理3:TD方法
增强学习Reinforcement Learning经典算法梳理1:policy and value iteration
增强学习Reinforcement Learning经典算法梳理1:policy and value iteration