linux内核调试的主要方法
Posted
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了linux内核调试的主要方法相关的知识,希望对你有一定的参考价值。
参考技术A 1。printk ,以及系统日志。阅读源码,想象代码运行的情况,结合打印的信息,推测问题所在。2。内核调试器,例如 Kgdb 。
3。user mode linux 。
4。在虚拟机上调试。例如 Bochs 。
参考资料:http://blog.csdn.net/windhue/archive/2005/03/07/313415.aspx
本回答被提问者采纳Linux下调试方法汇总
一、Linux驱动调试方法
Linux驱动调试主要有以下几种方法:
1、利用printk。
2、查看OOP消息。
3、利用strace。
4、利用内核内置的hacking选项。
5、利用ioctl方法。
6、利用/proc 文件系统。
7、使用kgdb。
1.1、printk
这是驱动开发中最朴实无华,同时也是最常用和有效的手段。scull驱动的main.c第338行如下,就是使用printk进行调试的例子,这样的例子相信大家在阅读驱动源码时随处可见。
338 // printk(KERN_ALERT "wakeup by signal in process %d\\n", current->pid);printk的功能与我们经常在应用程序中使用的printf是一样的,不同之处在于printk可以在打印字符串前面加上内核定义的宏,例如上面例子中的KERN_ALERT(注意:宏与字符串之间没有逗号)。
#define KERN_EMERG "<0>"
#define KERN_ALERT "<1>"
#define KERN_CRIT "<2>"
#define KERN_ERR "<3>"
#define KERN_WARNING "<4>"
#define KERN_NOTICE "<5>"
#define KERN_INFO "<6>"
#define KERN_DEBUG "<7>"
#define DEFAULT_CONSOLE_LOGLEVEL 7
这个宏是用来定义需要打印的字符串的级别。值越小,级别越高。内核中有个参数用来控制是否将printk打印的字符串输出到控制台(屏幕或者/sys/log/syslog日志文件)
# cat /proc/sys/kernel/printk
6 4 1 7第一个6表示级别高于(小于)6的消息才会被输出到控制台,
第二个4表示如果调用printk时没有指定消息级别(宏)则消息的级别为4,
第三个1表示接受的最高(最小)级别是1,
第四个7表示系统启动时第一个6原来的初值是7。
因此,如果你发现在控制台上看不到你程序中某些printk的输出,请使用
echo 8 > /proc/sys/kernel/printk来解决。
我们在复杂驱动的开发过程中,为了调试会在源码中加入成百上千的printk语句。
而当调试完毕形成最终产品的时候必然会将这些printk语句删除。
最要命的是,如果我们将调试用的printk语句删除后,用户又报告我们的驱动有bug,所以我们又不得不手工将这些上千条的printk语句再重新加上。所以,我们需要一种能方便地打开和关闭调试信息的手段。看看scull驱动或者leds驱动的源代码吧!
#define LEDS_DEBUG
#undef PDEBUG /* undef it, just in case */
#ifdef LEDS_DEBUG
#ifdef __KERNEL__
/* This one if debugging is on, and kernel space */
#define PDEBUG(fmt, args…) printk( KERN_EMERG "leds: " fmt, ## args)
#else
/* This one for user space */
#define PDEBUG(fmt, args…) fprintf(stderr, fmt, ## args)
#endif
#else
#define PDEBUG(fmt, args…) /* not debugging: nothing */
#endif
#undef PDEBUGG
#define PDEBUGG(fmt, args…) /* nothing: it’s a placeholder */这样一来,在开发驱动的过程中,如果想打印调试消息,我们就可以用PDEBUG(“address of i_cdev is %p\\n”, inode->i_cdev);,如果不想看到该调试消息,就只需要简单的将PDEBUG改为PDEBUGG即可。而当我们调试完毕形成最终产品时,只需要简单地将第1行注释掉即可。
上边那一段代码中的__KERNEL__是内核中定义的宏,当我们编译内核(包括模块)时,它会被定义。当然如果你不明白代码中的…和##是什么意思的话,就请认真查阅一下gcc关于预处理部分的资料吧!如果你实在太懒不愿意去查阅的话,那就充当VC工程师把上面的代码copy到你的代码中去吧。
1.2、查看OOP消息
OOP意为惊讶。当你的驱动有问题,内核不惊讶才怪:嘿!小子,你干吗乱来!好吧,就让我们来看看内核是如何惊讶的。
根据faulty.c(编译出faulty.ko,并 insmod faulty.ko。执行echo yang >/dev/faulty,结果内核就惊讶了。内核为什么会惊讶呢?因为faulty驱动的write函数执行了*(int *)0 = 0,向内存0地址写入,这是内核绝对不会容许的。
52 ssize_t faulty_write (struct file *filp, const char __user *buf, size_t count,
53 loff_t *pos)
54
55 /* make a simple fault by dereferencing a NULL pointer */
56 *(int *)0 = 0;
57 return 0;
58
1 Unable to handle kernel NULL pointer dereference at virtual address 00000000
2 pgd = c3894000
3 [00000000] *pgd=33830031, *pte=00000000, *ppte=00000000
4 Internal error: Oops: 817 [#1] PREEMPT
5 Modules linked in: faulty scull
6 CPU: 0 Not tainted (2.6.22.6 #4)
7 PC is at faulty_write+0×10/0×18 [faulty]
8 LR is at vfs_write+0xc4/0×148
9 pc : [<bf00608c>] lr : [<c0088eb8>] psr: a0000013
10 sp : c3871f44 ip : c3871f54 fp : c3871f50
11 r10: 4021765c r9 : c3870000 r8 : 00000000
12 r7 : 00000004 r6 : c3871f78 r5 : 40016000 r4 : c38e5160
13 r3 : c3871f78 r2 : 00000004 r1 : 40016000 r0 : 00000000
14 Flags: NzCv IRQs on FIQs on Mode SVC_32 Segment user
15 Control: c000717f Table: 33894000 DAC: 00000015
16 Process sh (pid: 745, stack limit = 0xc3870258)
17 Stack: (0xc3871f44 to 0xc3872000)
18 1f40: c3871f74 c3871f54 c0088eb8 bf00608c 00000004 c38e5180 c38e5160
19 1f60: c3871f78 00000000 c3871fa4 c3871f78 c0088ffc c0088e04 00000000 00000000
20 1f80: 00000000 00000004 40016000 40215730 00000004 c002c0e4 00000000 c3871fa8
21 1fa0: c002bf40 c0088fc0 00000004 40016000 00000001 40016000 00000004 00000000
22 1fc0: 00000004 40016000 40215730 00000004 00000001 00000000 4021765c 00000000
23 1fe0: 00000000 bea60964 0000266c 401adb40 60000010 00000001 00000000 00000000
24 Backtrace:
25 [<bf00607c>] (faulty_write+0×0/0×18 [faulty]) from [<c0088eb8>] (vfs_write+0xc4/0×148)
26 [<c0088df4>] (vfs_write+0×0/0×148) from [<c0088ffc>] (sys_write+0x4c/0×74)
27 r7:00000000 r6:c3871f78 r5:c38e5160 r4:c38e5180
28 [<c0088fb0>] (sys_write+0×0/0×74) from [<c002bf40>] (ret_fast_syscall+0×0/0x2c)
29 r8:c002c0e4 r7:00000004 r6:40215730 r5:40016000 r4:00000004
30 Code: e1a0c00d e92dd800 e24cb004 e3a00000 (e5800000)
1行惊讶的原因,也就是报告出错的原因。
2-4行是OOP信息序号。
5行是出错时内核已加载模块。
6行是发生错误的CPU序号。
7-15行是发生错误的位置,以及当时CPU各个寄存器的值,这最有利于我们找出问题所在地。
16行是当前进程的名字及进程ID。
17-23行是出错时,栈内的内容。
24-29行是栈回溯信息,可看出直到出错时的函数递进调用关系(确保CONFIG_FRAME_POINTER被定义)。
30行是出错指令及其附近指令的机器码,出错指令本身在小括号中。
反汇编faulty.ko( arm-linux-objdump -D faulty.ko > faulty.dis ;cat faulty.dis)可以看到如下的语句如下:
0000007c <faulty_write>:
7c: e1a0c00d mov ip, sp
80: e92dd800 stmdb sp!, fp, ip, lr, pc
84: e24cb004 sub fp, ip, #4 ; 0×4
88: e3a00000 mov r0, #0 ; 0×0
8c: e5800000 str r0, [r0]
90: e89da800 ldmia sp, fp, sp, pc定位出错位置以及获取相关信息的过程:
9 pc : [<bf00608c>] lr : [<c0088eb8>] psr: a0000013
25 [<bf00607c>] (faulty_write+0×0/0×18 [faulty]) from [<c0088eb8>] (vfs_write+0xc4/0×148)
26 [<c0088df4>] (vfs_write+0×0/0×148) from [<c0088ffc>] (sys_write+0x4c/0×74)出错代码是faulty_write函数中的第5条指令((0xbf00608c-0xbf00607c)/4+1=5),该函数的首地址是0xbf00607c,该函数总共6条指令(0×18),该函数是被0xc0088eb8的前一条指令调用的(即:函数返回地址是0xc0088eb8。这一点可以从出错时lr的值正好等于0xc0088eb8得到印证)。调用该函数的指令是vfs_write的第49条(0xc4/4=49)指令。
达到出错处的函数调用流程是:
write(用户空间的系统调用)–>sys_write–>vfs_write–>faulty_write
OOP消息不仅让我定位了出错的地方,更让我惊喜的是,它让我知道了一些秘密:
1、gcc中fp到底有何用处?
2、为什么gcc编译任何函数的时候,总是要把3条看上去傻傻的指令放在整个函数的最开始?
3、内核和gdb是如何知道函数调用栈顺序,并使用函数的名字而不是地址?
4、我如何才能知道各个函数入栈的内容?哈哈,我渐渐喜欢上了让内核惊讶,那就再看一次内核惊讶吧。
执行 cat /dev/faulty,内核又再一次惊讶!
1 Unable to handle kernel NULL pointer dereference at virtual address 0000000b
2 pgd = c3a88000
3 [0000000b] *pgd=33a79031, *pte=00000000, *ppte=00000000
4 Internal error: Oops: 13 [#2] PREEMPT
5 Modules linked in: faulty
6 CPU: 0 Not tainted (2.6.22.6 #4)
7 PC is at vfs_read+0xe0/0×140
8 LR is at 0xffffffff
9 pc : [<c0088c84>] lr : [<ffffffff>] psr: 20000013
10 sp : c38d9f54 ip : 0000001c fp : ffffffff
11 r10: 00000001 r9 : c38d8000 r8 : 00000000
12 r7 : 00000004 r6 : ffffffff r5 : ffffffff r4 : ffffffff
13 r3 : ffffffff r2 : 00000000 r1 : c38d9f38 r0 : 00000004
14 Flags: nzCv IRQs on FIQs on Mode SVC_32 Segment user
15 Control: c000717f Table: 33a88000 DAC: 00000015
16 Process cat (pid: 767, stack limit = 0xc38d8258)
17 Stack: (0xc38d9f54 to 0xc38da000)
18 9f40: 00002000 c3c105a0 c3c10580
19 9f60: c38d9f78 00000000 c38d9fa4 c38d9f78 c0088f88 c0088bb4 00000000 00000000
20 9f80: 00000000 00002000 bef07c80 00000003 00000003 c002c0e4 00000000 c38d9fa8
21 9fa0: c002bf40 c0088f4c 00002000 bef07c80 00000003 bef07c80 00002000 00000000
22 9fc0: 00002000 bef07c80 00000003 00000000 00000000 00000001 00000001 00000003
23 9fe0: 00000000 bef07c6c 0000266c 401adab0 60000010 00000003 00000000 00000000
24 Backtrace: invalid frame pointer 0xffffffff
25 Code: ebffff86 e3500000 e1a07000 da000015 (e594500c)
26 Segmentation fault不过这次惊讶却令人大为不解。OOP竟然说出错的地方在vfs_read(要知道它可是大拿们千锤百炼的内核代码),这怎么可能?哈哈,万能的内核也不能追踪函数调用栈了,这是为什么?其实问题出在faulty_read的43行,它导致入栈的r4、r5、r6、fp全部变为了0xffffffff,ip、lr的值未变,这样一来faulty_read函数能够成功返回到它的调用者——vfs_read。但是可怜的vfs_read(忠实的APTCS规则遵守者)并不知道它的r4、r5、r6已经被万恶的faulty_read改变,这样下去vfs_read命运就可想而知了——必死无疑!虽然内核很有能力,但缺少了正确的fp的帮助,它也无法追踪函数调用栈。
36 ssize_t faulty_read(struct file *filp, char __user *buf,
37 size_t count, loff_t *pos)
38
39 int ret;
40 char stack_buf[4];
41
42 /* Let’s try a buffer overflow */
43 memset(stack_buf, 0xff, 20);
44 if (count > 4)
45 count = 4; /* copy 4 bytes to the user */
46 ret = copy_to_user(buf, stack_buf, count);
47 if (!ret)
48 return count;
49 return ret;
50 00000000 <faulty_read>:
0: e1a0c00d mov ip, sp
4: e92dd870 stmdb sp!, r4, r5, r6, fp, ip, lr, pc
8: e24cb004 sub fp, ip, #4 ; 0×4
c: e24dd004 sub sp, sp, #4 ; 0×4,这里为stack_buf[]在栈上分配1个字的空间,局部变量ret使用寄存器存储,因此就不在栈上分配空间了
10: e24b501c sub r5, fp, #28 ; 0x1c
14: e1a04001 mov r4, r1
18: e1a06002 mov r6, r2
1c: e3a010ff mov r1, #255 ; 0xff
20: e3a02014 mov r2, #20 ; 0×14
24: e1a00005 mov r0, r5
28: ebfffffe bl 28 <faulty_read+0×28> //这里在调用memset
78: e89da878 ldmia sp, r3, r4, r5, r6, fp, sp, pc1.3、利用strace
有时小问题可以通过监视程序监控用户应用程序的行为来追踪,同时监视程序也有助于建立对驱动正确工作的信心。例如,在看了它的读实现如何响应不同数量数据的读请求之后,我们能够对scull正在正确运行感到有信心。
有几个方法来监视用户空间程序运行。你可以运行一个调试器来单步过它的函数,增加打印语句,或者在 strace 下运行程序。这里,我们将讨论最后一个技术,因为当真正目的是检查内核代码时,它是最有用的。
strace 命令是一个有力工具,它能显示所有的用户空间程序发出的系统调用。它不仅显示调用,还以符号形式显示调用的参数和返回值。当一个系统调用失败, 错误的符号值(例如, ENOMEM)和对应的字串(Out of memory) 都显示。
strace 有很多命令行选项,其中最有用的是
-t 来显示每个调用执行的时间,
-T 来显示调用中花费的时间,
-e 来限制被跟踪调用的类型(例如strace –eread,write ls表示只监控read和write调用),
以及-o 来重定向输出到一个文件。缺省情况下,strace 打印调用信息到 stderr。
strace 从内核自身获取信息。这意味着可以跟踪一个程序,不管它是否带有调试支持编译(对 gcc 是 -g 选项)以及不管它是否被strip过。此外,你也可以追踪一个正在运行中的进程,这类似于调试器连接到一个运行中的进程并控制它。
跟踪信息常用来支持发给应用程序开发者的故障报告,但是对内核程序员也是很有价值的。我们已经看到驱动代码运行如何响应系统调用,strace 允许我们检查每个调用的输入和输出数据的一致性。
例如,运行命令strace ls /dev > /dev/scull0将会在屏幕上显示如下的内容:
open("/dev", O_RDONLY|O_NONBLOCK|O_LARGEFILE|O_DIRECTORY) = 3
fstat64(3, st_mode=S_IFDIR|0755, st_size=24576, …) = 0
fcntl64(3, F_SETFD, FD_CLOEXEC) = 0
getdents64(3, /* 141 entries */, 4096) = 4088
[...]
getdents64(3, /* 0 entries */, 4096) = 0
close(3) = 0
[...]
fstat64(1, st_mode=S_IFCHR|0664, st_rdev=makedev(254, 0), …) = 0
write(1, "MAKEDEV\\nadmmidi0\\nadmmidi1\\nadmmid"…, 4096) = 4000
write(1, "b\\nptywc\\nptywd\\nptywe\\nptywf\\nptyx0\\n"…, 96) = 96
write(1, "b\\nptyxc\\nptyxd\\nptyxe\\nptyxf\\nptyy0\\n"…, 4096) = 3904
write(1, "s17\\nvcs18\\nvcs19\\nvcs2\\nvcs20\\nvcs21"…, 192) = 192
write(1, "\\nvcs47\\nvcs48\\nvcs49\\nvcs5\\nvcs50\\nvc"…, 673) = 673
close(1) = 0
exit_group(0) = ?
从第一个 write 调用看, 明显地, 在 ls 结束查看目标目录后,它试图写 4KB。但奇怪的是,只有 4000 字节被成功写入, 并且操作被重复。但当我们查看scull 中的写实现,发现它一次最多只允许写一个quantum(共4000字节),可见驱动本来就是期望部分写。几步之后, 所有东西清空, 程序成功退出。正是通过strace的输出,使我们确信驱动的部分写功能运行正确。
作为另一个例子, 让我们读取 scull 设备(使用 wc scull0 命令):
[...]
open("/dev/scull0", O_RDONLY|O_LARGEFILE) = 3
fstat64(3, st_mode=S_IFCHR|0664, st_rdev=makedev(254, 0), …) = 0
read(3, "MAKEDEV\\nadmmidi0\\nadmmidi1\\nadmmid"…, 16384) = 4000
read(3, "b\\nptywc\\nptywd\\nptywe\\nptywf\\nptyx0\\n"…, 16384) = 4000
read(3, "s17\\nvcs18\\nvcs19\\nvcs2\\nvcs20\\nvcs21"…, 16384) = 865
read(3, "", 16384) = 0
fstat64(1, st_mode=S_IFCHR|0620, st_rdev=makedev(136, 1), …) = 0
write(1, "8865 /dev/scull0\\n", 17) = 17
close(3) = 0
exit_group(0) = ?如同期望的, read 一次只能获取 4000 字节,但是数据总量等同于前个例子写入的。
这个例子,意外的收获是:可以肯定,wc 为快速读进行了优化,它因此绕过了标准库(没有使用fscanf),而是直接一个系统调用以读取更多数据。这一点,可从跟踪到的读的行里看到wc一次试图读取16 KB的数据而确认。
1.4、使用内核内置的hacking选项
内核开发者在make menuconfig的Kernel hacking提供了一些内核调试选项。这些选项有助于我们调试驱动程序,因为当我们启用某些调试选项的时候,操作系统会在发现驱动运行有问题时给出一些错误提示信息,而这些信息非常有助于驱动开发者找出驱动中的问题所在。下面就举几个简单例子。
先启用如下选项:
General setup — Configure standard kernel features (for small systems) — Load all symbols for debugging/ksymoops (NEW)
Kernel hacking — Kernel debugging
Device Drivers — Generic Driver Options — Driver Core verbose debug messages
1、Kernel debugging — Spinlock and rw-lock debugging: basic checks (NEW)可以检查到未初始化的自旋锁
2、Kernel debugging — Mutex debugging: basic checks (NEW) 可以检查到未初始化的信号量
717 //init_MUTEX(&scull_devices[i].sem);例如,如果我们忘记了初始化scull驱动中的信号量(将main.c的第717行注释掉),则在open设备scull时只会产生OOP,而没有其它信息提示我们有信号量未初始化,因此此时我们很难定位问题。相反,如果启用了上述选项,操作系统则会产生相关提示信息,使我们知道有未初始化的信号量或者自旋锁。从而,我们就可以去驱动代码中初始化信号量和自旋锁的地方修正程序。
这个测试,我们的意外收获是:信号量的实现,其底层仍然是自旋锁。这与我们之前的大胆推测一致。
process 751 enter scull_open
BUG: spinlock bad magic on CPU#0, sh/751
lock: c38ac1e4, .magic: 00000000, .owner: <none>/-1, .owner_cpu: 0
[<c002fe70>] (dump_stack+0×0/0×14) from [<c0130b5c>] (spin_bug+0×90/0xa4)
[<c0130acc>] (spin_bug+0×0/0xa4) from [<c0130b98>] (_raw_spin_lock+0×28/0×160)
r5:40000013 r4:c38ac1e4
[<c0130b70>] (_raw_spin_lock+0×0/0×160) from [<c025276c>] (_spin_lock_irqsave+0x2c/0×34)
[<c0252740>] (_spin_lock_irqsave+0×0/0×34) from [<c0053d28>] (add_wait_queue_exclusive+0×24/0×50)
r5:c38ac1e4 r4:c38a1e1c
[<c0053d04>] (add_wait_queue_exclusive+0×0/0×50) from [<c024fcf0>] (__down_interruptible+0x5c/0x16c)
r5:c38a0000 r4:c38ac1dc
[<c024fc94>] (__down_interruptible+0×0/0x16c) from [<c024fb4c>] (__down_interruptible_failed+0xc/0×20)
[<bf000530>] (scull_open+0×0/0xd8 [scull]) from [<c0088eb8>] (chrdev_open+0x1b4/0x1d8)
r6:c3ef0300 r5:c38ac1fc r4:bf0045a0Kernel debugging — Spinlock debugging: sleep-inside-spinlock checking (NEW) 可以检查出驱动在获取自旋锁后又睡眠以及死锁等状况
345 ssleep(5);
87 #define usespin
例如,如果第1个进程在获得自旋锁的情况下睡眠(去掉main.c第345行的注释,去掉scull.h第87行的注释),当第2个进程试图获得自旋锁时将死锁系统。但如果启用了上面的选项,则在死锁前操作系统可以给出提示信息。
process 763 enter read
semphore get, and begin sleep 5 second in process 763
BUG: scheduling while atomic: cat/0×00000001/763
[<c002fe70>] (dump_stack+0×0/0×14) from [<c024fe64>] (schedule+0×64/0×778)
[<c024fe00>] (schedule+0×0/0×778) from [<c02510a8>] (schedule_timeout+0x8c/0xbc)
process 764 enter read
BUG: spinlock cpu recursion on CPU#0, cat/764
lock: c3ae7014, .magic: dead4ead, .owner: cat/763, .owner_cpu: 0
[<c002fe70>] (dump_stack+0×0/0×14) from [<c0130b5c>] (spin_bug+0×90/0xa4)
[<c0130acc>] (spin_bug+0×0/0xa4) from [<c0130bcc>] (_raw_spin_lock+0x5c/0×160)
r5:beed2c70 r4:c3ae7014
[<c0130b70>] (_raw_spin_lock+0×0/0×160) from [<c025273c>] (_spin_lock+0×20/0×24)
[<c025271c>] (_spin_lock+0×0/0×24) from [<bf000610>] (scull_read+0×64/0×210 [scull])
r4:c3949520
[<bf0005ac>] (scull_read+0×0/0×210 [scull]) from [<c0085eac>] (vfs_read+0xc0/0×140)
BUG: spinlock lockup on CPU#0, cat/764, c3ae7014
[<c002fe70>] (dump_stack+0×0/0×14) from [<c0130c94>] (_raw_spin_lock+0×124/0×160)
[<c0130b70>] (_raw_spin_lock+0×0/0×160) from [<c025273c>] (_spin_lock+0×20/0×24)
[<c025271c>] (_spin_lock+0×0/0×24) from [<bf000610>] (scull_read+0×64/0×210 [scull])
r4:c3949520
[<bf0005ac>] (scull_read+0×0/0×210 [scull]) from [<c0085eac>] (vfs_read+0xc0/0×140)
Magic SysRq key可以在已经死锁的情况下,打印一些有助于定位问题的信息。
魔键 sysrq在大部分体系上都可用,它是用PC 键盘上 alt 和 sysrq 键组合来发出的, 或者在别的平台上使用其他特殊键(详见 documentation/sysrq.txt), 在串口控制台上也可用。
一个第三键, 与这2 个一起按下, 进行许多有用的动作中的一个:
r 关闭键盘原始模式; 用在一个崩溃的应用程序( 例如 X 服务器 )可能将你的键盘搞成一个奇怪的状态.
k 调用"安全注意键"( SAK ) 功能. SAK 杀掉在当前控制台的所有运行的进程, 给你一个干净的终端.
s 进行一个全部磁盘的紧急同步.
u umount. 试图重新加载所有磁盘在只读模式. 这个操作, 常常在 s 之后马上调用, 可以节省大量的文件系统检查时间, 在系统处于严重麻烦时.
b boot. 立刻重启系统. 确认先同步和重新加载磁盘.
p 打印处理器消息.
t 打印当前任务列表.
m 打印内存信息.例如,在系统死锁的情况下,期望能知道寄存器的值,则可以使用该魔法键。
SysRq : Show Regs
Pid: 764, comm: cat
CPU: 0 Not tainted (2.6.22.6 #6)
PC is at _raw_spin_lock+0xbc/0×160
LR is at _raw_spin_lock+0xcc/0×160
pc : [<c0130c2c>] lr : [<c0130c3c>] psr: 60000013
sp : c3b11ecc ip : c3b11e08 fp : c3b11efc
r10: c3b10000 r9 : 00000000 r8 : 055b131f
r7 : c3ae7014 r6 : 00000000 r5 : 05f1e000 r4 : 00000000
r3 : 00000000 r2 : c3b10000 r1 : 00000001 r0 : 00000001
Flags: nZCv IRQs on FIQs on Mode SVC_32 Segment user
Control: c000717f Table: 33b48000 DAC: 00000015
[<c002cdb0>] (show_regs+0×0/0x4c) from [<c015ab00>] (sysrq_handle_showregs+0×20/0×28)
r4:c0310c34
[<c015aae0>] (sysrq_handle_showregs+0×0/0×28) from [<c015ad50>] (__handle_sysrq+0xa0/0×148)
[<c015acb0>] (__handle_sysrq+0×0/0×148) from [<c015ae28>] (handle_sysrq+0×30/0×34)
[<c015adf8>] (handle_sysrq+0×0/0×34) from [<c016477c>] (s3c24xx_serial_rx_chars+0x1b0/0x2d4)
r5:00000000 r4:c03111e4
[<c01645cc>] (s3c24xx_serial_rx_chars+0×0/0x2d4) from [<c0061474>] (handle_IRQ_event+0×44/0×80)
[<c0061430>] (handle_IRQ_event+0×0/0×80) from [<c00629a8>] (handle_level_irq+0xd0/0×134)
r7:c03073e8 r6:c3e52940 r5:00000046 r4:c03073bc
[<c00628d8>] (handle_level_irq+0×0/0×134) from [<c0038118>] (s3c_irq_demux_uart+0×50/0×90)
r7:00000000 r6:00000046 r5:00000001 r4:c03073bc
[<c00380c8>] (s3c_irq_demux_uart+0×0/0×90) from [<c003816c>] (s3c_irq_demux_uart0+0×14/0×18)
r6:c0336650 r5:0000002c r4:c0306cd4
[<c0038158>] (s3c_irq_demux_uart0+0×0/0×18) from [<c002b044>] (asm_do_IRQ+0×44/0x5c)
[<c002b000>] (asm_do_IRQ+0×0/0x5c) from [<c002ba78>] (__irq_svc+0×38/0xb0)
Exception stack(0xc3b11e84 to 0xc3b11ecc)
1e80: 00000001 00000001 c3b10000 00000000 00000000 05f1e000 00000000
1ea0: c3ae7014 055b131f 00000000 c3b10000 c3b11efc c3b11e08 c3b11ecc c0130c3c
1ec0: c0130c2c 60000013 ffffffff
r7:00000002 r6:10000000 r5:f0000000 r4:ffffffff
[<c0130b70>] (_raw_spin_lock+0×0/0×160) from [<c025273c>] (_spin_lock+0×20/0×24)
[<c025271c>] (_spin_lock+0×0/0×24) from [<bf000610>] (scull_read+0×64/0×210 [scull])
r4:c3949520
[<bf0005ac>] (scull_read+0×0/0×210 [scull]) from [<c0085eac>] (vfs_read+0xc0/0×140)
[<c0085dec>] (vfs_read+0×0/0×140) from [<c00861d0>] (sys_read+0x4c/0×74)
r7:00000000 r6:c3b11f78 r5:c3949520 r4:c3949540
[<c0086184>] (sys_read+0×0/0×74) from [<c002bf00>] (ret_fast_syscall+0×0/0x2c)
r8:c002c0a4 r7:00000003 r6:00000003 r5:beed2c70 r4:00002000
Debug shared IRQ handlers可用于调试共享中断
1.5、利用ioctl方法
由于驱动中的ioctl函数可以将驱动的一些信息返回给用户程序,也可以让用户程序通过ioctl系统调用设置一些驱动的参数。
所以在驱动的开发过程中,可以扩展一些ioctl的命令用于传递和设置调试驱动时所需各种信息和参数,以达到调试驱动的目的。如何在驱动中实现ioctl,请参见“驱动程序对ioctl的规范实现”一文
1.6、利用/proc 文件系统
/proc文件系统用于内核向用户空间暴露一些内核的信息。因此出于调试的目的,我们可以在驱动代码中增加向/proc文件系统导出有助于监视驱动的信息的代码。
这样一来,我们就可以通过查看/proc中的相关信息来监视和调试驱动。如何在驱动中实现向/proc文件系统导出信息,请参见《Linux Device Driver》的4.3节。
1.7、使用kgdb
kgdb是在内核源码中打用于调试内核的补丁,然后通过相应的硬件和软件,就可以像gdb单步调试应用程序一样来调试内核(当然包括驱动)。
至于kgdb如何使用,就请你google吧,实在不行,必应一下也可以。
二、linux应用调试方法
2.1、'printf' 语句
这是一个基本的调试问题的方法。 我们在程序中怀疑的地方插入print语句来了解程序的运行流程控制流和变量值的改变。 这是一个最简单的技术, 它的缺点。 需要进行程序编辑,添加'print'语句,必须重新编译,重新运行来获得输出。若需要调试的程序比较大,这将是一个耗时费力的方法。
2.2、strace
strace拦截和记录系统调用及其接收的信号。对于用户,它显示了系统调用、传递给它们的参数和返回值。strace的可以附着到已在运行的进程或一个新的进程。它作为一个针对开发者和系统管理员的诊断、调试工具是很有用的。它也可以用来当做一个通过跟踪不同的程序调用来了解系统的工具。这个工具的好处是不需要源代码,程序也不需要重新编译。
使用strace的基本语法是:strace 命令
strace有各种各样的参数。可以检查看strace的手册页来获得更多的细节。 strace的输出非常长,我们通常不会对显示的每一行都感兴趣。我们可以用'-e expr'选项来过滤不想要的数据。
用 '-p pid' 选项来绑到运行中的进程.
用'-o'选项,命令的输出可以被重定向到文件。
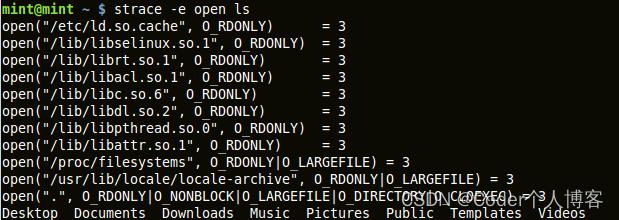
转存失败重新上传取消
2.3、ltrace
ltrace跟踪和记录一个进程的动态(运行时)库的调用及其收到的信号。它也可以跟踪一个进程所作的系统调用。它的用法是类似与strace。
ltrace command
'-i' 选项在调用库时打印指令指针。
'-S' 选项被用来现实系统调用和库调用
所有可用的选项请参阅ltrace手册。
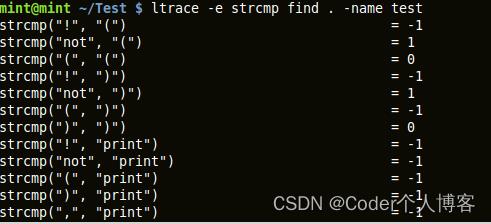
转存失败重新上传取消
2.4、Valgrind
Valgrind是一套调试和分析工具。它的一个被广泛使用的默认工具——'Memcheck'——可以拦截malloc(),new(),free()和delete()调用。换句话说,它在检测下面这些问题非常有用:
1、内存泄露
2、重释放
3、访问越界
4、使用未初始化的内存
5、使用已经被释放的内存等。
它直接通过可执行文件运行。
Valgrind也有一些缺点,因为它增加了内存占用,会减慢你的程序。它有时会造成误报和漏报。它不能检测出静态分配的数组的访问越界问题。
valgrind –tool=memcheck –leak-check=yes test
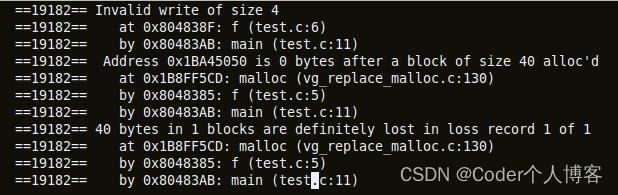
转存失败重新上传取消
valgrind显示堆溢出和内存泄漏的输出
正如我们在上面看到的消息,我们正在试图访问函数f未分配的内存以及分配尚未释放的内存。
2.5、GDB
GDB是来自自由软件基金会的调试器。它对定位和修复代码中的问题很有帮助。当被调试的程序运行时,它给用户控制权去执行各种动作, 比如:
1、启动程序
2、停在指定位置
3、停在指定的条件
4、检查所需信息
5、改变程序中的数据 等。
你也可以将一个崩溃的程序coredump附着到GDB并分析故障的原因。
GDB提供很多选项来调试程序。 然而,我们将介绍一些重要的选择,来感受如何开始使用GDB。
如果你还没有安装GDB,可以在这里下载:GDB官方网站。
三、Linux性能问题定位
3.1、基本流程
如果你在Linux下碰到比较复杂的性能问题,记住,按照下面的4步走,会让你解决linux性能问题的时候事半功倍。
1、先用top命令看linux系统总体的cpu使用情况。如果有异常,用pidstat -u查看细粒度的各个进程的cpu使用情况;否则,转向下一步。
2、用vmstat命令查看linux系统总体的内存使用情况。如果有异常,用smem查看细粒度的各个进程的内存使用情况;否则,转向下一步。
3、用iostat命令查看linux系统总体的IO使用情况。如果有异常,用iotop查看细粒度的各个进程的IO使用情况;否则,转向下一步。
4、用iftop命令查看linux系统总体的网络使用情况。如果有异常,用nethogs查看细粒度的各个进程的网络带宽使用情况。
3.2、常用工具
Linux下应用程序的cpu使用率较高,如何找到是哪段代码引起的?给你介绍这5个linux工具试试看!
1、先看整体。通过top命令查看linux系统整体的cpu使用率和整体的平均负载;
2、然后再看进程个体。通过pidstat -u 1查看linux下各个进程的cpu使用率,找到可疑进程;
3、pstree -p pid查看进程的继承关系,这一步是可选的,但可以让我们清楚了解进程的族谱;
4、strace -f -p pid 追踪进程的系统调用情况,确认是否存在频繁的系统调用?如果存在,就说明找到了根本原因;否则,继续下一步;
5、pstack pid显示应用程序的实时的函数调用堆栈,从而找出性能瓶颈点;
以上是关于linux内核调试的主要方法的主要内容,如果未能解决你的问题,请参考以下文章
Vmware+gdb调试Linux内核——工欲善其事,必先利其器