多因子模型用啥数据
Posted
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了多因子模型用啥数据相关的知识,希望对你有一定的参考价值。
多因子模型是用来解释资产或投资组合的收益率的一种统计模型。它的输入数据包括两部分:1. 因子数据:多因子模型基于一系列不同的因素来解释资产或投资组合的收益率。这些因素包括宏观经济指标(如通货膨胀率、利率、就业率等)、公司基本面(如市盈率、市净率、壳牌油气分类行业等)以及其他特定因素(如股票的市值、风险、动量等)。因子数据可以通过公开数据源(如政府机构、金融机构、研究机构等)获取,也可以通过专业数据提供商(如Bloomberg、Factset、Thomson Reuters等)提供。
2. 资产或投资组合数据:多因子模型需要计算每个资产或投资组合的收益率,并与因子数据进行对比。资产或投资组合的收益率可以从各种数据来源中获取,例如财务报告、证券交易所数据、专业数据提供商等。
需要注意的是,多因子模型的结果可以受到数据质量的影响,因此在使用多因子模型之前,需要对数据进行审核和清洗,确保其准确性和可靠性。同时还需要考虑因子选取的问题,选择哪些因子和如何加权这些因子是多因子模型中的关键问题。 参考技术A 多因子模型使用多个因素数据进行分析,数据可以是从金融投资交易中收集的价格、交易量、市场情绪等信息,或者是从其他行业的统计数据,如气候、政治、经济、社会等信息,也可以是从机器学习、人工智能等技术中获取的数据。多因子模型把所有的因素数据融合到一起,然后进行模型拟合和预测,以满足分析师的需求。
2种方法筛选出多因子量化选股模型
多因子选股模型在模型搭建中,往往会涉及到非常多的股价影响因子,并可能导出数量极多的备选模型。因此,对于多因子选股模型的评价和筛选,就显得尤为关键。
对于专业的量化投资人而言,就需要进一步了解多因子选股模型的两种主要的评价判断方法——打分法和回归法。
打分法的评价原理和流程
所谓打分法,就是根据各个因子的大小对股票进行打分,然后按照一定的权重加权得到一个总分,最后根据总分再对股票进行筛选。
对于多因子模型的评价而言,实际通过评分法回测出的股票组合收益率,就能够对备选的选股模型做出优劣评价。
打分法的优点是相对比较稳健,不容易受到极端值的影响。但是打分法需要对各个因子的权重做一个相对比较主观的设定,这也是打分法在实际模型评价过程中,比较困难和需要模型求取的关键点所在。
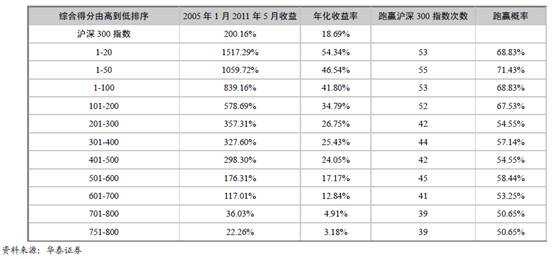
华泰证券在2011年对中证800指数成份股在2005年1月至2011年5月的走势,构造了一个等权重多因子策略。
选股因子包括:总市值、市盈率TTM、营业利润同比增长率、净资产收益率、前1个月涨跌幅、前1个月日均换手率、前1个月波动率、户均持股比例变化、机构持股变化、最近1个月净利润上调幅度等10个因子。
这10个因子按等权重的方式,计算各股票的综合得分。按各指标排序,把800只成份股分成:(1-50)、(1-100)、(101-200)、(201-300)、(301-400)、(401-500)、(501-600)、(601-700)、(701-800)、((751-800)等10个组合;股票组合调整周期为月,每月最后一个交易日收盘后构建下一期的组合。
以下就是按照上述10个因子等权重方式,回测出的各档股票组合收益率情况。
进一步从打分法的流程来看,多因子选股模型的建立、评价和改进流程,大致可以分为4个步骤,见下图。
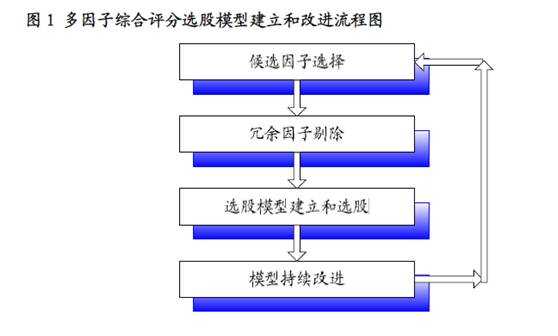
此外,对于量化选股打分法,专业人士还提示指出,一方面,多因子选股模型中有的因子会逐渐失效,而另一些新的因子可能被验证有效而加入到模型当中;
另一方面,一些因子可能在过去的市场环境下比较有效,而随着市场风格的改变,这些因子可能短期内失效。
在这种情况下,对综合评分选股模型的使用过程中,需要对选用的因子、模型本身做持续的再评价和不断的改进以适应变化的市场环境。
除此之外,在计算综合评分的过程中,除了各因子得分的权重设计之外,交易成本和风险控制等因素,也同样需要予以综合考量。
多元线性回归
所谓回归法,就是用过去的股票的收益率对多因子进行回归,得到一个回归方程,然后再把最新的因子值代入回归方程得到一个对未来股票收益的预判,然后再以此为依据进行选股,并对选股模型的有效性和收益率进行评价。
回归法的优点是能够比较及时地调整股票对各因子的敏感性,而且不同的股票对不同的因子的敏感性也可以不同。
回归法的缺点,则是容易受到极端值的影响,在股票对因子敏感度变化较大的市场情况下效果也比较差。
在线性回归分析中,如果有两个或两个以上的自变量,就称为多元线性回归。因此,通过多元线性回归对多因子选股模型进行评价,也能够得到一个直观的股票组合收益率结果,同时能够有效评价该选股模型的优劣。
从数学的角度来说,假设因变量Y(预期收益率)是自变量X1,X2,X3..Xk(候选因子)的线性函数,用方程来表示就是:
Yi=β0+β1X1i+β2X2i+...+βkXki+εi
其中,Yi表示因变量(被解释变量)的第i个观测值,而Xki则是第k个自变量(解释变量)的第i个观测值,是自变量Xk的系数,εi是第i组观测值的残差项。在金融领域,β0有时候会写成α,该方程来表示也可以写作:
Yi=α+β1X1i+β2X2i+...+βkXki+εi
在此之中,多元线性回归通常采用普通最小二乘法(OLS)进行估计,普通最小二乘估计法的思路是改变β0,β1,β2,...,βk,使得残差的平方和最小。
从回归法的流程来看,多因子选股模型的建立、评价和改进流程,大致可以分为6个步骤,见下图。
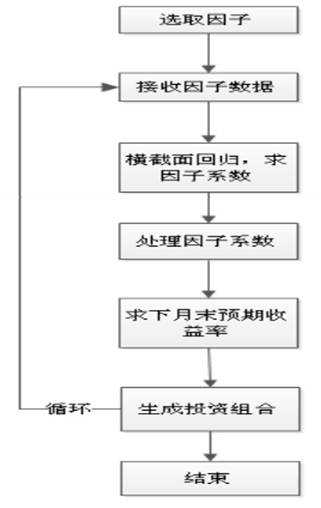
写在最后:今天分享的两种方法,不如自己测试看看,参考使用在自己的实战交易系统。
来源:量化投资俱乐部
-------------------------------------------------------------------
推荐阅读:量化投资 双均线策略 多因子选股 网格交易 海龟交易法 日内交易
以上是关于多因子模型用啥数据的主要内容,如果未能解决你的问题,请参考以下文章
图像识别技术能否用于投资?——基于PCANet的价值成长多因子选股模型