量化交易——因子选股多因子选股策略
Posted xiugeng
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了量化交易——因子选股多因子选股策略相关的知识,希望对你有一定的参考价值。
一、因子选股策略
1、因子
因子:选择股票的某种标准。因子是能够预测股票收益的变量。
(1)基本面因子
基本面因子描述了一个公司的财务状况,最常见的基本面因子是由利润表,资产负债表以及现金流量表中的数据直接计算出的比率。通过财务报表可以构建出无数的财务比率及财务报表变量的组合,并以此来预测股票的收益率。
一般将基本面因子分为6小类:估值因子、偿债能力因子、营运效率因子、盈利能力因子、财务风险因子以及流动性风险因子。
(2)技术面因子
大多数技术面因子是由过去的价格、成交量以及其他可获得的金融信息所构建的,技术面因子一大优势是能够持续更新。新的基本面数据最多只能按季度获取,相反,最新的技术指标每隔几秒就可以获得。
(3)经济因子
最初的套利定价模型是基于经济指标来构建的。比较流行的经济因子包括:GDP增速、失业率以及通货膨胀率等,它们几乎会影响到市场的每一个角落。
(4)其他因子
其他因子的类型包括但不限于:分析师预测因子、事件驱动因子。
2、选股策略(策略模型)
对于某个因子,选取表现最好(因子最大或最小)的N支股票持仓。
每隔一段时间调仓一次。
3、小市场策略
选取股票池中市值最小的N只股票持仓。
二、聚宽实现因子选股策略——小市值策略
沪深300中,根据市值最小的20只股票选股:
# 初始化函数,设定基准等等 def initialize(context): # 设定沪深300作为基准 set_benchmark(‘000300.XSHG‘) # 开启动态复权模式(真实价格) set_option(‘use_real_price‘, True) # 输出内容到日志 log.info() log.info(‘初始函数开始运行且全局只运行一次‘) # 股票类每笔交易时的手续费是:买入时佣金万分之三,卖出时佣金万分之三加千分之一印花税, 每笔交易佣金最低扣5块钱 set_order_cost(OrderCost(close_tax=0.001, open_commission=0.0003, close_commission=0.0003, min_commission=5), type=‘stock‘) # 获取指数成份股 g.security = get_index_stocks(‘000300.XSHG‘) # valuation:财务数据表,code是对应的股票代码 # 这里不能使用 in 操作, 要使用in_()函数,找到沪深300股份对应的财务数据 g.q = query(valuation).filter(valuation.code.in_(g.security)) g.N = 20 # 20只股票 run_monthly(handle, 1) # 第一个参数是对应的函数,第二个参数指第几个交易日 def handle(context): df = get_fundamentals(g.q)[[‘code‘, ‘market_cap‘]] # 花式索引选出股票代码和市值 df = df.sort_values("market_cap").iloc[:g.N,:] # pandas排序函数,将数据集依照某个字段中的数据进行排序 # 期待持有的股票 to_hold = df[‘code‘].values for stock in context.portfolio.positions: if stock not in to_hold: # 目标股数下单,卖出非标的的股票 order_target(stock, 0) # 期待持有且还未持仓的股票 to_buy = [stock for stock in to_hold if stock not in context.portfolio.positions] if len(to_buy) > 0: # 需要调仓 # 每只股票预计投入的资金 cash_per_stock = context.portfolio.available_cash / len(to_buy) for stock in to_buy: # 按价值下单,买入需买入的股票 order_value(stock, cash_per_stock)
执行效果:
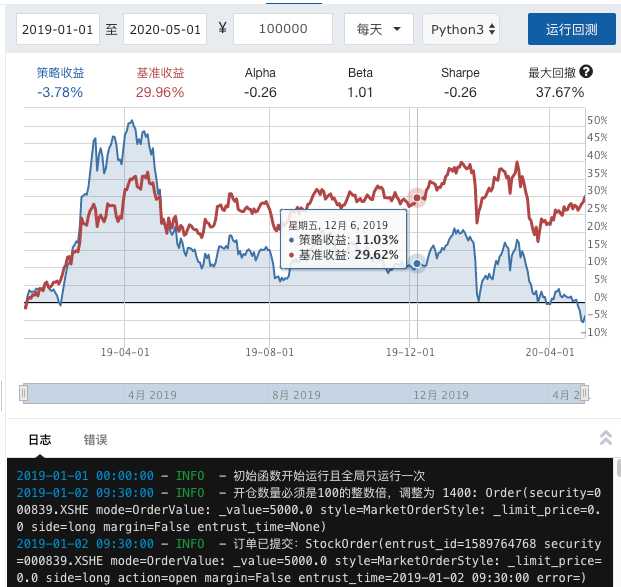
这个策略在短线情况下表现一般,长线情况下效果不错。
1、查询财务数据
查询财务数据,详细数据字段描述见:财务数据文档
get_fundamentals(query_object, date=None, statDate=None)
(1)参数介绍
query_object:一个sqlalchemy.orm.query.Query对象, 可以通过全局的 query 函数获取 Query 对象;
date:查询日期, 一个字符串(格式类似‘2015-10-15‘)或者[datetime.date]/[datetime.datetime]对象, 可以是None, 使用默认日期. 这个默认日期在回测和研究模块上有点差别:
- 回测模块: 默认值会随着回测日期变化而变化, 等于 context.current_dt 的前一天(实际生活中我们只能看到前一天的财报和市值数据, 所以要用前一天)
- 研究模块: 使用平台财务数据的最新日期, 一般是昨天。如果传入的date不是交易日,则使用这个日期之前的最近的一个交易日。
statDate:财报统计的季度或者年份, 一个字符串, 有两种格式:
- 季度: 格式是: 年 + ‘q‘ + 季度序号, 例如: ‘2015q1‘, ‘2013q4‘.
- 年份: 格式就是年份的数字, 例如: ‘2015‘, ‘2016‘.
(2)date和statDate参数只能传入一个
传入date时, 查询指定日期date收盘后所能看到的最近(对市值表来说, 最近一天, 对其他表来说, 最近一个季度)的数据, 我们会查找上市公司在这个日期之前(包括此日期)发布的数据, 不会有未来函数.
传入statDate时, 查询 statDate 指定的季度或者年份的财务数据.
(3)执行示例
def initialize(context): # 设定沪深300作为基准 set_benchmark(‘000300.XSHG‘) # 开启动态复权模式(真实价格) set_option(‘use_real_price‘, True) # 输出内容到日志 log.info() log.info(‘初始函数开始运行且全局只运行一次‘) # 股票类每笔交易时的手续费是:买入时佣金万分之三,卖出时佣金万分之三加千分之一印花税, 每笔交易佣金最低扣5块钱 set_order_cost(OrderCost(close_tax=0.001, open_commission=0.0003, close_commission=0.0003, min_commission=5), type=‘stock‘) # 获取指数成份股 g.security = get_index_stocks(‘000300.XSHG‘) # valuation:财务数据表,code是对应的股票代码 # 这里不能使用 in 操作, 要使用in_()函数,找到沪深300股份对应的财务数据 g.q = query(valuation).filter(valuation.code.in_(g.security)) g.N = 20 # 20只股票 run_monthly(handle, 1) # 第一个参数是对应的函数,第二个参数指第几个交易日 def handle(context): df = get_fundamentals(g.q)[[‘code‘, ‘market_cap‘]] # 花式索引选出股票代码和市值 df = df.sort_values("market_cap").iloc[:g.N,:] # pandas排序函数,将数据集依照某个字段中的数据进行排序 print(df)
每月执行一次找出市值最低的20只股票,执行效果:
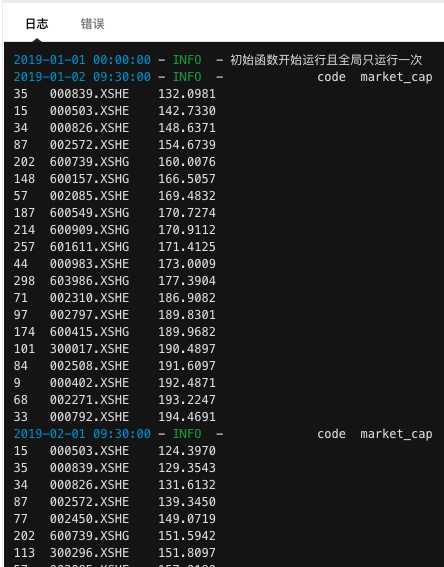
2、每30天执行一次
(1)基于handle_data实现
# 初始化函数,设定基准等等 def initialize(context): # 设定沪深300作为基准 set_benchmark(‘000300.XSHG‘) # 开启动态复权模式(真实价格) set_option(‘use_real_price‘, True) # 输出内容到日志 log.info() log.info(‘初始函数开始运行且全局只运行一次‘) # 股票类每笔交易时的手续费是:买入时佣金万分之三,卖出时佣金万分之三加千分之一印花税, 每笔交易佣金最低扣5块钱 set_order_cost(OrderCost(close_tax=0.001, open_commission=0.0003, close_commission=0.0003, min_commission=5), type=‘stock‘) # 获取指数成份股 g.security = get_index_stocks(‘000300.XSHG‘) # valuation:财务数据表,code是对应的股票代码 # 这里不能使用 in 操作, 要使用in_()函数,找到沪深300股份对应的财务数据 g.q = query(valuation).filter(valuation.code.in_(g.security)) g.days = -1 # 加1后,可第一天就执行 def handle_data(context, data): g.days += 1 if g.days % 30 == 0: # 每30天执行一次 # code
(2)基于定时运行策略实现
三种定时运行策略:run_daily/run_weekly/run_monthly。
# 初始化函数,设定基准等等 def initialize(context): # 设定沪深300作为基准 set_benchmark(‘000300.XSHG‘) # 开启动态复权模式(真实价格) set_option(‘use_real_price‘, True) # 输出内容到日志 log.info() log.info(‘初始函数开始运行且全局只运行一次‘) # 股票类每笔交易时的手续费是:买入时佣金万分之三,卖出时佣金万分之三加千分之一印花税, 每笔交易佣金最低扣5块钱 set_order_cost(OrderCost(close_tax=0.001, open_commission=0.0003, close_commission=0.0003, min_commission=5), type=‘stock‘) # 获取指数成份股 g.security = get_index_stocks(‘000300.XSHG‘) # valuation:财务数据表,code是对应的股票代码 # 这里不能使用 in 操作, 要使用in_()函数,找到沪深300股份对应的财务数据 g.q = query(valuation).filter(valuation.code.in_(g.security)) run_monthly(handle, 1) # 第一个参数是对应的函数,第二个参数指第几个交易日 def handle(context): print("Hello")
2019-1-1到2019-6-30执行效果:
2019-01-01 00:00:00 - INFO - 初始函数开始运行且全局只运行一次 2019-01-02 09:30:00 - INFO - Hello 2019-02-01 09:30:00 - INFO - Hello 2019-03-01 09:30:00 - INFO - Hello 2019-04-01 09:30:00 - INFO - Hello 2019-05-06 09:30:00 - INFO - Hello 2019-06-03 09:30:00 - INFO - Hello
三、多因子选股策略
1、如何同时综合多个因子来选股
多因子选股模型的建立过程主要分为候选因子的选取、选股因子有效性的检验、有效但冗余囚子的剔除、综合评分模型的建立和模型的评价及持续改进5个步骤。
候选因子的选取:候选因子可能是一些基本面指标,如PB、PE、EPS增长率等,也可能是一些技术面指标,如动量、换手率、波动等;或者是其他指标,如预期收益增长、分析师一致预期变化、宏观经济变量等。候选因子的选择主要依赖于经济逻辑和市场经验,但选择更多和更有效的因了无疑是增强模型信息捕获能力,提高收益的关键因素之一。
选股因子有效性检验:检验方法主要采用排序的方法检验候选因子的选股有效性。对于任意一个候选因子,在模型形成期的第一个月初开始计算市场中每只正常交易股票的该因子的大小,按从小到大的顺序对样本股票进行排序,并平均分为n个组合,一直持有到月末,在下月初再按同样的方法重新构建n个组合并持有到月末,每月如此,一直重复到模型形成期末。组合构建完毕后,计算这n个组合的年化复合收益、相对于业绩基准的超出收益、在不同市场状况下的高收益组合跑赢基准和低收益组合跑输基准的概率等。
综合评分模型的建立:综合评分模型迭取去除冗余后的有效因子,在模型运行期的每个月初对市场中正常交易的个股计算每个因子的最新得分,并按照一定的权重求得所有因子的平均分。如果有的因子在某些月份可能无法取值(例如,有的个股因缺少分析师预期数据无法计算预期相关因子),那么按剩下的因了分值求加权平均。最后,根据模型所得出的综合平均分对股票进行排序,然后根据需要选择排名靠前的股票。例如,选取得分最高的前20%股票,或者选取得分最高的50~100只股票等。
模型的评价及持续改进:一方面,由于量选股方法是建立在市场无效或弱有效的前提之下,随着使用多因子选股模型的投资者数量的不断增加,有的因子会逐渐失效,而另一些新的因素可能被验证有效而加入到模型中;另一方面,一些因子可能在过去的市场环境下比较有效,而随着市场风格的改变,这些因子可能短期内失效,而另外一些以前无效的因子会在当前市场环境下表现较好。另外,计算综合评分的过程中,各因子得分的权重设计、交易成本考虑和风险控制等都存在进一步改进的空间。因此在综合评分选股模型的使用过程中,会对选用的因子、模型本身做持续再评价和不断改进以适应变化的市场环境。
2、评分模型
每个股票针对每个因子进行评分,将评分相加;
选出总评分最大的N只股票持仓;
如何计算股票在某个因子下的评分:归一化(标准化)。
3、数据预处理——归一化/标准化/正则化
对于多因子策略,不同因子的量纲和数量级不同,为实现不同指标的可加性,需要对原始指标数据进行标准化处理。
(1)数据标准化方法分类
直线型:极值法、标准差法
折线型:三折线法
曲线型:半正态性分布
(2)数据标准化处理
数据同趋化:主要解决不同性质数据问题,使所有指标对评测方案的作用力同趋化
无量纲化:主要解决数据的可比性
数据标准化原理是将数据按比例缩放,使所有数据落入一个小的特定区间。最常见的就是归一化,将数据统一映射到[0,1]之间。
归一化是标准化的特例,标准化是特征缩放的特例。
(3)数据标准化方法
1)最小-最大标准化(Min-max normalization)
min-max标准化又称为离差标准化,是常见的归一化处理。将原始数据转化为一个0到1的数。
- 获取因子值最大值max,最小值min;
- 对数据进行线性变化
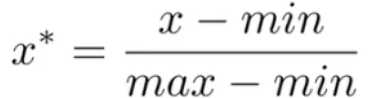
缺点:若有新数据加入,可能导致min和max的变化。
演示示例:
import numpy as np a = np.random.uniform(-10, 20, 100) # 100个-10到20之间的随机数 print(a) # [ 2.74793518 6.41071562 15.34009849 ... -1.33143778 -7.95168854] b = (a - a.min()) / (a.max() - a.min()) print(b) # [0.1371042 0.04541101 0.14368817 0.35814033 0.27530808 ... 0.76208966 0.41034195]
2)Z-score标准化

将原始数据转化为 均值为0,标准差为1 的正态分布的随机变量。
演示示例:
import numpy as np a = np.random.uniform(-10, 20, 100) # 100个-10到20之间的随机数 print(a) # [ 2.74793518 6.41071562 15.34009849 ... -1.33143778 -7.95168854] c = (a - a.mean()) / a.std() print(c) # [ 0.73462873 -1.2513859 -1.73108227 -1.05090879 ... 0.80783486 1.66651732]
四、多因子选股策略实现——市值+ROE(净资产收益率)
双因子评分:市盈率越高越好,市值越小越好。
def initialize(context): # 设定沪深300作为基准 set_benchmark(‘000300.XSHG‘) # 开启动态复权模式(真实价格) set_option(‘use_real_price‘, True) # 输出内容到日志 log.info() log.info(‘初始函数开始运行且全局只运行一次‘) # 股票类每笔交易时的手续费是:买入时佣金万分之三,卖出时佣金万分之三加千分之一印花税, 每笔交易佣金最低扣5块钱 set_order_cost(OrderCost(close_tax=0.001, open_commission=0.0003, close_commission=0.0003, min_commission=5), type=‘stock‘) # 获取指数成份股 g.security = get_index_stocks(‘000300.XSHG‘) # valuation:财务数据表,code是对应的股票代码 # indicator:财务指标数据 # 这里不能使用 in 操作, 要使用in_()函数,找到沪深300股份对应的财务数据 g.q = query(valuation, indicator).filter(valuation.code.in_(g.security)) g.N = 20 # 20只股票 run_monthly(handle, 1) # 第一个参数是对应的函数,第二个参数指第几个交易日 def handle(context): df = get_fundamentals(g.q)[[‘code‘, ‘market_cap‘, ‘roe‘]] # 花式索引选出股票代码和市值、净资产收益率 # 市值和ROE的数值大小差别很大,先完成归一化 df[‘market_cap‘] = (df[‘market_cap‘] - df[‘market_cap‘].min()) / (df[‘market_cap‘].max() - df[‘market_cap‘].min()) df[‘roe‘] = (df[‘roe‘] - df[‘roe‘].min()) / (df[‘roe‘].max() - df[‘roe‘].min()) # 创建新的score列 df[‘score‘] = df[‘roe‘] - df[‘market_cap‘] df = df.sort_values(‘score‘).iloc[-g.N:,:] # 根据score排序,选最大的20个,因此获取最后20个 # 期待持有的股票 to_hold = df[‘code‘].values for stock in context.portfolio.positions: if stock not in to_hold: # 目标股数下单,卖出非标的的股票 order_target(stock, 0) # 期待持有且还未持仓的股票 to_buy = [stock for stock in to_hold if stock not in context.portfolio.positions] if len(to_buy) > 0: # 需要调仓 # 每只股票预计投入的资金 cash_per_stock = context.portfolio.available_cash / len(to_buy) for stock in to_buy: # 按价值下单,买入需买入的股票 order_value(stock, cash_per_stock)
执行效果:
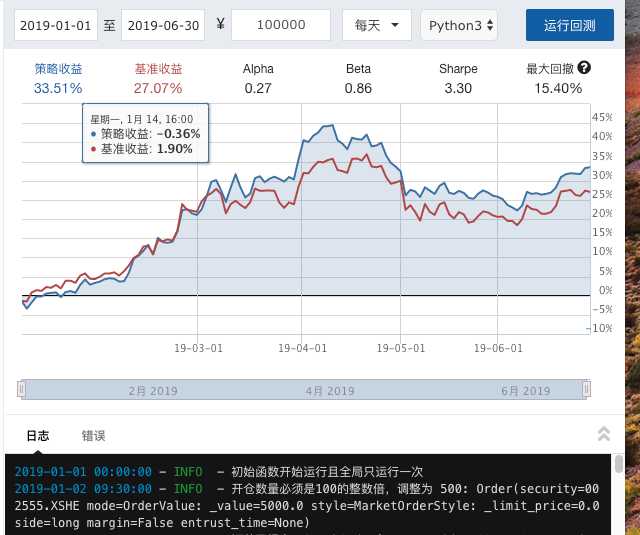
1、花式索引选出股票代码和市值、净资产收益率
打印出股票代码、市值、净资产收益率信息:
def initialize(context): # 设定沪深300作为基准 set_benchmark(‘000300.XSHG‘) # 开启动态复权模式(真实价格) set_option(‘use_real_price‘, True) # 输出内容到日志 log.info() log.info(‘初始函数开始运行且全局只运行一次‘) # 股票类每笔交易时的手续费是:买入时佣金万分之三,卖出时佣金万分之三加千分之一印花税, 每笔交易佣金最低扣5块钱 set_order_cost(OrderCost(close_tax=0.001, open_commission=0.0003, close_commission=0.0003, min_commission=5), type=‘stock‘) # 获取指数成份股 g.security = get_index_stocks(‘000300.XSHG‘) # valuation:财务数据表,code是对应的股票代码 # indicator:财务指标数据 # 这里不能使用 in 操作, 要使用in_()函数,找到沪深300股份对应的财务数据 g.q = query(valuation, indicator).filter(valuation.code.in_(g.security)) g.N = 20 # 20只股票 run_monthly(handle, 1) # 第一个参数是对应的函数,第二个参数指第几个交易日 def handle(context): df = get_fundamentals(g.q)[[‘code‘, ‘market_cap‘, ‘roe‘]] # 花式索引选出股票代码和市值、净资产收益率 print(df)
执行效果如下:
2019-01-01 00:00:00 - INFO - 初始函数开始运行且全局只运行一次 2019-01-02 09:30:00 - INFO - code market_cap roe 0 000001.XSHE 1610.5846 3.06 1 000002.XSHE 2629.5259 3.54 2 000063.XSHE 821.3444 2.52 3 000069.XSHE 520.9592 5.71 4 000100.XSHE 331.9664 3.04 5 000157.XSHE 277.9839 1.18 6 000166.XSHE 917.2129 1.82 7 000333.XSHE 2455.9929 6.12 8 000338.XSHE 615.7874 4.33 ...
2、数据标准化处理
可以看到市值和roe的数据量级都不同,如果要进行分析肯定要进行数据预处理,使两者获得一样的权重。
def handle(context): df = get_fundamentals(g.q)[[‘code‘, ‘market_cap‘, ‘roe‘]] # 花式索引选出股票代码和市值、净资产收益率 # 市值和ROE的数值大小差别很大,先完成归一化 df[‘market_cap‘] = (df[‘market_cap‘] - df[‘market_cap‘].min()) / (df[‘market_cap‘].max() - df[‘market_cap‘].min()) df[‘roe‘] = (df[‘roe‘] - df[‘roe‘].min()) / (df[‘roe‘].max() - df[‘roe‘].min()) print(df)
执行效果如下:
2019-01-01 00:00:00 - INFO - 初始函数开始运行且全局只运行一次 2019-01-02 09:30:00 - INFO - code market_cap roe 0 000001.XSHE 0.078971 0.513834 1 000002.XSHE 0.133397 0.537549 2 000063.XSHE 0.036815 0.487154 3 000069.XSHE 0.020771 0.644763 4 000100.XSHE 0.010676 0.512846 5 000157.XSHE 0.007792 0.420949 6 000166.XSHE 0.041936 0.452569 7 000333.XSHE 0.124128 0.665020
以上是关于量化交易——因子选股多因子选股策略的主要内容,如果未能解决你的问题,请参考以下文章