线程池大小选择:针对 I/O 密集型场景和 CPU 密集型场景
Posted 钊YChen
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了线程池大小选择:针对 I/O 密集型场景和 CPU 密集型场景相关的知识,希望对你有一定的参考价值。
线程池大小选择:针对 I/O 密集型场景和 CPU 密集型场景
I/O 密集型场景
I/O 密集型场景指的是系统的磁盘以及内存的性能要高于CPU 性能,因此系统在这种场景下,大部分时间消耗在磁盘/内存的读写,CPU 的利用率不高。比如一些包含网络传输的场景。通常我们不会希望 CPU 成为瓶颈,因为 CPU 毕竟是计算机中很昂贵的部分,我们希望 CPU 可以做更多的工作,因为我们会通过调整线程池大小来转移业务瓶颈,这将在下文提到。
CPU密集型场景
CPU 密集型则相反,指的是 CPU 的性能高于磁盘和内存,这时 CPU 的利用率为 100%,I/O 只需要很短的时间就可以完成。比如当使用 CPU 时(而不是 GPU),神经网络的前向和反向计算就是典型的 CPU 密集型场景,因为这其中涉及了大量的卷积和数值运算。
线程池大小选择
线程池在 I/O 密集型场景的必要性
在这两种场景下,线程池大小的选择也是不同的。在 I/O 密集型场景中,我们需要增大线程池的大小以通过 overlap 消除 CPU 等待 I/O 的时间。这样讲很抽象,可以参考下图,首先我们假设这是一个任务,红色部分表示 I/O 时间,白色部分表示 CPU 处理时间
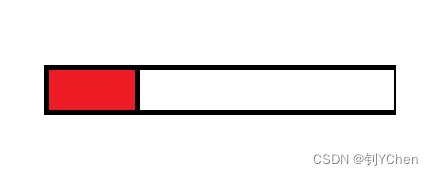
当线程池大小为1,也就是串行执行时,可以看到中间会有很多等待 I/O 的时间,CPU 被白白浪费:

当线程池大小为2,两个线程并发执行,这时候可以遮盖(overlap)I/O 的部分,从外部看 CPU 一直在执行,没有干等的时候:

可以看到合理设置线程池大小,可以将 I/O 的时间给遮盖掉,更好地利用 CPU 的资源。具体公式将在后续讲解。
线程池在 CPU 密集型场景的必要性
实际上,只有多核 CPU 的主机才适合使用线程池处理 CPU 密集型场景。我们举个例子,在单核 CPU 中,CPU 占用率为 100%,这时我们的线程池大小设置为2,那么在线程切换时需要有线程上下文切换的开销,这是需要时间的,而且线程的切换并没有意义,单个 CPU 的的利用率一直是 100%,相当于白白多了上下文切换的时间。而假如是 6 核的 CPU,这时可以将线程池大小设置为 6,这样 6 个 CPU 中都有自己的线程,处理速度可以提升 6 倍。
线程池大小计算
铺垫了前面的理论,我们这里具体给出线程池大小的计算公式。首先明确几个变量:
- Ncpu = CPU 的数量
- Ucpu = CPU 的目标使用率
- W / C = 等待 I/O 的时间和 CPU 计算时间的比
为保持 CPU 的使用率,最优的线程池大小为:
Nthreads = Ncpu x Ucpu x (1 + W / C)
这个公式的由来我们可以参考《Linux 多线程服务器端编程》中的一个思路:
如果线程池在执行任务时,CPU 计算所占的时间比重为 P,主机一共有 C 个 CPU,为了让 C 个 CPU 都跑到 100%,那么我们需要 C / P 个线程,所以也就是:
Nthreads =(( I/O 时间 + CPU 计算时间 )/ CPU 计算时间)x CPU 数量
也就是
Nthreads = (( I/O 时间 / CPU 计算时间 )+ 1)x CPU 数量
再加上目标的 CPU 利用率,就是上面提到的公式了。
所以我们可以分析在不同场景下的线程池大小计算,I/O 密集型场景,根据公式计算即可。CPU 密集型场景,根据公式应该是 CPU 核数,但是实际应用场景中通常用 CPU 核数 + 1,这个 + 1 实际上是为了保证当某个 CPU 上的线程因为缺页中断或某些原因暂停时,刚好有一个额外的线程来保证 CPU 不会空等,总之还是让 CPU 一直处于忙碌的状态。
Linux 下查看 CPU 利用率和 I/O 占用率
CPU 利用率查看
1 - 使用 top 命令:

关注 %Cpu(s) 的第四项 id,表示的是空闲 CPU 的百分比,所以在我这个场景下,CPU 的利用率就是 1 - 74.3 % = 25.7%,如果该主机拥有多个 CPU,可以在 top 命令界面按1,会显示多个 CPU 的情况,如下图所示:
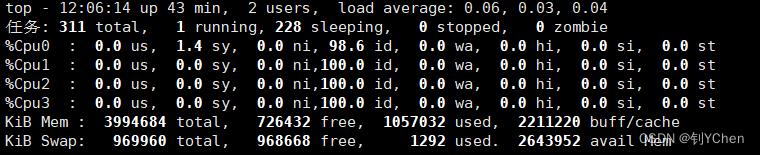
所以在 top 命令查看时,如果发现 CPU 空闲率接近 0,此时的任务就是 CPU 密集型场景了。
2 - 使用 vmstat -w -w 命令:

如图,看最右边 CPU 一项,同样可以查看当前 CPU 的空闲率,在这里是 97%,也就是 CPU 利用率为 3%。
I/O 查看
1 - 使用 top 命令:
我们同样可以使用 top 命令查看 I/O 是否频繁,这里关注 CPU 项的 wa,wa 表示等待输入输出(也就是 I/O)的时间百分比,这一项如果高于 30%,我们可以认定为存在 I/O 瓶颈,也就是当前为 I/O 密集型任务。
2 - 使用 vmstat 命令:
查看其中的 io 项,其中 bi 表示发送到块设备的块数,单位为块/秒,bo 表示从块设备接收到的块数,单位为块/秒。
3 - 使用 iostat 命令:
输入 iostat -x 5,其中 -x 表示更详细信息

查看最后的 util 项表示的是采用周期内用于 I/O 操作的时间比率,即IO队列非空的时间比率,可以用于表示 I/O 繁忙程度。如果 %util 接近 100%,说明产生的 I/O 请求太多,I/O 系统已经满负荷,该磁盘可能存在瓶颈。
总结
总的来说,线程 I/O 时间比例越高,需要越多线程来 overlap 这个 I/O,反之需要越少的线程。
文末介绍了在 Linux 系统中如何查看 CPU 利用率和 I/O 繁忙程度。
同时需要认识到,并不是使用线程池就一定比单线程高效,单线程相比多线程避免了上下文切换时间和锁。因此也可以很高效。
有了以上方法,我们就可以做到在不同业务场景中选择不同的线程池大小了。
场景应用:线程池的队列大小你通常怎么设置?
文章目录
多线程执行的任务类型
1. CPU密集型任务
尽量使用较小的线程池,一般为CPU核心数+1。 因为CPU密集型任务使得CPU使用率很高,若开过多的线程数,会造成CPU过度切换。
2. IO密集型任务
可以使用稍大的线程池,一般为2*CPU核心数。 IO密集型任务CPU使用率并不高,因此可以让CPU在等待IO的时候有其他线程去处理别的任务,充分利用CPU时间。
3. 混合型任务
可以将任务分成IO密集型和CPU密集型任务,然后分别用不同的线程池去处理。 只要分完之后两个任务的执行时间相差不大,那么就会比串行执行来的高效。因为如果划分之后两个任务执行时间有数据级的差距,那么拆分没有意义。
因为先执行完的任务就要等后执行完的任务,最终的时间仍然取决于后执行完的任务,而且还要加上任务拆分与合并的开销,得不偿失。
扩展:线程数量的计算
一般多线程执行的任务类型可以分为 CPU 密集型和 I/O 密集型,根据不同的任务类型,我们计算线程数的方法也不一样。
CPU 密集型任务
CPU 密集型任务:这种任务消耗的主要是 CPU 资源,可以将线程数设置为 N(CPU 核心数)+1,比 CPU 核心数多出来的一个线程是为了防止线程偶发的缺页中断,或者其它原因导致的任务暂停而带来的影响。一旦任务暂停,CPU 就会处于空闲状态,而在这种情况下多出来的一个线程就可以充分利用 CPU 的空闲时间。
当线程数量太小,同一时间大量请求将被阻塞在线程队列中排队等待执行线程,此时 CPU 没有得到充分利用;当线程数量太大,被创建的执行线程同时在争取 CPU 资源,又会导致大量的上下文切换,从而增加线程的执行时间,影响了整体执行效率。
I/O 密集型任务
I/O 密集型任务:这种任务应用起来,系统会用大部分的时间来处理 I/O 交互,而线程在处理 I/O 的时间段内不会占用 CPU 来处理,这时就可以将 CPU 交出给其它线程使用。因此在 I/O 密集型任务的应用中,我们可以多配置一些线程,具体的计算方法是 2N。
在平常的应用场景中,我们常常遇不到这两种极端情况,那么碰上一些常规的业务操作,比如,通过一个线程池实现向用户定时推送消息的业务,我们又该如何设置线程池的数量呢?
此时我们可以参考以下公式来计算线程数:
线程数 =N(CPU 核数)*(1+WT(线程等待时间)/ST(线程时间运行时间))
我们可以通过 JDK 自带的工具 VisualVM 来查看 WT/ST 比例
总结
综合来看,我们可以根据自己的业务场景,从“N+1”和“2N”两个公式中选出一个适合的,计算出一个大概的线程数量,之后通过实际压测,逐渐往“增大线程数量”和“减小线程数量”这两个方向调整,然后观察整体的处理时间变化,最终确定一个具体的线程数量。
以上是关于线程池大小选择:针对 I/O 密集型场景和 CPU 密集型场景的主要内容,如果未能解决你的问题,请参考以下文章