elasticsearch 搭配 canal 构建主从复制架构实战
Posted 今天想吃柠檬
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了elasticsearch 搭配 canal 构建主从复制架构实战相关的知识,希望对你有一定的参考价值。
目录
前言
elasticsearch通常在项目中用于做海量数据存储和全文搜索,在电商的商品搜索,论坛的发帖搜索中有广泛应用。但是一般这些数据会存储在关系型数据库中例如mysql,mysql数据库拥有良好的事务解决方案,清晰的数据结构,丰富的组合查询功能,是大部分项目的首选存储方案。那么当数据量增长到一定程度,或者有全文搜索、模糊搜索、联想搜索等搜索方面的需求的时候,ES就会比Mysql显得更加合适了。
这个时候问题来了,在现有服务的存储环境主要是mysql的前提下如何把搜索服务交给ES来进行处理,那么就需要将mysql中的数据同步到ES中,并且这种同步操作应该是异步不影响原先服务运行的。我们采用的方案是使用阿里的canal搭建一个主从复制架构,将mysql的数据同步过来到ES,然后ES提供搜索服务
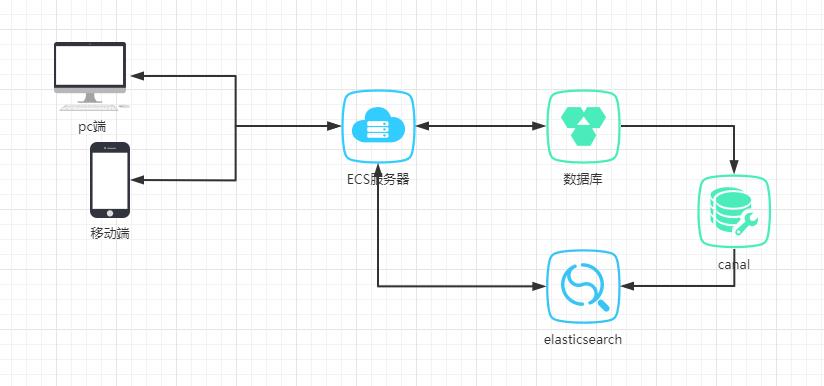
安装ES
首先我们登录ES官网
选择liunx x86平台,本次实战中我们选择的版本是7.10.0。 点击下载,我们可以得到一个elasticsearch的压缩包,然后我们通过ftp将压缩包上传到我们的服务器上你想要安装的目录,然后将压缩包进行解压。
解压之后可以得到一个elasticsearch-7.10.0的文件夹
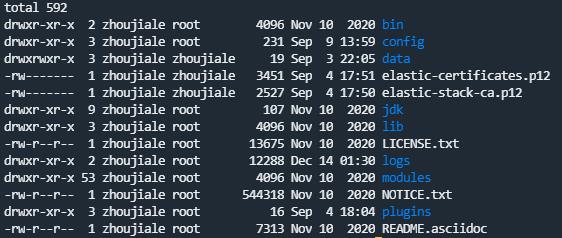
可以看到解压后的目录如上。下面我们进入bin的目录看到如下
一般elasticsearch启动,应该使用非root用户来执行改命令,所以记住我们需要先创建一个新的用户然后输入命令
./elasticsearch -d-d表示以守护进程运行,即使退出当前命令也可以在后台执行。
监听或打开安装目录下的logs/elasticsearch.log,有如下的日志输出即为成功

启动成功后,我们在浏览器中输入elasticsearch部署的ip加上9200端口可以返回elasticsearch的相关信息 。
"name" : "DESKTOP-KRUG30P",
"cluster_name" : "elasticsearch",
"cluster_uuid" : "FAUTZ1PBTdelqYRhiz876Q",
"version" :
"number" : "7.10.0",
"build_flavor" : "default",
"build_type" : "zip",
"build_hash" : "51e9d6f22758d0374a0f3f5c6e8f3a7997850f96",
"build_date" : "2020-11-09T21:30:33.964949Z",
"build_snapshot" : false,
"lucene_version" : "8.7.0",
"minimum_wire_compatibility_version" : "6.8.0",
"minimum_index_compatibility_version" : "6.0.0-beta1"
,
"tagline" : "You Know, for Search"
如果启动失败的话,有时候可能是因为内存不足的原因,因为elasticsearch默认的分配内存是比较大的,如果你的机器配置比较低可能就无法启动。这个时候可以找到elasticsearch的config目录下有个jvm.options的文件,这个文件就是设置java虚拟机的各种参数
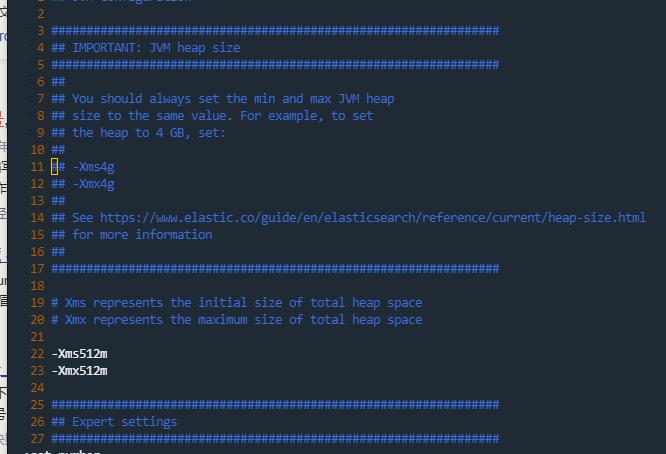
按照例子我们可以降低内存分配再启动试试
一般在使用elasticsearch时我们都会使用到分词器,通常对于中文分词我们会使用ik分词器
可以到GitHub 上进行下载。
一种是我们在plugins目录下自己创建一个文件夹,将ik插件的压缩包解压到此。
另一种是直接通过bin目录下的命令来下载
elasticsearch-plugin install https://github.com/medcl/elasticsearch-analysis-ik/releases/download/v7.10.0/elasticsearch-analysis-ik-7.10.0.zip安装ES-head插件
一般我们需要查看存储数据的时候,都会需要一个图形化的操作工具,这样便于我们操作。那么elasticsearch-head插件就是很好的一种方案。
我们进入GitHub,找到elasticsearch-head项目 可以通过git clone下该项目,也可以直接下载。切换到elasticsearch-head文件目录,然后运行命令
npm install
npm run start &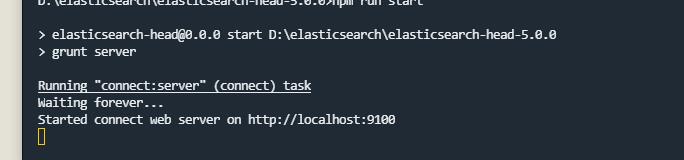
看到上面的日志输出即为成功。
打开浏览器访问主机ip:9100端口可以看到
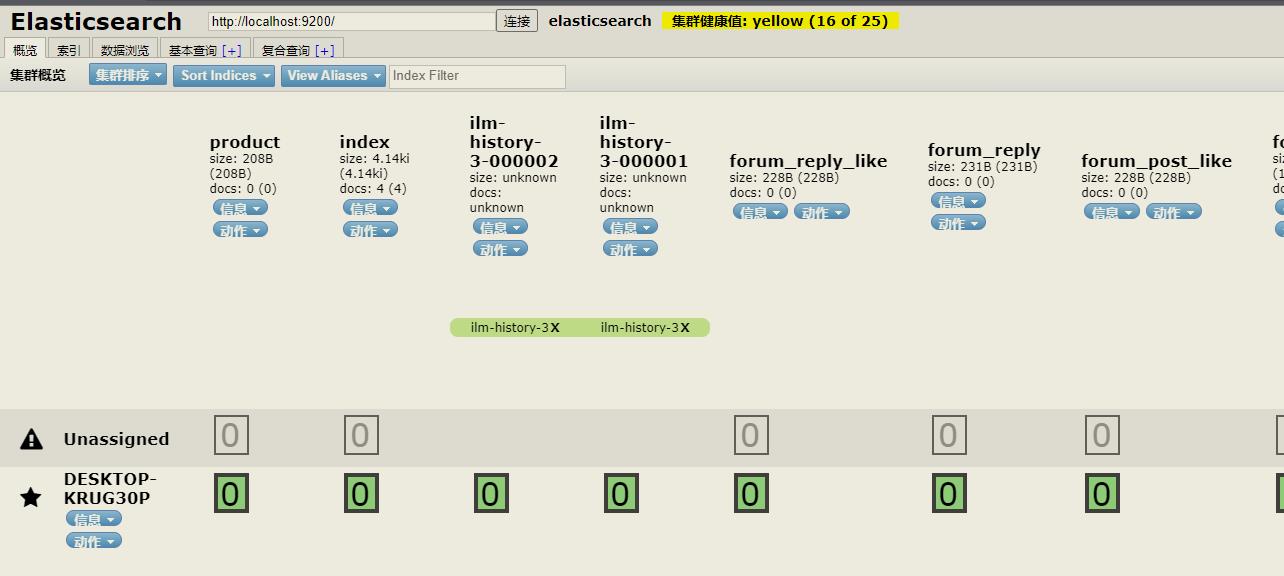
这个就是我们的elasticsearch-head控制台。
安全保护
上面两步已经完成了对elasticsearch和elasticsearch-head的安装。那么刚才的访问都是匿名的,对于我们来说是不安全的容易收到外界的攻击。所以我们需要激活elasticsearch的x-pack功能来增加账号密码的验证。
首先进入elasticsearch的安装目录找到config文件夹,进入elasticsearch.yml文件,在末尾添加上如下的配置
#支持跨域
http.cors.enabled: true
http.cors.allow-origin: "*"
http.cors.allow-headers: Content-Type,Accept,Authorization, x-requested-with
#password
xpack.security.enabled: true
xpack.security.transport.ssl.enabled: true
xpack.security.transport.ssl.verification_mode: certificate
xpack.security.transport.ssl.client_authentication: required
xpack.security.transport.ssl.keystore.path: elastic-certificates.p12
xpack.security.transport.ssl.truststore.path: elastic-certificates.p12跨域是为了解决设置账号密码之后elasticsearch-head访问的跨域问题,下面的是开启相关的安全参数。退出保存后,进入安装目录下的bin文件夹
执行命令
elasticsearch-setup-passwords interactive按提示输入账号和密码进行配置。
然后我们重启elasticsearch和elasticsearch-head。在浏览器中输入elasticsearch服务的地址加9200端口,访问后会看到需要我们输入账号密码,说明我们elasticsearch的密码配置已经成功了
然后我们访问elasticsearch-head,在浏览器中输入elasticsearch-head服务地址加9100端口后面跟上用户名和密码,例如
http://localhost:9100/?auth_user=elastic&auth_password=elastic这里账号密码都用的是elastic.
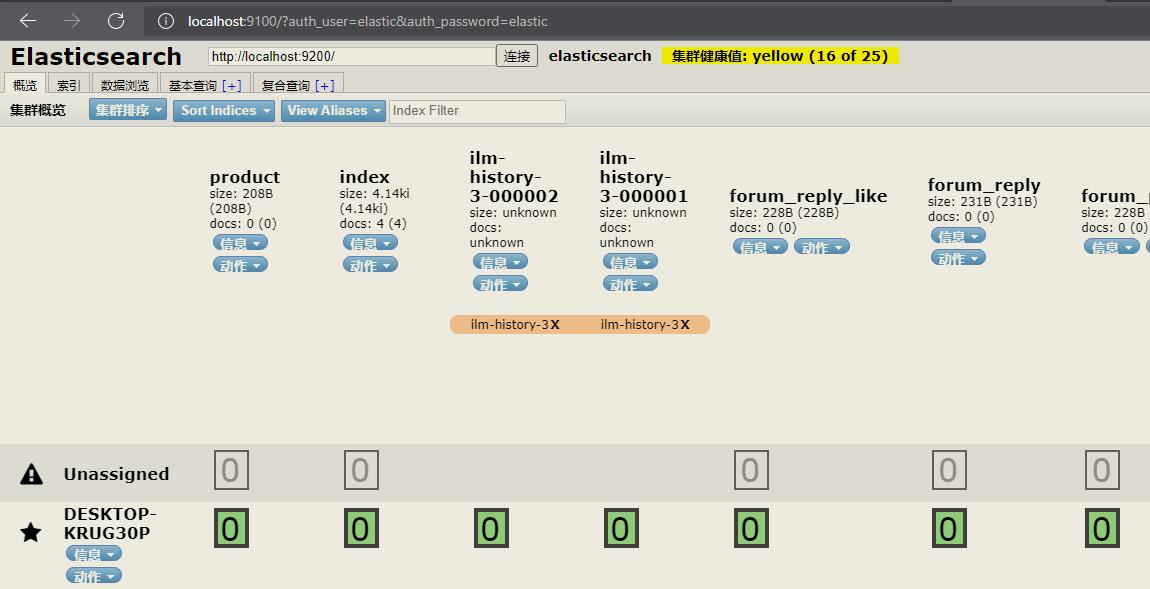
可以看到服务能够正常访问。
此外我们通常会使用spring框架来整合这些中间件服务。由于我们的elasticsearch加了账号密码。我们需要在代码中配置。
首先在配置文件里面加上
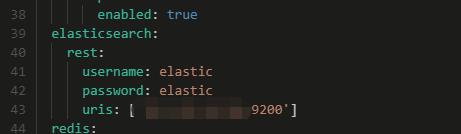
然后在配置类中设置账号密码,可以通过spring的@Value读取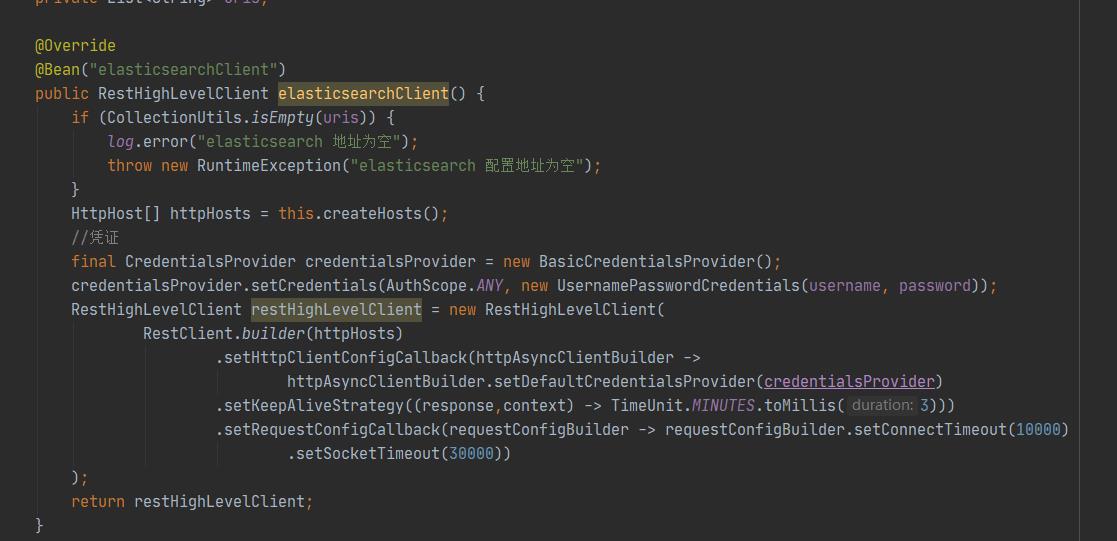
到此elasticsearch和elasticsearch-head的配置就完成了
canal实时同步mysql数据到elasticsearch(部署,配置,测试)
这里写目录标题
简介

canal基于MySQL数据库增量日志解析,提供增量数据订阅和消费,是阿里开源CDC工具,它可以获取MySQL binlog数据并解析,然后将数据变动传输给下游。基于canal,可以实现从MySQL到其他数据库的实时同步
工作原理
MySQL主备复制原理
MySQL master 将数据变更写入二进制日志( binary log, 其中记录叫做二进制日志事件binary log events,可以通过 show binlog events 进行查看)
MySQL slave 将 master 的 binary log events 拷贝到它的中继日志(relay log)
MySQL slave 重放 relay log 中事件,将数据变更反映它自己的数据
canal 工作原理
canal 模拟 MySQL slave 的交互协议,伪装自己为 MySQL slave ,向 MySQL master 发送dump 协议
MySQL master 收到 dump 请求,开始推送 binary log 给 slave (即 canal )
canal 解析 binary log 对象(原始为 byte 流)
以上来自canal的github介绍,链接:https://github.com/alibaba/canal
canal 使用流程

- 部署Deployer服务,该服务负责从上游拉取binlog数据、记录位点等
- 部署Client-Adapter服务,该服务负责对接Deployer解析过的数据,并将数据传输到目标库中。
- 部署完成后,canal默认会自动同步MySQL增量数据。
- 如果需要同步MySQL全量数据,请手动调用Client-Adapter服务的方法触发同步任务。
待全量数据同步完成后,canal会自动开始增量同步。
环境搭建
环境使用版本
需要注意版本对应,canal1.1.6版本需要jdk11,canal1.1.5版本支持jdk8
| 应用 | 版本 |
|---|---|
| mysql | 8.0.28 |
| elasticsearch | 7.9.2 |
| canal | 1.1.5 |
| jdk | 8 |
mysql配置
修改配置
配置数据库my.cnf文件,如果是windows则配置my.ini文件
#设置serveri_id
server_id=101
#开启二进制日志功能
log-bin=mall-mysql-bin
#设置使用的二进制日志格式(mixed,statement,row)
binlog_format=row
配置完成重启mysql,使用 show variables like ‘%log_bin%’; 命令查看是否开启
mysql> show variables like '%log_bin%';
+---------------------------------+-------------------------------------+
| Variable_name | Value |
+---------------------------------+-------------------------------------+
| log_bin | ON |
| log_bin_basename | /var/lib/mysql/mall-mysql-bin |
| log_bin_index | /var/lib/mysql/mall-mysql-bin.index |
| log_bin_trust_function_creators | OFF |
| log_bin_use_v1_row_events | OFF |
| sql_log_bin | ON |
+---------------------------------+-------------------------------------+
6 rows in set (0.12 sec)
查看是否为row模式
mysql> show variables like '%binlog_format%';
+---------------+-------+
| Variable_name | Value |
+---------------+-------+
| binlog_format | ROW |
+---------------+-------+
1 row in set (0.02 sec)
创建从库权限账号
创建从库权限账号canal,用于订阅binlog
mysql> create user canal identified by 'Password@123';
mysql> grant select, replication slave, replication client on *.* to 'canal'@'%';
mysql> flush privileges;
创建测试数据库
mysql> CREATE DATABASE canal;
mysql> CREATE DATABASE IF NOT EXISTS canal default charset utf8 COLLATE utf8_general_ci;
创建测试数据表
CREATE TABLE `test_book` (
`id` bigint unsigned NOT NULL AUTO_INCREMENT,
`title` varchar(200) CHARACTER SET utf8mb4 COLLATE utf8mb4_general_ci DEFAULT NULL COMMENT '题名',
`isbn` varchar(20) CHARACTER SET utf8mb4 COLLATE utf8mb4_general_ci DEFAULT NULL COMMENT 'isbn',
`author` varchar(255) CHARACTER SET utf8mb4 COLLATE utf8mb4_general_ci DEFAULT NULL COMMENT '作者',
`publisher_name` varchar(255) CHARACTER SET utf8mb4 COLLATE utf8mb4_general_ci DEFAULT NULL COMMENT '出版社名',
PRIMARY KEY (`id`) USING BTREE
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_general_ci ROW_FORMAT=DYNAMIC
elasticsearch配置
创建索引

建立映射
"properties":
"id":
"type": "long"
,
"title":
"type": "text"
,
"isbn":
"type": "text"
,
"author":
"type": "text"
,
"publisherName":
"type": "text"

canal的下载部署
下载canal
下载地址:https://github.com/alibaba/canal/releases
下载解压到服务器指定目录

配置服务端 canal-deployer
canal-deployer伪装成mysql的从库,监听binlog接收数据,目录结构如下:

修改配置/conf/canal.properties,除了ip和port外,其他配置可不改动
#canal的server地址:127.0.0.1
canal.ip =127.0.0.1
#canal端口,用于客户端监听
canal.port = 11111
修改配置/conf/example/instance.properties
#被同步的mysql地址
canal.instance.master.address=127.0.0.1:3306
#数据库从库权限账号
canal.instance.dbUsername=canal
#数据库从库权限账号的密码
canal.instance.dbPassword=Password@123
#数据库连接编码
canal.instance.connectionCharset = UTF-8
#需要订阅binlog的表过滤正则表达式
canal.instance.filter.regex=.*\\\\..*
启动canal-deployer,进入bin目录,执行启动命令:
./startup.sh
查看日志:/logs/canal/canal.log
2023-02-02 15:28:16.016 [main] INFO com.alibaba.otter.canal.deployer.CanalLauncher - ## set default uncaught exception handler
2023-02-02 15:28:16.043 [main] INFO com.alibaba.otter.canal.deployer.CanalLauncher - ## load canal configurations
2023-02-02 15:28:16.054 [main] INFO com.alibaba.otter.canal.deployer.CanalStarter - ## start the canal server.
2023-02-02 15:28:16.112 [main] INFO com.alibaba.otter.canal.deployer.CanalController - ## start the canal server[127.0.0.1(127.0.0.1):11111]
2023-02-02 15:28:17.824 [main] INFO com.alibaba.otter.canal.deployer.CanalStarter - ## the canal server is running now ......
查看日志:/logs/canal/canal.log
2023-02-02 15:28:17.590 [main] INFO c.a.otter.canal.instance.spring.CanalInstanceWithSpring - start CannalInstance for 1-example
2023-02-02 15:28:17.619 [main] WARN c.a.o.canal.parse.inbound.mysql.dbsync.LogEventConvert - --> init table filter : ^.*\\..*$
2023-02-02 15:28:17.619 [main] WARN c.a.o.canal.parse.inbound.mysql.dbsync.LogEventConvert - --> init table black filter : ^mysql\\.slave_.*$
2023-02-02 15:28:17.757 [destination = example , address = /127.0.0.1:3306 , EventParser] WARN c.a.o.c.p.inbound.mysql.rds.RdsBinlogEventParserProxy - ---> begin to find start position, it will be long time for reset or first position
2023-02-02 15:28:17.776 [main] INFO c.a.otter.canal.instance.core.AbstractCanalInstance - start successful....
2023-02-02 15:28:17.776 [destination = example , address = /127.0.0.1:3306 , EventParser] WARN c.a.o.c.p.inbound.mysql.rds.RdsBinlogEventParserProxy - prepare to find start position just show master status
2023-02-02 15:28:18.382 [destination = example , address = /127.0.0.1:3306 , EventParser] WARN c.a.o.c.p.inbound.mysql.rds.RdsBinlogEventParserProxy - ---> find start position successfully, EntryPosition[included=false,journalName=mall-mysql-bin.000008,position=12380,serverId=101,gtid=,timestamp=1675309792000] cost : 610ms , the next step is binlog dump
日志如上就已经成功启动
可能的问题: caching_sha2_password Auth failed
原因:
使用mysql版本为8.0,而创建用户时默认的密码加密方式为caching_sha2_password,所以修改为mysql_native_password
ALTER USER 'canal'@'%' IDENTIFIED WITH mysql_native_password BY '密码'; #更新一下用户密码
FLUSH PRIVILEGES; #刷新权限
配置客户端canal-adapter
canal-adapter:作为canal的客户端,会从canal-server中获取数据,然后同步数据到MySQL、Elasticsearch等存储中去。目录结构如下:

修改配置/conf/application.yml
server:
port: 8081
spring:
jackson:
date-format: yyyy-MM-dd HH:mm:ss
time-zone: GMT+8
default-property-inclusion: non_null
canal.conf:
mode: tcp # 客户端的模式,可选tcp kafka rocketMQ
flatMessage: true # 扁平message开关, 是否以json字符串形式投递数据, 仅在kafka/rocketMQ模式下有效
zookeeperHosts: # 对应集群模式下的zk地址
syncBatchSize: 1000 # 每次同步的批数量
retries: 0 # 重试次数, -1为无限重试
timeout: # 同步超时时间, 单位毫秒
accessKey:
secretKey:
consumerProperties:
# canal tcp consumer
canal.tcp.server.host: 127.0.0.1:11111 #设置canal-server的地址
canal.tcp.zookeeper.hosts:
canal.tcp.batch.size: 500
canal.tcp.username:
canal.tcp.password:
srcDataSources: # 源数据库配置
defaultDS:
url: jdbc:mysql://127.0.0.1:3306/canal?useUnicode=true&useSSL=true #测试数据库连接
username: root #数据库账号
password: Cxstar@2014 #数据库密码
canalAdapters: # 适配器列表
- instance: example # canal实例名或者MQ topic名
groups: # 分组列表
- groupId: g1 # 分组id, 如果是MQ模式将用到该值
outerAdapters:
- name: logger # 日志打印适配器
- name: es7 # ES同步适配器
hosts: 192.168.0.182:9200 # ES连接地址
properties:
mode: rest # 模式可选transport(9300) 或者 rest(9200)
#security.auth: elastic:123456 # 连接es的用户和密码,仅rest模式使用
cluster.name: elasticsearch # ES集群名称, 与es目录下 elasticsearch.yml文件cluster.name对应
进入/conf/es7目录下,复制mytest_user.yml命名为test_book.yml,同时修改:
dataSourceKey: defaultDS # 源数据源的key, 对应上面配置的srcDataSources中的值
destination: example # canal的instance或者MQ的topic
groupId: g1 # 对应MQ模式下的groupId, 只会同步对应groupId的数据
esMapping:
_index: test_book # es 的索引名称
_id: _id # es 的_id, 如果不配置该项必须配置下面的pk项_id则会由es自动分配
sql: "SELECT
tb.id AS _id,
tb.title,
tb.isbn,
tb.author,
tb.publisher_name as publisherName
FROM
test_book tb" # sql映射
etlCondition: "where p.id>=" #etl的条件参数
commitBatch: 3000 # 提交批大小
启动canal-adapter,进入bin目录,执行启动命令:
./startup.sh
canal-adapter启动报错问题
1.com.mysql.jdbc.exceptions.jdbc4.CommunicationsException: Communications link failure
[main] ERROR com.alibaba.druid.pool.DruidDataSource - init datasource error, url: jdbc:mysql://127.0.0.1:3306/canal?useUnicode=true&useSSL=true
com.mysql.jdbc.exceptions.jdbc4.CommunicationsException: Communications link failure
The last packet successfully received from the server was 216 milliseconds ago. The last packet sent successfully to the server was 210 milliseconds ago.
解决方法:/conf/application.yml 中的mysql连接去除&useSSL=true
2.com.alibaba.druid.pool.DruidDataSource cannot be cast to com.alibaba.druid.pool.DruidDataSource
ERROR c.a.o.canal.adapter.launcher.loader.CanalAdapterLoader - Load canal adapter: es7 failed
java.lang.RuntimeException: java.lang.RuntimeException: java.lang.ClassCastException: com.alibaba.druid.pool.DruidDataSource cannot be cast to com.alibaba.druid.pool.DruidDataSource
at com.alibaba.otter.canal.client.adapter.es7x.ES7xAdapter.init(ES7xAdapter.java:54) ~[client-adapter.es7x-1.1.5-jar-with-dependencies.jar:na]
原因:druid 包冲突
解决方法:
方法1.下载源码包 ,修改client-adapter/escore/pom.xml
<dependency>
<groupId>com.alibaba</groupId>
<artifactId>druid</artifactId>
<scope>provided</scope>
</dependency>
打包后将client-adapter/es7x/target/client-adapter.es7x-1.1.5-jar-with-dependencies.jar上传到服务器,替换adataper/plugin下的同名jar文件
方法2.下载v1.1.5-alpha-2,

找到plugin目录下的client-adapter.es7x-1.1.5-SNAPSHOT-jar-with-dependencies.jar
上传到服务器 canal.adapter-1.1.5/plugin目录下,同时删除client-adapter.es7x-1.1.5-jar-with-dependencies.jar
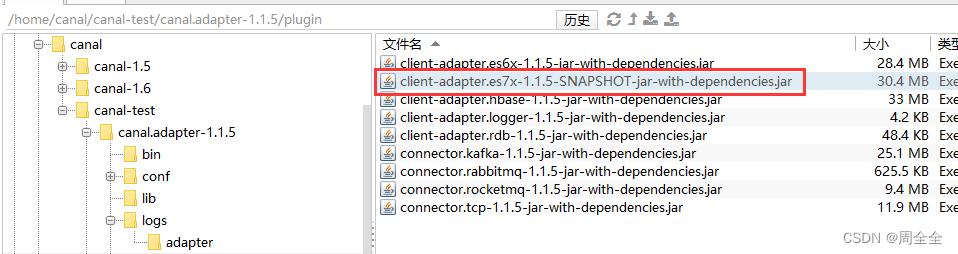
3.Load canal adapter: es7 failed,Name or service not known
ERROR c.a.o.canal.adapter.launcher.loader.CanalAdapterLoader - Load canal adapter: es7 failed
java.lang.RuntimeException: java.net.UnknownHostException: http: Name or service not known
at com.alibaba.otter.canal.client.adapter.es7x.ES7xAdapter.init(ES7xAdapter.java:54) ~[client-adapter.es7x-1.1.5-SNAPSHOT-jar-with-dependencies.jar:na]
解决方案:/conf/application.yml配置中 ,hosts不要带http://
4.java.lang.NullPointerException: esMapping._type
ERROR c.a.o.c.client.adapter.es.core.monitor.ESConfigMonitor - esMapping._type
java.lang.NullPointerException: esMapping._type
at com.alibaba.otter.canal.client.adapter.es.core.config.ESSyncConfig.validate(ESSyncConfig.java:35) ~[client-adapter.es7x-1.1.5-SNAPSHOT-jar-with-dependencies.jar:na]
at com.alibaba.otter.canal.client.adapter.es.core.monitor.ESConfigMonitor$FileListener.onFileChange(ESConfigMonitor.java:102) ~[client-adapter.es7x-1.1.5-SNAPSHOT-jar-with-dependencies.jar:na]
at org.apache.commons.io.monitor.FileAlterationObserver.doMatch(FileAlterationObserver.java:400) [commons-io-2.4.jar:2.4]
at org.apache.commons.io.monitor.FileAlterationObserver.checkAndNotify(FileAlterationObserver.java:334) [commons-io-2.4.jar:2.4]
at org.apache.commons.io.monitor.FileAlterationObserver.checkAndNotify(FileAlterationObserver.java:304) [commons-io-2.4.jar:2.4]
at org.apache.commons.io.monitor.FileAlterationMonitor.run(FileAlterationMonitor.java:182) [commons-io-2.4.jar:2.4]
at java.lang.Thread.run(Thread.java:748) [na:1.8.0_221]
解决方案:canal.adapter-1.1.5/conf/es7目录下的yml中增加一个官方配置的属性
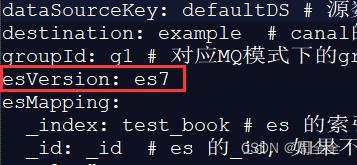
hosts: 192.168.0.182:9200 # ES连接地址
验证canal-adapter是否启动成功
查看日志 canal.adapter-1.1.5/logs/adapter/adapter.log
[org.springframework.cloud.context.properties:name=configurationPropertiesRebinder,context=2b76ff4e,type=ConfigurationPropertiesRebinder]
2023-02-03 09:34:13.373 [main] INFO c.a.o.canal.adapter.launcher.loader.CanalAdapterService - ## syncSwitch refreshed.
2023-02-03 09:34:13.374 [main] INFO c.a.o.canal.adapter.launcher.loader.CanalAdapterService - ## start the canal client adapters.
2023-02-03 09:34:13.375 [main] INFO c.a.otter.canal.client.adapter.support.ExtensionLoader - extension classpath dir: /home/canal/canal-test/canal.adapter-1.1.5/plugin
2023-02-03 09:34:13.418 [main] INFO c.a.o.canal.adapter.launcher.loader.CanalAdapterLoader - Load canal adapter: logger succeed
2023-02-03 09:34:13.643 [main] INFO c.a.o.c.client.adapter.es.core.config.ESSyncConfigLoader - ## Start loading es mapping config ...
2023-02-03 09:34:13.726 [main] INFO c.a.o.c.client.adapter.es.core.config.ESSyncConfigLoader - ## ES mapping config loaded
2023-02-03 09:34:13.995 [main] INFO c.a.o.canal.adapter.launcher.loader.CanalAdapterLoader - Load canal adapter: es7 succeed
2023-02-03 09:34:14.005 [main] INFO c.alibaba.otter.canal.connector.core.spi.ExtensionLoader - extension classpath dir: /home/canal/canal-test/canal.adapter-1.1.5/plugin
2023-02-03 09:34:14.029 [main] INFO c.a.o.canal.adapter.launcher.loader.CanalAdapterLoader - Start adapter for canal-client mq topic: example-g1 succeed
2023-02-03 09:34:14.029 [Thread-4] INFO c.a.otter.canal.adapter.launcher.loader.AdapterProcessor - =============> Start to connect destination: example <=============
2023-02-03 09:34:14.029 [main] INFO c.a.o.canal.adapter.launcher.loader.CanalAdapterService - ## the canal client adapters are running now ......
2023-02-03 09:34:14.037 [main] INFO org.apache.coyote.http11.Http11NioProtocol - Starting ProtocolHandler ["http-nio-8081"]
2023-02-03 09:34:14.039 [main] INFO org.apache.tomcat.util.net.NioSelectorPool - Using a shared selector for servlet write/read
2023-02-03 09:34:14.067 [main] INFO o.s.boot.web.embedded.tomcat.TomcatWebServer - Tomcat started on port(s): 8081 (http) with context path ''
2023-02-03 09:34:14.080 [main] INFO c.a.otter.canal.adapter.launcher.CanalAdapterApplication - Started CanalAdapterApplication in 5.221 seconds (JVM running for 5.807)
2023-02-03 09:34:14.169 [Thread-4] INFO c.a.otter.canal.adapter.launcher.loader.AdapterProcessor - =============> Subscribe destination: example succeed <=============
同步测试
建立es索引和mysql表的映射
在客户端目录canal.adapter-1.1.5/conf/es7下配置字段的映射,adapter默认会加载es路径下的所有yml文件。一个配置文件表示一张表的mapping。
建立es和mysql的映射文件test_book.yml
dataSourceKey: defaultDS # 源数据源的key, 对应上面配置的srcDataSources中的值
destination: example # canal的instance或者MQ的topic
groupId: g1 # 对应MQ模式下的groupId, 只会同步对应groupId的数据
esVersion: es7
esMapping:
_index: test_book # es 的索引名称
_id: _id # es 的_id, 如果不配置该项必须配置下面的pk项_id则会由es自动分配
sql: "SELECT
b.id AS _id,
b.title,
b.author,
b.isbn,
b.publisher_name as publisherName
FROM
test_book b" # sql映射
etlCondition: "where p.id>=" #etl的条件参数
commitBatch: 5000 # 提交批大小
插入mysql数据验证同步
INSERT INTO `canal`.`test_book`( `title`, `isbn`, `author`, `publisher_name`) VALUES ( '三体', '98741254125', '刘慈欣', '工业出版社');
查看日志 canal.adapter-1.1.5/logs/adapter/adapter.log
2023-02-03 10:18:21.988 [pool-2-thread-1] INFO c.a.o.canal.client.adapter.logger.LoggerAdapterExample - DML: "data":["id":3,"title":"三体","isbn":"98741254125","author":"刘慈欣","publisher_name":"工业出版社"],"database":"canal","destination":"example","es":1675390701000,"groupId":"g1","isDdl":false,"old":null,"pkNames":["id"],"sql":"","table":"test_book","ts":1675390701977,"type":"INSERT"
2023-02-03 10:18:22.225 [pool-2-thread-1] DEBUG c.a.o.canal.client.adapter.es.core.service.ESSyncService - DML: "data":["id":3,"title":"三体","isbn":"98741254125","author":"刘慈欣","publisher_name":"工业出版社"],"database":"canal","destination":"example","es":1675390701000,"groupId":"g1","isDdl":false,"old":null,"pkNames":["id"],"sql":"","table":"test_book","ts":1675390701977,"type":"INSERT"
Affected indexes: test_book
查看es数据,已经成功同步
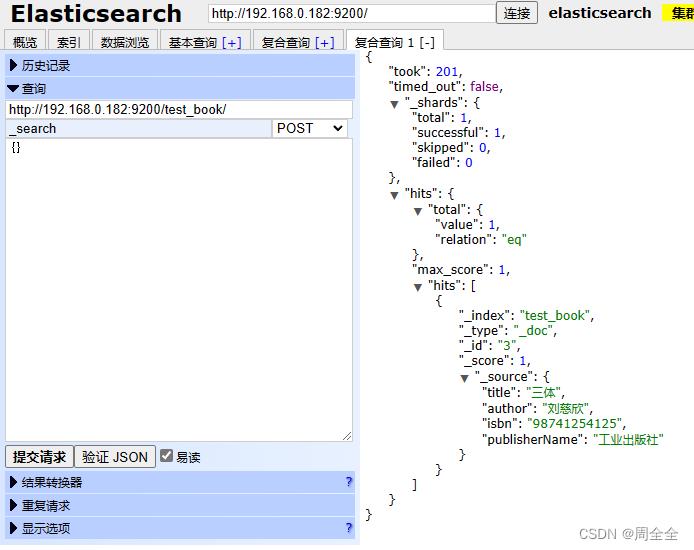
数据同步
canal开启前的数据如何同步
canal-adapter提供一个REST接口可全量同步数据到ES,调用Client-Adapter服务的方法触发同步任务。此时,canal会先中止增量数据传输,然后同步全量数据。待全量数据同步完成后,canal会自动进行增量数据同步。
注意:如果数据是binlog开启前存在,则不可以使用此种方式
curl http://127.0.0.1:8081/etl/es7/test_book.yml -X POST
同步日志:
2023-02-03 10:41:35.043 [http-nio-8081-exec-1] INFO c.a.otter.canal.client.adapter.es7x.etl.ESEtlService - start etl to import data to index: test_book
2023-02-03 10:41:35.130 [http-nio-8081-exec-1] INFO c.a.otter.canal.client.adapter.es7x.etl.ESEtlService - 数据全量导入完成, 一共导入 3 条数据, 耗时: 85
binlog未开启前的历史数据如何同步?
因为canal是基于binlog实现全量同步的,那么未开启binlog之前的历史数据就无法被同步,将数据库中的数据导出再重新导入一遍,这样就可以生成binlog
es数组类型同步
adapter配置文件中添加配置
objFields:
author: array:, #代表字段以,分割
配置更新后会监听到配置改变,无需重启
2023-02-03 11:33:24.098 [Thread-3] INFO c.a.o.c.client.adapter.es.core.monitor.ESConfigMonitor - Change a es mapping config: test_book.yml of canal adapter
更新数据,author字段
UPDATE `canal`.`test_book` SET `title` = '三体', `isbn` = '98741254125', `author` = '刘慈欣,刘电工', `publisher_name` = '工业出版社' WHERE `id` = 1;
es中的数据已改变

多张表数据同步到一个索引中
yml映射文件中,主表一定要在最左侧,从表的数据改变也会自动同步到es中!
示例:journal_volume 表中的数据改变,也会自动同步到journal_paper 表对应的es索引中
SELECT
jp.id AS _id,
jp.sid AS sid,
jp.import_id AS importId,
jp.journal_id AS journalId,
jp.journal_volume_id AS journalVolumeId,
jv.`year` as year,
jv.volume as volume,
jv.issue as issue,
j.publisher_name as publisherName
FROM journal_paper jp
left join journal_volume jv on jp.journal_volume_id=jv.id
left join journal j on j.id=jp.journal_id
可参考,待亲自实现
https://blog.csdn.net/qq_24950043/article/details/122643889
以上是关于elasticsearch 搭配 canal 构建主从复制架构实战的主要内容,如果未能解决你的问题,请参考以下文章
实战 | canal 实现Mysql到Elasticsearch实时增量同步
使用canal解决Mysql和ElasticSearch数据同步问题
使用Canal中间件同步MySql数据到ElasticSearch
使用canal监控mysql数据库实现elasticsearch索引实时更新